.png&w=384&q=75)
Введение
В эпоху цифровой экономики сбор и анализ данных с веб-сайтов (веб-скрапинг) играет ключевую роль во многих областях, включая маркетинговые исследования, мониторинг цен, научные изыскания и агрегацию контента. Однако современные веб-ресурсы все чаще применяют сложные технологии для отображения информации и защиты от автоматизированного доступа. К таким технологиям относятся динамическая загрузка контента с помощью JavaScript, а также различные системы защиты от ботов. Отсутствие публичного API (Application Programming Interface) у многих коммерческих сайтов, таких как dns-shop.ru, дополнительно усложняет задачу автоматизированного сбора данных, вынуждая разработчиков прибегать к созданию специализированных парсеров.
Целью данной работы является разработка программного средства, способного эффективно извлекать информацию о товарах с веб-сайта dns-shop.ru, преодолевая такие препятствия, как динамическая загрузка данных и специфические механизмы защиты, в частности использование cookie-параметра qrator_jsid.
Объекты и методы исследования
Объектом исследования является веб-сайт крупной российской сети по продаже цифровой и бытовой техники dns-shop.ru, характеризующийся динамической подгрузкой каталога товаров и отдельных страниц продуктов, а также использованием системы защиты от автоматизированных запросов.
Для достижения поставленной цели был разработан парсер на языке программирования Python с использованием следующих ключевых библиотек и технологий:
- Selenium WebDriver: Применялся для эмуляции действий пользователя в браузере (Google Chrome) с целью получения первоначальных сессионных данных, необходимых для обхода защиты. В частности, для получения валидного cookie-параметра qrator_jsid, который генерируется на стороне клиента после выполнения JavaScript-кода. Были использованы опции для отключения загрузки изображений (--blink-settings=imagesEnabled=false) и сокрытия факта управления браузером автоматизированным ПО (--disable-blink-features=AutomationControlled, Page.addScriptToEvaluateOnNewDocument).
- Requests: Высокоуровневая HTTP-библиотека, использовалась для выполнения последующих GET-запросов к серверу сайта с уже полученным qrator_jsid и другими необходимыми заголовками (например, User-Agent, генерируемый fake_useragent, и x-requested-with). Это позволило значительно ускорить процесс сбора данных по сравнению с постоянным использованием Selenium.
- BeautifulSoup4: Библиотека для парсинга HTML и XML документов. Применялась для извлечения идентификаторов товаров (GUID) и общего количества товаров в категории из HTML-разметки страниц каталога.
- JSON: Стандартный формат обмена данными, использовался для структурированного сохранения собранной информации о товарах.
- Logging: Стандартный модуль Python для ведения журнала событий, обеспечивающий отслеживание процесса работы парсера и диагностику возможных ошибок.
Алгоритм работы парсера включает следующие основные этапы [1, с. 85]:
1) Инициализация и настройка Selenium WebDriver [2].
2) Переход на главную страницу dns-shop.ru для получения и сохранения cookie qrator_jsid и времени его истечения.
3) Определение общего количества товаров в целевой категории (get_product_count) и расчет необходимого количества страниц для обхода.
4) Последовательный обход страниц каталога:
- Формирование запроса к странице каталога с указанием номера страницы (get_product_guids) с использованием библиотеки requests и полученного qrator_jsid.
- Извлечение GUID (Globally Unique Identifier) каждого товара на странице с помощью BeautifulSoup [3].
- Проверка актуальности qrator_jsid перед каждым запросом данных о товаре; при необходимости – обновление через Selenium.
- Для каждого GUID формирование запроса к API-подобной конечной точке сайта (/pwa/pwa/get-product/) для получения полной информации о товаре в формате JSON (get_product).
- Добавление полученных данных о товаре в общий список.
5) Сохранение собранного списка данных о товарах в файл формата JSON (save).
6) Завершение работы WebDriver.
Результаты и их обсуждение
Разработанное программное средство было успешно протестировано на примере сбора данных о товарах с сайта dns-shop.ru. Ключевой проблемой, решенной в ходе работы, стало преодоление системы защиты, основанной на cookie qrator_jsid. Использование Selenium на начальном этапе для имитации легитимного пользователя позволило получить данный cookie, после чего основная масса запросов выполнялась более легковесной библиотекой requests. Это обеспечило как обход защиты, так и приемлемую скорость сбора данных.
