.png&w=384&q=75)
Введение
Интенсивная интеграция генеративных языковых моделей (Large Language Models, LLM) в корпоративные IT-решения расширяет потенциал автоматизации и оптимизации внутренних бизнес-процессов. Вместе с тем, как этапы обучения, так и эксплуатация таких систем оказываются неразрывно связаны с рисками компрометации и утечки информации. Применение в качестве тренировочных и валидационных данных реальных пользовательских или клиентских сведений создает прямую угрозу несоблюдения регуляторных требований, что помимо серьёзных финансовых санкций ведёт к подрыву репутации и утрате доверия со стороны ключевых стейкхолдеров. По оценкам экспертов, к 2032 году объём мирового рынка генеративного ИИ может достичь 1,3 триллиона долларов [1], что свидетельствует не только о масштабах внедрения, но и о параллельном росте связанных угроз. Средняя стоимость одного инцидента утечки данных для организации по состоянию на 2023 год уже превысила 4 млн долларов [2], что делает стратегическое инвестирование в превентивные меры защиты данных экономически оправданным шагом.
В качестве одной из ключевых технологий риск-менеджмента сегодня рассматривается генерация синтетических данных, искусственно созданных наборов, сохраняющих статистические и корреляционные характеристики оригинальных выборок без раскрытия реальной информации. Благодаря этому подходу возможно полное воспроизведение условий обучения и тестирования моделей при минимизации прямого доступа к персональным или конфиденциальным данным. Вместе с тем существующие алгоритмические методики порождения синтетических данных сталкиваются с рядом проблем: от обеспечения корректности воспроизводимых зависимостей между признаками до верификации качества финальных выборок и их соответствия требованиям безопасности и регуляторного надзора. Решение этих задач требует развития методов дифференциальной приватности, усовершенствования генеративных архитектур и создания стандартизированных процедур оценки достоверности синтетических данных.
Целью исследования выступает обобщение и детальный разбор методологических приёмов проектирования и верификации процедур обезличивания, применяемых при синтезе тренировочных наборов данных для обучения моделей.
Научная новизна заключается в описании комплексного фреймворка верификации синтетических данных, объединяющего три ключевых компонента.
Гипотеза сформулирована следующим образом: последовательная многоступенчатая верификация синтетических данных, включающая статистические тесты на схожесть, моделирование атак на приватность и алгоритмические проверки реляционных связей, позволит добиться баланса между высокой точностью воспроизведения реальных данных и минимизацией рисков утечки, при этом снижая операционные издержки, связанные с ошибочным идентифицированием персональных данных в корпоративных приложениях.
Материалы и методы
В последние годы в корпоративных IT-продуктах наблюдается стремительный рост внедрения генеративных моделей, что обусловлено как экономическими, так и технологическими факторами. Так, по оценкам Bloomberg, к 2032 г. объём рынка генеративного ИИ достигнет 1,3 трлн долл. США [1], а в отчёте McKinsey подчёркивается, что уже в начале 2024 г. наблюдается резкий всплеск внедрения Gen AI, приносящий первые ощутимые результаты [14]. Однако рост популярности технологий сопровождается увеличением рисков утечек: согласно отчету IBM, средняя стоимость одного инцидента утечки данных в 2023 г. существенно возросла и превысила сумму в несколько миллионов долларов [2]. Параллельно с этим в «Индустрии 4.0» усиливаются требования к анализу и обработке больших данных, что дополнительно стимулирует создание синтетических наборов данных как средства балансировки между качеством обучения и соблюдением нормативов конфиденциальности (Duan L., Da Xu L. [4, с. 2287-2303]).
Если же переходить к теоретической составляющей исследований, то в центре внимания авторов, с одной стороны, разработка и оценка методов генерации синтетических данных, пригодных для корпоративных кейсов. Aggarwal A., Mittal M., Battineni G. [3] представляют обзор теории GAN и их применений, подчёркивая возможности адаптации к табличным данным. Brophy E. et al. [13, с. 1-31] анализируют использование GAN для временных рядов, выявляя основные архитектурные паттерны и типичные проблемы сходимости моделей. Zhang T. et al. [6] продвигают идею предварительного предобучения таблиц, демонстрируя, как синтетические образцы улучшают последующую табличную классификацию и регрессию. Qian Z., Davis R., Van Der Schaar M. [7, с. 3173-3188] фокусируются на практических benchmark-фреймворках для синтетических табличных данных, обеспечивая разнообразие сценариев применения и унифицированные метрики сравнения. Для промышленных задач Iantovics L. B., Enăchescu C. [11] предлагают методику оценки качества синтетики на основе статистических и семантических критериев, что позволяет адаптировать подход к корпоративным процессам автоматизированного контроля качества. Аналогично, Mayer R., Hittmeir M., Ekelhart A. [10, с. 195-207] показывают, как синтетические данные можно использовать для обнаружения аномалий при сохранении свойств приватности первичных выборок.
