.png&w=384&q=75)
1. Введение
В настоящее время интернет-боты стали неотъемлемой частью повседневной жизни человека. По некоторым оценкам, более 42% трафика в сети Интернет генерируется ботами [2, с. 5].
С одной стороны, боты очень полезны: они помогают улучшить индексацию в браузерах, обеспечить вовлеченность клиентов, а также масштабировать операции. Однако, с другой стороны, их часто используют с целью мошенничества, причинения вреда конечным пользователям или организациям в целом.
В связи с этим, весьма актуальной является задача отделения ботов от реальных людей, чтобы затруднить вредоносным ботам доступ к данным пользователей. Раньше это было довольно простой задачей, ведь боты, в отличие от пользователей, не могут использовать мышь и клавиатуру. Однако с появлением браузеров, работающих в headless-режиме, боты получили возможность взаимодействовать с веб-страницей точно так же, как и обычный пользователь.
1.1. Постановка задачи
Даны сессии пользователей веб-сайта, часть из которых – реальные люди, а часть – боты. Каждая сессия представляет собой список событий, совершённых пользователем (например, клик мышкой, перемещение мышки, прокрутка колёсика мышки), а также время этого события и его место (координата пикселя на экране на момент начала события).
Для каждой из данных сессий уже известно, какому пользователю она соответствует. Необходимо обучить ML-модель, которая для каждой новой сессии будет с хорошей точностью (не менее 75%) определять, какому пользователю она соответствует.
1.2. Этапы решения поставленной задачи
- Выбор и описание датасета.
- Исследование датасета и выбор фичей.
- Выбор метода обучения, подбор параметров и обучение модели.
- Оценка точности полученной модели.
2. Текущие методы обнаружения и их ограничения
3. Методология
3.1. Выбор датасета
Существует три основных способа получить датасет (обучающую выборку) для решения данной задачи:
- Собрать датасет вручную (записать все события из сессий достаточно большого количества пользователей и ботов) – требует большого количества временных и материальных ресурсов;
- Проэмулировать его с помощью специальной программы Bezmouse [4] – но тогда есть большой риск, что настоящие пользователи и боты будут вести себя иначе, и обученная модель окажется нерелевантной;
- Взять готовый датасет из базы – представляется наиболее оптимальным в условиях ограниченности ресурсов.
Таким образом, было принято решение взять датасет «Mouse dynamics» [3], который содержит по 6 сессий для каждого из 20 пользователей, часть из которых – боты, а часть – реальные люди.
3.2. Описание датасета «Mouse dynamics»
Датасет состоит из двух частей – обучающей и тестовой. Обучающая часть содержит почти 12 тысяч событий из 120 пользовательских сессий – по 6 сессий для каждого из 20 пользователей, а тестовая – около 4 тысяч событий из 40 сессий.
Обучающий датасет содержит 7 полей:
- uid – ID события, все uid в датасете различны;
- session_id – ID сессии, все session_id для различных сессий различны;
- user_id – ID пользователя, все user_id для различных пользователей различны;
- timestamp – время (с точностью до миллисекунды), когда произошло событие;
- event_type – тип события: 1 – отпустить клавишу мышки (release), 2 – передвинуть мышку с отпущенной клавишей (move), 3 – покрутить колёсико мышки (wheel), 4 – передвинуть мышку с нажатой клавишей (drag), 5 – нажать клавишу мышки (click);
- screen_x и screen_y – координаты (в пикселях) места, где зафиксировано событие.
Тестовый датасет содержит 6 полей – всё, кроме user_id (ведь его необходимо определить).
На рисунке 1 приведён фрагмент обучающего датасета.
