.png&w=384&q=75)
Актуальность исследования
Актуальность исследования определяется тем, что переход организаций к облачным, гибридным и мультиоблачным архитектурам становится устойчивым направлением цифровой трансформации, а сами информационные системы всё чаще строятся на микросервисных принципах. В таких условиях растёт количество межсервисных взаимодействий, усложняются сетевые маршруты, контуры безопасности и механизмы управления доступом, а также возрастает роль внешних платформенных компонентов: очередей сообщений, сервисов наблюдаемости, кэшей, общих хранилищ данных и сторонних провайдеров.
При миграции в облако существенную угрозу для устойчивости создают именно скрытые зависимости – связи, которые не отражены в архитектурной документации, проявляются только в отдельных сценариях, зависят от конфигурации, флагов функциональности, профиля нагрузки или особенностей инфраструктуры. Такие зависимости особенно опасны, потому что способны приводить к труднообъяснимым инцидентам: деградации производительности, каскадным отказам по цепочке вызовов, нарушению целевых показателей доступности, а также к рискам по безопасности из-за неучтённых каналов обмена данными и ошибочно настроенных правил доступа.
Существующие практики выявления связей нередко дают неполную картину: они хуже обнаруживают транзитивные, условные и инфраструктурно-опосредованные зависимости, а также зависимости, формирующиеся вокруг данных и событий. Поэтому разработка и обоснование методов, позволяющих системно выявлять скрытые межсервисные зависимости и учитывать их влияние на планирование и выполнение миграции, является актуальной научной и прикладной задачей, напрямую связанной с повышением надёжности перехода в облако, снижением операционных рисков и обеспечением предсказуемого качества сервисов.
Цель исследования
Целью данного исследования является обоснование и описание методического подхода к выявлению скрытых межсервисных зависимостей в микросервисных системах при миграции в облачные среды, а также определение способов использования данных наблюдаемости и управленческих журналов для формирования проверяемого реестра зависимостей, снижающего риски отказов и деградаций после переноса.
Материалы и методы исследования
Материалами исследования выступили открытые нормативно-методические публикации и руководства по микросервисной архитектуре и надёжности распределённых систем, включая положения NIST SP 800-204, а также общедоступная документация облачно-нативных технологических средств наблюдаемости и управления.
В работе применены методы анализа и обобщения научно-технических источников, сравнительный анализ подходов к выявлению зависимостей, систематизация видов межсервисных связей и причин их скрытости, а также концептуальное моделирование реестра зависимостей как проверяемого представления взаимодействий и инфраструктурных условий их корректной работы.
Результаты исследования
Микросервисная архитектура рассматривается как подход, при котором приложение декомпозируется на независимые сервисы, каждый из которых реализует отдельную функциональность и взаимодействует с другими компонентами по сети, сохраняя для пользователя целостность системы [4].
Теоретически такая декомпозиция усиливает модульные границы и упрощает независимые изменения и развёртывания, однако на практике приводит к появлению большого числа связей между сервисами и инфраструктурными элементами, от которых зависит работоспособность распределённой комплексной операции. Поэтому в контексте миграции в облачные среды межсервисная зависимость корректно понимается не только как факт вызова одного сервиса другим, но и как необходимость наличия определённых «сквозных» платформенных возможностей, без которых взаимодействия либо становятся невозможными, либо приобретают недопустимые свойства по безопасности и устойчивости [3].
В открытых руководствах по микросервисным системам подчёркивается, что взаимодействие между множеством компонентов требует поддерживающих базовых возможностей. Так, в NIST SP 800-204 прямо перечисляются ключевые функции, необходимые для сложных взаимодействий: аутентификация и управление доступом, обнаружение сервисов, безопасные протоколы связи, мониторинг безопасности, техники повышения доступности и устойчивости, балансировка нагрузки и ограничение запросов, техники обеспечения целостности при вводе новых сервисов, а также обработка сохранения состояния сессии; при этом указано, что эти функции могут быть интегрированы в архитектурные фреймворки. Эта рамка важна теоретически, поскольку переводит разговор о зависимостях из уровня «сервис A вызывает сервис B» на уровень зависимостей от механизмов идентификации, маршрутизации, шифрования и управления трафиком, которые во время миграции в облако часто меняются [5].