С другой стороны, ключевым направлением является интеграция гарантий приватности непосредственно в процедуры обучения и эксплуатации генеративных моделей. Pan K. et al. [5] подробно рассматривают дифференциальную приватность в глубоком обучении, классифицируя существующие методы на микро- и макро-уровнях и оценивая их эффективность в задачах компьютерного зрения и обработки текстов. Dockhorn T. et al. [12] адаптируют дифференциальную приватность к диффузионным моделям, предлагая алгоритмы добавления шума на этапах обратного процесса генерации без значительной деградации качества выборок. В свою очередь, Guo C. et al. [8, с. 8056-8071] формулируют жёсткие границы для возможности восстановления обучающих данных из частных глубоких сетей, внедряя ограничения на лосс-функции и структуру сети, что даёт формальные гарантии приватности на уровне вероятностных оценок.
Наконец, правовые и регуляторные аспекты анонимизации синтетических данных рассматриваются в работе Boudewijn A., Ferraris A. F. [9], которые анализируют синтетические данные как стратегию де-идентификации с точки зрения европейского и международного законодательства, указывая на неоднозначность трактовки «анонимности» и риски обратной идентификации при использовании продвинутых моделей генерации.
Таким образом анализ литературы выявляет противоречие между требованиями к качеству синтетических данных (высокая точность воспроизведения статистических и семантических свойств оригинала) и жёсткими гарантиями приватности (минимизация риска восстановления индивидуальных записей). Большинство работ фокусируется либо на улучшении качества генерации [3; 6; 7, с. 3173-3188], либо на формальных доказательствах приватности [5; 8, с. 8056-8071; 12], тогда как комплексные исследования, сочетающие оба подхода и оценивающие их в корпоративных условиях, встречаются редко. Кроме того, недостаточно освещены следующие вопросы:
- интеграции дифференциальной приватности в генерацию сложных структурированных данных (графов, временных рядов) с учётом специфики корпоративных процессов;
- единства метрик для оценки компромисса «приватность – качество» в реальных приложениях, что затрудняет сравнение разных методов;
- долгосрочных последствий применения синтетических данных в продуктивных IT-системах и рисков кумулятивного накопления утечек при регулярном обновлении моделей;
- формализации требований регуляторов к синтетическим данным в разных юрисдикциях и их учёте при разработке корпоративных решений.
Таким образом, дальнейшие исследования должны быть направлены на разработку унифицированных протоколов верификации и валидации методов приватности, а также на практические испытания гибридных подходов в условиях реальных IT-продуктов.
Результаты и обсуждения
Разрешение имеющихся противоречий возможно лишь при создании целостной методологии, в рамках которой процессы генерации и проверки конфиденциальных данных интегрируются и реализуются последовательно в едином цикле. В качестве решения предлагается архитектура (рис. 1), включающая четыре взаимосвязанных этапа: предварительный анализ и подготовка входных данных, собственно приватная генерация, многогранная верификация результатов и поэтапное, контролируемое развертывание [4, с. 2287-2303; 10, с. 195-207]. Фреймворк выступает концептуальным синтезом современных методологических подходов и обеспечивает непрерывную обратную связь между всеми стадиями жизненного цикла приватных данных.
