.png&w=384&q=75)
Конституция Российской Федерации (ст. 33) гарантирует гражданам право на обращение в государственные и муниципальные органы [1], которые обязаны их рассматривать. В условиях цифровой трансформации возрастает значимость автоматизации обработки таких обращений.
Муниципальные и федеральные органы ежегодно сталкивается с увеличением количества запросов, что создает нагрузку на специалистов, согласно данным сайта Правительства Российской Федерации [2]. Рассмотрение обращения требует анализа нормативной базы, межведомственного взаимодействия и соблюдения сроков (до 30 дней) [5]. В связи с этим актуальной становится задача внедрения технологий искусственного интеллекта (ИИ) для оптимизации процесса.
Актуальность исследования обусловлена стремительным ростом количества обращений граждан в муниципальные органы через различные каналы коммуникации (официальные порталы, электронная почта, госулуги), параллельно с этим установлены обязательства по обеспечению доступа к информации о деятельности муниципальных органов в социальных сетях [3], где граждане тоже могут оставлять сообщения, указывающие на городские проблемы. Что создает значительную нагрузку на муниципальных служащих, также И. В. Шевченко выделяет проблемы и с организацией работы управлений по работе с обращениями граждан, компетенциями специалистов [6].
Целью исследования является разработка концептуального методологического подхода к созданию интеллектуальной системы обработки обращений граждан в муниципальных органах власти, сочетающей: технологии глубокого семантического анализа текста (NLP), методы машинного обучения для классификации и кластеризации обращений, механизмы поиска релевантных ответов в нормативно-правовых базах данных.
В статье последовательно рассматриваются: теоретические основы автоматизации обработки обращений, применяемые технологии NLP и ML, предлагаемая архитектура системы, а также практические аспекты ее внедрения в муниципальных органах власти.
Методы автоматизации на основе NLP
Автоматизация обработки обращений граждан в муниципальных органах требует комплексного подхода, сочетающего технологии обработки естественного языка (NLP) с четкой системой классификации. Эффективность такой системы во многом зависит от того, насколько точно она способна определить: нормативный акт, регулирующий рассматриваемый вопрос; сферу компетенции муниципального органа, ответственного за решение проблемы; источник поступления сообщения, влияющий на формальность ответа.
Классификация по нормативному акту
Каждое обращение граждан, даже если оно выражено в свободной форме, в конечном итоге связано с конкретными нормами права. Например, жалоба на плохое состояние дороги может относиться к Федеральному закону № 131-ФЗ «Об общих принципах организации местного самоуправления», а запрос о порядке начисления коммунальных платежей – к Жилищному кодексу РФ (табл. 1).
Автоматическое определение нормативного акта позволяет: ускорить подготовку ответа, так как система сразу предлагает релевантные правовые выдержки; минимизировать ошибки, исключая ситуации, когда ответ дается на основе устаревших или неверных норм; обеспечить юридическую корректность, что особенно важно при обжаловании решений.
Для обучения модели используются не только тексты законов, но и базы ранее данных ответов, в которых уже установлены соответствия между тематикой вопроса и нормативным актом.
Таблица 1
Пример классификации по нормативно-правовым актам
Тип обращения | Пример формулировки | Нормативный акт |
Жалоба на состояние дорог | «На улице Центральной уже месяц ямы не ремонтируют» | ФЗ № 131 «Об общих принципах организации местного самоуправления» |
Запрос о ЖКХ | «Почему в квитанции появилась новая строка оплаты?» | Жилищный кодекс РФ |
Вопрос о благоустройстве | «Когда установят детскую площадку во дворе?» | ФЗ № 131 (ст. 14.1), муниципальные нормативы |
Классификация по сфере муниципального органа
Муниципальное управление охватывает множество направлений – от ЖКХ и транспорта до социальной поддержки и экологии. Ошибка в определении ответственного подразделения приводит к задержкам и недовольству граждан.
