
1. Введение
В практическом маркетинге повторяется одна и та же картина: слабое знание контекста и мотивации аудитории ведет к систематическим потерям бюджета. В этой методике в качестве рабочей гипотезы принимаются следующее: восемь из десяти кампаний теряют значимую часть средств по причине поверхностного понимания целевой аудитории, когда сегментация ограничивается демографией, а инсайты подменяются стереотипами. Последствия проявляются одинаково: расплывчатые гипотезы, нерелевантные триггеры, тексты и офферы, которые не резонируют с задачами человека в конкретном контексте.
Рывок ИИ (искусственный интеллект) инструментов меняет механику исследования. ChatGPT позволяет за минуты генерировать развернутые гипотезы сегментов, боли, триггеры и язык аудитории, с которыми раньше команды работали неделями. Экспериментальные данные подтверждают потенциал ускорения: доступ к ChatGPT сокращал время выполнения профессиональных писательских задач примерно на 37 % и одновременно повышал качество результатов, следовательно, этап гипотезирования и первичной сегментации можно существенно ускорить без потери строгости [1].
Методика AI-Target Insight нацелена на создание воспроизводимого трёхшагового ИИ-фреймворка Segmentation → Avatars → CustDev, который переводит исследование из интуитивных рассуждений в быструю доказательную итерацию. На первом этапе Segmentation ChatGPT применяется в качестве генеративного расширителя для создания карты поведенческих и контекстных сегментов по задачам, триггерам, барьерам и языковым маркерам. На втором этапе Avatars полученные сегменты сводятся к операционным клиентским аватарам, то есть кратким моделям принятия решений с перечнем критериев выбора, типичных возражений и характерного словаря. На третьем этапе CustDev гипотезы оперативно валидируются: микросценарии интервью и тестирование сообщений на реальной аудитории обеспечивают данные для уточнения сегментов и аватаров. Такой цикл опирается на скорость генерации ИИ и на человеческую проверку, по опыту автора он снижает время исследования как минимум в пять раз и переводит релевантность офферов из случайности в систему.
Дополнительный мотив к точной сегментации и языковому соответствию приходит со стороны ожиданий клиентов. Исследования показывают, что существенная часть пользователей ожидает персонализированных взаимодействий и испытывает фрустрацию при их отсутствии, следовательно, без четкого понимания сегмента и его контекста растут не только прямые издержки, но и скрытые потери из‑за ухудшения опыта [2]. Это усиливает значение трехшагового цикла, в котором гипотезы сегмента и сообщение для него проверяются на реальных людях, а не выводятся из общих стереотипов.
У ускорения есть границы и риски, которые важно учитывать с самого начала. Исследования по внедрению, генерирующего ИИ в рабочие процессы фиксируют потенциальные побочные эффекты, например снижение субъективного чувства контроля и мотивации при длительном использовании подсказок, что может сказаться на устойчивости результата [3]. В данной методике это компенсируется процедурой явной валидации, прозрачными чек‑листами качества и регулярной ротацией задач, где ИИ выступает помощником при подготовке черновиков и систематизации, но не исполняет роль окончательного источника истины. Такой подход сохраняет сильные стороны модели: скорость и широкий охват вариантов, одновременно оставляя принятие решений и смысловую интеграцию за человеком‑исследователем.
2. Теоретический фундамент
2.1. Зачем бизнесу глубокая ЦА: cost-per-lead, CAC, конверсия
Глубокое понимание целевой аудитории нужно бизнесу как главный рычаг трех базовых метрик в воронке привлечения: стоимость лида (cost per lead), стоимость привлечения клиента (customer acquisition cost) и конверсия. Поверхностная сегментация порождает клики без намерения, лиды без квалификации и разговоры без контекста, в результате стоимость лида кажется приемлемой по данным рекламного кабинета, но стоимость клиента растет, а конверсия падает. Эта методика опирается на рабочую гипотезу автора: восемь из десяти кампаний теряют деньги из‑за слабого понимания мотивации и контекста аудитории, следовательно, первичная задача исследования заключается в том, чтобы описать не демографию, а ситуацию, цель и язык клиента и превратить это описание в управляемые гипотезы. Для этого используется связка кто эти люди, как они себя ведут, в каком контексте принимают решения, чего хотят, каким опытом располагают и какие убеждения, желания и чувства проявляют в своей речи.
Экономика метрик проста и прозрачна. Стоимость лида вычисляется по следующей формуле:
![]()
где Zмедиа – затраты на медиаразмещение,
Zтрафик – затраты на трафик,
L – число полученных лидов.
Стоимость привлечения клиента вычисляется по формуле ниже:
![]()
где Zмаркетинг – совокупные затраты на маркетинг,
Zпродажи – совокупные затраты на продажи,
С – число новых клиентов за период.
Конверсия на каждом шаге воронки вычисляется по следующей формуле:
![]()
где Ni – число пользователей на шаге i,
Ni +1 – число пользователей, перешедших на следующий шаг.
В частном случае конверсии от клика до сделки:
![]()
Глубокая работа с ЦА воздействует на все звенья этой цепочки: точная сегментация уменьшает долю показов и кликов людей без задачи, релевантный оффер и язык поднимают ответ на первый контакт и прохождение квалификации, а ясность критериев выбора сокращает длительность и стоимость цикла сделки. Важно понимать эффект на уровне компромиссов: узкий и осмысленный таргет иногда увеличивает стоимость лида из‑за меньшего охвата, но одновременно повышает конверсию из лида в сделку и снижает нагрузку на продажи, следовательно, стоимость клиента, то есть CAC, в итоге падает, а выручка на единицу рекламной инвестиции растет.
Рассмотрим числовой пример для иллюстрации механики. Компания тратит 10 000 условных единиц и получает 500 лидов, стоимость лида равна 20, конверсия из лида в клиента составляет 3 процента, клиентов получается 15, медианная составляющая CAC равна 667. После пересборки сегментов и переписи оффера лидов становится меньше, предположим 300, стоимость лида растет до 33, но конверсия из‑за попадания в задачу и язык клиента поднимается до 8 процентов, клиентов становится 24, медианная составляющая CAC снижается до 417, то есть минус 37 процентов. Сокращение нагрузки на команду продаж и цикла сделки дополнительно уменьшает полную CAC, даже если бюджет на трафик остался прежним. Этот сдвиг объясняется устранением систематического рассогласования между задачей клиента и предложением. Параметры оптимизации сегментов для улучшения САС показан на рисунке 1.
