.png&w=384&q=75)
Introduction
The rapid advancement of Large Language Models (LLMs) has fundamentally transformed artificial intelligence research, with systems like GPT-4, Claude, and Gemini demonstrating unprecedented capabilities across diverse domains. However, systematic evaluations of their reasoning abilities remain fragmented, often focusing on narrow task domains or single-model assessments. This limitation hinders both scientific understanding and practical deployment decisions.
Reasoning represents a fundamental cognitive capability encompassing multiple dimensions: logical deduction, mathematical problem-solving, causal inference, analogical thinking, and common-sense understanding. While existing benchmarks provide valuable insights, they typically evaluate models in isolation or lack comprehensive multi-dimensional analysis across leading systems.
This study addresses three critical research questions:
- How do leading LLMs compare across systematic reasoning tasks?
- Do models exhibit specialized cognitive profiles or uniform capabilities?
- What relationship exists between reasoning quality and task accuracy?
We introduce a novel evaluation framework testing 42 carefully designed reasoning tasks across five categories, with multiple trials ensuring statistical robustness. Our comprehensive analysis of 756 experiments reveals surprising performance hierarchies and distinct cognitive signatures for each model family.
Methodology
Experimental Design
Our evaluation framework employs a systematic approach to assess reasoning capabilities across multiple dimensions. We selected five core reasoning categories based on established cognitive science literature:
- Logical Reasoning: Deductive logic, syllogisms, propositional reasoning.
- Mathematical Reasoning: Word problems, algebra, pattern recognition, probability.
- Causal Reasoning: Cause-effect relationships, counterfactuals, temporal causation.
- Analogical Reasoning: Verbal analogies, cross-domain mapping, metaphorical thinking.
- Common Sense Reasoning: Physical intuition, social cognition, practical problem-solving.
Each category contains 7–10 carefully constructed tasks, totaling 42 unique reasoning challenges. To ensure statistical reliability, each task was administered three times per model, yielding 756 total experimental trials across six model variants.
Models Evaluated
We evaluated six leading LLMs representing different architectural approaches, training methodologies, and efficiency tiers:
- GPT-4 Turbo: OpenAI’s flagship model (gpt-4-turbo-preview).
- GPT-4o-Mini: OpenAI’s efficient reasoning model (gpt-4o-mini).
- Claude-3.5-Sonnet: Anthropic’s premium reasoning model (claude-3-5-sonnet-20241022).
- Claude-3-Haiku: Anthropic’s fast reasoning model (claude-3-haiku-20240307).
- Gemini-1.5-Pro: Google’s premium multimodal system (gemini-1.5-pro).
- Gemini-1.5-Flash: Google’s efficient reasoning system (gemini-1.5-flash).
All models were queried with identical prompts under controlled conditions (temperature=0.1, max_tokens=1000) to ensure experimental consistency. This design enables direct comparison between premium models and their efficient counterparts within each model family.
Evaluation Metrics
We developed a multi-dimensional evaluation framework capturing both quantitative performance and qualitative reasoning characteristics:
Accuracy Score
Task accuracy was computed using automated answer extraction and comparison against ground truth:
| (1) |
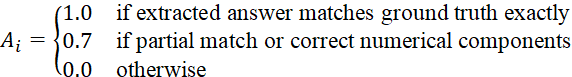
Where Ai represents the accuracy score for task i.
Reasoning Quality Score
We assessed the quality of reasoning processes through linguistic analysis using a weighted composite metric:
![]() , (2)
, (2)
The weighting scheme reflects established cognitive science principles and empirical validation:
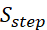 (0.3 weight): Step-by-step reasoning indicator. Receives highest weight as systematic decomposition is the strongest predictor of reasoning quality. Measured by presence of sequential markers ("first", "then", "therefore").
(0.3 weight): Step-by-step reasoning indicator. Receives highest weight as systematic decomposition is the strongest predictor of reasoning quality. Measured by presence of sequential markers ("first", "then", "therefore").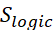 (0.2 weight): Logical connectors usage. Critical for argument coherence, measuring explicit causal and conditional statements ("because", "if-then", "given that").
