.png&w=384&q=75)
Актуальность исследования
Отказоустойчивость является ключевым свойством современных систем, обеспечивая их способность функционировать даже при сбоях компонентов, без прерывания работы или потери данных. В условиях растущей сложности распределённых, облачных и критически важных систем малочастотные (редкие) сбои могут приводить к серьёзным последствиям: финансовым потерям, утрате доверия пользователей и даже риску безопасности.
Традиционные методики бенчмаркинга отказоустойчивости, как правило, ориентированы на частые и стандартные сбои, и зачастую недостаточны для надёжной оценки систем в условиях редких, но потенциально катастрофических событий. С другой стороны, методы стресс-тестирования и внедрение неисправностей позволяют имитировать такие сценарии, но требуют значительных ресурсов и могут оказаться неэффективными или неповторяемыми без стандартизированных подходов.
В современном инженерном контексте критично развивать методы анализа отказоустойчивости, которые учитывают именно редкие сбои. Это необходимо не только для повышения надёжности, но и для ясной оценки рисков, определения узких мест и принятия обоснованных решений по оптимизации архитектуры и управления системами.
В структуре критически важных инфраструктур (КИИ) транспортный сектор занимает особое место: его сбои порождают каскадные эффекты в логистике, здравоохранении (медицинская эвакуация и доставка), продовольственных цепочках и системе общественной безопасности. Профильные регуляторы прямо относят транспорт к критическим секторам. Так, Агентство по кибербезопасности и безопасности инфраструктуры США (CISA) включает Сектор транспортных систем в перечень шестнадцати критических секторов [18]. В Европейском союзе обновлённая Директива (ЕС) 2022/2557 об устойчивости критических субъектов (CER) закрепляет подход к повышению устойчивости КИИ и прямо охватывает транспорт как одну из ключевых отраслей [6]. На этом фоне бенчмаркинг отказоустойчивости транспортных систем приобретает особую значимость.
Цель исследования
Целью данного исследования является разработка и обоснование комплексного подхода к бенчмаркингу отказоустойчивости систем, подверженных редким сбоям.
Материалы и методы исследования
Материалом исследования послужили современные публикации, отраслевые отчёты и кейсы применения бенчмаркинга отказоустойчивости. В исследовании использован собственный программный комплекс ResilienceBench, представляющий собой открытый репозиторий с Apache-2.0 лицензией.
Методы исследования включали:
- анализ теоретических моделей надёжности;
- сравнительный анализ существующих подходов к бенчмаркингу;
- систематизацию практического опыта ведущих компаний в DevOps и облачных инфраструктурах;
- выявление ограничений и проблем воспроизводимости результатов.
Результаты исследования
Теоретическая основа отказоустойчивости систем опирается на теорию надёжности, которая рассматривает методы и приёмы, обеспечивающие эффективную и безопасную работу сложных технических систем на всех этапах их жизненного цикла – от проектирования и производства до эксплуатации и хранения. Ключевую роль здесь играют количественные характеристики качества систем, такие как вероятность отказа, продолжительность безотказной работы и временные показатели восстановления, которые должны оцениваться и прогнозироваться на основе свойств составных частей системы.
Понятие отказоустойчивости определяется как способность системы сохранять свою работоспособность после выхода из строя одной или нескольких её составных частей [1]. Достигается это, прежде всего, за счёт избыточности – наличия резервных элементов или компонентов, способных компенсировать отказ. Пример: базовый уровень обеспечивается защитой от отказа одного элемента, что в критических системах является обязательным требованием. Однако создание отказоустойчивых систем сопряжено с дополнительными затратами и сложностью их контроля и диагностики, особенно при скрытых и множественных отказах.
На практике используются различные методы расчёта надёжности, основанные на представлении системы в виде структурной схемы и применении логико‑вероятностных методов [3]. В таких методах строятся схемы функциональной целостности, блок‑структурные схемы, деревья отказов и графы состояний и переходов, что позволяет аналитически оценить показатели надёжности системы посредством вероятностных моделей. Например, анализ с помощью деревьев отказов широко применяется в вычислительной технике, авиации и критических инфраструктурах (рисунок).
