.png&w=384&q=75)
1. Introduction to Large Language Models (LLMs)
Large language models (LLMs) are a breakthrough in the field of artificial intelligence, especially in natural language processing (NLP). These models are trained on huge text datasets from various sources and use billions of parameters to learn and simulate human language accurately. The underlying architecture of LLMs is the Transformer – a neural network architecture introduced by Vaswani et al. (2017), which helps process information in parallel and remember long-term relationships in text. Self-attention in the Transformer allows the model to identify related words in a sentence regardless of their position, which helps overcome the shortcomings of sequential models such as RNN or LSTM.
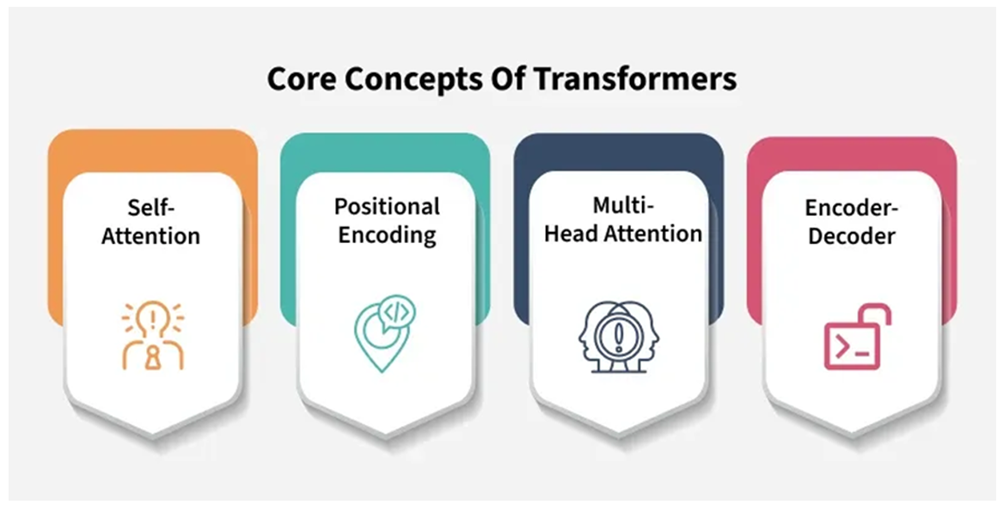
Fig. 1. Core Concepts of Transformers
2. Operating mechanism and improvements in Transformer models
The Transformer architecture is foundational to modern natural language processing (NLP) and underpins the development of most large language models (LLMs). It consists of two primary components: the encoder and the decoder. The encoder is responsible for processing and encoding the input sequence into a series of high-dimensional semantic representations. These representations capture not only the content of the input but also the contextual relationships between its components. The decoder, in turn, takes these encoded representations and generates an output sequence, often in the form of translated text, predicted tokens, or responses to a prompt.
Each encoder and decoder layer is composed of two core subcomponents: a multi-head self-attention mechanism and a position-wise feed-forward neural network. The self-attention mechanism allows the model to weigh the relevance of different tokens in the input sequence relative to one another, regardless of their position, enabling the model to capture long-range dependencies and contextual nuances. Multi-head attention extends this capability by allowing the model to attend to different parts of the input simultaneously from various representation subspaces. Following the attention block, a feed-forward network processes each token independently, applying non-linear transformations to refine the contextualized embeddings. These layers are typically followed by residual connections and layer normalization, which stabilize training and improve performance.
Since the original introduction of the Transformer model by Vaswani et al. (2017), a variety of extensions and adaptations have been proposed to enhance its capabilities. One notable example is BERT (Bidirectional Encoder Representations from Transformers) introduced by Devlin et al. (2019), which modifies the original architecture to utilize only the encoder stack. BERT employs bidirectional attention to understand the context on both sides of a target word, enabling deep language understanding and excelling at tasks such as question answering and sentence classification.
Another prominent model is RoBERTa, a robustly optimized version of BERT that improves performance through training on larger corpora and longer sequences. The T5 (Text-to-Text Transfer Transformer) model by Google takes a unified approach to NLP tasks by treating every problem as a text generation task, whether it be classification, summarization, or translation.
In contrast, the GPT (Generative Pretrained Transformer) series, developed by OpenAI (Brown et al., 2020), builds upon the decoder stack of the Transformer and is designed for unidirectional, autoregressive text generation. GPT models are pretrained on massive datasets using language modeling objectives and then fine-tuned for specific downstream tasks. GPT-3 and GPT-4 represent significant advances in model scale and performance, capable of zero-shot and few-shot learning, where the model can perform tasks with minimal or no task-specific training examples.