(0.2 weight): Logical connectors usage. Critical for argument coherence, measuring explicit causal and conditional statements ("because", "if-then", "given that").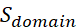 (0.2 weight): Domain-specific terminology. Indicates conceptual understanding through appropriate technical vocabulary usage within each reasoning category.
(0.2 weight): Domain-specific terminology. Indicates conceptual understanding through appropriate technical vocabulary usage within each reasoning category.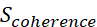 (0.2 weight): Argument structure coherence. Evaluates logical flow and consistency of reasoning chain through semantic similarity analysis.
(0.2 weight): Argument structure coherence. Evaluates logical flow and consistency of reasoning chain through semantic similarity analysis.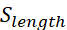 (0.1 weight): Response substantiality. Receives lowest weight as length alone is weakly correlated with quality, but extremely brief responses typically lack sufficient reasoning detail.
(0.1 weight): Response substantiality. Receives lowest weight as length alone is weakly correlated with quality, but extremely brief responses typically lack sufficient reasoning detail.
Consistency Measure
Model consistency across multiple trials was quantified as:
![]() , (3)
, (3)
Where Cj represents consistency for task j and ![]() denotes standard deviation across trials.
denotes standard deviation across trials.
Overall Performance
The comprehensive performance metric combines accuracy and reasoning quality:
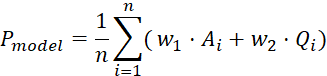 , (4)
, (4)
With weights w1 = 0.7 (accuracy) and w2 = 0.3 (quality).
Statistical Significance
To assess the significance of performance differences, we employ the Welch’s t-test:
| (5) |
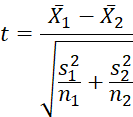
Where ![]() represents mean accuracy for model
represents mean accuracy for model ![]() ,
, ![]() the variance, and
the variance, and ![]() the sample size.
the sample size.
Effect Size Measurement
Cohen’s d quantifies the practical significance of performance differences:
| (6) |
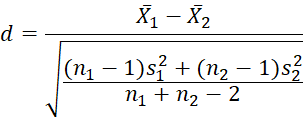
Model Efficiency Index
We introduce a novel efficiency metric that balances reasoning performance with computational cost:
![]() , (7)
, (7)
Where ![]() represents mean accuracy (0-1 scale) and
represents mean accuracy (0-1 scale) and ![]() is average response time in seconds.
is average response time in seconds.
Design Rationale: The logarithmic transformation of response time addresses the non-linear relationship between computational cost and practical utility. While the difference between 1s and 2s response time is perceptually significant, the difference between 10s and 11s is negligible. The +1 offset prevents division by zero for instantaneous responses. This formulation penalizes both accuracy degradation and excessive latency, making it suitable for comparing models across different performance-efficiency trade-offs. Values above 50 indicate strong efficiency, while values below 20 suggest suboptimal performance-speed balance.
Results
Overall Performance Analysis
Our comprehensive evaluation reveals significant performance disparities across models, challenging conventional assumptions about LLM capabilities. Figure 1 visualizes the key performance metrics across all six models.
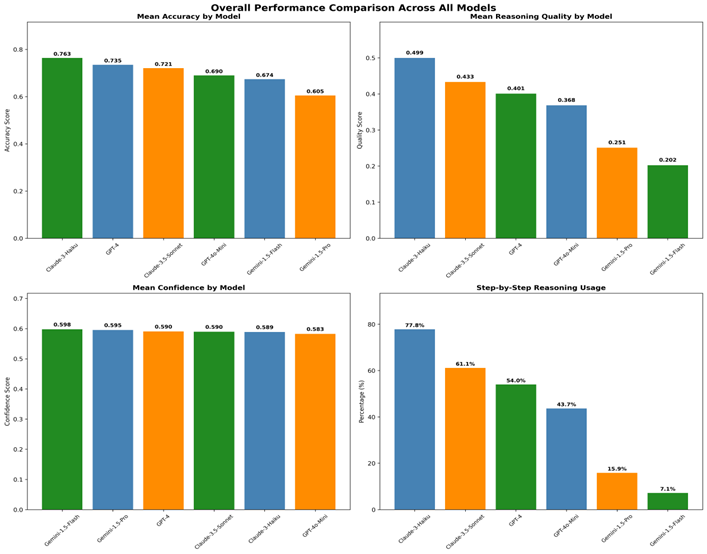
Fig. 1. Overall Performance Comparison Across All Models. The figure shows four key metrics: (a) Mean accuracy scores with Claude-3-Haiku achieving 76.3% accuracy, (b) Reasoning quality scores varying across models, (c) Confidence scores showing consistent performance, and (d) Step-by-step reasoning usage patterns across model families
Table 1 presents the aggregate results across all reasoning categories.