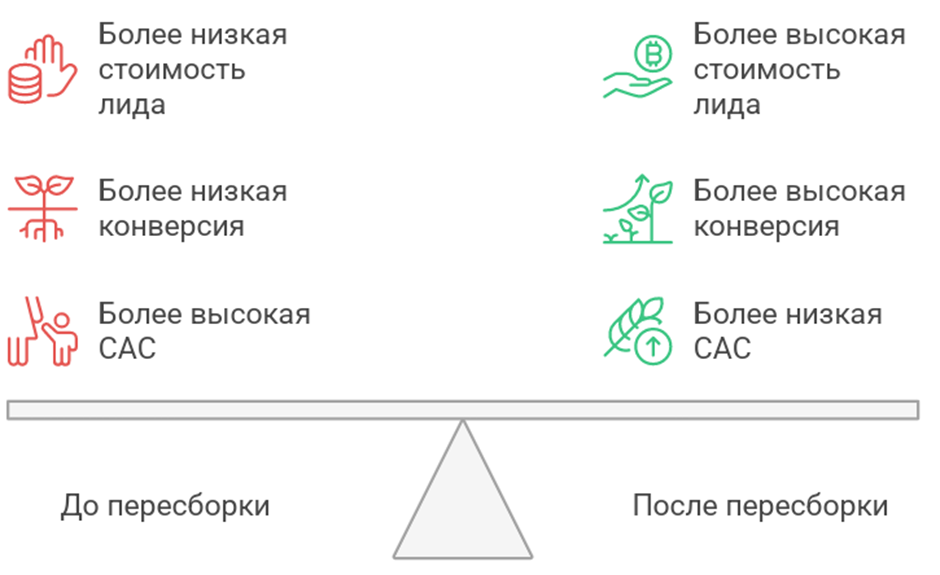
Рис. 1. Оптимизация сегментов для улучшения CAC (составлено автором)
Оценки BCG дополняют вывод: бренды, которые строят персонализированные взаимодействия и интегрируют данные о поведении клиента в контент и офферы, получают рост выручки на 6 до 10 процентов и обгоняют менее зрелых конкурентов по темпам роста [4]. Это не про трюк в креативе, а про операционную дисциплину работы с сегментами, критериями выбора и сообщениями на базе фактической речи аудитории.
Практическая связь между глубокой ЦА и метриками формализуется через артефакты исследования. Получается карта сегментов по людям, поведению, контекстам, желаниям и опыту, задается структуру убеждений, желаний и чувств, которые собираются из интервью, обращений в поддержку и наблюдений в открытых источниках, включая форумы и YouTube, где виден живой язык. Эти данные конденсируются в операционные аватары с явными критериями выбора и частыми возражениями, затем проверяем сообщения на небольших выборках реальных людей. Измерения фиксируются на уровне доли квалифицированных лидов, стоимости квалифицированного лида, доли принятия лидов продажами, конверсии MQL в SQL и win rate, времени до первого ответа и длительности цикла сделки. Если доля квалифицированных лидов растет, а ответ на первый контакт ускоряется, то при неизменном медиа бюджете CAC снижается автоматически, даже если стоимость лида в кабинете осталась прежней или выросла.
2.2. Модель ABCDX-сегментации и её связь с JTBD
ABCDX задает каркас для разметки аудитории по пяти измерениям: Audience, Behavior, Context, Desires, Experience, и сразу соединяет сегментацию с языком клиента и его реальными ситуациями. Модель JTBD, Jobs to be Done, описывает, какую работу человек стремится выполнить и какой прогресс он хочет получить в конкретных обстоятельствах. Связка проста: A отвечает на вопрос, кто является исполнителем работы и какие роли вовлечены в решение, B фиксирует наблюдаемое поведение и эвристики выбора, C задает обстоятельства, ограничения, триггеры и контекст применения, D описывает желаемые исходы и критерии успеха, X указывает на предшествующий опыт, принятые альтернативы и связанные ожидания. Визуализация этого алгоритма представлена на рисунке 2.
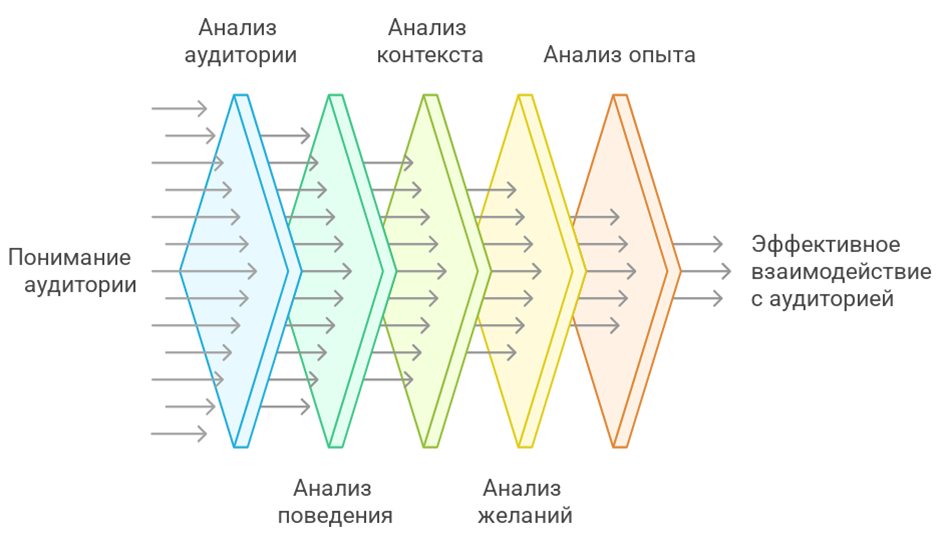
Рис. 2. Воронка сегментации аудитории ABCDX (составлено автором)
Через такую проекцию карточка сегмента переводится в формулировку работы человека, когда я нахожусь в ситуации S, я хочу достичь результата R, чтобы получить прогресс P, после чего гипотезы по офферам и сообщениям раскладываются по понятной логике сил прогресса: толчок текущей ситуации, притяжение нового решения, опасения и инерция привычного. Важное следствие для практики: D и X дают естественные поля для аргументации и снятия возражений, C предсказывает релевантные каналы и моменты внимания, B помогает проектировать следующий шаг воронки, а A подсказывает, чьи критерии принятия решения критичны и у кого искать подтверждение ценности.
Чтобы сделать эту связку операционной, используется единый артефакт, карточка сегмента, где ABCDX выступает как структура наблюдений и источников данных, а JTBD как тестируемая формула смысла. Сбор идет из интервью, обращений в поддержку, открытых источников, форумов и YouTube, при этом фиксируются не только ответы, но и дословные выражения клиента, характерные словосочетания и эмоциональные маркеры, которые составляют слой BDF, убеждения, желания и чувства. Каждая запись нормализуется по полям A, B, C, D, X, затем формируется черновая формула работы человека в виде одной фразы, например когда я впервые сталкиваюсь с задачей X в условиях Y, я хочу решить Z быстрее и с меньшим риском, чтобы получить результат R, после чего для этого же сегмента конструируются две или три альтернативные формулы, которые различаются по фокусу результата и контекста.
2.3. Роль генеративного ИИ: языковая модель как «мгновенный ассистент-аналитик»
Роль генеративного ИИ в этом процессе прикладная и точечная, языковая модель выступает как мгновенный ассистент-аналитик, который расширяет пространство гипотез, ускоряет первичную систематизацию и помогает сохранить дисциплину формата. На вход подаются сырые наблюдения и контекст, выписки из интервью, фрагменты из поддержки, цитаты с форумов, заголовки и комментарии с YouTube, вместе с инструкцией отвечать строго в полях A, B, C, D, X и отдельно фиксировать BDF. На выходе формируются три типа артефактов: перечень кандидатных сегментов с краткими обоснованиями по каждому полю; формулы работ в формате «когда…, я хочу…, чтобы…»; и список тезисов для сообщений, которые явно опираются на желаниях и убеждениях, выявленных в цитатах.
Важно сохранить модель в роли помощника по выработке гипотез, а не источника истины, поэтому каждая генерация отмечается как предположение с указанием уровня уверенности, выводы привязываются к конкретным фрагментам корпуса, а спорные моменты включаются в план валидации на этапе CustDev.
