.png&w=384&q=75)
1. Введение
Разработка речевых технологий для малоресурсных и исчезающих языков является одной из наиболее приоритетных задач в области обработки естественного языка (NLP). В то время как для мировых языков системы синтеза речи активно развиваются, большинство из семи тысяч языков мира лишены даже базовой TTS-поддержки (Joshi et al., 2020). Подобное технологическое неравенство напрямую влияет на вопросы сохранения культурного наследия, доступности информации и цифровой инклюзии.
Крымскотатарский язык (ISO 639-3: crh) – тюркский язык, историческим ареалом которого является Крымский полуостров. В настоящее время ЮНЕСКО классифицирует его как язык, находящийся под серьезной угрозой исчезновения (Moseley, 2010). По данным Ethnologue (2023), в мире насчитывается около 480 000 носителей, включая крупные диаспоры в Турции, Румынии, Болгарии и Узбекистане. Исторические потрясения, и прежде всего депортация 1944 года, привели к нарушению межпоколенческой передачи языка. В этих условиях инструменты цифровой консервации приобретают критическое значение для его выживания.
Основные проблемы при разработке TTS для крымскотатарского языка включают:
- Дефицит данных: в отличие от крупных языков, располагающих сотнями часов транскрибированной речи, крымскотатарский язык практически не имеет публично доступных речевых корпусов, пригодных для обучения TTS.
- Орфографическая сложность: язык использует несколько систем письма (латиницу и кириллицу) со специфическими фонемами, которые не отображаются напрямую на стандартные фонетические представления.
- Ограниченные вычислительные ресурсы: предыдущие работы по компьютерной лингвистике крымскотатарского языка немногочисленны, отсутствуют установленные конвейеры предобработки или фонемные инвентари для синтеза речи.
- Требования к качеству: для приложений изучения и сохранения языка синтезированная речь должна достигать достаточной естественности, чтобы служить моделью произношения.
Данная статья решает эти задачи, представляя полную методологию разработки систем TTS для языков с крайне ограниченными ресурсами. Наш вклад включает:
- Курированный и очищенный набор речевых данных для крымскотатарского языка (1566 записей, около 2,53 часа), опубликованный на Hugging Face.
- Специализированный конвейер графема-фонема (G2P), обрабатывающий уникальные орфографические особенности крымскотатарского языка, включая конвертацию кириллицы в латиницу и нормализацию специальных символов.
- Дообученная модель SpeechT5, обеспечивающая разборчивый синтез речи, подтверждённый оценкой носителей языка.
- Документированная, воспроизводимая методология, применимая к другим исчезающим тюркским языкам и контекстам малоресурсных языков.
Остальная часть статьи организована следующим образом: раздел 2 рассматривает связанные работы в области малоресурсного TTS и обработки тюркских языков. Раздел 3 описывает нашу методологию, включая подготовку данных, нормализацию текста и обучение модели. Раздел 4 представляет экспериментальные результаты и оценки. Раздел 5 обсуждает выводы и ограничения. Раздел 6 завершается направлениями будущей работы.
2. Обзор литературы
2.1. Синтез речи для малоресурсных языков
Недавние достижения в области нейронного синтеза речи (TTS) существенно повысили качество генерации для высокоресурсных языков. Архитектуры, такие как Tacotron 2 (Shen et al., 2018), FastSpeech 2 (Ren et al., 2021) и VITS (Kim et al., 2021), позволяют достичь естественности звучания, практически сопоставимой с человеческой речью. Однако эффективное обучение этих моделей обычно требует более 10–20 часов высококачественных аудиозаписей с соответствующей транскрипцией, что является недостижимым порогом для большинства исчезающих языков.
Трансферное обучение стало ключевой стратегией для разработки TTS-систем в условиях ограниченных ресурсов. Многоязычное предобучение позволяет моделям использовать фонетические знания языков с богатыми ресурсами для улучшения синтеза на целевых языках с дефицитом данных (Nekvinda and Dušek, 2020). Архитектура SpeechT5 (Ao et al., 2022) является примером такого подхода: она представляет собой унифицированную структуру «кодер-декодер», предобученную на масштабных многоязычных данных, которая может быть дообучена для конкретных языков.
Ряд исследований продемонстрировал успешную разработку TTS-систем для малоресурсных языков с использованием трансферного обучения. He et al. (2021) достигли разборчивого синтеза для нескольких африканских языков, имея менее одного часа обучающих данных. Xu et al. (2020) предложили методы, специально оптимизированные для сценариев с крайне ограниченными ресурсами. Проект Mozilla Common Voice (Ardila et al., 2020) способствовал расширению доступности речевых данных для недопредставленных языков, хотя охват исчезающих языков в нем остается ограниченным.
