.png&w=384&q=75)
1. Введение
Высоконагруженные сервисы – соцсети, маркетплейсы, стрим‑платформы – предъявляют жёсткие требования к backend‑архитектуре. Монолиты при росте пользователей теряют масштабируемость и отказоустойчивость, что ведёт к задержкам и простоям. Микросервисы решают эти проблемы, разбивая приложение на небольшие независимые сервисы, каждый из которых можно разрабатывать, развёртывать и масштабировать отдельно, тем самым сокращая время отклика и локализуя сбои [1, 2]. Однако вместе с преимуществами появляются новые сложности: сетевые накладные расходы, задержки и потребность в зрелых DevOps‑процессах для контейнеризации, оркестрации и мониторинга [4, 5]. Поэтому при проектировании важно сбалансировать модульность с мерами по снижению накладных расходов, обеспечивая производительность, надёжность и сопровождаемость микросервисной системы [2].
2. Постановка задачи
Объект исследования – типовое высоконагруженное веб‑приложение (стриминг или e‑commerce во время пиковых распродаж). В монолите единый процесс становится узким местом, тогда как микросервисы (пользователи, каталог, заказы, рекомендации и т. д.) масштабируются и управляются независимо. Цель – организовать их взаимодействие так, чтобы система надёжно выдерживала большие нагрузки. Ключевые требования:
- Пропускная способность растёт вместе с числом пользователей, а деградация при переполнении ресурсов происходит плавно;
- Отказоустойчивость – сбои изолируются на уровне сервиса и быстро устраняются;
- Горизонтальное масштабирование – лёгкое добавление экземпляров через Kubernetes и аналогичные оркестраторы.
3. Методология
Для достижения поставленных целей был спроектирован бэкенд на основе микросервисов и проведён ряд экспериментов. Методология включает описание архитектуры системы, реализацию механизмов масштабирования и отказоустойчивости, а также подход к тестированию, применённый для оценки производительности системы.
3.1. Архитектура системы
Приложение было рефакторизовано в набор слабо связанных микросервисов, каждый из которых отвечает за определённую функциональность. Взаимодействие сервисов происходит через легковесные RESTful API (HTTP) или посредством асинхронных сообщений, где это необходимо. Такой модульный дизайн соответствует принципам низкой связности и высокой коhezии: каждый сервис фокусируется на своей задаче и взаимодействует с другими через чётко определённые интерфейсы. Данные распределены между сервисами (паттерн «база данных на сервис»), что минимизирует общие точки отказа и позволяет каждому сервису выбирать оптимальную технологию хранения под свои потребности. Развёртывание каждого микросервиса выполнено в виде контейнера (Docker), что обеспечивает единообразие среды выполнения и облегчает переносимость. Оркестрация контейнеров на платформе Kubernetes управляет автоматическим развёртыванием, масштабированием и мониторингом большого числа сервисов [3, с. 195-216].
3.2. Меры обеспечения отказоустойчивости
Критичной частью методологии стало обеспечение способности системы переносить сбои сервисов и быстро восстанавливаться. В систему внедрён ряд паттернов и практик, повышающих отказоустойчивость микросервисов [7, 9]:
- Размыкатель цепи (Circuit Breaker). Этот механизм предотвращает длительное зависание запросов при недоступности зависимого сервиса. При серии неудачных попыток обращения к удалённому сервису дальнейшие запросы блокируются на короткое время, позволяя системе быстро получать ошибку вместо ожидания таймаута.
- Переборка (Bulkhead). Ресурсы, такие как потоки или подключения к базе данных, изолируются для каждого сервиса. Благодаря этому сбой или утечка ресурсов в одном сервисе не приводят к остановке других, что локализует влияние отказов.
- Автоматическое восстановление. Сервисы развёрнуты в контейнерах под управлением оркестратора, который при сбое автоматически перезапускает упавший контейнер. Kubernetes следит за здоровьем подов и при обнаружении падения экземпляра сервиса автоматически запускает новый, минимизируя время простоя.