Emerging models such as Claude (by Anthropic), LLaMA (by Meta), and Gemini (by Google DeepMind) further push the boundaries of the Transformer framework. These models incorporate innovations such as multi-task learning, which allows them to handle diverse tasks simultaneously; unsupervised learning, which enhances adaptability to new data; and advanced fine-tuning methods, enabling more controlled and safe interactions. Together, these models represent the state-of-the-art in generative AI, demonstrating both the scalability and versatility of the Transformer architecture in addressing a wide array of complex language tasks.
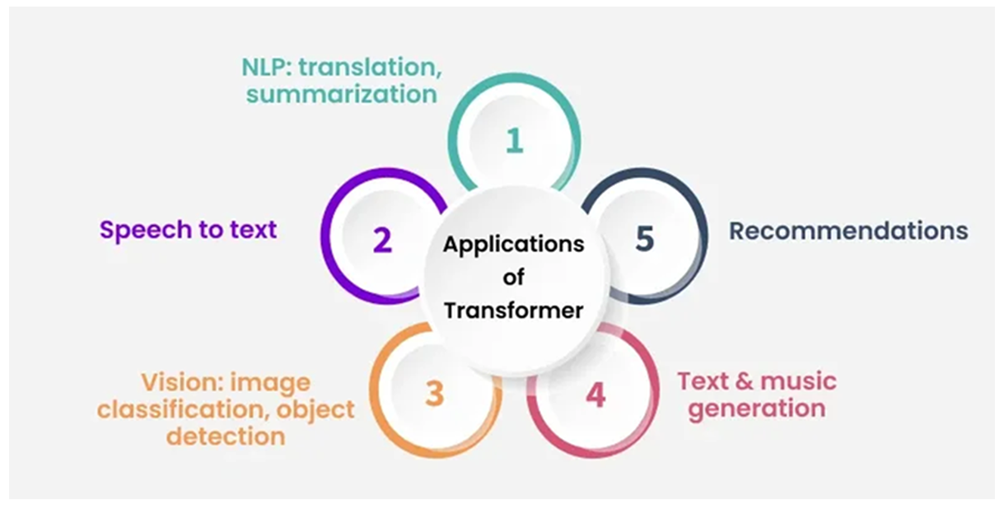
Fig. 2. Most common applications of Transformers
3. Application and Dissemination of LLM Technology
A prominent application of large language models (LLMs) is ChatGPT, introduced by OpenAI in late 2022. It quickly became one of the most widely adopted interactive tools globally, thanks to its ability to engage users in natural, coherent, and contextually relevant dialogue [6]. The emergence of ChatGPT marked a significant milestone in the democratization of artificial intelligence, bringing advanced natural language processing (NLP) capabilities to the general public. Its success catalyzed a technological race, prompting major tech companies such as Google (with Gemini), Microsoft (with Copilot), Meta (with LLaMA), and Amazon to integrate LLMs into their product ecosystems. These integrations span across search engines, virtual assistants, productivity tools, and cloud services, revolutionizing how users interact with digital platforms.
Beyond general-purpose applications like content creation, language translation, and question answering, LLMs are making inroads into specialized and high-stakes fields such as medicine, law, finance, and education [2]. In healthcare, LLMs have demonstrated potential in clinical documentation, patient communication, and even preliminary diagnostic assistance. For example, they can generate patient summaries, simplify medical jargon for laypeople, and provide responses to common queries, thereby reducing administrative burden on healthcare professionals. In the legal domain, LLMs are being explored for tasks like document review, contract analysis, and legal research, enhancing efficiency and reducing time-consuming manual work.
In finance, LLMs assist in automating customer support, generating market reports, and even analyzing trends based on unstructured data. Meanwhile, in education, LLMs serve as virtual tutors, grading assistants, or tools for personalized feedback and curriculum development. These use cases highlight the potential of LLMs to augment human expertise, enhance decision-making, and streamline operations across sectors.
However, the widespread deployment of LLMs also brings forth several challenges. One of the most pressing concerns is ethical: how can we ensure responsible use of AI-generated content? The ability of LLMs to produce plausible-sounding but factually incorrect or biased information raises concerns about misinformation and the erosion of trust in automated systems. Moreover, there is growing debate about intellectual property rights – particularly when LLMs are trained on copyrighted content without explicit consent. This raises fundamental legal and ethical questions about data provenance, ownership, and fair use in the age of generative AI.
Another critical issue is transparency. Most users interact with LLMs without understanding how the models generate responses or what data they were trained on. This lack of explainability makes it difficult to audit or regulate the outputs of these systems, especially in sensitive contexts such as healthcare or legal advice. Moreover, the potential for algorithmic bias and discrimination, inherited from the training data, underscores the importance of rigorous validation and testing before deployment in real-world scenarios.
To summarizing, while LLMs such as ChatGPT offer transformative potential across diverse domains, their deployment must be accompanied by thoughtful governance, ethical oversight, and continuous evaluation. A multidisciplinary approach – involving technologists, domain experts, ethicists, and policymakers – is essential to harness their benefits while mitigating the associated risks.