Автоматизированная система должна учитывать: Территориальную привязку (например, вопросы благоустройства конкретного двора относятся к районной администрации); Тематическую принадлежность (жалобы на шумные работы ночью – к отделу контроля за соблюдением тишины, а не к общему отделу ЖКХ); Пересечение компетенций (некоторые вопросы требуют согласованного ответа от нескольких ведомств) (табл. 2).
Таблица 2
Пример классификации по сферам:
Категория | Подкатегория | Ответственный орган |
ЖКХ | Управление МКД | Жилищная инспекция |
Транспорт | Дорожное покрытие | Управление дорожного хозяйства |
Благоустройство | Озеленение | Отдел городского хозяйства |
Классификация по источнику направления
Канал поступления сообщения влияет на стиль ответа и скорость его подготовки. Официальное обращение через портал «Госуслуги» требует строгого соблюдения регламентов, тогда как комментарий в социальной сети допускает более свободный тон.
Основные источники и их особенности:
Электронные приемные и порталы – требуют формального ответа со ссылками на законы;
Социальные сети – допускают краткие, но информативные ответы, иногда с элементами визуализации (например, фото выполненного ремонта);
Мессенджеры – предполагают оперативность, но не отменяют необходимости фиксации в CRM-системе.
Автоматическая маркировка источника позволяет: оптимизировать нагрузку на сотрудников (например, выделять отдельную группу модераторов для соцсетей); соблюдать регламенты (ответы на официальные запросы должны быть зарегистрированы и сохранены).
Интеграция классификаторов в NLP-модель
Для эффективной работы системы все три вида классификации должны применяться не последовательно, а в едином аналитическом контуре. Современные NLP-модели, такие, как BERT или GPT, способны одновременно [4]: извлекать ключевые сущности (например, адрес, название организации, тип проблемы); определять интенты (жалоба, запрос информации, предложение); сопоставлять их с нормативной базой и компетенциями органов.
При этом важно, чтобы система не просто «навешивала ярлыки», но и оценивала контекст. Например, фраза «Во дворе дома № 5 по ул. Ленина не убирают мусор» должна быть распознана не только как обращение по благоустройству, но и привязана к конкретному району, что автоматически определяет ответственное подразделение.
Архитектура интеллектуальной системы обработки обращений
Реализация системы автоматизированной обработки обращений требует тщательного проектирования архитектуры, которая органично впишется в существующие муниципальные процессы. Основная концепция заключается в создании интеллектуального помощника, который не заменяет муниципальных служащих, а значительно повышает эффективность их работы за счет автоматизации рутинных операций и предоставления контекстно-зависимых подсказок.
Ядром системы становится языковая модель, которая выполняет комплексный анализ входящих сообщений. Она не просто классифицирует обращения по заранее заданным категориям, а понимает их смысловую нагрузку, выявляет скрытые интенции и эмоциональную окраску. Например, сообщение «Когда уже починят эту ужасную дорогу на улице Садовой?» система распознает не только как жалобу на качество дорожного покрытия, но и как выражение явного недовольства, требующее особого внимания.
Интеграция с муниципальными информационными системами
Особое значение имеет механизм взаимодействия языковой модели с существующими муниципальными базами данных. Система не работает изолированно - она становится своеобразным «интеллектуальным интерфейсом» между гражданином и сложной структурой муниципальных информационных ресурсов.
После первичного анализа обращения система формирует серию точных запросов к различным информационным системам муниципалитета. Это требует разработки специальных адаптеров, которые преобразуют естественно-языковой запрос в формализованные поисковые конструкции, понятные существующим системам документооборота и учета.
Важным аспектом является оценка качества работы системы. Для этого предлагается использовать следующие ключевые метрики (табл. 3).