- Резервирование экземпляров. Для критически важных сервисов изначально запущено по крайней мере 2 экземпляра, работающих одновременно. Если один экземпляр выходит из строя, оставшийся продолжает обслуживать запросы, пока оркестратор не перезапустит упавший экземпляр. Эта избыточность позволяет системе пережить единичный отказ без заметного для пользователей перерыва.
Перечисленные меры значительно повысили устойчивость системы к отказам, что подтверждено результатами экспериментов. Например, если вероятность отказа одного экземпляра сервиса составляет p = 0,01 (1% в заданном интервале), то при наличии N = 2 экземпляров вероятность полной недоступности сервиса составит (0,01%). При N = 3 она снижается до (0,0001%), и т. д. Таким образом, добавление резервных экземпляров экспоненциально снижает вероятность одновременного отказа всех копий сервиса. Формально вероятность полного отказа при N резервируемых экземплярах равна:
![]() , (1)
, (1)
Где p – вероятность отказа одного экземпляра, N – число экземпляров сервиса.
3.3. Методика тестирования производительности
Было проведено систематическое нагрузочное тестирование для оценки работы микросервисного бэкенда при увеличении числа пользователей. Генератор нагрузки имитировал одновременных пользователей, отправляющих запросы через API-шлюз системы. В каждом прогоне теста заданное число виртуальных пользователей (потоков) непрерывно посылало запросы (смесь операций чтения и записи, распределённых между различными сервисами) в течение времени, достаточного для достижения стационарного режима. Число одновременных пользователей увеличивали ступенчато (100, 200, 300, … до 1000), и измеряли два основных показателя: (a) среднее время отклика – среднее время, затрачиваемое на обработку одного запроса (с точки зрения пользователя), и (b) пропускная способность – число запросов, обрабатываемых системой в секунду. Пропускная способность T рассчитывается как общее число выполненных запросов, делённое на длительность теста (в секундах), согласно формуле (2):
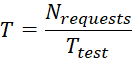 , (2)
, (2)
Где ![]() – общее число запросов, выполненных за интервал тестирования;
– общее число запросов, выполненных за интервал тестирования; ![]() – длительность тестового прогона. Этот показатель отражает ёмкость системы. Также в ходе испытаний мониторились ресурсы (CPU, память) на каждом экземпляре сервиса, чтобы соотнести потребление ресурсов с показателями производительности.
– длительность тестового прогона. Этот показатель отражает ёмкость системы. Также в ходе испытаний мониторились ресурсы (CPU, память) на каждом экземпляре сервиса, чтобы соотнести потребление ресурсов с показателями производительности.
Для оценки отказоустойчивости в ходе части нагрузочных тестов проводилась инъекция сбоев. В определённый момент времени при пиковой нагрузке принудительно завершалась работа одного из экземпляров работающего сервиса (например, «убивался» один контейнер сервиса каталога товаров), после чего отслеживалось влияние на систему. Замерялось время восстановления – промежуток от возникновения сбоя до полного восстановления нормальной работы (то есть появления нового экземпляра и возврата производительности к базовому уровню). Сравнивались сценарии с резервированием и без: при отсутствии резервирования (единственный экземпляр сервиса) отказ приводил к полной потере этого сервиса до перезапуска; при наличии резервирования (два экземпляра) сервис оставался частично доступен во время восстановления. Эксперимент позволил оценить, насколько быстро Kubernetes обнаруживает отказ и запускает замену, а также как система перенаправляет запросы в переходный период. Для оценки горизонтальной масштабируемости система изначально развернулась в базовой конфигурации (по 1 экземпляру каждого микросервиса), после чего число экземпляров выбранных сервисов постепенно увеличивалось. Например, количество экземпляров сервисов обработки заказов и рекомендаций последовательно увеличивали от 1 до 2, 4 и 8 на фоне постоянной высокой нагрузки, и фиксировали полученную пропускную способность. В идеале удвоение числа экземпляров должно приводить к удвоению пропускной способности при отсутствии других узких мест (линейное масштабирование). Однако в реальности из-за сетевых накладных расходов и координации между сервисами ожидается снижение эффективности при добавлении большого числа экземпляров.