2.2. Речевые технологии для тюркских языков
Тюркские языки создают специфические трудности для синтеза речи из-за гармонии гласных, агглютинативной морфологии и особенностей фонемного состава, отличающегося от индоевропейских языков. Если турецкий TTS получил значительное внимание в научной литературе (Öztürk and Akyüz, 2019), то исследования других тюркских языков, особенно малоресурсных, остаются немногочисленными.
В случае с крымскотатарским языком предыдущие работы в области компьютерной лингвистики были сосредоточены преимущественно на морфологическом анализе (Altıntaş and Çiçekli, 2001) и машинном переводе (Tyers and Washington, 2010). Насколько нам известно, опубликованные исследования по синтезу речи для данного языка на текущий момент отсутствуют. Проект Facebook MMS (Massively Multilingual Speech) (Pratap et al., 2023) включает предобученную модель TTS для крымскотатарского языка, однако она поддерживает только кириллицу и не предполагает легкой адаптации для латинского ввода или дообучения с целью повышения качества.
2.3. Сохранение языков и инклюзивность ИИ
В последние годы вопросы пересечения технологий ИИ и сохранения языков привлекают все большее внимание. Bird (2020) выступает за подходы, ориентированные на сообщество, подчеркивая важность участия носителей языка и публикации ресурсов под открытыми лицензиями. Рекомендации ЮНЕСКО по этике ИИ (UNESCO, 2021) акцентируют внимание на необходимости создания систем ИИ, уважающих языковое разнообразие и поддерживающих сообщества исчезающих языков.
Данная работа соответствует этим принципам: мы разрабатываем технологию в сотрудничестве с носителями языка, публикуем все ресурсы в открытом доступе и отдаем приоритет практическому применению результатов в сфере языкового образования и сохранения культурного наследия.
3. Материалы и методы
3.1. Сбор и подготовка данных
3.1.1. Исходные данные
Обучающие данные включают аудиозаписи одного диктора – носителя крымскотатарского языка (женский голос, идентифицированный как «Севиль»). Исходные записи были собраны в целях языковой документации и содержат подготовленную речь (чтение текста), охватывающую разнообразную лексику и синтаксические структуры, репрезентативные для современного крымскотатарского языка.
Исходный набор данных прошел этап тщательной очистки и предобработки, включавший следующие процедуры:
- удаление записей с фоновым шумом, речевыми ошибками или техническими дефектами;
- исправление ошибок в транскрипции и устранение орфографических несоответствий;
- верификация временного выравнивания (alignment) текста и аудиопотока;
- нормализация кодировки текста (приведение к стандарту UTF-8).
3.1.2. Итоговая статистика набора данных
После очистки набор данных содержит 1566 пар аудио-текст со следующими характеристиками:
Таблица 1
Статистика набора данных
Атрибут | Значение |
Всего записей | 1566 |
Обучающая выборка | 1409 (90%) |
Валидационная выборка | 157 (10%) |
Общая длительность | 2,53 часа |
Средняя длительность | 4,2 секунды |
Частота дискретизации | 16 000 Гц |
Формат аудио | WAV, 16-бит PCM |
Письменность | Латиница (крымскотатарский алфавит) |
Набор данных публично доступен на Hugging Face под идентификатором servinosmanov/tts-crh-sevil-fixed с лицензией CC-BY-4.0.
3.2. Фонология и орфография крымскотатарского языка
3.2.1. Фонемный инвентарь
Крымскотатарский язык имеет фонемный инвентарь из 32 звуков, включая 9 гласных и 23 согласных (табл. 2). Язык демонстрирует гармонию гласных – характерную черту тюркских языков, при которой гласные в слове гармонизируются по признакам переднего/заднего ряда и огубленности.