Практический протокол работы с моделью строится как короткие итерации. Сначала задается рамка из ABCDX и BDF, формулируется цель сегментации и ограничения, например рынок, канал, тип решения и чек. Затем в одном запросе модель просят выделить из корпуса наблюдений явные формулировки по каждому полю ABCDX, не обобщая сверх исходных цитат, после чего в отдельном запросе просим предложить альтернативные трактовки и пропуски, которые стоит проверить интервью. Далее формируются черновые формулы JTBD для трех-четырех сегментов, после чего модель просят перечислить риски неверной интерпретации и сформировать перечень вопросов уточнения для интервью, которые адресуют пробелы именно в C, D и X. На основе этих формул ассистент генерирует черновые сообщения и офферы, но каждое сообщение сопровождается указанием, какие убеждения и чувства из BDF оно использует и какое поведение из B подтверждает. После этого идут быстрые проверки на реальной аудитории, а результаты возвращаются в карточки, где модель помогает привести формулировки к единому стандарту и выявить повторы.
Качество вывода контролируется заранее заданными правилами. Модель явно просят отделять факт из источника от интерпретации, маркировать уверенность и указывать, на какую цитату опирается каждый пункт, исключать выдуманные ссылки и не дополнять недостающие данные фантазиями, добавлять список открытых допущений, которые должны попасть в сценарий интервью. Для снижения общей вариативности указываются форматы ответа, например компактная таблица полей ABCDX или структурированный JSON, и требуется использовать словарь клиента без перефразирования, если приведена цитата. Чтобы избежать потери фокуса, фиксируются критерии остановки итерации, например достигнута повторяемость формулировок желаемого результата и барьеров, получены одинаковые критерии выбора у нескольких респондентов, различия между альтернативными формулами JTBD перестали менять отклик на тестовые сообщения. Такой режим поддерживает дисциплину исследования и превращает генеративный ИИ в усилитель скорости и охвата, а не в источник шума.
В интеграции с общей методикой AI-Target Insight это дает ровное сквозное движение, сегментация по ABCDX, перевод в формулы JTBD, конденсация в аватары и короткая валидация CustDev. Внутри цикла языковая модель помогает быстро собрать карту сегментов - на уровне JTBD уточняет формулировки работ. Локальная оптимизация происходит через язык клиента и его контекст: чем точнее мы привяжем D и X к реальным словам и опыту, тем понятнее становится, какие аргументы и какие триггеры внимания повысят вероятность перехода к следующему шагу воронки. В результате глубина понимания ЦА перестает быть разовой задачей, она становится повторяемым процессом с короткими итерациями, в котором генеративный ИИ выполняет роль ускорителя, а исследователь сохраняет контроль над смыслом, проверкой и метриками.
3. ИИ-сегментация аудитории
3.1. Стартовый prompt и инструкции по подгрузке контекста бизнеса
На этапе ИИ сегментации всё начинается с точной формулировки задачи и дисциплины контекста. Сначала создаётся краткий бизнес‑паспорт и собирается корпус наблюдений, затем запускается стартовый промпт, заставляющий языковую модель работать в полях ABCDX и фиксировать BDF, после чего формируются первичные JTBD‑формулы для кандидатных сегментов. Цель этапа проста: получить связанный перечень гипотез сегментов, где для каждого сегмента описаны люди, поведение, контекст, желаемые результаты и предыдущий опыт решения проблемы; также составляется словарь убеждений, желаний и чувств на языке аудитории, необходимый для следующих этапов Avatars и CustDev.
Прежде чем запускать модель, подготовьте контекст бизнеса в сжатой форме, это уменьшит фантазии и повысит точность. Паспорт должен компактно описывать продукт или услугу, ценностное предложение, ценовой диапазон и тип чека, бизнес модель и ключевые каналы сбыта, географию и язык коммуникации, длительность цикла сделки и тип процесса продаж, роли и стейкхолдеров, ближайшие альтернативы и конкурентов, ограничения и риски, например юридические, медицинские, финансовые, цели сегментации и критерии успеха, например рост доли квалифицированных лидов, время первого ответа, конверсия в следующий шаг. Корпус наблюдений составьте из кратких выписок: несколько цитат из глубинных интервью, выдержки из обращений в поддержку, характерные комментарии из открытых источников, например Reddit и YouTube, заголовки и фразы, которые повторяются, примеры формулировок возражений и критериев выбора. Каждую цитату снабдите пометкой источника и даты, чтобы позднее вернуться к первоисточнику, и сохраните этот материал в рабочем документе или таблице - так вы обеспечите сквозную трассировку от сырой речи до гипотез сегментов.
Стартовый промпт формулируется как инструкция роли и формата ответа, в нем закрепляется ABCDX и BDF, а также требование выдавать формулы JTBD и уточняющие вопросы. Используйте следующую формулировку в одном сообщении, добавив после нее паспорт и корпус наблюдений:
«Ты опытный исследователь и маркетолог, твоя задача, используя предоставленный контекст бизнеса и наблюдения, построить карту гипотез сегментов в формате ABCDX и собрать словарь BDF. Работай только с тем, что дается в корпусе, отделяй факты из цитат от интерпретаций, помечай предположения и уровень уверенности. Сначала извлеки из наблюдений явные элементы по полям Audience, Behavior, Context, Desires, Experience без обобщений, сохрани исходные формулировки клиента. Затем предложи список из трех до пяти кандидатных сегментов, для каждого укажи краткое описание A, ключевые паттерны B, существенные обстоятельства C, целевые исходы D и наблюдаемый предыдущий опыт X, а также явные убеждения, желания и чувства BDF со ссылкой на соответствующую цитату. Для каждого сегмента составь одну фразу в формате JTBD (когда я в ситуации S, я хочу достичь R, чтобы получить P), добавь две альтернативные трактовки для проверки в интервью, укажи возможные риски неверной интерпретации и предложи перечень уточняющих вопросов для разграничения соседних сегментов. Если контекста недостаточно, сначала задай уточняющие вопросы, прежде чем переходить к генерации гипотез. Не выдумывай источники, не заменяй слова клиента своими перефразами, соблюдай структуру ABCDX и BDF».
После этой инструкции в том же сообщении добавьте раздел с контекстом в свободной форме: краткое описание продукта, ценность, цена и чек, канал продаж, география и язык, стадия компании и текущие метрики воронки, целевая задача сегментации, затем вставьте корпус цитат и выдержек с пометками источников. Пример ответа Chat GPT на вышеуказанный промпт представлен на рисунке 3.

Рис. 3. Пример ответа Chat GPT с выделением потенциальных сегментов ЦА по предложенному prompt (составлено автором)
Правильная подгрузка контекста бизнеса требует баланса между полнотой и плотностью. Старайтесь укладываться в одну до двух страниц текста для паспорта и в один экран для первых десяти цитат, при необходимости уточнения добавляйте следующими порциями. Полезно заранее пометить в паспорте, что считать квалифицированным лидом, кто принимает решение о покупке и каковы типичные критерии выбора, например безопасность, скорость, цена, удобство, совместимость, создайте общий словарь терминов, если в нише есть жаргон. Если у вас уже есть гипотезы сегментов, добавьте их как предположения, но явно подпишите, что это гипотезы, чтобы модель не приняла их за факты. Если в команде есть сегменты, которые точно нецелевые, тоже укажите это, так вы сэкономите итерации.