4. Результаты и обсуждение
В данном разделе представлены результаты проведённых экспериментов и их анализ с точки зрения разработки масштабируемых микросервисных бэкендов. Обсуждение разделено на три аспекта: производительность под нагрузкой, поведение системы при сбоях и горизонтальная масштабируемость.
4.1. Результаты нагрузочного тестирования
Микросервисная система была подвергнута постепенно возрастающей нагрузке для наблюдения за масштабированием производительности. Зависимость среднего времени отклика от числа одновременных пользователей показана на рисунке 1. Изначально при 100 одновременных пользователях время отклика было очень небольшим (порядка нескольких десятков миллисекунд). С ростом нагрузки время отклика увеличивалось умеренно до определённого момента – например, при 400 пользователях средняя задержка составила около 80 мс – что указывает на способность системы обрабатывать такую нагрузку с минимальной задержкой. Однако при превышении ~500 одновременных пользователей наблюдался более резкий рост времени отклика. При 800–1000 пользователях среднее время отклика достигло нескольких сотен миллисекунд и превышало 1 с. Этот экспоненциальный рост задержки при нагрузке выше определённого порога является признаком достижения системой предела своей пропускной способности, когда дополнительная нагрузка в основном увеличивает время ожидания запросов в очереди, а не обрабатывается немедленно.
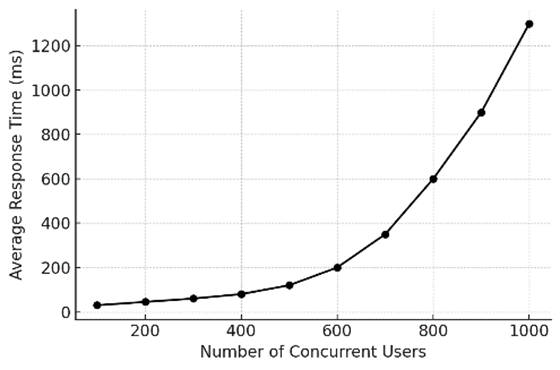
Рис. 1. Зависимость среднего времени отклика от числа одновременных пользователей
Соответственно, пропускная способность (количество выполненных запросов в секунду) возрастает с ростом числа пользователей, пока не выходит на плато при достижении максимальной ёмкости системы. На рисунке 2 показана пропускная способность при различных уровнях одновременных запросов. Наблюдается примерно линейное увеличение throughput с 100 до 500 одновременных пользователей: например, 100 пользователей дают ~100 запросов/с, 300 пользователей ~300 запросов/с, а 500 пользователей ~500 запросов/с. Это означает, что до ~500 пользователей система масштабировалась почти линейно – каждый новый пользователь мог обслуживаться с примерно той же эффективностью. Пропускная способность достигла пика около 500 запросов/с в нашем сценарии. Увеличение числа пользователей сверх этого не приводило к росту throughput; напротив, при 800–1000 пользователях пропускная способность слегка снизилась (с ~500 до ~460 запросов/с при 1000 пользователях). Это небольшое снижение связано с тем, что перегруженная система тратит больше времени на переключение контекста и управление очередями, а некоторые запросы могут не успевать выполниться (таймаут) или отбрасываться, уменьшая общее число завершённых транзакций. Плато около 500 запросов/с отражает предел ёмкости системы при фиксированных ресурсах (и фиксированном числе экземпляров сервисов) в данном тесте. Практически это означает, что один или несколько микросервисов (либо общий ресурс, такой как база данных) стали узким местом при данной нагрузке, ограничив дальнейший рост throughput. Эта картина согласуется с теорией массового обслуживания: поначалу пропускная способность растёт с увеличением нагрузки, но после насыщения дополнительная нагрузка лишь увеличивает задержки (как показано на рисунке 1) без повышения числа обслуженных запросов.