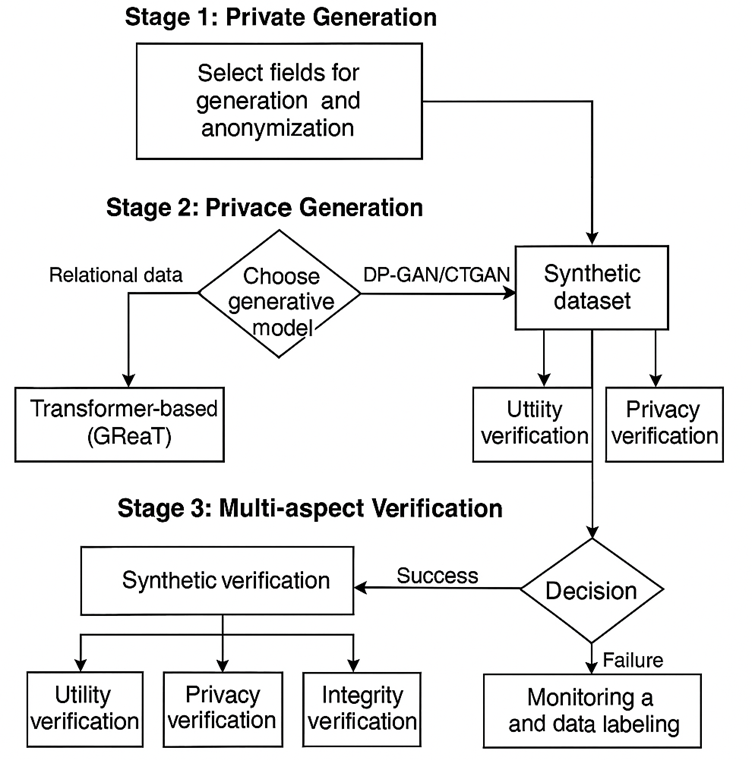
Рис. 1. Комплексный фреймворк разработки и верификации синтетических (составлено автором на основе анализа [11, 12])
Первая фаза предлагаемой методологической цепочки направлена на детальное декомпозирование и анализ корпоративной информации, обладающей сложной реляционной структурой. Цель этого этапа – построение полной ER-диаграммы (entity–relationship diagram), выявление и формализация первичных (PK) и внешних (FK) ключей, а также документирование каскадных правил обновления и удаления записей. Такой подход позволяет получить чёткую карту зависимостей между сущностями, необходимую для корректной эмуляции исходной базы данных в синтетическом виде.
Вторая фаза – генерация данных, предусматривает выбор подходящей архитектуры модели в зависимости от плотности и глубины взаимосвязей в БД. Для систем с развитой реляционной топологией предпочтение отдается трансформерным моделям, таким как GReaT [6], способным поэтапно генерировать строки, учитывая сложные межтабличные зависимости. В сценариях с менее связанными табличными наборами эффективны GAN-решения, например CTGAN или DP-GAN с механизмами дифференциальной приватности [5], что обеспечивает формальные гарантии защиты конфиденциальной информации.
Третий этап – верификация синтетических данных, является ядром предлагаемого фреймворка и решает задачу проверки соответствия сгенерированных выборок реальным аналитическим алгоритмам и критериям качества. Процесс верификации организован по трём независимым направлениям, каждое из которых фокусируется на специфических метриках и методиках оценки (табл.), что позволяет многогранно оценить пригодность синтетического набора для последующего использования.
Таблица
Метрики для многоаспектной верификации синтетических данных (составлено автором на основе анализа [7, с. 3173-3188; 8, с. 8056-8071; 9, с. 17; 13, с. 1-31])
Метрика | Описание | Целевое значение |
Полезность (Utility) | ||
Propensity Mean Squared Error (pMSE) | Оценивает, насколько хорошо классификатор может отличить синтетические данные от реальных. | Случайное угадывание |
Тест Колмогорова-Смирнова (KS Test) | Сравнивает распределения отдельных признаков в реальном и синтетическом наборах. | Минимальное расхождение |
Корреляционная матрица | Сравнение матриц корреляций между признаками. | Минимальное расхождение |
Приватность (Privacy) | ||
Membership Inference Attack (MIA) AUC | Площадь под ROC-кривой для атаки выведения принадлежности. Чем ниже, тем лучше. | Минимальное расхождение |
Дистанционная корреляция (Distance Correlation) | Измеряет зависимость между синтетическим набором данных и ближайшими к нему точками из реального набора. | Минимальное расхождение |
Целостность (Integrity) | ||
Процент нарушения внешних ключей (FK Violation Rate) | Доля строк в дочерних таблицах, ссылающихся на несуществующие записи в родительских. | Случайное угадывание |
Сохранение уникальности ключей (PK Uniqueness Rate) | Доля уникальных значений в столбцах первичных ключей. | Минимальное расхождение |
Ключевая трудность при качественной генерации синтетических данных заключается в частых ошибочных срабатываниях систем обнаружения персональной информации в тестовых средах – это прямое следствие необходимости сбалансировать функциональную ценность выходных данных и требования к конфиденциальности. Основная цель фреймворка – выстроить такую оптимальную точку пересечения кривых «информационная полезность ↔ защита приватности», которая одновременно обеспечивает высокое качество моделей и отвечает корпоративным политикам безопасности.