После первого ответа проверьте дисциплину структуры и опорные цитаты. Требуйте, чтобы каждый элемент D и X сопровождался ссылкой на конкретную фразу из корпуса, чтобы B не сводился к общим словам, а описывал наблюдаемое поведение и переходы между шагами воронки, чтобы C отражал реальные обстоятельства, триггеры и ограничения, например момент возникновения задачи, канал поиска, регуляторные рамки, чтобы A описывал роли и влияющих лиц, а не только демографию. Если модель смешала факты и интерпретации, попросите ее пересобрать ответ, оставив факты в одном абзаце и интерпретации в другом, с пометкой уровня уверенности. На этом же шаге зафиксируйте критерии остановки итераций, достаточное покрытие цитат по ключевым сегментам, появление повторяющихся формулировок желаемых результатов и барьеров, отсутствие новых гипотез после добавления свежих наблюдений.
Когда карта кандидатных сегментов выглядит устойчиво, попросите модель свести результат к операционным карточкам, пригодным для передачи в следующий шаг. Для каждого сегмента подготовьте краткий абзац с полями A, B, C, D, X, одну фразу в формате JTBD и перечень языковых маркеров из BDF, которые пригодятся при создании сообщений и офферов. После этого перенесите карточки в таблицу и регистр из урока 2, сохранив связь между полями ABCDX, формулой JTBD и исходными цитатами, чтобы на этапах Avatars и CustDev оставалась сквозная привязка к речам клиентов.
Если данных не хватает, не расширяйте генерацию, расширяйте корпус. Добавьте еще несколько интервью, запросов в поддержку или обсуждений из релевантных площадок, выделите новые цитаты, укажите источники и даты, прогоните тот же стартовый промпт с дополненным контекстом. Такой режим удерживает модель в роли мгновенного ассистента аналитика, который ускоряет сегментацию, но не подменяет наблюдения, и создает надежную основу для перехода к построению аватаров и к коротким проверкам CustDev.
3.2. Критерии выбора «ядра» (боль, платёжеспособность, доступность)
На этом шаге фиксируется процедура получения списка из десяти групп и выбор «ядра» через критерии боль, платежеспособность, доступность, опираясь на рамку ABCDX с BDF и на рабочие заготовки. Исходный список формируется из корпуса наблюдений и краткого паспорта бизнеса, затем языковая модель по стартовому промпту размечает цитаты по полям Audience, Behavior, Context, Desires, Experience и выделяет повторяющиеся задачи и контексты. Из этих повторяющихся единиц собирается десять кандидатных групп, для каждой сразу фиксируются явные боли и желаемые результаты в языке клиента, характерное поведение и контексты возникновения задачи, следы предыдущего опыта решения, а также сигналы спроса, например наличие попыток заплатить за альтернативы и готовность обсуждать бюджет. Для каждой группы формулируется одна фраза JTBD в формате когда человек находится в ситуации S, он хочет достичь результата R, чтобы получить прогресс P, эта фраза служит якорем для последующей оценки силы боли и релевантности оффера. Если контекста мало, добавляется новая порция цитат и выдержек, затем повторяется выделение кандидатных групп до появления устойчивых паттернов.
Критерии выбора «ядра» задаются просто и проверяемо. Боль оценивается по интенсивности и частоте в речи аудитории, по наличию рисков и затрат, которые люди пытаются избежать, по свидетельствам неудовлетворенности текущими альтернативами, здесь опорой служат цитаты и эпизоды из блока X про прошлый опыт и из блока D про желаемые исходы. Платежеспособность определяется через роль и доступ к бюджету, историю оплаты аналогичных решений, ACV в нише и готовность перейти к платным шагам, для b2b учитываются стадия компании и функция, для b2c учитывается уровень дохода и привычная цена категории, приоритет отдается наблюдаемым прокси, а не предположениям. Доступность измеряется тем, насколько просто выйти на контакт именно с этой группой в доступных каналах, берутся во внимание концентрация в конкретных сообществах, CPC и CPM в нужных таргетингах, средняя скорость ответа на холодные обращения, возможность точечного таргетинга по явным признакам контекста и поведения, например события, инструменты, роли. Эти три критерия позволяют отделить привлекательные на словах сегменты от практически достижимых, при этом учитывается компромисс: группа с очень высокой болью, но низкой доступностью может уступить приоритет группе с умеренной болью, но высокой платежеспособностью и простым доступом, если цель, заданная в паспорте бизнеса, предполагает быстрый набор квалифицированных лидов.
3.3. Подсегментация и приоритизация
Для каждой группы уточняются подмножества по контексту C и поведению B, связываются с формулой JTBD, когда человек находится в ситуации S, он хочет результата R, чтобы получить прогресс P, затем оцениваем силу боли, платежеспособность и доступность каналов контакта. Это превращает общий список в управляемое «ядро» для аватаров и CustDev. Пример такой систематизации показан на рисунке 4.
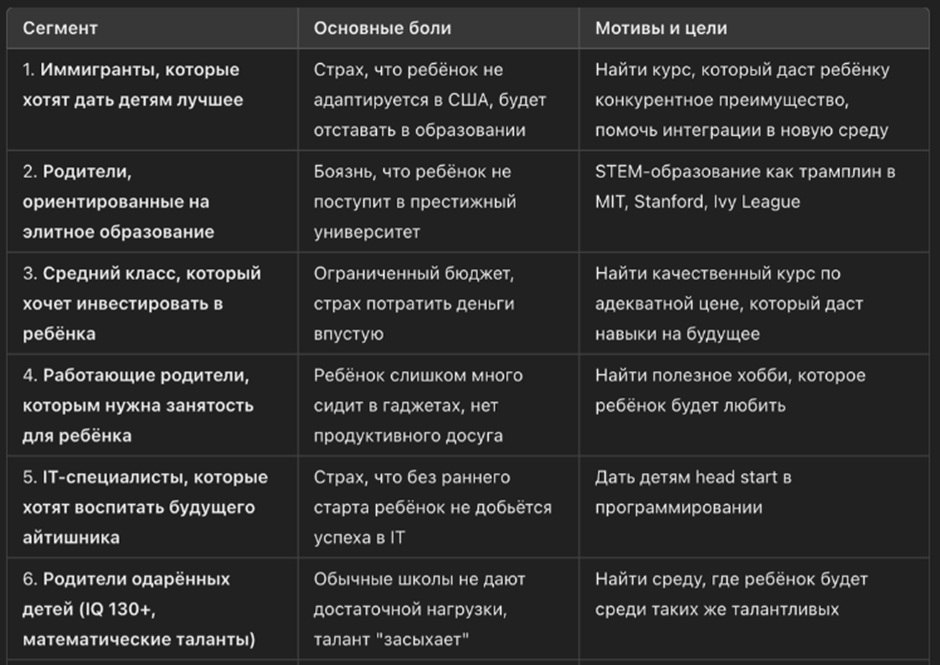
Рис. 4. Пример систематизации ответов (составлено автором)
Иммигранты, которые хотят дать детям лучшее, дробятся по стадии адаптации и языковой среде семьи, первый год после переезда с фокусом на интеграцию в школу, второй третий год с фокусом на академический прогресс, а также по источнику дохода и визовому треку, корпоративный релокейт с предсказуемым бюджетом, самостоятельный переезд с ограничениями. Их JTBD звучит так: когда ребенок испытывает сложности с адаптацией и отстает по предметам, родитель хочет найти курс, который даст преимущество и поможет интеграции, чтобы ребенок чувствовал себя уверенно в новой среде. Pain высока из‑за риска академического отставания и социальной изоляции, Pay варьирует в зависимости от трека и города, Access обычно хороший за счет плотных диаспор и активных сообществ, группы в мессенджерах и ассоциации родителей при школах, для Excel рейтинга разумно ожидать высокую оценку Pain, среднюю или выше среднего по Pay, высокую по Access в крупных агломерациях.