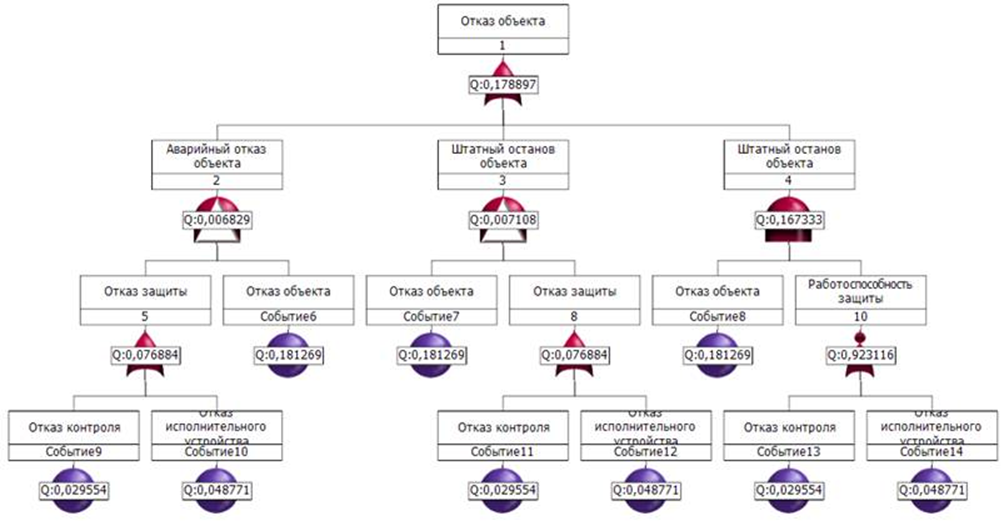
Рис. Графическое отображение дерева неисправностей [2]
Среди методов моделирования надёжности отказоустойчивых систем выделяется подход, основанный на моделях Маркова (или полу‑Маркова), который описывает систему через пространство состояний и вероятностные переходы между ними. Это позволяет учесть множественные режимы отказа и восстановления.
Также математические модели используют графы состояний и системы дифференциальных уравнений, чтобы оценить вероятности отказов на разных уровнях системы передачи данных. Такие методы применялись, например, при вычислительном моделировании отказоустойчивости ИТ‑систем.
В инженерной практике дополнительно используются концепции диагностики, мониторинга и корригирующих действий, которые позволяют предотвращать отказы или минимизировать их последствия. Это важный аспект теории надёжности, направленный на продление безотказной работы механических и электронных систем [14].
Все эти подходы в совокупности создают целостную систему теоретических знаний и моделей, которая помогает проектировать и анализировать системы с отказоустойчивостью, обеспечивать высокий уровень устойчивости и готовности к редким или критичным сбоям.
Для системного анализа отказоустойчивости в научной и инженерной практике используется широкий спектр методов, отличающихся как по методологии, так и по области применения. В таблице 1 приведено сравнение ключевых подходов, отражающее их суть, область применения, преимущества, ограничения и источники в открытых исследованиях.
Таблица 1
Подходы к бенчмаркингу отказоустойчивости систем
Подход/инструмент | Суть метода | Применение | Преимущества | Ограничения |
Fault injection [8] | Искусственное введение ошибок (задержки, повреждение данных, сбои процессов) | Аппаратные и программные системы, cloud-native | Позволяет выявить «узкие места», моделировать редкие отказы | Требует ресурсов и тщательной настройки; может быть разрушительным |
Метод Tsai et al. [5] | Синтетические нагрузки + сбои CPU/памяти/IO | Коммерческие отказоустойчивые системы | Метрики «катастрофические сбои» и «деградация производительности» | Старый стандарт; применим ограниченно к современным архитектурам |
Chaos engineering [4] | Введение сбоев в боевой среде (например, Chaos Monkey от Netflix) | Микросервисные и облачные платформы | Проверка устойчивости «вживую», выявление скрытых зависимостей | Высокий риск для продуктивных систем, нужны «safety-guardrails» |
MATCH Benchmark Suite [11] | Набор тестов для MPI-приложений | Высокопроизво-дительные вычисления (HPC) | Сравнение стратегий ULFM, Reinit recovery, FTI checkpointing | Специфичен для HPC-среды |
Метрики SLA и tail latency [4] | Измерение времени восстановления, задержек, доступности | Потоковые системы (Flink, Kafka Streams, Spark) | Практико-ориентированные показатели качества обслуживания | Чувствительны к конфигурации и нагрузке |
Оценка отказоустойчивости систем при редких сбоях базируется на ключевых метриках надёжности и доступности. Классические показатели – MTBF/MTTF (среднее время наработки на отказ) и MTTR (среднее время восстановления) – используются для вычисления коэффициента доступности:
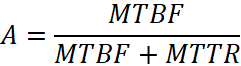 , (1)
, (1)
Эта формула лежит в основе SLA/SLO и служит базой для расчёта «пяти девяток» доступности.