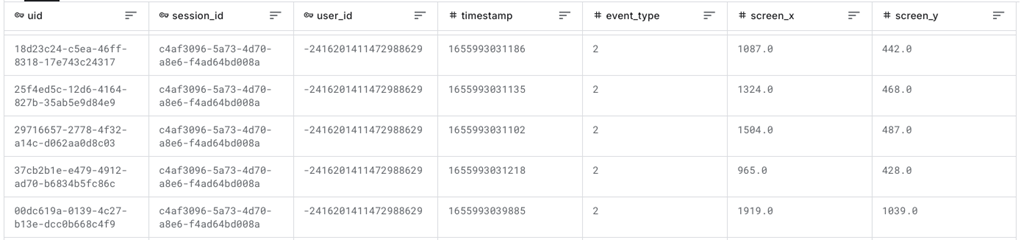
Рис. 1. Фрагмент обучающего датасета «Mouse dynamics»
3.3. Исследование датасета
Из пункта 1 видно, что данных, описывающих поведение пользователя, немного: временная метка, код события и координаты пикселя на экране. Визуализируем эти данные, чтобы понять, чем может отличаться поведение различных пользователей.
Начнём с отображения траектории движения мышки по монитору. Временные промежутки между событиями при этом игнорируются – соблюдается лишь их порядок – а различные события (вернее, различные переходы между событиями) обозначаются разными цветами.
Примеры траекторий для трёх сессий различных пользователей приведены соответственно на рисунках 2 а), б) и в).
Из этих примеров видно, что:
- сессии могут сильно отличаться по количеству событий;
- события могут начинаться с абсолютно разных частей экрана;
- некоторые пользователи совершают события ближе к центру экрана, а некоторые – ближе к одному из его углов;
- у некоторых пользователей движения более размашистые (что приводит к появлению угловатых траекторий), а у некоторых – более плавные (и траектории, соответственно, также более округлые).
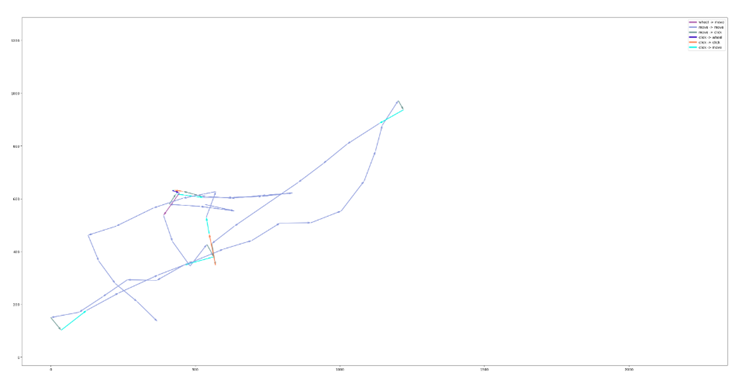
Рис. 2. Траектории мышки а)
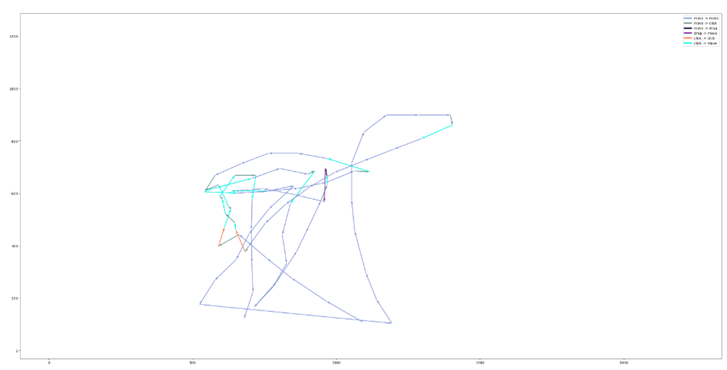
Рис. 2. Траектории мышки б)
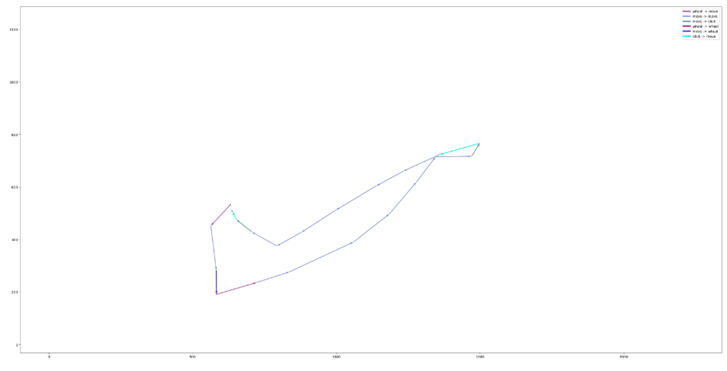
Рис. 2. Траектории мышки в)
Теперь нужно визуализировать временные метки (timestamps). Для этого разные цвета уже не нужны (в отличие от координат, время – это одно измерение), а код события можно отображать по оси Y; по оси X же будет идти время.