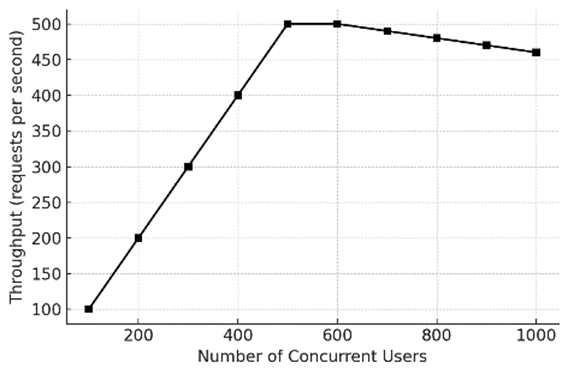
Рис. 2. Зависимость пропускной способности от числа одновременных пользователей
Полученные результаты сведены на рисунке 3, где приведены измеренные средние времена отклика и пропускная способность для выбранных значений нагрузки. Видно, что скачок времени отклика между 500 и 600 пользователями значителен (с 120 мс до 200 мс), несмотря на отсутствие роста пропускной способности, что сигнализирует о начале перегрузки (накопления очередей). К 1000 пользователям время отклика существенно возрастает, тогда как пропускная способность немного ниже пикового значения, подчёркивая, что система была нагружена сверх оптимальной точки.
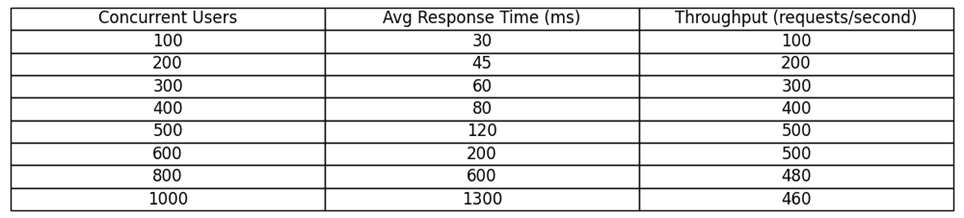
Рис. 3. Результаты нагрузочного тестирования (имитационная модель)
Отметим, что аналогичные эффекты (линейный рост производительности до насыщения и резкое увеличение задержек при перегрузке) наблюдаются и в других исследованиях производительности микросервисных систем. Это подтверждает общую тенденцию: система на основе микросервисов способна эффективно масштабироваться до тех пор, пока не будет достигнут предел по какому-либо ресурсу, после чего дальнейший рост нагрузки приводит преимущественно к увеличению задержек.
4.2. Отказоустойчивость и восстановление после сбоев
Для оценки отказоустойчивости в систему вводились искусственные сбои, и анализировалось её поведение. Как описано в методике, во время нагрузочного теста принудительно завершалась работа одного экземпляра сервиса, чтобы сымитировать его неожиданное падение. Сравнивались два сценария: (a) сервис имел только один экземпляр (без резервирования); (b) сервис имел два экземпляра, работающих параллельно за балансировщиком (активно-активное резервирование). Разница результатов оказалась существенной. В случае единственного экземпляра кратковременный отказ сервиса приводил к полной недоступности соответствующей функциональности до тех пор, пока Kubernetes не перезапустил контейнер. В нашем эксперименте система оркестрации обнаружила отказ и запустила новый экземпляр примерно за 10 с. В течение этих ~10 с все запросы, адресованные этому сервису, завершались с ошибкой (либо находились в очереди и впоследствии истекали по таймауту). В противоположность этому, в сценарии с двумя экземплярами при отключении одного из них пользовательские запросы автоматически перераспределялись на уцелевший экземпляр. Это означало, что сервис продолжал функционировать (хоть и с половинной мощностью) в период восстановления. После запуска нового экземпляра (через те же ~10 с) полная мощность сервиса восстанавливалась. С точки зрения клиента влияние сбоя проявилось лишь как кратковременное замедление или небольшое увеличение задержки, если его запрос пришёлся на момент переключения; многие пользователи вообще могли не заметить никакого сбоя.