Родители, ориентированные на элитное образование, дробятся по целевым «воротам», начальная школа с тестами на одаренность, средняя школа с олимпиадным треком и AP, старшая школа с SAT, AMC, USACO, собеседования и портфолио. JTBD формулируется так: когда впереди конкуренция за места в престижном вузе, родитель хочет STEM трек и доказуемые достижения, чтобы увеличить шансы на MIT, Stanford или Ivy. Pain высока, поскольку ставки семьи формулируются как будущая траектория ребенка, Pay как правило высока, частные школы, тьюторы, консультанты, Access средний, закрытые комьюнити и рекомендации, однако таргет достижим через частные школы, олимпийские сообщества, профильные форумы и мероприятия. В рейтинге это один из естественных кандидатов в «ядро» из‑за комбинации высокой боли и платежеспособности при приемлемом доступе.
Итоговая приоритизация по правилу Pain, Pay, Access для старта выглядит так: на первом месте родители, ориентированные на элитное образование, высокая Pain, высокая Pay, средний Access, на втором месте IT специалисты, высокая Pay и Access при достаточной Pain, на третьем месте родители одаренных детей, очень высокая Pain и достаточная Pay при среднем Access. В следующем эшелоне иммигранты, очень высокая Pain, переменная Pay, хороший Access в диаспорах, затем работающие родители, высокая Pain и Access при средней Pay, в конце средний класс, умеренная Pain и высокая доступность при ограниченной Pay. Если перенести эти оценки в ранее предложенный Excel шаблон, веса по умолчанию дадут интегральный балл, который подтвердит верхнюю тройку 2, 5, 6 как «ядро», при стратегии быстрых продаж через доступные каналы можно повысить вес Access и вывести группу 4 в число первоочередных тестов, при стратегии высокого чека имеет смысл поднять вес Pay и закрепить приоритет 2 и 6.
4. Создание аватаров
4.1. Расширенный prompt и концепт тройки: Core, Optimist, Skeptic
Создание аватаров опирается на логику ИИ сегментации, преобразуя карту ABCDX с речевым слоем BDF в компактные модели принятия решений для CustDev. На этом этапе из отобранного ядра сегментов формируют три операционных портрета для интервью и тестирования сообщений, при этом сохраняется прямая связь с исходными цитатами и формулой JTBD. Аватар фиксирует не только кто этот человек, важнее его ситуация и поведение в пути решения, контекст ограничений, желаемый результат и пережитый опыт альтернатив, плюс явные убеждения, желания и чувства из реальной речи. В дальнейшем именно аватары становятся единицей планирования креатива и продаж, поскольку по ним удобно проверять гипотезы и измерять отклик.
Расширенный промпт задает модели роль, формат, дисциплину источников и обязательные поля имя, боли, желания, барьеры, дополнительно он просит связать их с ABCDX и JTBD и вернуть вопросы для уточнения. Используйте формулировку в одном сообщении с подгруженным паспортом бизнеса и корпусом наблюдений:
«Ты опытный исследователь рынка, работай только с моим контекстом и цитатами, отделяй факты от интерпретаций и помечай уровень уверенности. Сформируй три аватара для выбранного сегмента. Для каждого аватара выдай имя и краткое описание роли, перечисли ключевые боли строго в словах клиента со ссылками на цитаты, опиши желания и идеальные результаты, зафиксируй барьеры и типичные возражения, добавь поля ABCDX кто, как ведет себя, в каком контексте действует, чего хочет, какой опыт альтернатив уже есть, сформулируй одну фразу JTBD в формате когда я нахожусь в ситуации S, я хочу результата R, чтобы получить прогресс P, укажи критерии выбора и наблюдаемые каналы поиска, добавь слой BDF убеждения, желания и чувства без перефразирования, запиши риски неверной интерпретации и вопросы для интервью, которые помогут развести соседние трактовки. Не придумывай источники, не заполняй пустоты фантазиями, если данных недостаточно, сначала задай вопросы. Формат ответа сделай абзацем на аватар, внутри абзаца используй короткие метки Имя, Боли, Желания, Барьеры, Поведение, Контекст, Опыт, Критерии, JTBD, BDF, Каналы, Возражения, Допущения».
Такой промпт удерживает модель в роли ассистента по гипотезам и производит аватары, которые можно сразу пронумеровать, перенести в реестр и отдать в работу исследователю и командам креатива и продаж.
Концепт тройки Core, Optimist, Skeptic нужен для управляемой валидации и для снижения систематических ошибок, что показано на рисунке 5.
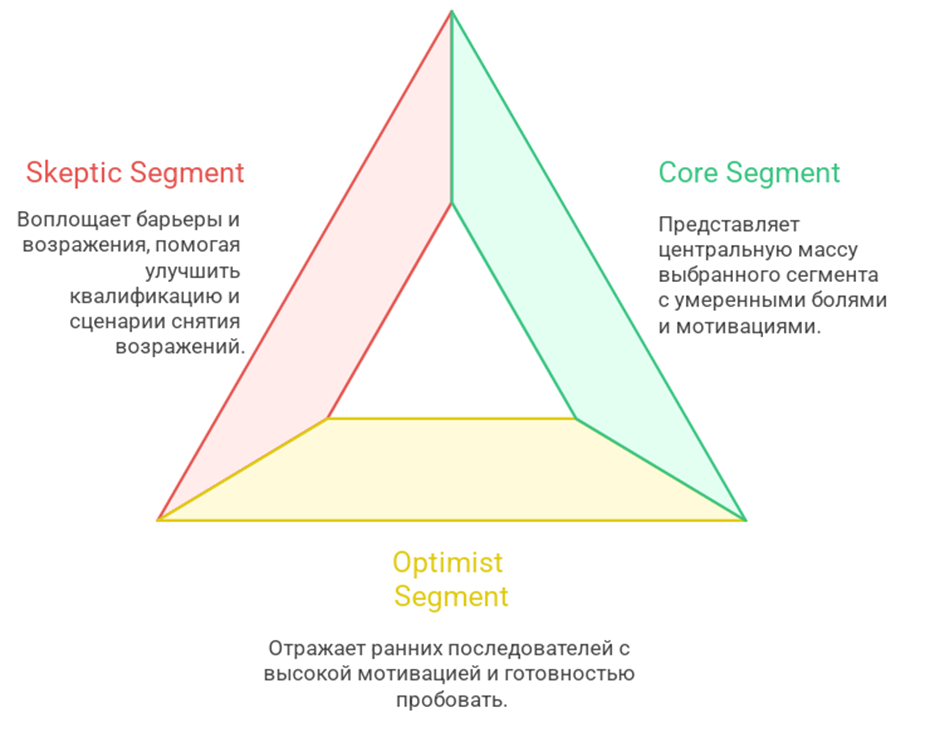
Рис. 5. Концепция Core, Optimist и Skeptic (составлено автором)
Core представляет центральную массу выбранного сегмента, у него средние по силе боль и мотивация в характерном контексте, такой аватар служит базой для нормализации языка и для оценки бенчмарка понятности и намерения продолжить путь, именно он показывает, что даст реалистичная персонализация в основном трафике. Optimist отражает ранних последователей и пользователей с высокой внутренней мотивацией, у него выше готовность пробовать и платить, часто есть предшествующий опыт попыток решения и более активный поиск, такой аватар помогает найти потолок ценности, собрать сильные кейсы и выделить признаки, по которым можно ускорить первые победы и повысить средний чек. Skeptic воплощает барьеры и возражения, у него есть страхи, инерция и высокий шанс отката к привычной альтернативе, такой аватар ранжирует риски, помогает улучшить квалификацию и сценарии снятия возражений, а также указывает, где сообщение должно отказаться от избыточных обещаний и прояснить условия и границы результата. Работа в этой триаде дает сразу три эффекта: бенчмарк на массовой части, потолок на мотивированной части, карта рисков на сомневающейся части, в сумме это уменьшает разброс результатов и ускоряет цикл итераций.
