
Актуальность исследования
В последние годы наблюдается стремительный рост применения глубоких нейронных сетей в самых разных областях: компьютерное зрение, обработка естественного языка, анализ временных рядов и др. Они демонстрируют высочайшую точность на сложных задачах, особенно при наличии большого объёма размеченных данных.
Однако широкая популяризация глубокого обучения создала устойчивый миф о том, что нейросети – универсальное решение. На практике классические методы (такие, как линейная регрессия, деревья решений, SVM, бустинг) зачастую превосходят нейросети на небольших и умеренных по объёму данных, требуют меньше вычислительных ресурсов и проще интерпретируются.
Кроме того, в задачах с ограниченным объёмом выборки или строгими требованиями к объяснимости для промышленности и клинических приложений классические модели остаются предпочтительным выбором. Поэтому важно не плыть по течению «хайпа» без оценки обоснованности перехода на нейросети.
Цель исследования
Цель данного исследования – разработать и обосновать чёткие критерии, при которых применение более сложных архитектур нейронных сетей действительно оправдано, а в каких задачах предпочтительнее классические модели машинного обучения.
Материалы и методы исследования
Исследование основано на анализе открытых источников, включая научные публикации, бенчмарки, данные Kaggle и открытые исследования архитектур TabNet, TabTransformer и FT-Transformer. Эмпирическая часть включает сравнение производительности пяти классических моделей при балансировке выборки с помощью методов ADASYN и SMOTE. Использованы количественные метрики оценки качества моделей: Accuracy, AUC, а также показатели вычислительной эффективности. Рассматривались как табличные, так и неструктурированные данные (изображения, текст, временные ряды). Для нейросетевых моделей оценивались архитектуры MLP, CNN, RNN (в т. ч. LSTM, GRU), трансформеры.
Результаты исследования
Классические машинные модели – такие, как линейные методы (логистическая регрессия, LDA), SVM, деревья решений, ансамбли и k‑ближайших соседей – по-прежнему широко используются благодаря своей надёжности, интерпретируемости и способности эффективно работать на малых и средних датасетах. Линейные модели, особенно логистическая регрессия и LDA, отлично справляются с задачами при наличии большого числа признаков и относительно линейной структуре зависимостей. Они быстро обучаются, легко обобщаются и почти не требуют тщательной настройки. Однако они ограничены в возможностях описания сложных, нелинейных закономерностей.
SVM с ядровыми функциями (например, RBF) существенно расширяет область применимости, позволяя качественно решать труднорешаемые нелинейные классификации и устойчив к шумам и выбросам. При достаточном объёме данных SVM и RF (Random Forest) демонстрируют схожую производительность, однако SVM может оказаться медленнее на больших выборках.
Деревья решений и особенно ансамбли (Random Forest, градиентный бустинг) эффективны при работе с категориальными и табличными данными, легко интерпретируемые, устойчивы к пропускам и выбросам данных, и позволяют оценить важность признаков.
На рисунке 1 представлены значения двух ключевых метрик – точности (Accuracy) и площади под кривой ошибок (AUC) – для пяти классических моделей машинного обучения: Gradient Boosting, Random Forest, SVM, Decision Tree и Logistic Regression. Каждая модель протестирована при использовании двух популярных методов балансировки классов: ADASYN и SMOTE. Это позволяет сравнить, как различная стратегия балансировки влияет на эффективность моделей.