На рисунке 4 показано измеренное время недоступности сервиса (downtime) в каждом сценарии. При одном экземпляре фактический простой составил ~10 с (все запросы в этот интервал были потеряны). При двух экземплярах эффективный простой практически равен 0 – сервис оставался доступным, пока работал хотя бы один экземпляр. Мы зафиксировали время переключения около 1 с в сценарии с резервированием, что соответствует интервалу, необходимому балансировщику нагрузки (и клиентским библиотекам) для обнаружения сбоя и перенаправления трафика на уцелевший экземпляр. Таким образом, добавление второго экземпляра практически устранило простой, вызванный отказом отдельного сервиса.
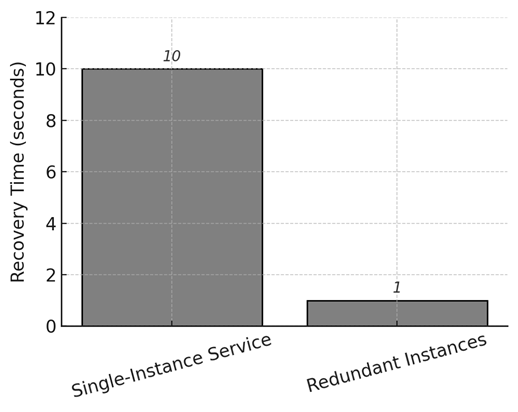
Рис. 4. Время недоступности сервиса после отказа: без резервирования (1 экземпляр) и с резервированием (2 экземпляра)
Данный эксперимент наглядно демонстрирует высокую отказоустойчивость микросервисной архитектуры при использовании резервирования и оркестрации контейнеров. Даже при отказе одного из компонентов система продолжила предоставлять основные функции, чего невозможно добиться в монолитной архитектуре, где сбой модуля приводит к простою всего приложения.
4.3. Горизонтальная масштабируемость и использование ресурсов
Возможность масштабирования системы за счёт добавления экземпляров сервисов является ключевым преимуществом микросервисного подхода в облачной среде. Мы оценили эффективность горизонтального масштабирования, последовательно увеличивая число экземпляров отдельных микросервисов под высокой нагрузкой. Исходная конфигурация включала по 1 экземпляру каждого сервиса; затем количество экземпляров наиболее нагруженных сервисов (например, обработки заказов и рекомендаций) удваивалось: 2, 4 и 8 экземпляров, при постоянно высокой интенсивности запросов. Для каждого шага измерялась суммарная пропускная способность системы. В идеальном случае удвоение числа экземпляров привело бы к удвоению общей пропускной способности при отсутствии других узких мест (линейное масштабирование). На практике же из-за накладных расходов на межсервисное взаимодействие и координацию между узлами кластера эффективность использования дополнительных экземпляров постепенно снижается.
Результаты эксперимента представлены на рисунке 5, где сравнивается измеренная пропускная способность с идеальным линейным масштабированием. Начиная с 1 экземпляра на сервис (пропускная способность условно принята за 100%), увеличение до 2 экземпляров привело к росту throughput примерно до 190% от базового уровня, до 4 экземпляров – до ~360%, и до 8 экземпляров – около 680%. Иными словами, масштабирование было близким к линейному до ~4 экземпляров на сервис; дальнейший рост (с 4 до 8) дал прирост ниже идеального – сказывались возросшие накладные расходы и, возможно, ограниченные ресурсы, общие для всех сервисов (например, база данных или пропускная способность сети). Тем не менее при 8 экземплярах суммарная пропускная способность более чем в 6,8 раз превысила базовый уровень (1 экземпляр), что значительно улучшило производительность системы. На графике идеальная линейная зависимость показана штриховой линией для сравнения. Таким образом, система продемонстрировала высокую эффективность горизонтального масштабирования, хотя и не идеальную: это совпадает с ожидаемыми закономерностями (например, законом Амдала), согласно которым при добавлении ресурсов прирост производительности постепенно приближается к пределу ниже теоретически возможного.