4. The impact of LLM on research, education and society
The application of large language models (LLMs) in academia raises significant concerns regarding the integrity of research and education. With their ability to generate coherent, contextually appropriate, and content-rich text, LLMs are increasingly blurring the line between human content creators and assistive technologies. When students or researchers use such tools to produce essays, scientific papers, or research proposals without transparency, there is a high risk of plagiarism, misinformation, and copyright violations [4]. This is particularly serious in academic settings, where integrity and transparency are foundational principles of scientific inquiry.
Beyond the issue of research quality, unregulated use of LLMs also complicates educators’ ability to assess students’ actual capabilities. If assignments, theses, or even dissertations are primarily generated by AI without critical input from the individual, it undermines the core mission of higher education – cultivating critical thinking, creativity, and academic ethics. Current tools for detecting AI-generated content are still not fully reliable, creating a "gray area" in enforcing academic misconduct policies, especially when students blend self-written and AI-generated text.
Beyond academia, professions that rely heavily on language processing - such as editors, journalists, translators, administrative assistants, and even lawyers - are at risk of being partially replaced by this technology. While LLMs can improve productivity and save time, they also present challenges in maintaining professional standards, objectivity, and the human element in fields that demand contextual judgment, emotional nuance, and ethical responsibility.
To address these risks, educational and research institutions must urgently develop clear legal and ethical frameworks governing the use of LLMs. This includes issuing transparent guidelines on the permissible extent of AI usage in coursework, research, and publication; integrating AI-content detection tools into academic integrity systems; and, crucially, providing training for both students and faculty on how to use LLMs ethically, responsibly, and effectively. Furthermore, interdisciplinary research should be encouraged to investigate the long-term impact of AI on the academic knowledge ecosystem, enabling the formulation of policies that balance technological innovation with the core values of higher education.
5. Environmental Impact: An aspect that has not received due attention
Large language models (LLMs) are powerful but resource-intensive systems that demand significant computational and energy resources. The training of these models involves processing datasets consisting of hundreds of billions of words and optimizing models that may contain hundreds of billions of parameters. This scale of computation requires the use of specialized hardware, such as high-performance GPUs and TPUs, running over extended periods-often weeks or months. As a result, the environmental footprint of LLMs has become a growing concern within the AI research and sustainability communities.
Studies have estimated that training a single large-scale model like GPT-3 can result in the emission of hundreds of metric tons of carbon dioxide (CO₂) equivalents [7, 8]. These emissions arise primarily from the electricity consumption required to power large-scale data centers during training. The magnitude of this impact is influenced by several factors, including the size of the model, the efficiency of the hardware used, the number of training iterations, and the source of the electricity. For example, training a model on fossil fuel-based power grids can substantially increase emissions compared to using data centers powered by renewable energy. Beyond direct emissions, the environmental costs associated with the physical infrastructure of AI are also significant. The manufacture of high-performance computing hardware depends on the extraction and refinement of rare earth minerals, which often involves environmentally destructive mining practices and significant energy consumption. Furthermore, as hardware becomes obsolete due to rapid technological advancement, electronic waste (e-waste) is accumulating at an unprecedented rate, raising concerns about toxicity and long-term ecological damage.
These combined factors suggest that, if unregulated, the growth of LLMs and other compute-heavy AI systems may contribute disproportionately to global carbon emissions and environmental degradation. This is particularly problematic given the increasing deployment of LLMs in commercial applications, which leads not only to more frequent model retraining but also to high-volume inference workloads that consume substantial energy during day-to-day operation.
To mitigate these environmental challenges, researchers and developers are exploring multiple strategies. One key avenue is the design of more energy-efficient models through the use of model compression techniques such as pruning, quantization, and knowledge distillation. These methods reduce model size and computational requirements without significantly sacrificing performance. Another approach involves optimizing training algorithms to improve convergence speed and reduce redundant computation.
Moreover, the AI community is increasingly advocating for the use of renewable energy sources to power training and inference infrastructures. Cloud service providers such as Google Cloud, Microsoft Azure, and Amazon Web Services have committed to net-zero emissions goals and are investing in green energy. Encouraging transparency in reporting energy use and carbon emissions associated with AI development can also help hold organizations accountable and promote sustainability.
As the capabilities and deployment of LLMs continue to grow, aligning AI advancement with environmental responsibility is not optional-it is imperative. A concerted effort across academia, industry, and policy-making is necessary to ensure that the future of AI is not only intelligent but also sustainable [1].
6. Conclusion
Large language models, especially transformer-based ones, are opening up a new era in human-computer interaction. However, they come with social, academic, and environmental challenges. Research and application of LLMs must be conducted responsibly, transparently, and in a sustainable manner, in order to maximize the benefits of the technology while minimizing its risks.
Funding
This research is funded by Electric Power University under research 2025.
