
В условиях современного документооборота существует потребность в автоматической классификации текстовой информации, что позволяет существенно ускорить обработку документов. Алгоритмы на основе методов глубокого обучения и нейросетей, такие, как Word2Vec, способны обеспечивать высокую точность при работе с большими массивами текстовых данных, выделяя семантические связи между словами.
На этапе формирования признакового пространства текстовой информации предлагается использовать алгоритм Word2Vec, который позволяет представить слова в виде плотных векторов в непрерывном пространстве. В отличие от TF-IDF, который присваивает каждому слову уникальный вес на основе его частоты в документе и значимости для всего корпуса, Word2Vec обучается выявлять взаимосвязи между словами на основе их контекста. Это делает Word2Vec более эффективным при работе с неформализованными текстами, так как он способен улавливать семантические связи.
После предварительной обработки текстовой информации, включающей лемматизацию, удаление пунктуации и токенизацию, текстовая информация поступает на вход модели Word2Vec. Word2Vec обучается на корпусе текстов, где каждая словарная величина представляется в виде вектора фиксированной размерности. Эти векторы отражают семантическое сходство между словами на основании контекстов их употребления.
1. Обучение Word2Vec:
Для обучения модели используется алгоритм Skip-gram или CBOW (Continuous Bag of Words). Эти алгоритмы обучают нейросеть предсказывать слово на основе контекста или контекст на основе слова. В процессе обучения для каждого слова формируется вектор, который отражает его положение в семантическом пространстве.
2. Формирование признакового пространства:
После обучения Word2Vec, каждому документу присваивается векторное представление, вычисленное как среднее векторов слов, присутствующих в тексте. Это позволяет каждому документу иметь плотное векторное представление фиксированной длины, что упрощает дальнейшую классификацию.
3. Классификация:
Векторное представление документа поступает на вход нейросетевой модели для дальнейшей классификации на наличие или отсутствие сведений, составляющих государственную тайну. Преимуществом использования Word2Vec является возможность классификации текстов, содержащих редкие или измененные ключевые слова, поскольку алгоритм улавливает семантические связи между словами, а не опирается на их точное совпадение.
Алгоритм формирования признакового пространства и классификации текстов с использованием Word2Vec
1. Входные данные:
Корпус текстов: ![]() , где каждый документ
, где каждый документ ![]() представляет собой текстовую информацию электронного вида (ТИЭВ). Каждый текст может содержать или не содержать служебную информацию.
представляет собой текстовую информацию электронного вида (ТИЭВ). Каждый текст может содержать или не содержать служебную информацию.
2. Разметка данных:
Экспертная группа помечает тексты со служебной информацией (СИ) меткой ![]() (наличие служебных сведений) и тексты без СИ меткой
(наличие служебных сведений) и тексты без СИ меткой ![]() (отсутствие служебных сведений). Множество документов разбивается на два класса:
(отсутствие служебных сведений). Множество документов разбивается на два класса: ![]() и
и ![]()
Обеспечивается сбалансированность классов путём аугментации данных или удаления избыточных данных.
3. Предварительная обработка текстов:
Для каждого документа ![]() :
:
- приведение текста к нижнему регистру;
- очистка от пунктуации и символов, которые не несут информационной ценности;
- лемматизация для приведения слов к начальной форме;
- токенизация – разбиение текста на отдельные слова (токены);
- удаление «стоп-слов» – слов, не несущих значимого вклада в смысл текста.
4. Обучение модели Word2Vec:
Для обучения модели Word2Vec используется алгоритм Skip-gram или CBOW.
Корпус текстов ![]() служит для обучения модели. Модель формирует плотные векторные представления для каждого слова на основе его контекстов в корпусе.
служит для обучения модели. Модель формирует плотные векторные представления для каждого слова на основе его контекстов в корпусе.
Вектор слова ![]() представляет собой точку в многомерном пространстве, где слова, употребляющиеся в схожих контекстах, расположены рядом.
представляет собой точку в многомерном пространстве, где слова, употребляющиеся в схожих контекстах, расположены рядом.
5. Векторизация документов:
Для каждого документа ![]() , содержащего слова
, содержащего слова ![]() создаётся векторное представление документа.
создаётся векторное представление документа.
Вектор документа ![]() вычисляется как среднее векторов всех слов в документе:
вычисляется как среднее векторов всех слов в документе:
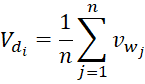 , (1)
, (1)
Где ![]() – векторное представление слова
– векторное представление слова ![]() , полученное с помощью модели Word2Vec.
, полученное с помощью модели Word2Vec.
6. Формирование обучающей и тестовой выборок:
Документы ![]() делятся на обучающую
делятся на обучающую ![]() и тестовую
и тестовую ![]() выборки в соотношении 80/20.
выборки в соотношении 80/20.
Для каждого документа в выборках также сохраняется его метка класса ![]() или
или ![]() .
.
7. Обучение нейросетевой модели:
На вход нейросети подаются векторные представления документов ![]() , а также метки классов.
, а также метки классов.
Нейросеть имеет один скрытый слой и один выходной нейрон для задачи бинарной классификации (наличие или отсутствие ССГТ).
В процессе обучения используется метод обратного распространения ошибки и функция активации (например, сигмоидальная функция):
![]() , (2)
, (2)
Цель обучения – минимизация ошибки классификации на обучающей выборке.
8. Контроль качества классификации:
Проводится контроль на предмет сбалансированности классов и корректности работы модели на тестовой выборке.
Модель оценивается по метрике Accuracy:
![]() , (3)
, (3)
Где ![]() – количество верных срабатываний для класса
– количество верных срабатываний для класса ![]() – верные срабатывания для класса
– верные срабатывания для класса ![]() – количество ложных срабатываний для класса
– количество ложных срабатываний для класса ![]() ,
, ![]() – пропуски срабатываний для класса
– пропуски срабатываний для класса ![]()
9. Итог:
После обучения модели и получения высоких показателей точности ![]() , модель сохраняется для дальнейшего использования в системе контроля.
, модель сохраняется для дальнейшего использования в системе контроля.
Если текст подлежит контролю (формализованный документ), дополнительно используется косинусное сравнение векторов для проверки сходства с эталонными формализованными документами.