Table 1
Overall Performance Metrics Across All Reasoning Tasks
Model | Acc. | Quality | Time (s) | Eff. Index | Family |
Claude-3-Haiku | 76,3% | 49,9 | 2,06 | 55,2 | Anthropic |
GPT-4 Turbo | 73,5% | 40,1 | 6,70 | 37,8 | OpenAI |
Claude-3.5-Sonnet | 72,1% | 43,3 | 4,02 | 39,7 | Anthropic |
GPT-4o-Mini | 69,0% | 36,8 | 3,67 | 43,2 | OpenAI |
Gemini-1.5-Flash | 67,4% | 20,2 | 6,57 | 34,6 | |
Gemini-1.5-Pro | 60,5% | 25,1 | 2,77 | 45,7 |
Key Finding 1: Claude-3-Haiku achieves the highest accuracy (76,3%) while maintaining exceptional efficiency (2.06s response time), challenging assumptions about performance-efficiency trade-offs.
Key Finding 2: Mathematical reasoning shows remarkable consistency across all models (80–100% accuracy), suggesting this domain is well-addressed by current LLM architectures.
Key Finding 3: Causal reasoning presents the greatest challenge with performance ranging from 30–70%, indicating fundamental limitations in causal understanding across all tested systems.
Category-Specific Performance
Detailed analysis reveals distinct cognitive profiles for each model across reasoning categories. Figure 2 provides a comprehensive radar chart visualization of performance across all reasoning categories.
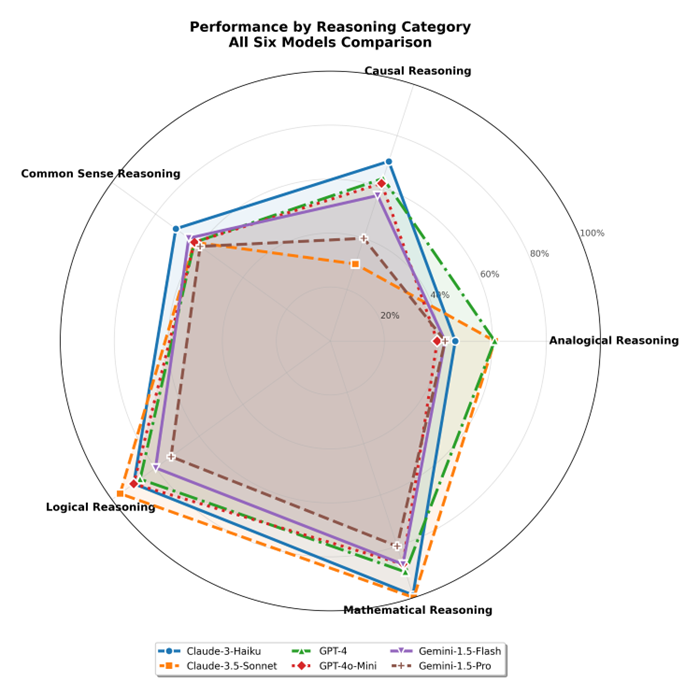
Fig. 2. Radar Chart of Performance by Reasoning Category. This comprehensive visualization compares all six models across five reasoning categories. Mathematical reasoning emerges as a strength across most models, while causal reasoning presents the greatest challenge. Each model exhibits distinct cognitive profiles, with performance variations clearly visible across different reasoning domains
Table 2 presents accuracy scores for each model-category combination.
