.png&w=384&q=75)
Введение
Первые мобильные приложения часто развивались как «витрина» сервиса: ограниченный функционал, умеренная нагрузка, простая инфраструктура. По мере роста цифровых экосистем мобильный клиент стал полноценным каналом доступа к финансовым операциям, персональным данным, корпоративным сервисам и государственным функциям. Это автоматически повышает цену ошибки. Если сбой в развлекательном приложении воспринимается как неудобство, то сбой в банковском или крупном сервисе – это уже риск для денег, репутации, регуляторного соответствия и доверия пользователей.
Эволюция требований проявляется в нескольких измерениях одновременно:
- Угрозы становятся разнообразнее (фишинг, SIM-swap, вредоносные приложения, эксплуатация уязвимостей API);
- Масштаб повышает эффект даже небольших дефектов (ошибка затрагивает не сотни, а миллионы);
- Сложность инфраструктуры растет (микросервисы, внешние интеграции, несколько регионов);
- Регуляторика и аудит превращаются в обязательный контур (хранение данных, журналирование, контроль доступа).
В этих условиях безопасность и надежность – это не два отдельных направления, а связанные компоненты зрелой инженерной системы: плохая надежность разрушает доверие, а слабая безопасность делает любой рост токсичным.
1. Как меняются требования при росте масштаба
При переходе от локального продукта к региональному и далее к глобальному масштабу растет интенсивность требований сразу в трех плоскостях: безопасность, надежность/доступность и соблюдение нормативов (compliance, auditability). Это происходит не линейно: требования «скачкообразно» усиливаются при выходе в регулируемые домены (например, финтех) и при географическом расширении.
На ранней стадии достаточно базовых мер: корректная аутентификация, минимальные политики хранения данных, резервное копирование. На уровне банковского приложения появляются обязательные сценарии управления риском: многофакторная аутентификация, антифрод-сигналы, строгие журналы событий, контроль доступа по принципу least privilege. На глобальном уровне добавляются: многорегиональные стратегии, повышенные требования к отказоустойчивости, детальная наблюдаемость, сегментация данных и регуляторные различия по странам.
2. Банковский контекст: почему мобильная безопасность начинается с идентичности
Банковский продукт ценен не «функциями», а доступом к активам и персональным данным. Поэтому ядро безопасности – это корректная работа с идентичностью:
- сильная аутентификация (включая MFA),
- управление сессиями,
- устойчивость к компрометации устройства и к перехвату каналов,
- защита от социальной инженерии (например, через риск-ориентированные политики).
Важно, что идентичность – это не только логин/пароль. Это набор сигналов и ограничений: устройство, география, поведение, история действий, подтверждения для операций повышенного риска. Чем зрелее продукт, тем чаще используются адаптивные механизмы (risk-based), где система динамически усиливает проверку в зависимости от контекста.
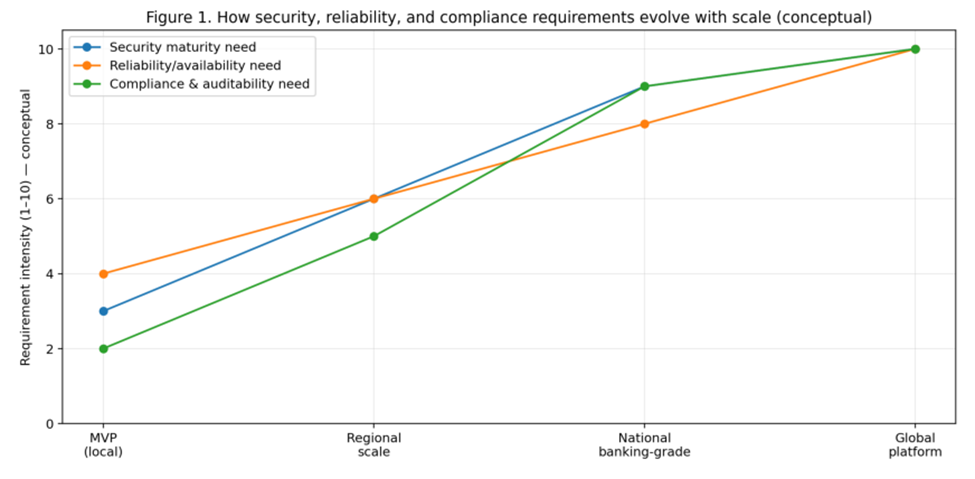
Рис. 1
3. Edge-уровень и API: главная зона атак для масштабных систем
Для глобальных платформ значительная часть атак сосредоточена на API и edge-инфраструктуре. Даже идеально защищенный клиент не спасает, если API позволяет обходить ограничения, извлекать лишние данные или перегружать сервис. Поэтому усиливаются практики:
- централизованное управление входящим трафиком (gateway),
- ограничения частоты (rate limiting) и защита от злоупотреблений,
- фильтрация и сигнатурные/поведенческие механизмы защиты,
- единые политики авторизации и «сужение поверхности» данных (минимизация того, что отдается наружу).
В продуктовой реальности это напрямую связано с экономикой: атаки на API увеличивают расходы (нагрузка), поднимают риск утечки и ухудшают доступность для легитимных пользователей.