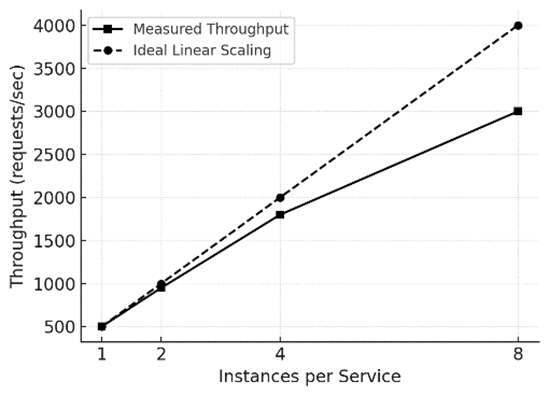
Рис. 5. Масштабирование пропускной способности при увеличении числа экземпляров сервисов (сравнение с идеальной линейной зависимостью)
Помимо throughput, отслеживалось распределение нагрузки по CPU и памяти между экземплярами, чтобы убедиться, что оркестратор балансирует нагрузку равномерно. В ходе эксперимента узких мест по ресурсам внутри узлов кластера не выявлено – нагрузка распределялась относительно равномерно. Таким образом, добавление экземпляров сервисов эффективно повышает производительность системы до определённого предела, после чего влияние ограничивающих факторов становится заметным.
Примечание. В реальных условиях с непостоянным и непредсказуемым трафиком эффективность масштабирования может проявляться менее предсказуемо. Поэтому для промышленных систем рекомендуется применять практики типа chaos engineering (умышленное внесение сбоев в рабочую среду для проверки устойчивости) и регулярное нагрузочное тестирование в промежуточной среде, чтобы непрерывно подтверждать надёжность и масштабируемость системы [10].
5. Заключение
В данной работе исследована разработка масштабируемого распределённого бэкенда на основе микросервисов для высоконагруженных условий. Работа актуальна потребностью обеспечивать обслуживание большого числа пользователей с приемлемой производительностью и надёжностью. Экспериментально подтверждено, что микросервисная архитектура при правильной организации масштабирования и отказоустойчивости способна удовлетворить требованиям высоконагруженных систем. Нагрузочное тестирование показало почти линейный рост пропускной способности по мере увеличения нагрузки до наступления ограничения по ресурсам, при этом низкое время отклика сохранялось до точки насыщения. Реализация механизмов отказоустойчивости (резервирование экземпляров, автоматический перезапуск контейнеров и т. д.) свела к минимуму простой при сбоях: система продолжала работу даже при отказе отдельных сервисов, обеспечивая восстановление в течение секунд. Горизонтальное масштабирование сервисов с помощью оркестрации контейнеров (Kubernetes) значительно повысило производительность системы, хотя при большом числе экземпляров эффект масштабирования несколько снизился из-за сетевых и координационных накладных расходов. Достигнутая производительность существенно превосходит возможности эквивалентной монолитной системы, что подтверждает преимущества микросервисного подхода в данных условиях [6, с. 51-59; 8, с. 437-442]. Таким образом, разработанная микросервисная бэкенд-система удовлетворяет предъявленным требованиям по масштабируемости и отказоустойчивости в высоконагруженной среде. Полученные результаты согласуются с выводами других исследований в области высоконагруженных микросервисных систем [6, с. 51-59; 8, с. 437-442] и обобщают лучшие практики создания подобных систем. В перспективе данное исследование может быть расширено анализом обеспечения согласованности данных между сервисами и оптимизации межсервисных взаимодействий, а также внедрением методик непрерывной доставки и мониторинга для дальнейшего повышения надёжности системы.