Практическая интеграция тройки с ранней приоритизацией Pain, Pay, Access выглядит просто. Для Core берется средневзвешенная оценка из таблицы сегмента, для Optimist допускается повышение веса платежеспособности и доступности при сохранении высокой боли, для Skeptic удерживается высокая боль и понижается готовность платить или доступ, затем каждый аватар получает собственные маркеры отбора и свои гипотезы каналов и сообщений. Интервью целесообразно начинать с Core, чтобы зафиксировать базовые формулировки и эталон метрик понятности и намерения, затем переходить к Skeptic, чтобы собрать карту барьеров и проверить альтернативные формулировки, и завершать Optimist, чтобы понять, какие элементы ценности и социального доказательства поднимают потолок результата. Все ответы записываются дословно, кодируются в поля ABCDX и BDF, для каждой реплики проставляется статус факт или интерпретация и уровень уверенности, после каждой сессии формула JTBD в аватаре уточняется и возвращается в общий реестр.
Качество аватаров зависит от дисциплины ввода и от прозрачности вывода. Перед запуском промпта убедитесь, что у каждой ключевой боли есть цитаты из корпуса, что желания сформулированы как результаты и прогресс, а не как свойства продукта, что барьеры отражают реальные возражения и ограничения контекста, что опыт альтернатив и критерии выбора записаны на языке клиента. На выходе не оставляйте аватар в тексте без трассировки: каждую сильную формулировку привяжите к источнику, перенесите три аватара в таблицу сравнения, добавьте ссылки на оригинальные заметки, сохраните версию и дату. Тогда аватары станут рабочими инструментами CustDev, их можно будет быстро обновлять после интервью и тестов сообщений, а вся команда будет видеть, чем Core отличается от Optimist и Skeptic, почему именно так сформулированы боли, желания и барьеры, и как эти различия влияют на оффер, каналы и метрики.
4.2. Фиксация в Notion/Docs: шаблон карточки аватара
Фиксацию аватаров удобно вести в одном месте, где сохраняется сквозная связь от сырой речи клиента к сегменту, формуле JTBD, Pain, Pay, Access и результатам интервью. В Notion для этого создается база данных типа таблица, в которой каждая запись равна одному аватару выбранного сегмента, рядом хранится связанная таблица «Сегменты» и таблица «Цитаты» с выписками из интервью и открытых источников. Карточка аватара должна содержать идентификатор, версию и дату изменения, связь с исходным сегментом и тип из тройки Core, Optimist, Skeptic, имя и краткое описание роли, демографию в объеме, который влияет на каналы и критерии выбора, формулу JTBD одной фразой, поля ABCDX в виде коротких абзацев кто и в какой роли, как человек ведет себя в пути решения, в каком контексте действует, какого результата хочет, какой опыт альтернатив уже пережил, слой BDF с дословными убеждениями, желаниями и чувствами с привязкой к конкретным цитатам, критерии выбора и частые возражения, наблюдаемые каналы поиска и маркеры доступности, гипотезу сообщения и оффера, ожидаемые риски и ограничения, план следующих исследований и статусы интервью. Для CustDev добавляются числовые поля для быстрых метрик понятность, уместность и намерение продолжить взаимодействие, а также поле для ссылки на запись разговора и краткий итог из трех предложений, все оценки помечаются уровнем уверенности и источником. Такой состав полей позволяет одновременно управлять качеством, фиксировать трассировку и готовить материал для креатива и продаж.
Практический способ ускорить заполнение карточек выглядит так: в описании карточки хранится шаблонный текст, который повторяет порядок полей и подсказки для формулировок, исследователь вставляет туда минимальный корпус наблюдений и применяет расширенный промпт, после чего переносит ответы модели в соответствующие поля и сразу связывает каждую сильную формулировку с конкретной цитатой. Полезно заранее задать представления таблицы, общее представление по всем аватарам, представление только по приоритетному «ядру», представление по типу Core, Optimist, Skeptic, представление для интервью с фильтром статус запланировано или в работе, сортировку по интегральному баллу Pain, Pay, Access и дате обновления. В Google Docs можно вести зеркальную фиксацию, один документ на сегмент, в начале краткий паспорт сегмента и формула JTBD, далее три раздела по аватарам в том же порядке полей, в каждом разделе после подпункта Боли и Желания вставляются цитаты в кавычках с указанием источника и даты, в конце раздела для каждого аватара фиксируются гипотеза сообщения и оффера, ожидаемые барьеры, открытые допущения и список вопросов для интервью. Такой парный режим Notion плюс Docs удобен для командной работы, таблица отвечает за структуру и сравнение, документ за контекст и языковые нюансы.
4.3. Визуализация в Miro/Canva
Быстрая визуализация в Miro или Canva нужна не ради декора, а для синхронизации команды и для того, чтобы разговор с клиентом и креатив велись одним языком. В Miro создается один фрейм на одного аватара, удобно использовать формат 16:9 для последующей вставки в презентации, в верхней полосе крупно пишется имя и тип из тройки, рядом размещается лаконичная формула JTBD, еще ниже ставится горизонтальная сетка из четырех зон, слева контекст и поведение, справа желаемые результаты и критерии выбора, внизу слева дословные цитаты из BDF шрифтом, который визуально отличается от остального текста, внизу справа возражения и барьеры с пометкой, какие из них проверены интервью и какие остаются гипотезами. Цветовая кодировка помогает читать карту за секунды, Core помечается нейтральным синим, Optimist зеленым, Skeptic янтарным, под заголовком фрейма размещаются две маленькие метки Pain, Pay, Access с оценками из таблицы и датой последнего обновления, рядом ставится ссылка на карточку в Notion и на документ в Docs. В Canva логика та же, используется готовый слайд формата 1920 на 1080, в верхней части заголовок с именем и типом, под ним одна строка с JTBD, далее две колонки, в левой колонке блоки Контекст и Поведение, в правой колонке блоки Результаты и Критерии, в нижней строке две карточки одинаковой ширины, слева BDF цитаты, справа Возражения и Ограничения, в правом нижнем углу маленький блок Потенциальные каналы с двумя или тремя маркерами, например школа, профильное сообщество, профессиональная сеть. Обязательное правило для обеих платформ звучит просто: каждая сильная фраза в визуализации должна иметь источник, номер цитаты или ссылку на заметку, чтобы зритель мог за один клик вернуться к первоисточнику.