Ниже приведена сводная таблица 1 перечисленных в NIST SP 800-204 базовых возможностей микросервисной системы и типовых форм, в которых они проявляются как межсервисные зависимости (перечень функций воспроизводится по тексту публикации, а «форма зависимости» описывает наблюдаемый в системе артефакт – например, необходимость выполнения обнаружения сервиса по имени или требования к защищённому каналу).
Таблица 1
Базовые возможности микросервисной системы по NIST SP 800-204 и их проявление в виде межсервисных зависимостей (разработка автора)
Базовая возможность (NIST SP 800-204) | В чём выражается зависимость на практике (артефакт/условие взаимодействия) | Почему относится к межсервисным зависимостям при миграции |
Аутентификация и управление доступом | Наличие доверенной системы идентификации, корректных токенов/ключей и политик доступа для вызовов между компонентами | Межсервисный вызов превращается в зависимость от единого механизма удостоверения и авторизации по всей цепочке |
Обнаружение сервисов | Возможность найти актуальную конечную точку сервиса по имени/реестру и корректно обновлять сведения об экземплярах | В распределённой среде адреса меняются, и связь «кто с кем разговаривает» опирается на служебные механизмы обнаружения |
Безопасные протоколы связи | Использование защищённых соединений при обмене данными (например, TLS в качестве транспорта) | При смене облачной сети/политик зависимость от защищённого канала становится критичной для сохранения работоспособности и доверия |
Мониторинг безопасности | Наличие наблюдаемости событий и телеметрии, позволяющих выявлять аномалии и нарушения | «Невидимые» связи часто выявляются именно по телеметрии и корреляции событий между компонентами |
Техники устойчивости и доступности | Настроенные механизмы отказоустойчивости и ограничение каскадирования отказов | Связь между сервисами включает не только функциональный контракт, но и правила деградации/отказа |
Балансировка нагрузки и троттлинг | Наличие политик распределения трафика и ограничений, влияющих на силу и характер взаимодействий | Миграция меняет сетевые границы и профили нагрузки; зависимость проявляется в требованиях к управлению трафиком |
Обеспечение целостности при вводе новых сервисов | Процедуры безопасного «подключения» новой версии/экземпляра без нарушения взаимодействий | Межсервисная связь зависит от того, как система допускает новые компоненты и проверяет их корректность |
Обработка сохранения состояния сессии | Требования к сохранению/передаче состояния, влияющие на маршрутизацию и масштабирование | В облаке часто меняются балансировка и топология; зависимости возникают вокруг сессий и их «привязки» |
С точки зрения инфраструктурной теории распределённых систем особенно важна зависимость от механизмов обнаружения и именования. В Kubernetes сервис задаёт логический набор конечных точек и политику доступа к ним, позволяя обращаться к группам pod’ов как к единому сетевому объекту. Для этого Kubernetes создаёт DNS-записи для сервисов и pod’ов, чтобы рабочие нагрузки находили сервис по стабильному имени, а не по изменяющимся IP-адресам; при этом kubelet настраивает DNS в pod’ах таким образом, чтобы приложения могли выполнять разрешение имён сервисов. Теоретически такой механизм означает, что значимая доля зависимости «сервис A → сервис B» реализуется через унифицированный слой сервисных имён и правил сетевого доступа внутри кластера, а не зашита в код в виде конкретных адресов [1].
Отдельный класс зависимостей формируется вокруг «точек агрегации» и «сквозных функций», вынесенных из бизнес-логики. В паттернах микросервисной архитектуры API Gateway описывается как промежуточный слой, который маршрутизирует запросы клиентов к доступным экземплярам сервисов, а также может реализовывать кросс-функциональные возможности вроде аутентификации, работы с токенами доступа и применения устойчивых стратегий вызовов. В терминах зависимостей это означает, что часть межсервисных взаимодействий становится опосредованной: фактический доступ к сервисам происходит через шлюз, и система начинает зависеть от корректности его маршрутизации, политик и цепочек проксирования.
