.png&w=384&q=75)
Введение
Электронная коммерция (e-commerce) – это бизнес-модель, позволяющая компаниям и частным лицам осуществлять покупку и продажу товаров и услуг через интернет [1]. Она быстро набирает популярность и стала важной частью нашей жизни. Для успешной работы таких систем важны точные методы прогнозирования спроса и анализа поведения клиентов.
Мы рассмотрим пример продажи товара “Samsung A70” и продемонстрируем, как нейронные сети могут быть эффективно использованы для точного прогнозирования. Пошагово создадим модель и наглядно покажем её высокую эффективность.
Постановка задачи
Традиционные статистические методы не всегда учитывают все факторы, влияющие на прогнозирование, что приводит к ошибкам, избыточным запасам и потерям прибыли. Нейронные сети, особенно LSTM, решают эту проблему, обеспечивая гибкость и точность.
LSTM (Long Short-Term Memory) – это тип рекуррентной нейронной сети (RNN), разработанный для решения проблемы долгосрочной зависимости, характерной для классических RNN. LSTM способны эффективно обучаться и сохранять информацию на протяжении долгих временных интервалов [2].
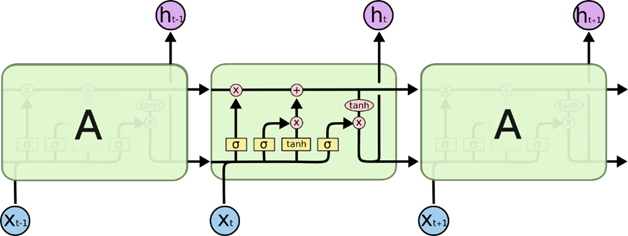
Рис. 1. Структура LSTM сети
Решение задачи
Решение данной задачи разделим на несколько этапов:
1. Загрузка и подготовка данных
Для исследования использован Excel-файл с данными о продажах из сайта e-katalog. Файл состоит из двух страниц: на первом листе представлены данные для обучения и тестирования модели (с 29.08.2022 по 15.07.2024), а на второй – данные для проверки точности прогнозов на новых данных (с 22.07 по 26.08).
Excel-файл имеет следующий вид:
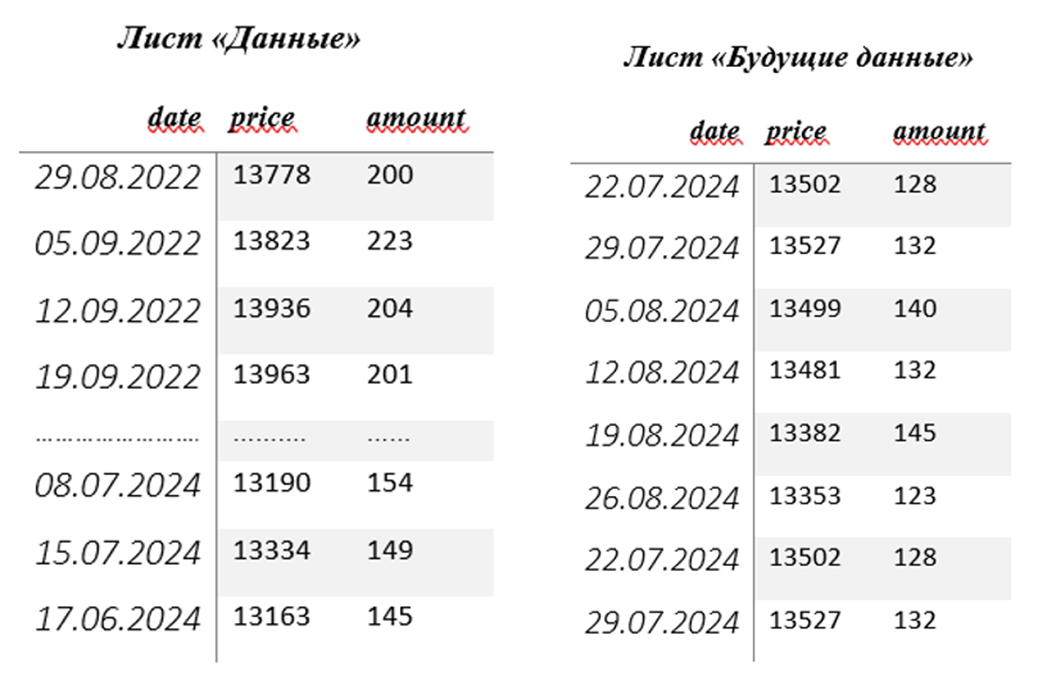
Рис. 2. Содержание Excel-файла
Столбец с датами преобразуем в числовой формат с помощью метода toordinal(), поскольку модели машинного обучения работают с числовыми значениями. В результате этих действий получаем:
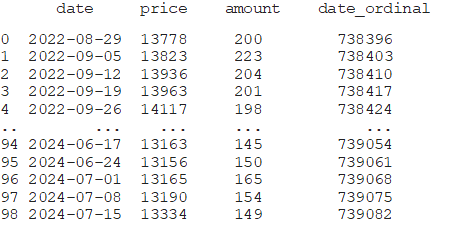
Рис. 3. Данные после преобразования даты
2. Определение признаков и целевой переменной
В качестве признаков (X) используем дату в числовом формате, а целевыми переменными (y) являются цена и количество продаж.