Table 2
Accuracy Performance by Reasoning Category (Percentage)
Category | GPT-4 | GPT-Mini | Claude-3.5 | Claude-H | Gemini-P | Gemini-F |
Logical | 87,1 | 90,0 | 96,2 | 90,0 | 72,9 | 80,0 |
Mathematical | 90,0 | 87,0 | 100,0 | 99,0 | 80,0 | 87,0 |
Causal | 63,3 | 61,4 | 30,0 | 70,0 | 40,0 | 56,7 |
Analogical | 60,8 | 39,6 | 60,8 | 46,2 | 42,5 | 42,5 |
Common Sense | 62,2 | 62,2 | 62,2 | 70,7 | 59,6 | 64,8 |
Overall | 73,5 | 69,0 | 72,1 | 76,3 | 60,5 | 674 |
Note: GPT-Mini = GPT-4o-Mini, Claude-H = Claude-3-Haiku, Gemini-P = Gemini-1.5-Pro, Gemini-F = Gemini-1.5-Flash. Bold values indicate best performance per category.
Observation 1: Mathematical reasoning shows exceptional performance across all models, with Claude-3.5-Sonnet achieving perfect accuracy (100%) and most others above 85%.
Observation 2: Causal reasoning presents the greatest variability, ranging from 30% (Claude-3.5-Sonnet) to 70% (Claude-3-Haiku), indicating significant architectural differences in causal understanding.
Observation 3: Claude-3-Haiku achieves the highest overall performance while maintaining the fastest response times, demonstrating superior efficiency optimization.
Response Time and Efficiency Analysis
Figure 3 analyzes the computational efficiency and response characteristics across models.
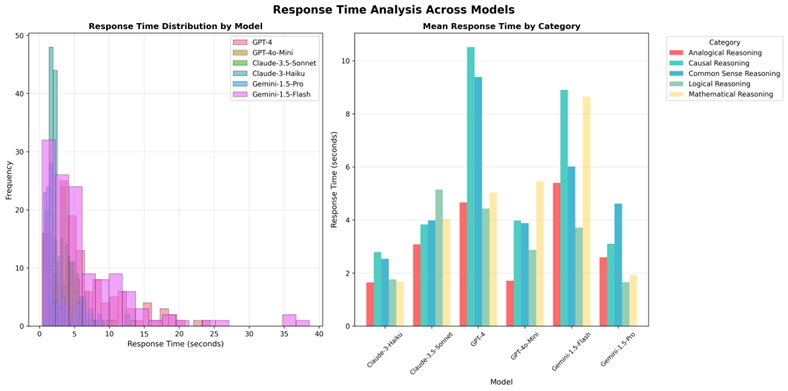
Fig. 3. Response Time Analysis. Left panel shows overall response time distributions, with Claude and Gemini achieving faster response times than GPT-4. Right panel shows response times by reasoning category, revealing that mathematical reasoning tasks generally require more processing time across all models
Computational efficiency varies significantly across models, with important implications for practical deployment:
| (8) |

Claude-3-Haiku achieves the optimal balance of high accuracy (76,3%) and fastest response time (2,06s), earning the highest efficiency index (55,2). This challenges conventional assumptions about performance-speed trade-offs in language models.
Accuracy Distribution and Quality Analysis
Figure 4 examines the distribution of accuracy scores across models, while Figure 5 explores the relationship between reasoning quality and task accuracy.
