.png&w=384&q=75)
Введение
Анализ фондового рынка сегодня – это не просто работа с графиками и индикаторами. Это борьба за время и контекст: кто быстрее поймёт, что новость в Telegram-канале или пресс-релиз компании – это не просто текст, а сигнал к движению цены? Кто сможет отличить настоящую аномалию от случайного шума?
Традиционные методы, основанные на статистических моделях (ARIMA, GARCH), часто не успевают за динамикой рынка. Они работают с числами, но не видят, почему эти числа изменились – из-за эмоций, событий, слухов или реальных финансовых показателей. Это особенно критично в условиях высокой волатильности и информационного перегруза [1].
Поэтому мы разработали систему, которая объединяет два мира: рынок (котировки, объёмы) и новости (тексты, события). Она не просто собирает данные – она их понимает. Система автоматически выявляет, когда по конкретной акции происходит что-то необычное, сравнивая текущие показатели с её собственной историей за текущий квартал, и связывает это с тем, что пишут о компании в тот же момент. Цель – дать аналитику или трейдеру не сырые данные, а готовый, интерпретируемый сигнал, который можно использовать для решения [2].
Методы
Система построена как набор независимых, но взаимодействующих сервисов – микросервисов, развёрнутых в контейнерах. Это позволяет легко добавлять новые источники данных, заменять модели анализа или масштабировать отдельные компоненты под растущую нагрузку [3]. Архитектура включает следующие ключевые компоненты (рис.).
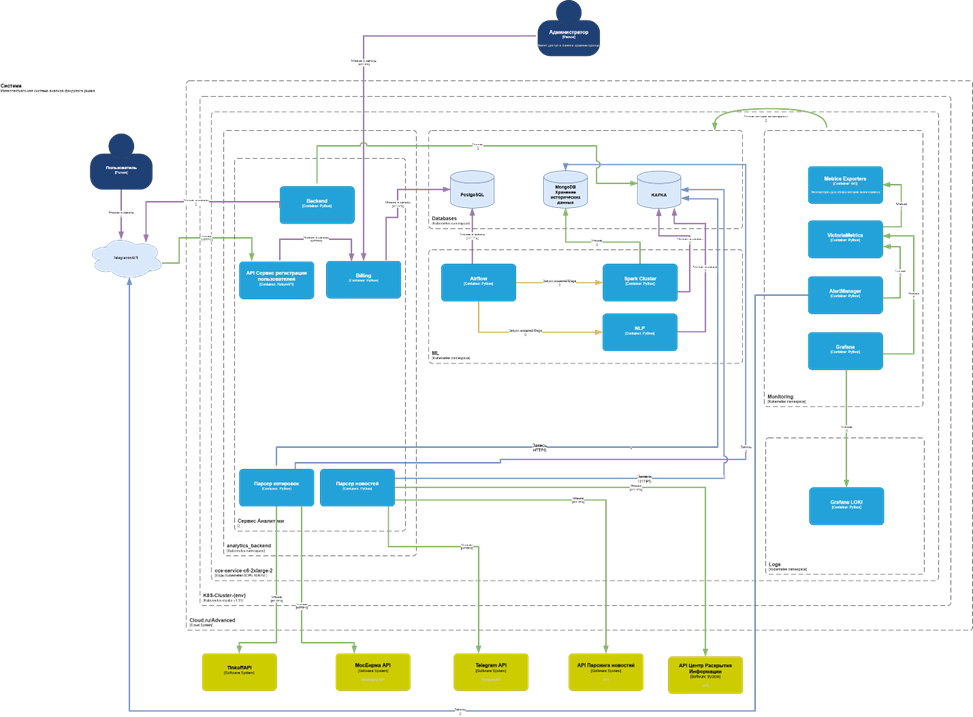
Рис. Архитектура интеллектуальной системы анализа данных фондового рынка для поддержки принятия решений
Сбор данных
На вход поступают данные из двух типов источников:
- Финансовые API: TinkoffAPI, MoexAPI – получение котировок, объёмов, стаканов.