4. Надежность как часть доверия: от «аптайма» к SLO
Когда продукт становится критически важным, важно не только «чтобы работало», а чтобы работало с предсказуемым качеством. Именно поэтому зрелые команды переходят от абстрактной «доступности» к SLO:
- какова допустимая доля ошибок?
- какой целевой p95/p99 по задержке в ключевых операциях?
- какой допустимый MTTR?
- какие сценарии считаются деградацией сервиса?
SLO дают два эффекта: делают качество измеримым и управляемым; создают язык для приоритизации – технические инициативы связываются с тем, что критично для пользователя и бизнеса. В банкинге и глобальных платформах надежность – это часть «социального контракта» с пользователем: сервис не имеет права на хаотичное поведение.
5. Устойчивость к отказам: почему «ретраи» и «таймауты» – это архитектура, а не детали
При росте системы увеличивается число компонентов и зависимостей. Это означает: частичные отказы становятся нормой. Устойчивость строится не на надежде «все всегда доступно», а на правильном поведении при сбоях:
- корректные таймауты,
- ограниченные ретраи (чтобы не усиливать инцидент),
- fallback-сценарии,
- управляемая деградация (сохранение критичных функций),
- планы аварийного восстановления (DR).
На практике именно эти «мелкие» инженерные настройки решают судьбу инцидентов: либо система локализует проблему, либо превращает частичный сбой в каскад.
6. Защита данных: шифрование, секреты и дисциплина доступа
С ростом продукта усложняется контур данных: больше интеграций, больше сервисов, больше мест хранения и передачи. Это создает потребность в комплексной модели защиты:
- шифрование «в покое» и «в пути»,
- управление секретами (а не хранение ключей «рядом с кодом»),
- сегментация доступа и аудит,
- минимизация выдаваемых данных и контроль того, что логируется.
Особенно важно учитывать, что безопасность уязвима к «операционным утечкам»: не только через прямые атаки, но и через неправильные логи, чрезмерные права сервисных аккаунтов, тестовые окружения и некорректно настроенные доступы.
7. Наблюдаемость: без нее нельзя управлять ни безопасностью, ни надежностью
Наблюдаемость (логи/метрики/трейсы) превращает безопасность и надежность в управляемые процессы. Для зрелых мобильных продуктов важны две стороны наблюдаемости:
- серверная (что происходит внутри сервисов и инфраструктуры),
- клиентская (что реально испытывает пользователь: время запуска, сеть, краши, деградации).
Без этой связки команда не видит «истинной картины»: сервер может быть «зеленым», а пользователи – страдать из-за сетевых условий, тяжелых экранов, проблем на конкретных устройствах. В масштабных продуктах именно эта слепота часто приводит к потере доверия.
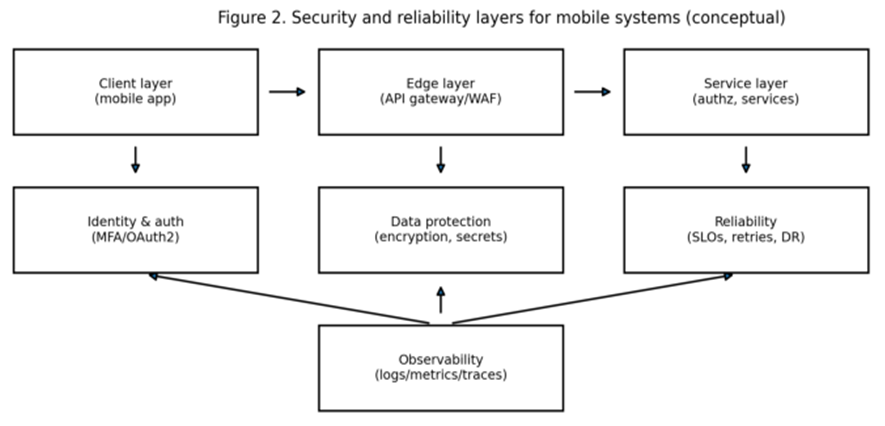
Рис. 2
8. Релизы как фактор риска: почему безопасные изменения – это управляемые изменения
По мере роста системы изменяется и роль релизов: каждое изменение становится потенциальным источником инцидента. Поэтому в зрелых командах релиз – это управляемый процесс:
- постепенные раскатки,
- возможность быстрого отката,
- совместимость версий клиента и сервера,
- контроль регрессий по метрикам,
- фиксация влияния изменений на SLO и продуктовые KPI.
В банковских и глобальных продуктах релизная дисциплина – это часть безопасности: «непредсказуемая доставка» часто приводит к нарушениям доступности и росту операционных рисков.
Заключение
Эволюция от банковских мобильных приложений к глобальным платформам усиливает требования к безопасности и надежности не «в два раза», а качественно. Идентичность становится ядром защиты, API и edge-уровень – ключевой зоной атак и контроля, а надежность – измеримой обязанностью через SLO и практики устойчивости к частичным отказам. Защита данных требует дисциплины доступа и операционной зрелости, а наблюдаемость связывает технические сигналы с пользовательской реальностью. В итоге масштабирование превращается не в «добавим мощности», а в системный инженерный процесс: архитектура, эксплуатация, релизы и метрики работают как единый контур управления доверием пользователя.