3. Разделение данных на тренировочную и тестовую выборки
Чтобы проверить способность модели к обобщению, мы разделяем набор данных на две части: тренировочную (X_train, y_train) и тестовую выборки (X_test, y_test). Для этого используем функцию train_test_split(). 80% данных направляем на обучение модели, а оставшиеся 20% – на тестирование.
4. Масштабирование данных
Масштабируем данные перед их подачей в нейронную сеть. Признаки (дата) и целевые переменные (цена и количество) нормализуем с помощью MinMaxScaler, что позволяет преобразовать их значения в диапазон от 0 до 1. Это стандартная практика при работе с нейронными сетями, так как нормализованные данные улучшают сходимость модели и предотвращают проблемы с градиентами.
5. Создание и настройка нейронной сети
Для прогнозирования создаем нейронную сеть с TensorFlow, включающую несколько слоев: первый слой с 128 нейронами и активацией ReLU, второй и третий слои с 64 и 32 нейронами соответственно, также с активацией ReLU для извлечения сложных зависимостей, и выходной слой с 2 нейронами для прогнозов цены и количества с линейной активацией. ReLU преобразует входное значение в диапазон от 0 до положительной бесконечности, передавая ноль для значений меньше или равных нулю. Линейная активация передает входной сигнал без изменений. Модель компилируется с оптимизатором Adam и функцией потерь MSE для минимизации отклонений прогнозов от реальных значений.
6. Обучение модели
Модель обучаем на тренировочной выборке на протяжении 1000 эпох с размером пакета в 16 данных. Обучение модели осуществляется с использованием метода обратного распространения ошибки, который корректирует веса нейронной сети на каждом этапе, минимизируя функцию потерь. Используем большое количество эпох для того, чтобы модель могла найти оптимальные веса, учитывая сложность задачи.
7. Оценка модели