Для наглядного представления модели взаимодействия «клиенты – шлюз – микросервисы» целесообразно использовать архитектурную схему с единым API Gateway, через который проходят запросы мобильного клиента, SPA-приложения и традиционного веб-клиента. Такая схема демонстрирует, что межсервисные зависимости в реальной системе проявляются не только как прямые вызовы между микросервисами, но и как зависимость от промежуточного компонента маршрутизации и обработки запросов (рисунок).
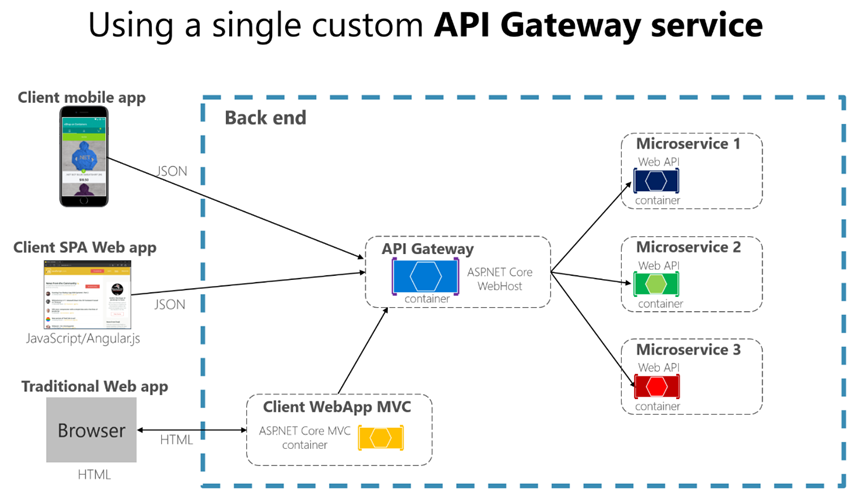
Рис. Использование единого пользовательского API Gateway для доступа клиентов к микросервисам [7]
Параллельно в облачно-нативной экосистеме закрепился подход service mesh как инфраструктурного слоя, предназначенного для управления трафиком между сервисами и добавления надёжности, наблюдаемости и безопасности единообразно для всех взаимодействий [6]. Эта постановка напрямую связана с классификацией зависимостей: зависимость фиксируется не только как логический контракт «вызов API», но и как зависимость от единых правил управления коммуникациями (маршрутизация, политика отказов, шифрование), которые применяются прозрачно на платформенном уровне и поэтому легко остаются «неявными» для команд, если анализ ограничен только кодом сервисов.
Скрытые межсервисные зависимости дестабилизируют процесс миграции прежде всего потому, что при переносе меняются условия удалённых взаимодействий: сетевые маршруты, задержки, точки контроля и политики коммуникаций. В распределённых системах это быстро приводит к каскадным отказам, когда частичная деградация одной части системы повышает нагрузку на другие части и запускает самоподдерживающийся цикл ухудшения. Такой сценарий подробно описывается в Google SRE как отказ, усиливающийся за счёт положительной обратной связи, где главной первопричиной выступает перегрузка и связанные с ней эффекты очередей, истощения ресурсов и роста времени обработки запросов [2].
В таблице 2 приведена краткая сводка типовых механизмов срыва миграции, которые в открытых руководствах напрямую связываются с поведением распределённых взаимодействий и часто «маскируют» реальные межсервисные зависимости до момента переноса в новую среду.
Таблица 2
Типовые механизмы срыва миграции из-за скрытых межсервисных зависимостей (разработка автора)
Механизм | Почему «скрытая зависимость» проявляется именно при миграции | Что обычно видно в телеметрии |
Каскадный отказ при перегрузке | Меняется профиль задержек и доступности, и «слабое звено» в цепочке начинает определять поведение всей операции | Одновременный рост ошибок и задержек в нескольких сервисах после локального сбоя |
Некорректно настроенные предельные времена ожидания | Значения подходили для прежней среды, но в облаке становятся слишком короткими или слишком длинными, провоцируя ранние отказы или удержание ресурсов | Резкий рост ошибок по истечению времени ожидания, увеличение «хвостовой» задержки, рост числа незавершённых операций |
Повторные запросы без ограничений и «бюджета» | Повторы усиливают нагрузку при деградации и мешают восстановлению; требуется увеличение паузы между повторами и случайное разнесение повторов во времени | Рост количества запросов без роста пользовательской нагрузки, ускоренное ухудшение состояния зависимых сервисов |
Выявление межсервисных зависимостей при миграции в облако основывается на восстановлении фактического графа взаимодействий по наблюдаемым следам работы системы. Наиболее информативным подходом считается распределённая трассировка, поскольку она позволяет связать операции разных сервисов в единую цепочку при условии корректной передачи контекста между компонентами. Дополняющим источником выступают журналы и показатели мониторинга, которые в связке с трассировкой позволяют уточнять последовательность событий и локализовать проблемное звено в цепочке взаимодействий.