На рисунке 3 приведена визуализация таймлайнов двух сессий различных пользователей.
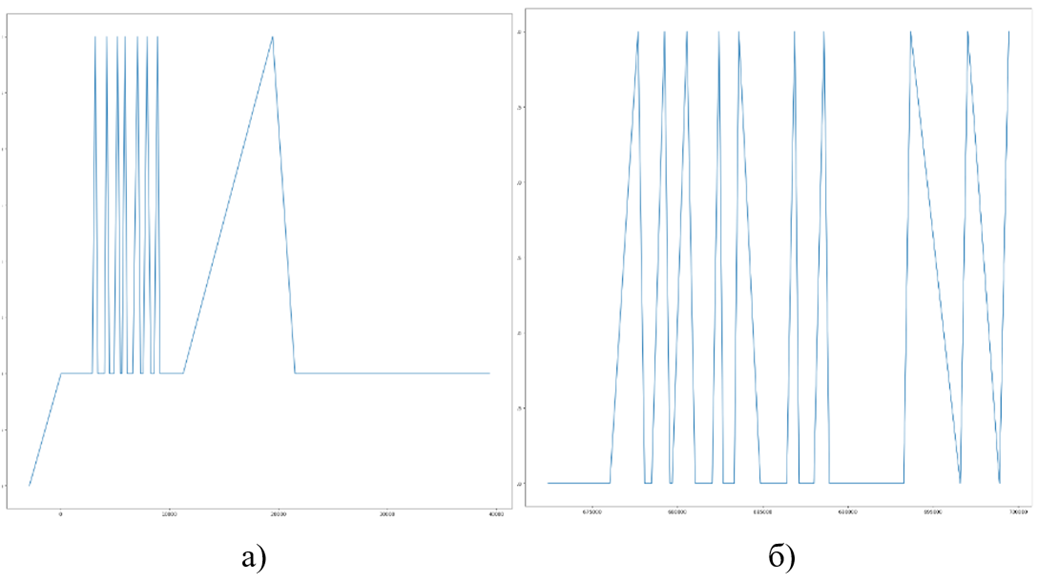
Рис. 3. Таймлайны событий для двух сессий различных пользователей
Из этих примеров видно, что:
- У различных пользователей может быть абсолютно разная частота и равномерность событий;
- В промежутках между результативными событиями пользователи могут как отпускать мышку, так и постоянно двигать её.
3.4. Выбор фичей
Исходя из рассмотренных примеров, было принято решение взять следующие фичи для обучения модели:
1) Основанные на координатах:
- Координаты средней точки экрана по всем событиям сессии (то есть среднее арифметическое по каждой из координат): center_x, center_y;
- Координаты средней точки экрана по событиям «click» (нажатия клавиши мышки): center_click_x, center_click_y;
- Координаты начальной точки экрана: first_x, first_y.
2) Параметры траектории:
- Радиус окружности, содержащей все точки событий: radius. Показывает, насколько размашисто пользователь водил мышкой по монитору;
- Угол наклона траектории: slope. Показывает, в каком направлении пользователь чаще всего водил мышкой (например, слева направо, с левого нижнего в правый верхний угол и т. д.)
- «Узость» траектории: narrow. Показывает, насколько траектория близка к прямой линии (для «округлых» траекторий значения будут маленькими, а для «протяжённых» – большими).