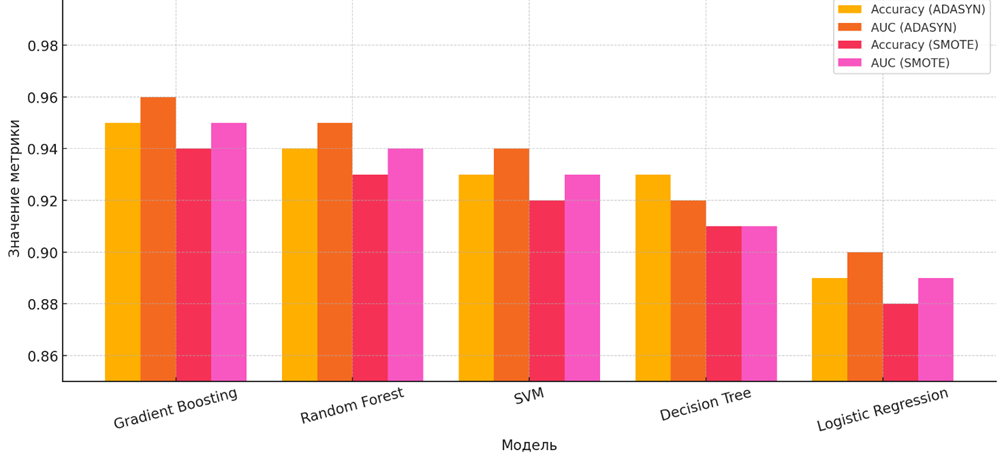
Рис. 1. Сравнение Accuracy и AUC при балансировке ADASYN и SMOTE
Архитектуры обнаруживают способность вычленять разный уровень признаков: MLP подходят для табличных данных, однако неэффективны при высокой размерности; CNN благодаря свёрткам автоматически учат иерархию признаков – низкоуровневые фильтры переходят к высокоуровневым паттернам, что делает их идеальным выбором для изображений. Свёрточные сети превосходят RF и SVM по качеству при обработке визуальных данных [1, с. 551].
RNN (LSTM, GRU) специально разработаны для последовательностей – текстов, временных рядов – за счёт памяти и обратных связей. Они успешно заменили методы без предшествующей памяти, такие как Naive Bayes, при анализе текста, поскольку учитывают контекст соседних токенов [2, с. 546].
Трансформеры с механизмом self-attention обеспечивают глобальное контекстирование, устраняя необходимость в рекуррентности, и значительно ускоряют обучение благодаря параллелизму. Они установили новые рекорды на знаменитых NLP-бенчмарках: BLEU‑41.8 для EN→FR, 28.4 BLEU для EN→DE. Benchmark GLUE/SuperGLUE и SQuAD демонстрируют лидерство трансформеров в языковых задачах.
В таблице 1 представлено систематизированное сравнение четырёх ключевых архитектур нейронных сетей – MLP (полносвязные сети), CNN (свёрточные сети), RNN (включая LSTM и GRU) и трансформеров.
Таблица 1
Сравнительная характеристика основных архитектур нейронных сетей
Архитектура | Параметры | Преимущества | Ограничения |
MLP | от сотен до миллионов | Простота, гибкость | Требует ручного отбора признаков |
CNN | От тысяч до сотен миллионов | Локальные и многомасштабные признаки, параметрическое снижение | Не годятся для последовательностей |
RNN/LSTM/GRU | Сотни тысяч – миллионы | Контекст последовательности | Проблемы с параллелизмом, исчезающие градиенты |
Transformer | Десятки миллионов и выше | Глобальные зависимости, параллельное обучение | Высокие требования к данным и ресурсам |
Сравнение нейросетей с классическими моделями показывает, что выбор подхода зависит не столько от трендов, сколько от специфики задачи, объёма данных и требований к ресурсоёмкости. На задачах обработки изображений, речи и текста нейросети превосходят классические модели благодаря способности автоматически извлекать сложные, абстрактные признаки и работать с нерегулярной структурой данных. Например, свёрточные сети превосходят SVM или RF на ImageNet с точностью Top‑1 около 76% против 55–60% у классических подходов.
Однако на табличных данных ситуация качественно иная. Многочисленные исследования подтверждают, что деревья решений, градиентный бустинг (XGBoost, LightGBM), часто превосходят или не уступают нейросетям на «средних» и небольших табличных выборках (~10000 строк).
Причины:
- сильное индуктивное смещение классических моделей позволяет лучше справляться с нерегулярными распределениями признаков;
- сетям труднее учиться на малых объемах без переобучения;
- нелинейность таблиц часто лучше отслеживается деревьями.