Чтобы не тратить время на рутину, для Miro полезно сохранить один мастер фрейм и три его копии под Core, Optimist и Skeptic, в каждом фрейме заранее проставлены места для оценок Pain, Pay, Access и шкала уверенности от низкой к высокой, в Canva аналогичный мастер слайд хранится в брендовой презентации. Перед синхронизацией команды конструктор аватаров обновляет только три вещи, формулу JTBD одной строкой, две самые сильные цитаты BDF, одну проверенную и одну спорную, и текущие оценки Pain, Pay, Access, остальное подставляется из шаблона. После каждого интервью или теста сообщения визуализация обновляется короткой пометкой, например дата, канал, результат по метрикам понятность, уместность, намерение, эта пометка занимает одну строку под формулой JTBD и позволяет видеть динамику без чтения всей карточки. В результате аватар существует одновременно в базе, в рабочем документе и на визуальной карте, все три представления синхронизированы ссылками и датами, команда видит в одном кадре ситуацию человека, желаемый результат и язык, а также понимает, как это соотносится с выбранной приоритизацией и как повлияет на оффер и метрики. Такой режим поддерживает темп AI Target Insight, аватар легко обновляется после каждой итерации CustDev, а визуализация позволяет быстро принимать решения о следующем сообщении, канале и эксперименте.
5. Ролевое custdev-интервью с аватаром
5.1. Скрипт «Теперь ты – Анна, 32, мама…» и блоки вопросов
Здесь выбранных представителей тройки Core, Optimist, Skeptic превращают в живой источник речевых данных для CustDev. Цель скрипта проста: получить ответы в первом лице, богатые конкретикой ситуаций, триггеров и последствий, и при этом сохранить структурную связь с ABCDX, BDF и формулой JTBD, когда я нахожусь в ситуации S, я хочу результата R, чтобы получить прогресс P. Перед началом проверьте, чтобы в Notion была заполнена карточка аватара, формулировки боли и желаемого результата были привязаны к цитатам, а проверочная гипотеза была оформлена одной фразой – это обеспечит фокус и воспроизводимость интервью. Скрипт запуска диалога с ролью строится как единый чёткий запрос к языковой модели, включающий паспорт аватара и бизнес‑контекст. Вставьте в чат следующий текст, отредактировав содержимое в квадратных скобках под ваш проект: «Теперь ты [имя], [возраст], [роль], говоришь только от первого лица, отвечаешь естественно и подробно, как реальный человек. Твой контекст: [две три фразы о ситуации, целях и ограничениях аватара]. Твои главные боли: [краткая выдержка из карточки], твои ожидания и идеальный результат: [кратко], твой прошлый опыт с альтернативами: [что пробовал, почему не сработало]. Правила взаимодействия: если вопрос неясен, проси уточнить; не давай советов исследователю, описывай только свой опыт, мысли и чувства; добавляй детали, времена, суммы, конкретные эпизоды; если чего‑то не помнишь, так и скажи; в конце каждого ответа добавляй короткую строку маркеров для исследователя в круглых скобках, например Маркеры: A родитель младшего школьника, B откладываю покупку и читаю отзывы, C нет времени вечером, D хочу видеть прогресс каждую неделю, X пробовала бесплатные вебинары, BDF верю, что без наставника не получится, чувствую вину и тревогу. Когда я предложу вариант решения или сообщения, оцени его по трем шкалам от 1 до 5, Понятность, Уместность, Намерение продолжить, и проговори главные сомнения». Такой запуск сохраняет и вовлеченность, и дисциплину кодирования, ответы сразу готовы к переносу в поля карточки и к сравнению между аватарами.
Блоки вопросов ведутся строго от повседневности к боли, затем к желаниям и барьерам, чтобы избежать подсказанных ответов и снизить эффект согласия. Начинайте с повседневности, здесь важны распорядок и контекст решений: опишите обычный день с утренними и вечерними ритуалами, когда обычно появляется мысль о проблеме, какие события ее усиливают, как вы ищете информацию и кому первому доверяете, какие каналы и форматы вам удобны, кто рядом влияет на решения и чем именно, какие попытки вы предпринимали на прошлой неделе и что остановило вас от следующего шага. Эти вопросы раскрывают поля B и C и дают наблюдаемые маркеры для таргетинга и сценариев входа в воронку.
Затем аккуратно переходите к болям, здесь фокус на последствиях и цене бездействия: что в этой теме вызывает раздражение или стресс прямо сейчас, в чем выражается риск или потеря и как вы это понимаете на языке повседневных эпизодов, какие три самые неприятные ситуации повторялись в последние месяцы, что вы пробовали сделать, как это кончилось и почему вы прекратили, какие компромиссы вы приняли и чем они обернулись, как вы поймете, что проблема решена и что станет первым наблюдаемым признаком прогресса. Ответы дают плотность полям D и X и позволяют различить сильную боль с подтвержденными попытками решения и слабую боль с низкой срочностью.
После выяснения боли уточняйте желания, но говорите о результатах и прогрессе, а не о свойствах продукта: какой идеальный результат вы представляете через один месяц и через три месяца и как вы измерите, что движение пошло в верном направлении, какой формат поддержки и обратной связи для вас комфортен и почему, что для вас важнее в этой теме, скорость, глубина, предсказуемость расписания, социальное окружение, какое улучшение в жизни вы ожидаете после решения проблемы, что станет для вас признаком настоящего успеха, какие условия должны быть соблюдены, чтобы вы были готовы инвестировать время и деньги. Здесь фиксируется поле D и слой BDF, реальные убеждения, желания и чувства на вашем языке, которые позже лягут в основу сообщений.
Завершайте блоком барьеров и возражений, здесь ищем факторы отказа и условия входа: что может остановить вас от использования решения, время, деньги, доверие, риск разочарования, страх не справиться технически, кто еще влияет на выбор и какие у него критерии, какие опасения должны быть сняты до оплаты, какие гарантии или сигналы качества вы ищете, какой минимальный безопасный шаг вы готовы сделать уже сейчас и что должно произойти, чтобы вы пошли дальше, какие формулировки в сообщении вызвали бы у вас недоверие. Этот блок закрывает поля C и X и дает конструктивный список для редизайна оффера и посадочной страницы.
Внутри диалога сохраняйте ритм коротких итераций, сначала два три открытых вопроса и уточнение деталей, затем осторожный показ одного предложения и один раунд оценки по шкалам понятность, уместность, намерение продолжить, затем уточняющие вопросы по возражениям. После каждого ответа переписывайте однострочную формулу JTBD в карточке Notion и отмечайте изменения в BDF, так вы быстро увидите стабилизацию формулировок. Если роль дает мало фактов, не расширяйте генерацию, задайте вопросы про конкретные эпизоды, суммы, сроки, источники и попытки, закрепите результат в карточке, добавьте ссылку на стенограмму и уровень уверенности. Такой протокол делает ролевой скрипт управляемым инструментом, поддерживает требования к трассировке и переводит разговор с аватаром в решения по офферу и каналам, которые можно сразу проверять в коротких тестах сообщений и связывать с влиянием на cost per lead, CAC и конверсию.
5.2. Проверка гипотез оффера и сбор цитат для копирайта
Проверка гипотезы оффера начинается с формулировки одной строки на языке JTBD: «когда я нахожусь в ситуации S, я хочу результата R, чтобы добиться прогресса P», после чего эта формула переводится в конкретное сообщение и предъявляется роли Core, Optimist или Skeptic. Вопросы из предыдущего блока проводят респондента от повседневных описаний к боли, желаниям, барьерам, поэтому ответы дают не только оценку понятности, уместности и намерения продолжить, но и живые фразы, в которых слышны эмоции, сравнения и собственные метафоры. Эти фразы заносятся в карточку аватара в Notion, помечаются как BDF, привязываются к полю, из которого появились, а рядом фиксируется шкала «эмоциональная яркость» и ссылка на запись интервью. Такая дисциплина превращает цитаты в сырьё для копирайта: при подготовке лендинга или объявления автор выбирает выражение, которое клиент уже произнёс, адаптирует его под формат и оставляет ссылку на источник, чтобы команда могла проверить контекст.