3) Основанные на скорости движения мышки:
- Минимальная скорость перемещения мышки: stress. Показывает степень стресса пользователя: если это число велико – значит, похоже, он суетится или спешит;
- Максимальная скорость перемещения мышки: chill. Показывает степень расслабленности пользователя: если это число мало – значит, похоже пользователь никуда не торопится.
4) Количественные показатели:
- Общее количество событий: nbpoints. Показывает степень активности пользователя;
- Доля событий каждого из 5 типов: ev1, ev2, ev3, ev4, ev5.
На рисунке 4 приведён фрагмент таблицы с полученными фичами для нескольких сессий (для наглядности, таблица была транспонирована).
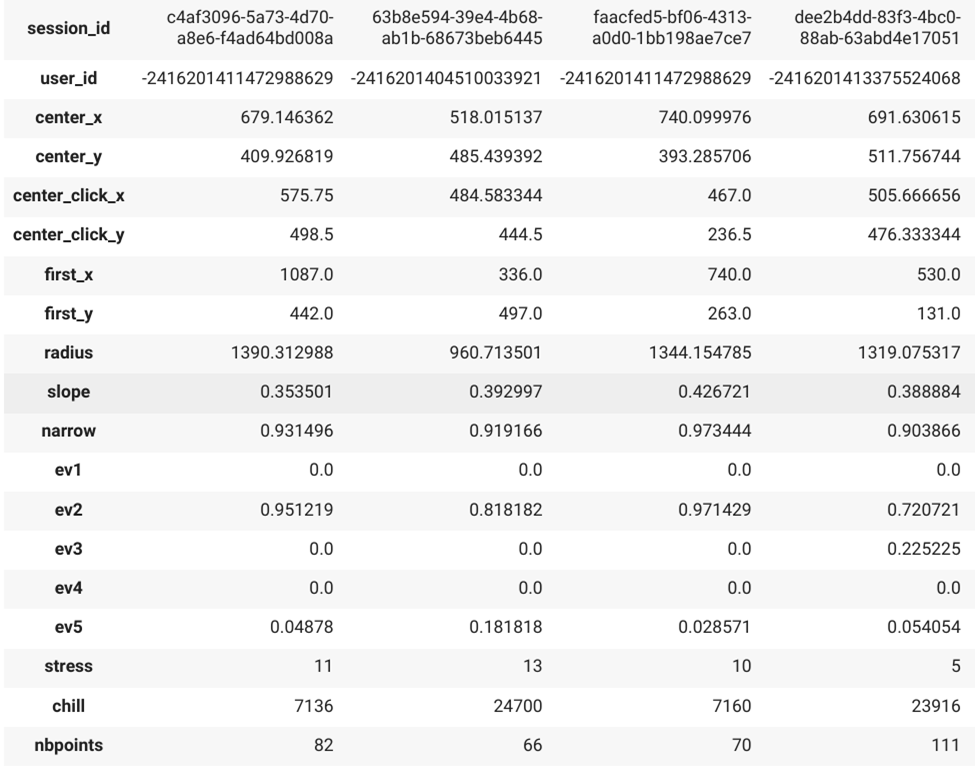
Рис. 4. Фрагмент датасета с фичами
3.5. Выбор метода обучения
Таким образом, в пункте 2.2 мы получили датасет со 120 строками (по одной на сессию) и 17 значимыми параметрами (фичами): center_x, center_y, center_click_x, center_click_y, first_x, first_y, radius, slope, narrow, stress, chill, nbpoints, ev1, ev2, ev3, ev4, ev5.
С одной стороны, это очень мало для обучения глубоких нейронных сетей: для них требуется по меньшей мере несколько десятков тысяч объектов. С другой – классические методы, которые хорошо работают с малыми объёмами данных (SVM, kNN), требуют либо хорошей линейной разделимости данных (что в данном случае далеко не гарантируется), либо долгого подбора правильной метрики (для kNN) или правильного ядра (для SVM). Для деревьев решений 120 объектов также маловато, существует большой риск переобучения.