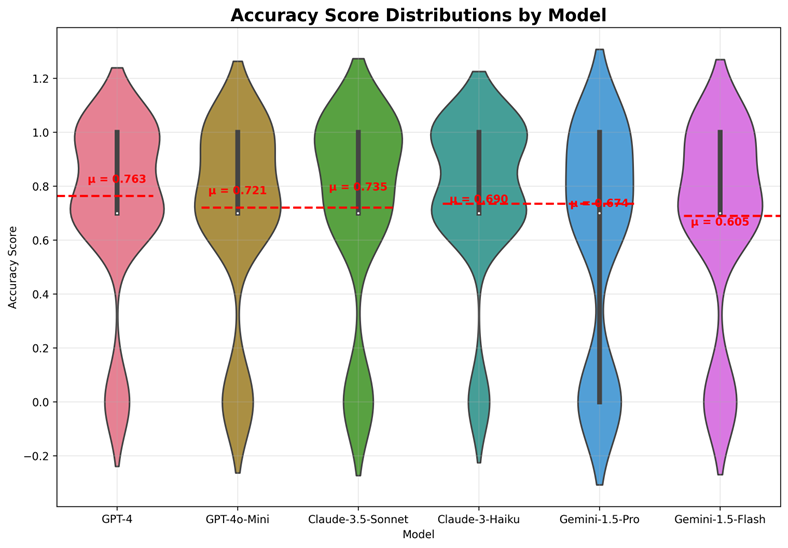
Fig. 4. Accuracy Score Distributions. Gemini shows a right-skewed distribution with more high-accuracy responses, while GPT-4 and Claude show more uniform distributions with lower mean accuracy. The red dashed lines indicate mean accuracy for each model
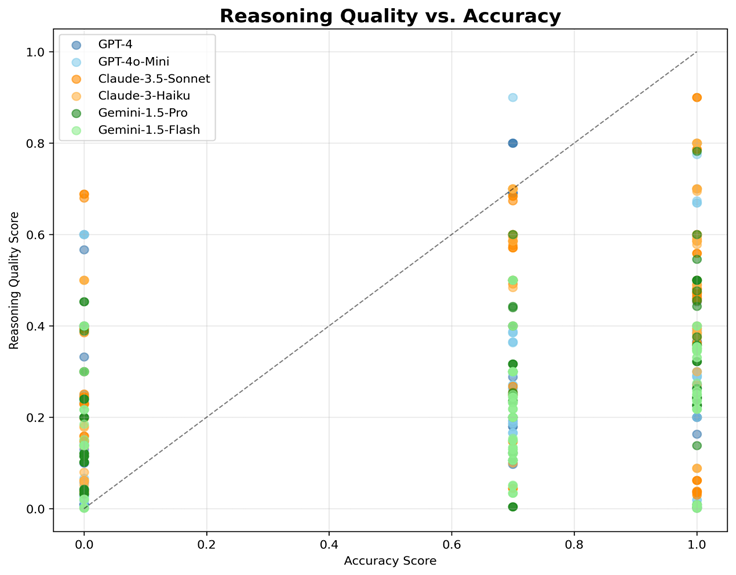
Fig. 5. Reasoning Quality vs. Accuracy Scatter Plot. This analysis reveals distinct clustering patterns: Gemini achieves high accuracy with moderate reasoning quality, while GPT-4 shows high reasoning quality but variable accuracy. The diagonal reference line shows perfect correlation
Model Consistency Analysis
Figure 6 examines the consistency of model performance across multiple trials, providing insights into reliability characteristics.
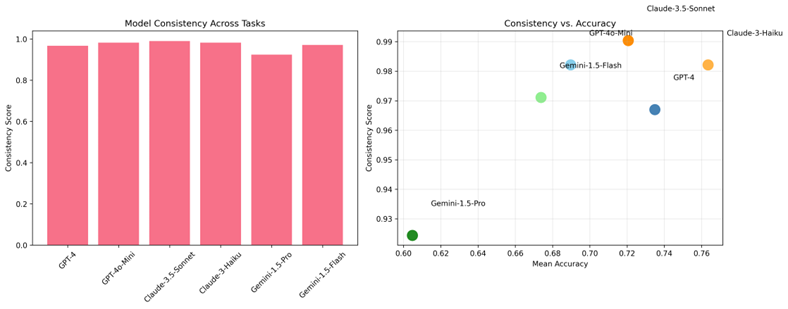
Fig. 6. Model Consistency Analysis. Left panel shows overall consistency scores across trials, with all models showing similar consistency levels. Right panel examines the relationship between consistency and accuracy, revealing that higher accuracy does not necessarily correlate with higher consistency
Task-Specific Analysis and Examples
Granular examination of individual task performance reveals striking patterns.