Для редких событий важны функция безотказной работы R(t), интенсивность отказов λ(t) и хвостовые метрики задержек (p99/p99.9 задержка). Последние широко применяются в распределённых системах: именно «длинные хвосты», а не средние значения, определяют пользовательский опыт.
Для критических доменов уместно формализовать политику бюджетов ошибок, закрепляя связь между частотой изменений и устойчивостью сервиса. Практика SRE (Google) рекомендует использовать «бюджет ошибок» как управленческий механизм: при приближении к исчерпанию бюджета приостанавливаются релизы, фокус смещается на стабильность и устранение регрессий; пополнение бюджета происходит по мере улучшения показателей надёжности и доступности. Публичные руководства SRE описывают такую политику и её влияние на баланс «скорость изменений ↔ устойчивость» [9]. Это особенно важно для серийных испытаний с инъекцией отказов: запланированная «стратегическая деградация» не должна разрушать SLO на интервале наблюдения.
Оптимизация систем после проведения бенчмаркинга основана на сравнительном анализе полученных результатов и выявлении наиболее эффективных стратегий повышения надёжности. Разные подходы позволяют решать задачи с различных сторон: от математического моделирования и адаптивного выбора стратегий до настройки протоколов в распределённых и блокчейн-системах. В таблице 2 представлены ключевые методы, использующиеся в современной практике, их суть и зафиксированный эффект оптимизации, подтверждённый результатами реальных исследований.
Таблица 2
Подходы к оптимизации отказоустойчивости
Подход/инструмент | Суть метода | Эффект оптимизации |
Марковские модели / RBD | Аналитика надёжности системы через диаграммы надёжности (RBD) и непрерывные марковские цепи; оценка выигрыша от параллельного резервирования | Для параллельного резервирования при независимых отказах: 𝑅sys = 1 − П𝑖(1−𝑅𝑖). Пример: при 𝑅 = 0,60 один узел даёт 0,60; два независимых – 0,84; три – 0,936 (рост вероятности успешного завершения на +40% и +56% относительно одного узла) [13] |
Стоимостной оптимизатор обработки запросов | Отправка «хеджирующего» запроса с небольшой задержкой, чтобы срезать хвостовые задержки при минимальной надбавке к нагрузке | Классический пример Google: при чтении 1000 ключей из BigTable (фан-аут на 100 серверов) запуск запасного запроса с задержкой 10 мс снижает p99.9 выполнения с 1800 мс до 74 мс при увеличении числа запросов всего на ≈ 2% [17] |
Настройка консенсуса в блокчейн-сетях | Подбор параметров и архитектуры BFT-консенсуса (размер кворума, тайм-ауты, иерархические / групповые схемы) | Эмпирика по Tendermint: при масштабировании с 16 до 128 валидаторов средняя задержка подтверждения увеличивается с 2,72 с до 3,45 с, а пропускная способность уменьшается с 535 до 438 tps (грациозная деградация). Дополнительно: в ряде работ по оптимизации HotStuff заявлено снижение задержки ≈ на 20% и рост пропускной способности при сбоях (пример – QuickBFT против HotStuff) [1] |
«Экологический ландшафт» (бенчмаркинг/хаос-инжиниринг) | Формализованные сценарии сбоев с blast radius, стоп-условиями и отчётностью по SLI/SLO; регулярные прогоны вместо «полевых» тестов | В AWS FIS доступны stop conditions на базе CloudWatch Alarms (эксперимент автоматически останавливается при наступлении порога) и генерация PDF-отчёта об эксперименте. Для проектирования алармов и метрик отчётности применяются практики SRE по мульти-окнам / мульти-скоростям сжигания бюджета ошибок [10] |
Практические применения бенчмаркинга отказоустойчивости находят отражение в реальных кейсах лидирующих компаний, аккумулирующих знания через контролируемое экспериментирование. Так, Netflix, разрабатывая Chaos Monkey, породил культуру постоянного тестирования отказоустойчивости: случайные выключения серверов в продуктивной среде позволили выявлять слабые места и укреплять архитектуру – отказ рассматривается как неизбежность, требующая автоматизации восстановления и избыточности. Этот подход стал основой для автоматизированной платформы Chaos Automation Platform, позволяющей запускать эксперименты с отказами и подтверждать устойчивость системы без воздействия на пользователей [7].