Поэтому было принято решение использовать многослойный персептрон с небольшим количеством слоёв – порядка 3-4. Это решает все проблемы: и не требует линейной разделимости, и минимизирует риск переобучения, и существенно облегчает перебор параметров.
3.6. Подбор параметров и обучение модели
Для обучения любой ML-модели сначала необходимо, во-первых, нормализовать датасет, а во-вторых – разбить его на собственно обучающую и псевдо-тестовую выборки (в отличие от тестовой, для псевдо-тестовой выборки известен правильный результат).
Нормализация заключается в масштабировании значений фичей так, чтобы все значения были от 0 до 1, причём наименьшее из них было равно 0, а наибольшее – 1. Это необходимо для того, чтобы все фичи для модели имели одинаковый вес.
Разбиение на собственно обучающую и псевдо-тестовую выборки необходимо для оценки точности модели в процессе её обучения, что, в свою очередь, требуется для оптимизации параметров этой модели. При этом в каждой из выборок количество сессий для каждого пользователя должно быть примерно одинаковым, иначе модель обучится на одних пользователях хуже, чем на других.
На рисунке 5 приведены фрагменты собственно обучающей и псевдо-тестовой выборки после нормализации (таблицы транспонированы для наглядности).
Поскольку с моделью мы уже определились, необходимо определиться с количеством слоёв в модели и с количеством нейронов в каждом из промежуточных слоёв (количество нейронов в первом слое многослойного персептрона всегда будет равно количеству фичей, а в последнем – количеству классов).
В результате перебора вариантов лучшее качество показал персептрон со следующими параметрами:
- Количество слоёв: 4;
- Количество нейронов в первом слое: 17 (по количеству фичей);
- Количество нейронов во втором слое: 40;
- Количество нейронов в третьем слое: 30;
- Количество нейронов в четвёртом слое: 20 (по количеству пользователей).
