
Компьютерные инциденты, вызванные злонамеренными действиями или уязвимостями в системах безопасности, представляют значительную угрозу для организаций. Ежегодно вследствие кибератак компании теряют миллионы долларов, и эти потери зачастую оказываются невосполнимыми. В условиях постоянного совершенствования методов атак становится очевидным, что ни одна система защиты не может обеспечить 100% безопасность.
Основная задача реагирования на компьютерные инциденты заключается в своевременном выявлении угрозы, сборе доказательной базы и реализации мер по минимизации ущерба. Несмотря на широкий спектр существующих систем защиты, инциденты продолжают происходить, что диктует необходимость постоянного развития методов их расследования.
Методология расследования инцидентов
Процесс реагирования на компьютерные инциденты включает несколько последовательных этапов: от подготовки к инциденту до его полного разрешения и анализа последствий. В ходе расследования решаются следующие задачи:
- подтверждение или опровержение факта инцидента;
- сбор достоверной информации о событии;
- контроль за правильностью обнаружения фактов;
- минимизация влияния на операционную деятельность компании;
- подготовка доказательной базы для гражданских и уголовных исков.
Основные этапы расследования:
1. Подготовка к инциденту
Этот этап включает комплекс мероприятий, направленных на минимизацию последствий компьютерных инцидентов и ускорение реагирования на них.
Основные действия:
Регулярное создание резервных копий данных ![]() , где
, где ![]() – объём данных, копируемых на резервные носители в момент времени
– объём данных, копируемых на резервные носители в момент времени ![]() Важно обеспечить минимальный интервал между созданием копий для критически важных данных, чтобы при инциденте объём утраченной информации
Важно обеспечить минимальный интервал между созданием копий для критически важных данных, чтобы при инциденте объём утраченной информации ![]() –
– ![]() был минимальным.
был минимальным.
Обеспечение своевременного обновления программного обеспечения. Здесь уместно применение модели надёжности ПО, например, модели восстановления ошибок:
![]() (1)
(1)
Где ![]() – вероятность обнаружения уязвимости в ПО к моменту времени
– вероятность обнаружения уязвимости в ПО к моменту времени ![]() , а
, а ![]() – параметр интенсивности обнаружения уязвимостей.
– параметр интенсивности обнаружения уязвимостей.
Кроме того, важна подготовка сотрудников, которые должны чётко понимать свои роли и обязанности в случае инцидента. Команда реагирования должна быть заранее назначена и обучена.
2. Выявление инцидентов
Выявление инцидентов можно рассматривать как задачу по детектированию аномалий в потоках данных и сетевых соединениях. В этом процессе используются IDS (системы обнаружения вторжений), которые опираются на модели нормального поведения сети и поиск отклонений:
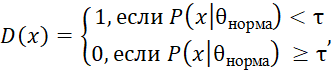 (2)
(2)
Где ![]() – бинарная функция, которая возвращает 1, если обнаружен инцидент (аномалия), и 0, если система функционирует в нормальном режиме,
– бинарная функция, которая возвращает 1, если обнаружен инцидент (аномалия), и 0, если система функционирует в нормальном режиме, ![]() – вероятность того, что наблюдаемый набор данных соответствует нормальному поведению сети с параметрами
– вероятность того, что наблюдаемый набор данных соответствует нормальному поведению сети с параметрами ![]() , а
, а ![]() – пороговое значение для определения аномалий.
– пороговое значение для определения аномалий.
Таким образом, система детектирует инцидент (выдаёт сигнал ![]() при нарушении нормального поведения).
при нарушении нормального поведения).
3. Первоначальная реакция
На этом этапе важно оперативно подтвердить факт инцидента и собрать первичные доказательства. Для этого анализируются лог-файлы, сетевые трафики и журналы событий. Один из математических методов, применяемых для анализа временных рядов логов, – автокорреляционный анализ:
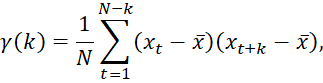 (3)
(3)
Где ![]() – автокорреляция на лаге
– автокорреляция на лаге ![]() ,
, ![]() – значение лог-файла в момент времени
– значение лог-файла в момент времени ![]() ,
, ![]() – среднее значение, а
– среднее значение, а ![]() – общее число наблюдений. Снижение корреляции может указывать на аномалии в активности пользователей или систем.