Проблема динамической загрузки контента была решена следующим образом [4, с. 100]:
- Для получения qrator_jsid Selenium ожидает полной загрузки страницы и выполнения всех скриптов (WebDriverWait).
- Для получения списка товаров на страницах каталога (get_product_guids) и информации о количестве товаров (get_product_count) используется requests для загрузки HTML-содержимого, которое затем парсится с помощью BeautifulSoup. Хотя часть контента может подгружаться динамически, ключевые элементы, содержащие идентификаторы товаров и их общее число, присутствуют в исходном HTML-ответе сервера при корректно сформированном запросе (включая qrator_jsid и city_path).
- Информация о конкретном товаре (get_product) извлекается путем прямого обращения к внутренней конечной точке (/pwa/pwa/get-product/), которая возвращает данные в формате JSON. Это является эффективным способом получения структурированных данных без необходимости парсинга сложных HTML-страниц товаров [5].
Парсер продемонстрировал способность собирать данные по заданной категории, корректно обрабатывать пагинацию и обновлять сессионные cookie при их истечении. Результаты работы сохраняются в файле products.json в легко читаемом и обрабатываемом формате (рис.). В процессе работы ведется подробное логирование, что упрощает отладку и мониторинг.
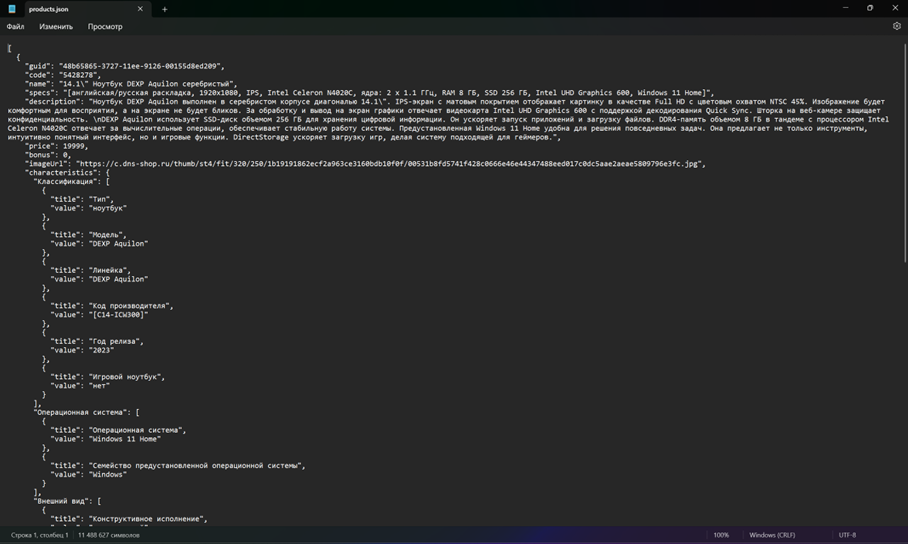
Рис. Результат работы парсера
Таким образом, предложенный подход, комбинирующий Selenium для решения специфических задач аутентификации/обхода защиты и requests/BeautifulSoup для массового сбора данных, оказался эффективным для решения поставленной задачи.
Заключение
В результате проведенной работы было разработано и апробировано программное средство для сбора данных с веб-сайта dns-shop.ru. Реализованный парсер успешно справляется с основными вызовами современного веб-скрапинга, такими как отсутствие публичного API, необходимость обработки динамически загружаемого контента и преодоление защитных механизмов на основе JavaScript и cookie.
Продемонстрирована эффективность комбинированного подхода с использованием Selenium для начальной аутентификации и получения сессионных данных, и последующим применением библиотек requests и BeautifulSoup для непосредственного сбора и парсинга информации. Это позволяет сочетать гибкость и возможности браузерной автоматизации с производительностью прямых HTTP-запросов.
Полученные результаты могут быть использованы для дальнейших исследований в области анализа цен, товарного ассортимента и других аспектов рынка электронной коммерции. Возможные направления развития проекта включают распараллеливание запросов для ускорения сбора больших объемов данных, интеграцию с базами данных для хранения информации, а также разработку более универсальных механизмов адаптации к изменениям в структуре целевых веб-сайтов.