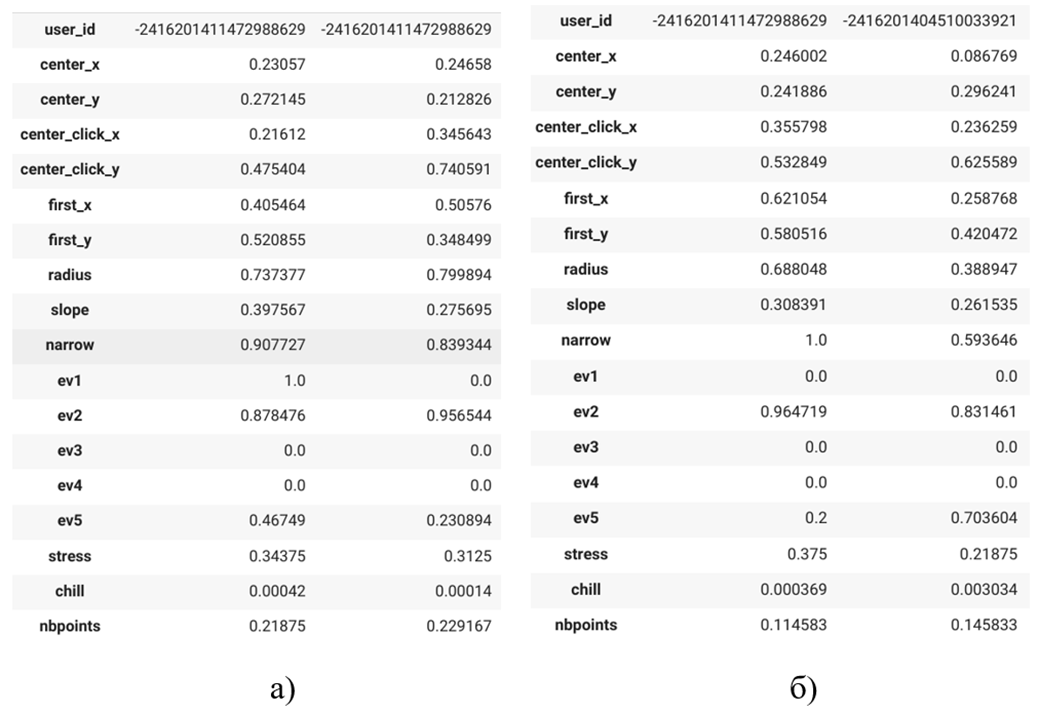
Рис. 5. Фрагменты собственно обучающей (а) и псевдо-тестовой (б) выборок после нормализации и разбиения датасета
Обучение же модели, по сути, состоит из пары строк кода (хоть и занимает 15–20 минут времени):
mlpc=MultilayerPerceptronClassifier(
featuresCol='features', labelCol='user_enc', layers = [17,40,30,20],
maxIter=30000, blockSize=8, seed=7, solver='gd')
ann = mlpc.fit(train_df)
Стоит отметить, что в данной модели задавались и другие параметры, такие как maxIter (количество итераций обучения), blockSize (сколько объектов участвует в обучении модели на каждой итерации), seed (основание генератора случайных чисел – произвольное число, которое нужно лишь для воспроизводимости результата) и solver (метод оптимизации функции). Однако, на наш взгляд, эти параметры не требовали перебора, поскольку были выбраны из общих соображений: например, solver='gd' («стандартный» градиентный спуск) хоть и медленнее, чем оптимизированный 'l-bfgs', но зато значительно точнее, что весьма критично для большого количества итераций, а block_size напрямую зависит от объёма выборки.
4. Оценка точности полученной модели
Теперь оценим точность полученной модели – отдельно на собственно обучающей выборке (результат должен получиться близким к 100%, ведь модель обучалась конкретно на этих данных) и отдельно на псевдо-тестовой (здесь результат должен получиться близким к реальной точности модели).
На рисунке 6 приведена полученная матрица ошибок для собственно обучающей выборки, а на рисунке 7 – матрица ошибок для псевдо-тестовой.
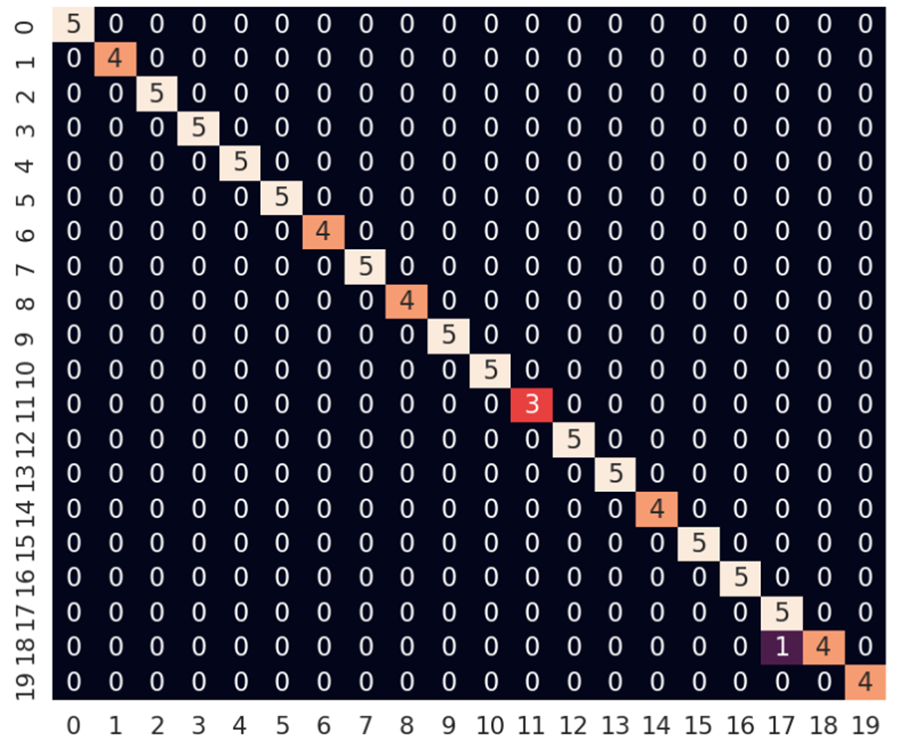
Рис. 6. Матрица ошибок для собственно обучающей выборки
Из рисунка 6 видно, что лишь одна пользовательская сессия из 93 была классифицирована неверно, что даёт точность 0,989 – и в самом деле близко к 100%.