В отдельных случаях нейросети, адаптированные для табличных данных (TabPFN), показывают успех на малых объемах до 10000 строк, но требуют специализированных архитектур.
С точки зрения ресурсов и интерпретируемости классические модели существенно выигрывают. Исследователи отмечают, что SVM, RF работают быстрее, требуют меньше RAM и CPU, проще объяснимы и настраиваемы. Нейросети требуют GPU, значительной вычислительной мощности, а также тщательной настройки гиперпараметров.
На рисунке 2 представлен пример сравнительного анализа: диаграмма производительности моделей на табличных данных средних и больших объёмов, где видно устойчивое лидерство бустинга, с возрастанием размера выборки нейросети приближаются, но не всегда превосходят.
Рис. 2. Структура направлений в области искусственного интеллекта
Таким образом, ситуации, в которых нейросети оправданы:
- когда вход = изображения, тексты, речь, видео;
- когда объем данных >50 000–100000, особенно с нерегулярной структурой;
- когда нужны сложные нелинейные взаимосвязи и высокие вычислительные ресурсы доступны.
С другой стороны, классические модели предпочтительны:
- при небольших (<10–20 тыс.) табличных данных;
- когда важна экономия ресурсов и интерпретируемость;
- при нерегулярных распределениях признаков и присутствии «шумных» колонок.
Принцип рационального выбора архитектуры нейросети опирается на следующие критерии:
- Тип данных и их объём: нейросети преобладают на неструктурированных данных и больших выборках (>50–100 тыс.), в то время как классические модели эффективны на табличных данных малого и среднего объёма.
- Доступные ресурсы: при ограниченных CPU/RAM выбираем классические модели, при возможности использования GPU – нейросети.
- Необходимость объяснимости: если важна прозрачность модели (клиника, финансы, юстиция), чаще остаются классические методы.
- Сложность задачи: для простых задач генерации признаков нейросети избыточны, классические модели предпочтительны; сложные задачи с нелинейностями, зависимостями и структурой требуют нейросетевых архитектур.
Таблица 2 представляет собой систематизированную подсказку для выбора между классическими моделями машинного обучения и нейронными сетями.
Таблица 2
Критерии выбора между классическими моделями машинного обучения и нейронными сетями
Критерий | Классические модели ML | Нейронные сети (Deep Learning) |
Тип данных | Табличные, структурированные | Изображения, текст, речь, видео |
Объём выборки | Малый-средний (<10–50 тыс.) | Большой (>50–100 тыс.) |
Вычислительные ресурсы | CPU, меньше RAM, быстрые плагины | GPU/TPU, много RAM, долгий обучение |
Интерпретируемость | Высокая (регрессии, деревья) | Низкая, чёрный ящик |
Потребность в фичеринге | Да, ручной | Нет, автоматическое |
Сложность задачи | Простые зависимости | Нелинейные, сложные паттерны |
Данный анализ позволяет сформировать чёткие правила:
- Выбор в пользу нейросетей: при работе с неструктурированными большими данными, когда вычислительные ресурсы и точность важнее интерпретируемости.
- Выбор в пользу классических моделей: при небольшом табличном наборе, ограниченных ресурсах и необходимости объяснимости результатов [5].
Рациональный выбор архитектуры модели машинного обучения должен основываться на типе данных, объёме выборки, цели анализа, требованиях к интерпретируемости и доступных вычислительных ресурсах. В практике выработаны устойчивые рекомендации, позволяющие избегать избыточного усложнения моделей и фокусироваться на эффективности.
Если задача связана с табличными данными (например, выгрузки из CRM или ERP-систем), наилучшие результаты показывают классические алгоритмы – прежде всего градиентный бустинг (XGBoost, LightGBM, CatBoost). Эти модели стабильно превосходят нейросети на малых и средних выборках. На объёмах до 10–50 тысяч строк нейросети, включая TabNet или FT-Transformer, не дают прироста качества, при этом требуют больше ресурсов и времени на обучение. Когда важна объяснимость (например, в медицине или кредитном скоринге), логистическая регрессия, деревья решений или их ансамбли остаются предпочтительными. Нейросети в таких условиях избыточны – их высокая гибкость оборачивается риском переобучения и слабой интерпретируемостью.