– общее число наблюдений. Снижение корреляции может указывать на аномалии в активности пользователей или систем.
4. Формирование стратегии реакции
Определение оптимальной стратегии реакции на инцидент требует анализа собранных данных и оценки вероятных сценариев развития атаки. Для этого используется модель оценки риска:
![]() (4)
(4)
Где ![]() – вероятность события
– вероятность события ![]() , а
, а ![]() – возможные последствия данного события в виде финансовых потерь или утраты данных. Цель – минимизация функции риска
– возможные последствия данного события в виде финансовых потерь или утраты данных. Цель – минимизация функции риска ![]() при выборе соответствующих мер реагирования.
при выборе соответствующих мер реагирования.
5. Сетевой мониторинг и дублирование данных
Для восстановления системы после инцидента и его расследования необходимо создавать точные копии данных (форензические копии). Эти данные могут использоваться для судебных разбирательств. Ключевым элементом является контроль целостности данных с помощью хэш-функций:
![]() (5)
(5)
Где ![]() – хэш-функция, применённая к файлу
– хэш-функция, применённая к файлу ![]() . Если хэш
. Если хэш ![]() совпадает с
совпадает с ![]() , то файлы
, то файлы ![]() и
и ![]() считаются идентичными, что необходимо для контроля неизменности данных после дублирования.
считаются идентичными, что необходимо для контроля неизменности данных после дублирования.
6. Исследование и восстановление
Анализ событий, приведших к инциденту, включает определение уязвимостей и моделей атак. Для этого используются графы атак, которые представляют собой ориентированные графы, где вершины – это состояния системы, а рёбра – действия злоумышленника:
![]() (6)
(6)
Где ![]() – множество возможных состояний системы, а
– множество возможных состояний системы, а ![]() – множество действий (атак) злоумышленника. Анализ графа атак позволяет предсказать возможные дальнейшие шаги атакующего и предложить меры для устранения уязвимостей.
– множество действий (атак) злоумышленника. Анализ графа атак позволяет предсказать возможные дальнейшие шаги атакующего и предложить меры для устранения уязвимостей.
Восстановление системы происходит на основе анализа критичности затронутых систем и ресурсов. Например, при потере данных можно использовать метод восстановления с применением резервных копий:
![]() (7)
(7)
Где ![]() – объём восстановленных данных,
– объём восстановленных данных, ![]() – объём данных из резервной копии, а
– объём данных из резервной копии, а ![]() – данные, восстановленные из других источников (например, сетевых кешей).
– данные, восстановленные из других источников (например, сетевых кешей).
7. Отчёт и завершение работы
Завершение расследования включает создание отчёта, где подробно фиксируются все обнаруженные факты, проведённые мероприятия и анализ последствий. Также проводится анализ эффективности проведённых мероприятий и оцениваются возможные меры для улучшения реакции на инциденты в будущем. На этом этапе может использоваться статистический анализ инцидентов для предсказания будущих угроз:
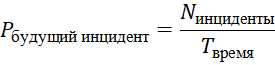 , (8)
, (8)
Здесь ![]() – вероятность нового инцидента в будущем,
– вероятность нового инцидента в будущем, ![]() – количество инцидентов за прошедший период, а
– количество инцидентов за прошедший период, а ![]() – длительность наблюдаемого периода.
– длительность наблюдаемого периода.
Расширенная методология реагирования на компьютерные инциденты с использованием математических моделей позволяет систематизировать процесс расследования, улучшить его точность и снизить время реакции на атаки. Формализованный подход к выявлению угроз и оценке рисков помогает компаниям своевременно предотвращать и минимизировать ущерб от инцидентов.