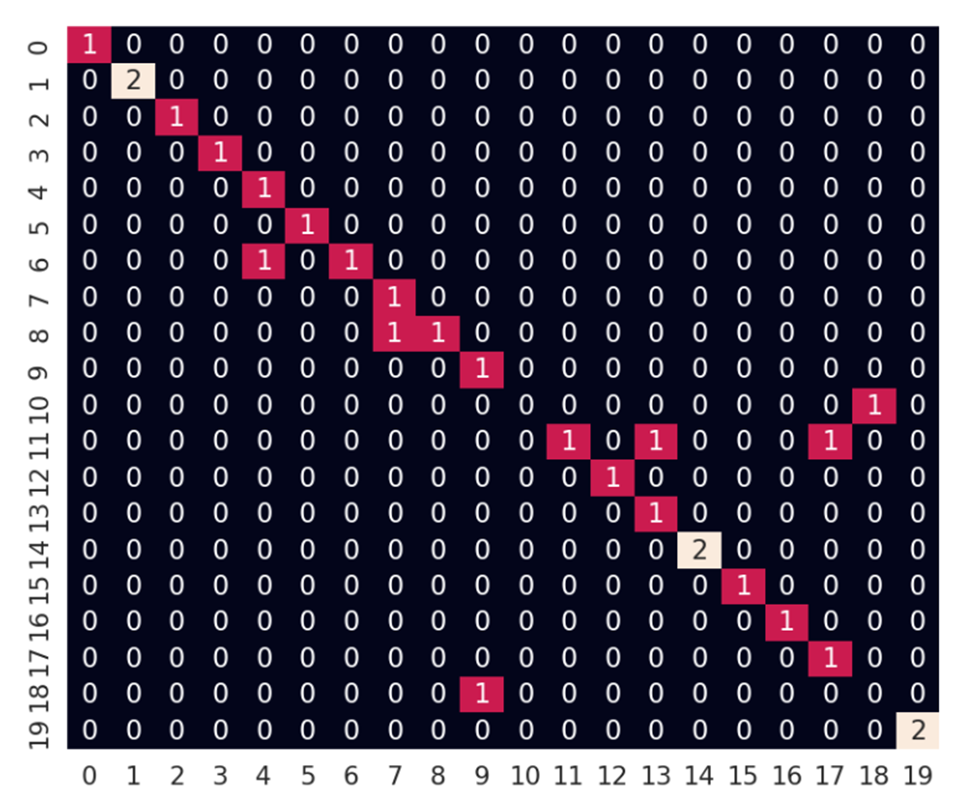
Рис. 7. Матрица ошибок для псевдо-тестовой выборки
Из рисунка 7 же можно видеть, что из 27 пользовательских сессий 5 были классифицированы неверно, что даёт точность 0,759 – больше, чем целевые 75%. Таким образом, поставленная задача была решена.
5. Выводы
В данной статье была рассмотрена и решена задача классификации пользователей по движению мышки на мониторе, что может быть использовано для определения ботов среди пользователей. Была выбрана и обучена модель, показавшая точность классификации 75,9% для 20 пользователей.
Вместе с тем можно достигнуть и более высокой точности модели, если, например:
- Увеличить объём датасета;
- Попробовать бо́льшее количество слоёв в многослойном персептроне (например, 5 или 6);
- Попробовать скомбинировать эту модель с другой (деревьями решений, SVM, kNN...);
- Попробовать добавить другие фичи пользователей (такими как средняя скорость движения мышки, дисперсия времени между соседними событиями и т. д.).
Предложенные пункты могут быть предметом дальнейших исследований.