На инфраструктурном уровне зависимости выявляются средствами сервисной сетки, где телеметрия коммуникаций между сервисами собирается на уровне прокси-компонентов и может визуализироваться в виде графов связей; такие инструменты позволяют видеть реальное распределение запросов и связи внутри сервисной сети. Отдельный класс методов относится к наблюдаемости сетевых потоков на уровне кластера, когда связи восстанавливаются по фактическим сетевым коммуникациям между рабочими нагрузками, что полезно при неполной инструментированности приложений. Также практическую ценность имеет аудит действий в инфраструктуре оркестратора: журналы аудита фиксируют изменения объектов и настроек в кластере и помогают связывать возникновение новых зависимостей с конкретными изменениями конфигурации.
Предлагаемый подход основывается на том, чтобы выявление скрытых межсервисных зависимостей опиралось на сопоставимые наблюдаемые данные, а не на предположения и разрозненную информацию. В качестве основы используется стандартизированная передача контекста трассировки, позволяющая связывать операции разных компонентов в единую причинно-следственную цепочку при прохождении запроса через несколько сервисов. Такая корреляция строится на общедоступно описанном стандарте W3C по контексту трассировки, который задаёт формат служебного заголовка передачи контекста и обеспечивает единообразное объединение событий в распределённой системе.
Для того чтобы результаты выявления зависимостей были сравнимыми между сервисами и средами, применяется единая схема описания операций через семантические правила OpenTelemetry. В частности, используются стабильные правила описания операций веб-взаимодействий, что позволяет интерпретировать однотипные обращения одинаково независимо от языка реализации и используемых библиотек. Эта унификация снижает риск того, что одни и те же связи будут фрагментироваться в различных представлениях данных наблюдаемости и, следовательно, не будут распознаны как единая зависимость.
Сбор и приведение данных наблюдаемости рекомендуется выполнять через сборщик телеметрии OpenTelemetry (Collector), который в открытой документации описан как компонент, принимающий данные, обрабатывающий их и передающий в выбранные хранилища. Такой способ удобен тем, что позволяет централизованно нормализовать данные и добавлять единые признаки окружения, благодаря чему журнальные сообщения, трассировки и метрики можно уверенно сопоставлять между собой и строить по ним схему зависимостей.
Итогом применения подхода является формализованный реестр межсервисных зависимостей, подтверждённый наблюдаемыми данными и пригодный для проверки на этапах миграции. За счёт сочетания стандартизированной корреляции, унификации описания операций, централизованного сбора телеметрии и учёта управленческих изменений в кластере снижается вероятность того, что критическая связь останется неучтённой и проявится только после переноса в облачную среду.
Выводы
Таким образом, скрытые межсервисные зависимости представляют собой один из ключевых факторов срыва миграции микросервисных систем в облако, поскольку при переносе изменяются условия сетевого взаимодействия, контуры безопасности и инфраструктурные механизмы, от которых фактически зависит целостность распределённых операций. Теоретическое рассмотрение на основе NIST SP 800-204 подтверждает, что межсервисная зависимость включает не только прямые вызовы между сервисами, но и общеплатформенные функции, обеспечивающие идентификацию, маршрутизацию, защищённую связь и устойчивость. Практики выявления зависимостей дают наибольший эффект при использовании комплексного подхода, объединяющего данные трассировки, мониторинга, анализа коммуникаций и аудита управленческих изменений. Формирование проверяемого реестра зависимостей на основе стандартизированной корреляции и унифицированного описания операций повышает предсказуемость миграции, снижает вероятность каскадных отказов и способствует обеспечению требуемого качества сервисов в целевой облачной среде.