Таблица 3
Ключевые метрики
Метрика | Формула расчета | Целевое значение |
Точность классификации | Количество верно классифицированных обращений / Общее количество обращений | ≥90% |
Среднее время обработки | Суммарное время обработки / Количество обращений | ≤15 минут |
Коэффициент автоматизации | Количество обращений, обработанных без участия человека / Общее количество обращений | 60–70% |
Удовлетворенность граждан | Количество положительных оценок / Общее количество оценок | ≥85% |
Генерация рекомендаций для операторов
Создаваемая система предлагает операторам не просто шаблонные ответы, а интеллектуальные рекомендации, учитывающие множество факторов. В зависимости от сложности обращения и наличия релевантной информации в муниципальных базах данных, система может предлагать различные варианты поддержки. Обработка обращения происходит последовательно (рис.).
Для стандартных ситуаций с четкими регламентами система генерирует практически готовые ответы, включающие все необходимые ссылки на нормативные акты и контактные данные ответственных лиц. В более сложных случаях, когда требуется межведомственное взаимодействие или дополнительная проверка, система предлагает пошаговый алгоритм действий с возможными вариантами формулировок.
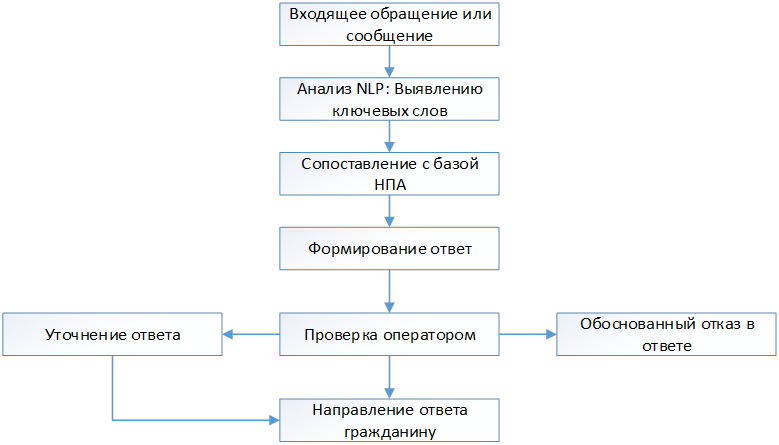
Рис. Принципиальная схема обработки обращения
Особую ценность представляют рекомендации по эскалации сложных вопросов. Система не просто перенаправляет обращение в другой отдел, а объясняет оператору, почему именно это подразделение должно заниматься вопросом, какие полномочия оно имеет, и даже предлагает варианты формулировок для служебной записки.
Перспективы развития и масштабирования системы
Развитие системы видится в нескольких взаимосвязанных направлениях. Во-первых, это постоянное совершенствование алгоритмов классификации за счет обучения на новых данных. Система должна адаптироваться к изменениям в нормативной базе и эволюции языковых практик граждан.
Во-вторых, важным направлением является развитие аналитических возможностей. Система сможет не только обрабатывать отдельные обращения, но и выявлять системные проблемы, анализировать динамику обращений по различным параметрам, прогнозировать всплески активности по определенным темам.
Особое внимание следует уделить персонализации взаимодействия. Со временем система сможет учитывать историю обращений конкретного гражданина, его предпочтительные каналы коммуникации и даже стиль общения, предлагая оператору соответствующие рекомендации по работе с данным заявителем.
Перспективным направлением является также разработка механизмов автоматического мониторинга исполнения решений по обращениям. Система сможет отслеживать, были ли выполнены обещания, данные гражданину, и своевременно сигнализировать о возможных нарушениях сроков.
Реализация этих возможностей потребует поэтапного внедрения, начиная с пилотных проектов по отдельным направлениям деятельности муниципалитета, с последующим постепенным расширением функционала и интеграцией с другими цифровыми сервисами.
Заключение
Проведенное исследование демонстрирует значительный потенциал применения технологий обработки естественного языка (NLP) и машинного обучения для автоматизации обработки обращений граждан в системе муниципального управления. Разработанная трехуровневая система классификации, учитывающая нормативные акты, сферу компетенции муниципальных органов и источник поступления сообщений, позволяет существенно оптимизировать процесс работы с обращениями граждан.