- Новостные потоки: Telegram API, API Парсинга новостей, API Центра Раскрытия Информации – сбор текстовой информации.
Все запросы выполняются асинхронно – это критично для минимизации задержек при большом числе источников [4].
Парсеры и предобработка
Полученные данные попадают в параллельные потоки обработки:
- Парсер котировок – преобразует данные в единый формат.
- Парсер новостей – очистка, нормализация, временная синхронизация. Этап предобработки обеспечивает согласованность и целостность данных перед анализом.
Хранение данных
Обработанные данные сохраняются в распределённое хранилище:
- PostgreSQL – основное реляционное хранилище для структурированных данных.
- MongoDB – хранение неструктурированных данных (тексты новостей, логи).
- Kafka – брокер сообщений для асинхронной передачи данных между сервисами.
Анализ
NLP-модуль
Мы используем обученную модель машинного обучения для обработки текстов из новостных API. Модель классифицирует новости по типам событий (дивиденды, M&A, регуляторика и др.), определяет тональность (позитив/негатив/нейтр) и вытаскивает ключевые сущности – компании, тикеры, цифры. На выходе – структурированное описание события, которое можно связать с рыночной активностью [5].
Детектор аномалий (квартал-ориентированное)
Мы отказались от универсальных порогов. Вместо этого для каждой акции и каждого квартала строится свой «профиль» – медиана, стандартное отклонение, межквартильный размах (IQR). Если текущее значение (объём, цена, волатильность) выходит за границы этого профиля – это аномалия. Такой подход резко снижает количество ложных срабатываний, потому что он учитывает уникальную «биографию» каждой акции [6].
Мониторинг и визуализация
- Grafana + Prometheus – визуализация метрик производительности и состояния системы.
- Telegram-бот – главный интерфейс для пользователя. Он получает уведомления в чате: «Аномалия по SBER: объём +200% относительно квартального среднего. Новость: «Сбербанк объявил дивиденды». Уверенность: 0.87». График прилагается. Никаких лишних деталей – только то, что важно для решения.
Таблица
Сравнение скорости и эффективности обработки данных
Показатель | Традиционные методы | Разработанная система |
Среднее время получения новостей из 5 источников, сек | 35 | 22 |
Задержка между публикацией и парсингом, сек | 30 | 20 |
Средняя нагрузка на CPU при 10 параллельных источниках (%) | 72 | 52 |
Доля пропущенных событий при пиках активности (%) | 7 | 4 |
Результаты
Мы протестировали систему на данных за 3 квартала 2024 года – котировки ~50 ликвидных акций на Мосбирже и ~10 новостных источников (включая «Интерфакс», «Коммерсантъ», «ТАСС» и топовые Telegram-каналы). Снижение latency на ~30–40%, повышение надёжности и производительности (табл.).
Пример реального кейса: 28 октября 2024 г. в 14:07 в Telegram-канале «РБК Инвестиции» вышла новость: «Норникель объявил о рекордных дивидендах за 3 квартал».
Через 80 секунд система зафиксировала всплеск объёма по NMTP (+210% относительно медианы квартала) и сформировала сигнал с уверенностью 0.86. Цена начала расти через 2 минуты после публикации.
Заключение
Мы создали систему, которая помогает инвесторам и аналитикам не просто «видеть» рынок, а «понимать» его. Она сочетает скорость сбора данных, глубину анализа текстов и адаптивность к поведению каждого отдельного инструмента.
Главное преимущество – контекст. Система не просто фиксирует всплеск объёма, она говорит: «Это необычно для этой акции именно сейчас, и вот почему – потому что только что вышла новость о дивидендах, и она совпадает по времени и смыслу».
Архитектура системы – масштабируемая и гибкая. Её можно развивать: добавлять новые источники, менять модели NLP, интегрировать с торговыми терминалами. Но уже сейчас она показывает, что осмысленный анализ, основанный на актуальных данных и адаптивных правилах, эффективнее, чем набор универсальных индикаторов [7].