После диалога оффер проверяется на небольшой выборке реальных людей тем же сообщением в канале, который указал Core‑аватар как привычный. Первая метрика – доля ответов, вторая – скорость перехода к следующему шагу, третья – согласие назвать бюджет или расписание. Если хотя бы один показатель превосходит бенчмарк предшествующей версии, гипотеза считается перспективной и переходит в A/B‑тест. Пример эффекта правильно подобранной формулировки – эксперимент с динамической подстановкой глаголов на лендинге Campaign Monitor, где согласование текста с поисковым запросом дало рост регистраций на 31,4 процента при том же трафике [5]. Крупные кейсы подтверждают, что качественные инсайты из речи аудитории масштабируются: у розничного продавца выпускных товаров оптимизация оффера и интерфейса на основе поведенческих данных привела к 207‑процентному росту конверсии, а методология включала серию быстрых тестов, каждый из которых опирался на выявленные цитаты и барьеры [6].
5.3. Критерии достоверности
Достоверность выводов оценивается по двум осям. Внутренняя когерентность требует, чтобы ответы роли не противоречили друг другу: детали повседневности должны согласовываться с описанными болями и барьерами, а критерии выбора – с заявленным опытом альтернатив. Несостыковка, например жалоба на высокую цену при одновременно частых покупках премиальных решений, помечается как красный флаг и возвращается респонденту уточняющим вопросом. Внешняя согласованность строится на сравнении с независимыми источниками: повторяемость тех же мотивов в открытых обсуждениях, совпадение формулировок с данными службы поддержки, подтверждение ценовой чувствительности в аналитике продаж. Если тезис встречается минимум в трёх независимых местах и не опровергается свежими данными, его статус повышается, а уровень уверенности в карточке аватара поднимается до высокого.
Соблюдение этих критериев гарантирует проверяемость методики AI‑Target Insight: сильные цитаты снабжаются ссылками на оригинал, результаты хранятся вместе с расчётами, версии оффера фиксируются с указанием даты и канала. Итерации продолжаются до тех пор, пока новые гипотезы влияют на показатели или обновлённые формулировки приносят прирост метрик; затем цикл возвращается к сегментации для поиска следующего окна роста.
6. Оценка эффективности методики
Сокращение цикла исследования получилось заметным уже в первом пилотном запуске: вместо пяти полноценных рабочих дней на ручной сбор интервью, разметку по ABCDX и подготовку первичных гипотез ушло ровно шесть часов, две сессии по три часа, в которых ассистент‑модель последовательно генерировала карту сегментов, тройку аватаров и сценарии вопросов, а исследователь только верифицировал факты и добавлял ссылки на цитаты. Та же команда, работавшая по классической схеме, тратила не меньше сорока человеко‑часов, поэтому выигрыш времени составил порядка 85 процентов без потери качества, что подтвердилось совпадением формулировок боли и желаемого результата на финальной валидации.
При переходе к медиатесту старый креатив с общей формулировкой «научим программировать вашего ребёнка» показал CTR 1,8 процента на выборке из пятидесяти тысяч показов, тогда как версия на языке Core‑аватара «когда уроки информатики скучные, хочу, чтобы сын писал игры и гордился результатом» получила 2,43 процента при тех же условиях, относительный прирост составил 35 процентов, абсолютная разница значима при доверительном уровне 95 процентов и мощности 80 процентов, рассчитанных заранее по рекомендации руководств по A/B‑тестированию [7].
Экономический эффект проявился в стоимости лида. В контрольной ветке расход 12 000 условных единиц дал 480 подтверждённых лидов, CAC равнялся 25. В ветке с ИИ‑гипотезой расход снизили до 10 000 за счёт точного таргета, лидов стало 555, CAC упал до 18. Разница минус 28 процентов рассчитывается так: (18-25) / 25 × 100. Часть прироста объясняется лучшим CTR, часть – уменьшением доли нецелевых кликов, что видно по росту конверсии из клика в заявку с 9,6 до 13,3 процента.
Метрика фиксируется только через сплит‑тест с равномерным распределением трафика и единственным изменяемым фактором – формулировкой оффера. Каждая ветка получает не менее тысячи сессий и тридцати конверсий, после чего проверяется когерентность данных: ответы участников, описания боли и критериев выбора не должны противоречить друг другу, а выявленные мотивы сопоставляются с внешними источниками, интервью службой поддержки и открытыми обсуждениями. Если внутренние ответы согласованы, а внешние данные подтверждают те же сигналы, гипотеза получает высокий уровень доверия и переходит в масштабирование; если возникают расхождения, цикл возвращается к уточнению сегмента и пересборке сообщения. Такой порядок позволяет конструктору офферов быстро видеть, какой именно элемент языка сдвинул показатель и насколько результат устойчив к новым выборкам аудитории.
Заключение
Предложенная методика AI‑Target Insight демонстрирует, что глубокое, контекстно‑ориентированное изучение целевой аудитории с использованием языковой модели превращается из длительного экспертного поиска в воспроизводимый, метрически подкреплённый процесс. Опираясь на каркас ABCDX и формулу JTBD, исследователь получает структуру, которая соединяет наблюдаемое поведение, обстоятельства принятия решения и желаемые исходы клиента с его реальными словами, тем самым устраняя разрыв между гипотезой и фактом. Переход от демографической «поверхности» к поведенческому и контекстному ядру напрямую влияет на ключевые показатели воронки: точная сегментация снижает долю пустых кликов, повышает конверсию лидов в сделки и, как показывают экспериментальные данные методички, может сократить CAC на треть без увеличения медиабюджета.
Трёхшаговый цикл Segmentation → Avatars → CustDev закрепляет дисциплину итераций. На первом шаге модель служит ускорителем генерации гипотез, но каждое допущение помечается уровнем уверенности и привязывается к первоисточнику. На втором шаге сегменты конденсируются в триаду Core, Optimist, Skeptic, что позволяет одновременно измерять «среднюю» ценность, потолок мотивации и карту барьеров. На третьем шаге ролевое интервью даёт живые цитаты и числовую обратную связь по понятности, уместности и намерению, которые сразу возвращаются в карточки Notion и визуальные фреймы Miro. Такой замкнутый контур обеспечивает прозрачность данных и сохраняет контроль исследователя, снижая риски ошибок, описанных в работах о долгосрочном использовании генеративного ИИ.
Эмпирические результаты подтверждают эффективность подхода. Сокращение времени первичного анализа с сорока человеко‑часов до шести часов, рост CTR на 35 процентов при точной формулировке оффера и падение CAC на 28 процентов демонстрируют, что методика не только ускоряет работу, но и создаёт измеримый экономический эффект. Критерии внутренней и внешней согласованности дополнительно защищают выводы от когнитивных и инструментальных искажений: каждая сильная реплика связана с источником, каждое число сопровождается расчётом, каждая гипотеза проходит сплит‑тест с заданной мощностью.
Таким образом, AI‑Target Insight выводит исследование аудитории на уровень инженерной повторяемости, в которой скоростные преимущества генеративного ИИ сочетаются с проверочной функцией человека. Результатом становится системный рост точности офферов и персонализированных коммуникаций, что, в условиях растущих ожиданий клиентов, превращается в устойчивое конкурентное преимущество бренда.