В задачах компьютерного зрения выбор нейросетевых архитектур очевиден. Свёрточные нейронные сети (CNN) типа ResNet, EfficientNet или VGG значительно превосходят классические модели. Для мобильных решений подойдут компактные архитектуры MobileNetV2 или SqueezeNet. В сложных задачах, где необходим глобальный контекст (например, медицинская визуализация), эффективны Vision Transformers (ViT, DeiT).
Для обработки текста (NLP) чёткое преимущество также за трансформерами. Модели BERT, RoBERTa, DistilBERT превосходят традиционные методы вроде наивного байеса или логистической регрессии в задачах классификации, извлечения сущностей и анализа тональности. Классические методы допустимы при крайне малом объёме данных или высокой чувствительности к ресурсоёмкости. Для генерации текста (ответы, автокомплиты, чат-боты) применяются автогрегрессивные трансформеры – GPT, T5, LLaMA.
В задачах прогнозирования временных рядов рекомендуется начинать с классических моделей – ARIMA, Prophet, экспоненциального сглаживания, Random Forest. При наличии выраженной нелинейной динамики и сложной сезонности применимы рекуррентные сети (LSTM, GRU), Temporal Convolutional Networks (TCN) и трансформерные архитектуры (Informer, Autoformer). Их применение оправдано только при достаточном объёме данных и ресурсов [3].
В ситуациях, где критически важна объяснимость модели (например, медицина, финансы, юриспруденция), приоритет остаётся за логистической регрессией, деревьями решений, RuleFit и другими интерпретируемыми подходами. Нейросети, особенно глубокие, уступают в прозрачности и плохо подходят для задач с требованиями к отчётности.
Обобщённо: если данные табличные, выборка ограничена, ресурсов мало, а объяснимость критична – используйте классические модели. Если данные сложные, объёмные, неструктурированные, а в приоритете точность – используйте нейросети. В любом случае, рекомендуется тестировать обе группы моделей – реальные данные часто ведут себя непредсказуемо [4].
Выбор архитектуры – это не гонка за модой, а грамотное сопоставление возможностей алгоритма с задачей. Такой подход позволяет добиться оптимального баланса между качеством, ресурсами, устойчивостью и практической применимостью модели.
В ближайшие годы ожидается рост гибридных подходов, сочетающих преимущества нейросетей и классических моделей (например, использование эмбеддингов в бустинге или стеккинг архитектур). Также активно развиваются интерпретируемые нейросети и энергоэффективные модели для edge-вычислений. Перспективными направлениями остаются AutoML, нейросетевые архитектуры для табличных данных, а также модели с малым числом параметров, способные обучаться на ограниченных выборках без потери качества.
Выводы
Проведённый анализ показал, что эффективность архитектур машинного обучения зависит от множества факторов: структуры и объёма данных, доступных ресурсов, требований к интерпретируемости и сложности задач. Нейросети существенно превосходят классические модели на неструктурированных данных (изображения, текст, звук), особенно при больших объёмах выборки и высокой сложности взаимосвязей. В то же время на табличных данных классические алгоритмы, такие как градиентный бустинг и SVM, демонстрируют не только сопоставимое, но и зачастую более стабильное качество при меньших затратах ресурсов и более высокой интерпретируемости.
Применение нейросетей при малом количестве примеров без специализированной архитектуры не оправдано и приводит к переобучению. На основе анализа предложена матрица критериев выбора модели, позволяющая обоснованно принимать архитектурные решения. Обобщённо, нейросети – мощный, но ресурсоёмкий инструмент, уместный не во всех задачах, тогда как классические модели сохраняют актуальность в условиях ограниченности ресурсов и требований к прозрачности вычислений.