После обучения оцениваем модель на тестовой выборке, используя метрику MAE (средняя абсолютная ошибка). Для нашей задачи MAE составила 0.0702873021364212. Низкое значение MAE свидетельствует о высокой точности модели, что важно для качественного прогнозирования во временных рядах.
8. Прогнозирование
После обучения модели приступаем к прогнозированию на тренировочных и тестовых наборах данных. Используем модель для предсказания цены и количества, затем выполняем обратное масштабирование с помощью MinMaxScaler, чтобы преобразовать нормализованные результаты в исходные единицы измерения. Это важно для того, чтобы результаты прогнозирования могли быть интерпретированы в реальных значениях.
9. Визуализация результатов
Для наглядной оценки результатов прогнозирования строим графики, которые отображают реальные и предсказанные значения цены и количества.
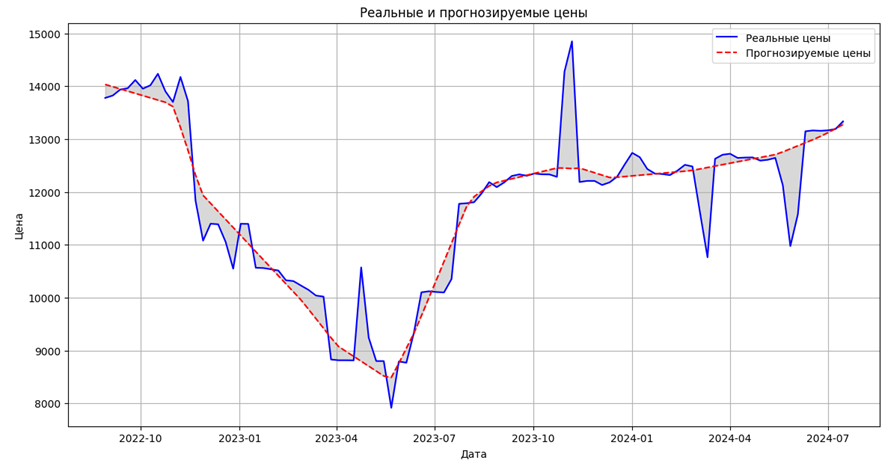
Рис. 4. График отклонения цены
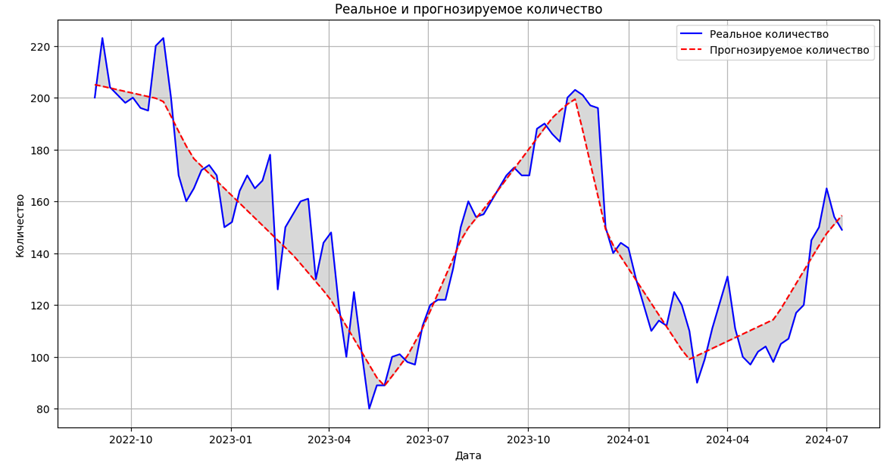
Рис. 5. График отклонения количества
10. Прогнозирование на будущее
Прогнозируем данные на 90 дней вперед, преобразуем и масштабируем даты. Модель использует обученные веса для предсказания цен и количества, затем выполняем обратное масштабирование для получения реальных значений. В заключение, визуализируем результаты на графике:
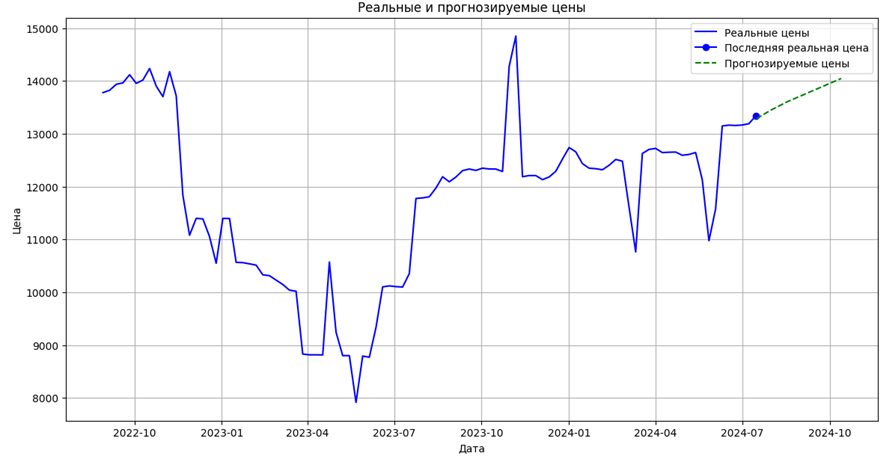
Рис. 6. Прогноз цен на ближайшие три месяца
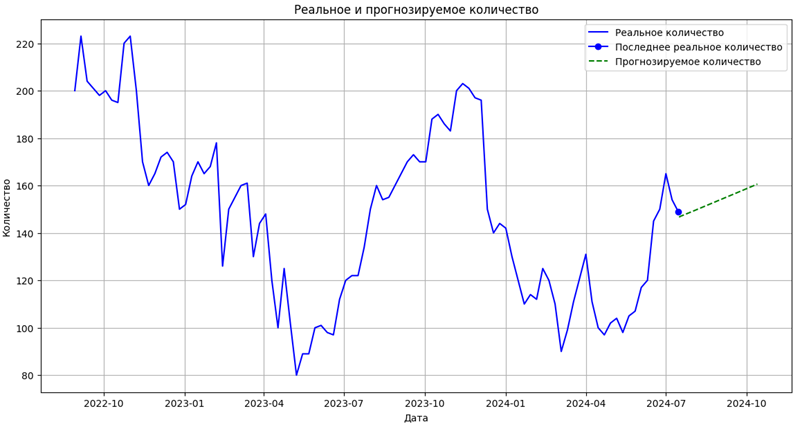
Рис. 7. Прогноз количества на ближайшие три месяца
Заключение
В данной статье рассмотрена проблема прогнозирования в электронной коммерции с использованием нейронных сетей, в частности LSTM. Разработанная программа на Python 3 в среде Colab с использованием TensorFlow показала высокую точность в предсказании цен и объемов продаж. Модель, прошедшая несколько этапов предварительной обработки данных, продемонстрировала возможность делать точные прогнозы на несколько месяцев вперед, что подтверждено сравнением с реальными данными. Это позволяет компаниям более эффективно планировать свою деятельность и учитывать изменения спроса.