Со временем Chaos Engineering выросло в практику, где эксперименты по стресс-тестированию проводятся регулярно и в контролируемой форме, тестируя сценарии вроде выхода из строя подсистем, задержек или отказов сетевых соединений. Эта практика позволяет выявить потенциальные уязвимости до того, как они приведут к отказу в продакшене.
Другие компании, вдохновлённые опытом Netflix, внедряют аналогичные подходы: регулярные сбои в облачных компонентах, Game Days, disaster recovery testing (DiRT) от Google – все они направлены на повышение устойчивости и проверку recovery-процессов в реальных условиях.
Эти подходы широко применяются и в DevOps-практиках крупных облачных инфраструктур, где используются инструменты типа Gremlin, AWS Fault Injection Simulator, Litmus Chaos, Chaos Toolkit и другие для инъекции отказов, анализа зависимости и устойчивости системы к воздействиям.
В совокупности эти реальные практики показывают, что Chaos Engineering – это не просто идея, а рациональный инструмент повышения отказоустойчивости. Он позволяет системам справляться с редкими сбоями, выявлять слабости до инцидентов, улучшать восстановление и создавать культуру надёжности на всех этапах жизненного цикла приложения.
В транспортной инфраструктуре редкие отказовые события могут диагностироваться по телематике и OBD-II-метрикам, которые стандартизованно считываются с ЭБУ автомобиля через PID-запросы [12]. В регуляторной практике OBD-II применяется для контроля выбросов и технического состояния в программах инспекции / обслуживания. Для бенчмаркинга отказоустойчивости это создаёт основу «живых датасетов» с высокой диагностической ценностью: обороты двигателя (RPM), температура охлаждающей жидкости, давление в топливной рампе, краткосрочные / долгосрочные топливные коррекции, скорость, счётчики пропусков воспламенения, DTC-коды.
Практическая реализация кейса выполнена в виде отдельного модуля ResilienceBench, позволяющего воспроизводить сценарии редких отказов на основе стандартных OBD-II PID (скорость, обороты двигателя, температура охлаждающей жидкости, давление топлива и др.). Полученные данные сопоставляются с SLI и SLO, что позволяет строить более точные модели влияния сбоев на транспортную инфраструктуру [15].
Несмотря на широкое распространение методов бенчмаркинга отказоустойчивости и накопленный опыт их практического применения, существует ряд проблем и ограничений, существенно влияющих на точность и полноту результатов. Эти ограничения связаны как с методологией, так и с техническими и организационными факторами, что требует критического анализа и поиска новых решений.
- Неполнота данных о редких сбоях – редкие отказы фиксируются нерегулярно, что снижает достоверность статистических моделей и ограничивает возможности предсказания.
- Высокая стоимость стресс-тестирования – проведение масштабных экспериментов требует значительных вычислительных ресурсов и может влиять на производительность систем.
- Риск дестабилизации продуктивной среды – при внедрении Chaos Engineering и fault injection всегда существует вероятность нарушения SLA и недовольства пользователей.
- Ограниченность существующих метрик – классические показатели (MTBF, MTTR, SLA) не всегда адекватно отражают тяжёлые хвосты распределений задержек и устойчивость к редким катастрофическим сбоям.
- Сложности воспроизводимости экспериментов – результаты бенчмаркинга зависят от конкретных условий, конфигураций и нагрузки, что мешает формировать универсальные стандарты.
- Баланс между надёжностью и затратами – избыточность и резервирование повышают отказоустойчивость, но существенно увеличивают стоимость инфраструктуры.
- Отсутствие унифицированных стандартов – в разных отраслях применяются разрозненные методики, что затрудняет кросс-сравнение систем.
- Человеческий фактор – интерпретация результатов бенчмаркинга и принятие решений часто зависят от опыта инженеров, что снижает объективность.