На четвертой стадии – после прохождения всех процедур верификации, происходит ввод синтетических наборов в эксплуатацию. В этом контексте ключевую роль играет присвоение специальной маркировки на уровне метаданных: каждая единица данных получает ярлык, однозначно указывающий на её искусственное происхождение. Такая система тегирования позволяет настроить инструменты защиты (DLP, SIEM и иные средства мониторинга) таким образом, чтобы они автоматически игнорировали события, связанные с отмеченными синтетическими репликами. В результате достигается устранение ложных положительных тревог без приостановки процессов тестирования и разработки [3; 10, с. 195-207; 11]. Схематическое изображение данного механизма представлено на рисунке 2.
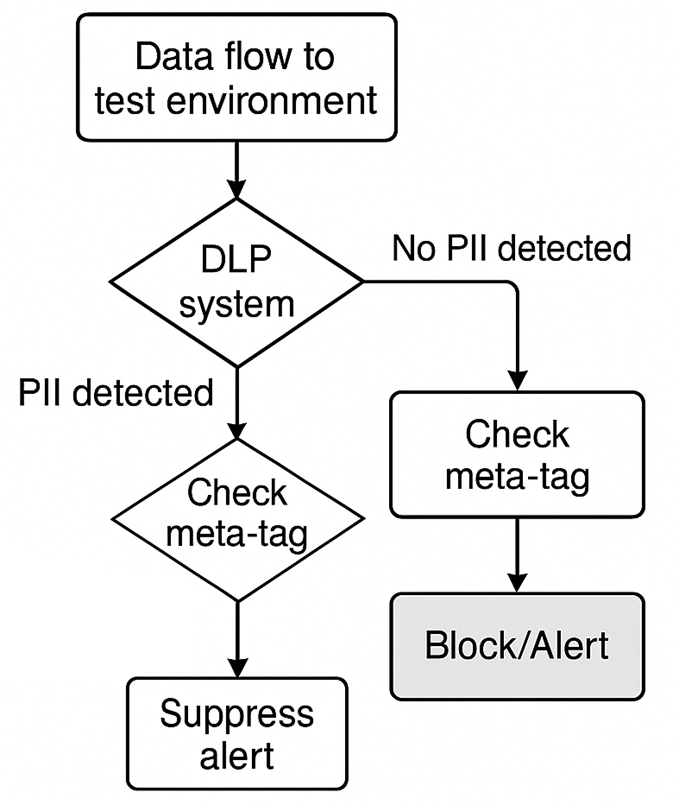
Рис. 2. Схема обработки данных в тестовой среде с маркировкой (составлено автором на основе анализа [3; 10, с. 195-207; 11])
Изложенная методика базируется на генерации синтетических массивов данных, обладающих высоким качеством и статистической инвариантностью в отношении реальных образцов, при этом полностью устраняются операционные барьеры. В данном контексте внимание акцентируется не на вопросе подлинности данных, а на их допустимости и соответствию нормативным и техническим требованиям среды, в которой они используются. Предложенный фреймворк объединяет в себе не только алгоритмические подходы к генерации и валидации синтетических данных, но и комплекс организационно-технических мер: от многоуровневого управления доступом до встроенного аудита и мониторинга, что обеспечивает их безопасную и эффективную интеграцию в жизненный цикл корпоративных IT-продуктов. Таким образом, организационно-технический конструкт вносит значимый вклад в решение проблемы сбалансированного сочетания конфиденциальности, соответствия нормативным требованиям и эксплуатационной эффективности.
Заключение
Проведённый анализ позволил упорядочить и осмыслить существующие методологии обеспечения конфиденциальности при внедрении генеративных моделей в корпоративной среде. В ходе работы было выявлено, что, несмотря на заметный прогресс в создании синтетических выборок с применением GAN и трансформерных сетей, а также в адаптации механизмов дифференциальной приватности, сохраняются сложности: генерация семантически связанных реляционных структур, согласование критериев полезности и приватности и эксплуатационные барьеры при различении высококачественного синтетического и реального контента.
Для устранения обнаруженных недостатков предложен четырёхступенчатый фреймворк, охватывающий полный жизненный цикл работы с синтетическими данными: от первичного анализа реальных наборов до их контролируемого развёртывания в тестовых и предэксплуатационных средах.
Тем самым достигается основная цель исследования. Гипотеза о том, что многоуровневая верификация является ключевым фактором безопасной имплементации технологии, получила подтверждение. Практическая значимость работы заключается в том, что описанный фреймворк может быть использован IT-департаментами и службами информационной безопасности для формирования внутренних стандартов и регламентов, что способствует снижению рисков утечки информации и повышению эффективности процессов разработки.