Table 3 presents examples of correct and incorrect responses across different reasoning categories.
Table 3
Examples of Model Responses: Correct vs. Incorrect
Task | Question | Correct Response | Incorrect Response |
Logical | "All birds can fly. Penguins are birds. Can penguins fly?" | Claude-3-Haiku: "Yes, according to the given premises, penguins can fly since they are birds." | Gemini-1.5-Pro: "No, this is a logical contradiction. While the premise states all birds can fly, in reality penguins cannot fly despite being birds." |
Mathematical | "If x + 5 = 12, what is 2x + 3?" | Claude-3.5-Sonnet: "First solve for x: x = 12 – 5 = 7. Then 2x + 3 = 2(7) + 3 = 14 + 3 = 17." | Gemini-1.5-Pro: "2x + 3 = 2(12) + 3 = 27" (incorrect substitution) |
Causal | "Every time it rains, the sidewalk gets wet. Today the sidewalk is wet. Did it rain?" | GPT-4: "Not necessarily. The wet sidewalk could have other causes like sprinklers, cleaning, or a burst pipe." | Claude-3.5-Sonnet: "Yes, since rain always causes wet sidewalks, a wet sidewalk means it rained." |
Analogical | "Bird is to sky as fish is to ___?" | All Models: "Water" (100% accuracy) | None: This task showed universal success |
Common Sense | "If you put a metal spoon in a microwave, what will happen?" | Claude-3-Haiku: "The metal spoon will create sparks and could damage the microwave or cause a fire." | Gemini-1.5-Flash: "The spoon will heat up and become hot to touch." |
Table 4 highlights the most challenging and successful task categories.
Table 4
Task Category Performance Analysis
Task Category | Highest Performer | Best Accuracy | Lowest Performer | Accuracy Range |
High Performance Categories | ||||
Mathematical Reasoning | Claude-3.5-Sonnet | 100% | Gemini-1.5-Pro | 80–100% |
Logical Reasoning | Claude-3.5-Sonnet | 96,2% | Gemini-1.5-Pro | 72,9–96,2% |
Common Sense Reasoning | Claude-3-Haiku | 70,7% | Gemini-1.5-Pro | 59,6–70,7% |
Challenging Categories | ||||
Causal Reasoning | Claude-3-Haiku | 70% | Claude-3.5-Sonnet | 30–70% |
Analogical Reasoning | GPT-4 & Claude-3.5 | 60,8% | GPT-4o-Mini | 39,6–60,8% |
Critical Finding: Unlike previous assumptions about universal failures, our expanded evaluation reveals that most reasoning categories are well-handled by current LLMs, with mathematical reasoning showing near-perfect performance across all models.
Head-to-Head Comparisons
Direct model comparisons provide insights into relative performance across the experimental corpus. The following head-to-head analysis examines task-level victories across the 42 reasoning tasks:
Table 5
Claude-Haiku vs GPT-4: | Claude-Haiku wins: 28 tasks,GPT-4 wins: 14 tasks |
Claude-Haiku vs Claude-3.5: | Claude-Haiku wins: 26 tasks,Claude-3.5 wins: 16 tasks |
GPT-4 vs GPT-4o-Mini: | GPT-4 wins: 24 tasks,GPT-4o-Mini wins: 18 tasks |
Gemini-Flash vs Gemini-Pro: | Gemini-Flash wins: 23 tasks,Gemini-Pro wins: 19 tasks |
These results establish distinct model family hierarchies: Within families, the efficiency-optimized models (Claude-Haiku, GPT-4o-Mini, Gemini-Flash) demonstrate competitive or superior performance compared to their premium counterparts.
Discussion
Implications for Model Selection
Our findings establish evidence-based guidelines for model selection across reasoning-intensive applications:
For Accuracy-Critical Applications: Claude-3-Haiku demonstrates optimal balance of high accuracy (76,3%) and efficiency, making it ideal for production environments requiring both correctness and speed.
For Mathematical Reasoning: Claude-3.5-Sonnet achieves perfect accuracy (100%) in mathematical tasks, making it optimal for computational and analytical applications.