Для практической реализации предложенного протокола и выбора инструментов под конкретные сценарии инъекции сбоев суммируем их ключевые возможности и ограничения. Ниже приведена матрица совместимости (табл. 3), позволяющая соотнести типы отказов, механизмы «ограждений», параметры планирования и отчётности с поддержкой в популярных платформах. Информация сведена из официальной документации и публичных материалов самих инструментов.
Таблица 3
Совместимость инструментов инъекции отказов
Категория/Инструмент | Chaos Monkey (Netflix OSS) | Gremlin | AWS Fault Injection Simulator (FIS) | LitmusChaos | Chaos Toolkit |
Целевая среда | AWS EC2 / Auto Scaling Groups, интеграция со Spinnaker | Хосты/VM, контейнеры, Kubernetes (через агент) | Ресурсы AWS (EC2, ECS, EKS и др.) | Kubernetes-native (CRD/оператор, ChaosHub) | Универсальная через драйверы/расширения (K8s, облака, on-prem) |
Терминация инстанса/пода | Да | Да | Да | Да | Да |
Сеть: задержка/потери/ разрыв | – (в базовом инструменте) | Да | Да | Да | Через расширения/прокси/скрипты |
Ресурсы: CPU/Memory/IO | – | Да | Да | Да | Через драйверы/плагины |
Сдвиг времени (Time shift) | – | Да | – | – | Возможен через пользовательские шаги/расширения |
HTTP-хаос (уровень L7) | – | – | – | Да | Через интеграции/расширения (например, сервис-мэш) |
Планирование/расписание | Да | Да | Да | Да | Через внешние оркестраторы (CI/CD, K8s-Operator) |
Guardrails/стоп-условия | Ограниченно – окна запуска/частота | Да | Да | Да | Да |
Отчётность/журналы | Через интеграции (Spinnaker/лог-системы) | История/репорты, интеграции с APM | Отчёты в шаблонах, интеграция с CloudWatch | События / результаты в CRD, хаос-дашборды | Автогенерация отчётов (HTML/PDF) через плагин |
Будущее бенчмаркинга отказоустойчивости связано с тремя направлениями. Во-первых, интеграция AI/ML: алгоритмы машинного обучения позволяют прогнозировать отказы, выявлять аномалии и автоматически выбирать стратегии восстановления, что делает системы адаптивными.
Во-вторых, расширение метрик: к MTBF, MTTR и SLA добавляются хвостовые задержки (p99/p99.9), QoE, показатели устойчивости к «чёрным лебедям» и энергоэффективности, что обеспечивает более полную оценку.
В-третьих, стандартизация: формирование международных норм (ISO, IEEE) создаст единый подход, сделает результаты тестов воспроизводимыми и упростит сертификацию критических систем.
Выводы
Проведённый анализ показывает, что надёжная оценка отказоустойчивости в условиях редких (малочастотных) сбоев требует совмещения трёх компонентов: строгих моделей надёжности (RBD/марковские цепи), практико-ориентированных метрик эксплуатации и воспроизводимых экспериментов по инъекции отказов с чёткими «ограждениями» и отчётностью. Предложенный в работе протокол стандартизирует сценарии, артефакты наблюдаемости и критерии «pass/conditional/fail», а сопоставительная матрица инструментов облегчает выбор технологической базы под конкретную среду.
Количественные примеры из литературы демонстрируют практическую отдачу: параллельное резервирование повышает итоговую вероятность успешного завершения операций, «стоимостные» стратегии радикально сокращают хвостовые задержки при минимальной надбавке к нагрузке, а корректная настройка консенсуса обеспечивает грациозную деградацию производительности при масштабировании.
Предложенный кейс транспортной КИИ с опорой на телематику и OBD-II-метрики расширяет доменную применимость и задаёт основу для открытого репозитория с DOI, повышающего воспроизводимость результатов.
Ограничениями подхода остаются зависимость эффектов от профиля нагрузки и корректности допущений (например, независимости отказов), а также стоимость полноразмерных экспериментов.
Перспективы дальнейшего развития напрямую связаны с расширением возможностей ResilienceBench, включая автоматизированный выбор сценариев средствами машинного обучения, интеграцию с промышленными платформами сбора телематики и движение к стандартизации протоколов бенчмаркинга отказоустойчивости.