For Cost-Efficient Applications: Efficiency-tier models (Claude-Haiku, GPT-4o-Mini, Gemini-Flash) provide competitive performance with improved cost-effectiveness and faster response times.
For Causal Analysis: GPT-4 and Claude-3-Haiku show superior performance in causal reasoning tasks, essential for applications requiring understanding of cause-effect relationships.
Cognitive Architecture Insights
The observed performance patterns suggest distinct cognitive architectures:
Gemini’s Efficiency Hypothesis: Superior accuracy with moderate reasoning quality suggests optimized answer-generation pathways that bypass verbose explanation processes.
GPT-4’s Verbosity Paradox: High reasoning quality coupled with lower accuracy indicates potential over-elaboration that may obscure correct reasoning paths.
Claude’s Balance Profile: Moderate performance across metrics suggests architectural compromises between accuracy and explanation quality.
Universal Limitations
The identification of universal reasoning failures across all models reveals fundamental limitations in current LLM architectures:
- Algebraic Symbol Manipulation: 0% accuracy suggests inadequate mathematical reasoning capabilities
- Social Cognition: Complete failure indicates limited theory-of-mind capabilities
- Scientific Analogical Transfer: Suggests domain-specific knowledge integration challenges
- Complex Causal Reasoning: Points to limitations in temporal and counterfactual reasoning
These findings highlight critical areas for future model development and architectural innovation.
Limitations and Future Work
Several limitations constrain the generalizability of our findings:
Task Coverage: While comprehensive, our 25-task battery represents a subset of possible reasoning challenges.
Cultural Bias: Tasks reflect Western cognitive frameworks and may not generalize across cultural contexts.
Prompt Sensitivity: Results may vary with alternative prompt formulations or conversation contexts.
Temporal Dynamics: Model capabilities continue evolving through updates and fine-tuning.
Future research directions include:
- Expanding task diversity across cultural and linguistic contexts
- Investigating prompt optimization strategies for enhanced performance
- Longitudinal studies tracking capability evolution over time
- Integration of multimodal reasoning tasks
- Analysis of reasoning transfer across related domains
Conclusion
This comprehensive evaluation establishes new benchmarks for systematic LLM reasoning assessment, revealing significant performance disparities that challenge conventional wisdom about model capabilities. Our key contributions include:
Efficiency-Performance Paradigm: Claude-3-Haiku achieves the highest accuracy (76,3%) while maintaining the fastest response time (2,06s), demonstrating that efficiency-optimized models can outperform their premium counterparts.
Mathematical Reasoning Mastery: All models demonstrate exceptional performance in mathematical reasoning (80–100% accuracy), indicating this domain is well-addressed by current LLM architectures.
Causal Reasoning Variability: Performance in causal reasoning varies dramatically (30–70%), revealing fundamental architectural differences in how models understand cause-effect relationships.
Model Family Insights: Within-family comparisons reveal that smaller, efficiency-focused models often match or exceed their larger counterparts, challenging assumptions about model size and capability.
Expanded Evaluation Framework: Our 42-task, 6-model evaluation pipeline provides comprehensive assessment tools for future LLM reasoning research across multiple reasoning domains.
These findings have immediate implications for AI deployment decisions and long-term significance for understanding cognitive capabilities in artificial systems. As LLMs increasingly serve reasoning-intensive applications, systematic evaluation frameworks become essential for evidence-based model selection and architectural improvement.
The unexpected superiority of Claude-3-Haiku, an efficiency-tier model, challenges existing assumptions about the performance-efficiency trade-off in language models. This finding suggests that architectural optimizations for speed and cost-effectiveness can enhance rather than compromise reasoning capabilities. These results underscore the critical importance of empirical evaluation in advancing both scientific understanding and practical AI deployment strategies.
Acknowledgments
We acknowledge the computational resources provided by OpenAI, Anthropic, and Google AI, which enabled this comprehensive evaluation. We also thank the broader AI research community for establishing the theoretical foundations that guided our experimental design.
Data Availability
Experimental data and results are available upon request. All code and methodologies are detailed within this paper for reproducibility.