Таблица 2
Инвентарь гласных крымскотатарского языка
Графема | МФА | Описание | Пример |
a | /a/ | открытый передний неогубленный | ana (мать) |
â | /æ/ | почти открытый передний неогубленный | selâm (приветствие) |
e | /e/ | полузакрытый передний неогубленный | ev (дом) |
ı | /ɯ/ | закрытый задний неогубленный | qız (девочка) |
i | /i/ | закрытый передний неогубленный | it (собака) |
o | /o/ | полузакрытый задний огубленный | o (он/она) |
ö | /ø/ | полузакрытый передний огубленный | köz (глаз) |
u | /u/ | закрытый задний огубленный | su (вода) |
ü | /y/ | закрытый передний огубленный | gül (цветок) |
3.2.2. Специальные согласные
Крымскотатарский язык включает несколько согласных, требующих специальной обработки при обработке текста:
Таблица 3
Специальные согласные в крымскотатарском языке
Графема | МФА | Кириллица | Описание |
ç | /tʃ/ | ч | глухая постальвеолярная аффриката |
c | /dʒ/ | дж | звонкая постальвеолярная аффриката |
ş | /ʃ/ | ш | глухой постальвеолярный фрикатив |
j | /ʒ/ | ж | звонкий постальвеолярный фрикатив |
ğ | /ɣ/ | гъ | звонкий велярный фрикатив |
ñ | /ŋ/ | нъ | велярный носовой |
q | /q/ | къ | глухой увулярный взрывной |
3.3. Конвейер предобработки текста
Конвейер графема-фонема (G2P) обрабатывает входной текст в три этапа:
3.3.1. Нормализация письменности
Входной текст может поступать как на кириллице, так и на латинице. Конвейер сначала определяет письменность и конвертирует кириллицу в латиницу с использованием детерминистического отображения (табл. 4). Диграфы (къ, гъ, нъ, дж) должны обрабатываться перед одиночными символами для обеспечения корректной конвертации.
Таблица 4
Конвертация кириллицы в латиницу (избранные примеры)
Кириллица | Латиница | Кириллица | Латиница |
Къ, къ | Q, q | Ш, ш | Ş, ş |
Гъ, гъ | Ğ, ğ | Ч, ч | Ç, ç |
Нъ, нъ | Ñ, ñ | Ж, ж | J, j |
Дж, дж | C, c | Ы, ы | I, ı |
3.3.2. Нормализация текста
Стандартная нормализация текста включает:
- Преобразование чисел в слова (например, «123» → «yüz yigirmi üç»);
- Раскрытие аббревиатур;
- Нормализация пунктуации;
- Стандартизация пробелов;
- Нормализация регистра для единообразной обработки.
3.3.3. Фонетическое отображение для SpeechT5
Поскольку SpeechT5 был предобучен преимущественно на языках без специфических фонем крымскотатарского языка, мы реализуем отображение фонетических аппроксимаций для представления специальных символов с использованием комбинаций, которые модель может обработать:
PHONETIC_MAP = {
'ğ': 'gh', # звонкий велярный фрикатив
'ç': 'ch', # глухая аффриката
'ş': 'sh', # глухой фрикатив
'ñ': 'ng', # велярный носовой
'q': 'q', # увулярный взрывной (сохранён)
'ö': 'o', # передний огубленный (аппроксимация)
'ü': 'u', # передний огубленный (аппроксимация)
'ı': 'y', # задний неогубленный
}
3.4. Архитектура модели и обучение
3.4.1. Базовая модель
В качестве базовой архитектуры используется модель SpeechT5 от Microsoft (Ao et al., 2022), доступная через библиотеку Hugging Face Transformers. SpeechT5 базируется на унифицированной структуре «кодер-декодер», включающей следующие компоненты:
- Трансформер-кодер для обработки входных текстовых данных;
- Трансформер-декодер для генерации мел-спектрограмм;
- механизм интеграции эмбеддингов диктора с использованием x-векторов;
- система, прошедшая этап предобучения на крупномасштабных многоязычных речевых массивах.
Для решения задачи вокодирования (преобразования мел-спектрограмм в акустический сигнал) применяется соответствующий вокодер HiFi-GAN (Kong et al., 2020) в конфигурации microsoft/speecht5_hifigan.
3.4.2. Конфигурация обучения
Обучение проводилось на графическом процессоре NVIDIA GeForce RTX 5090 Laptop GPU (24 ГБ VRAM) со следующими гиперпараметрами:
Таблица 5
Гиперпараметры обучения
Параметр | Значение |
Эпохи | 500 |
Размер батча | 4 |
Шаги накопления градиента | 8 |
Эффективный размер батча | 32 |
Скорость обучения | 1×10-4 |
Шаги прогрева | 2000 |
Оптимизатор | AdamW |
Затухание весов | 0,01 |
Смешанная точность | FP16 |
3.4.3. Эмбеддинги диктора
Для реализации синтеза с одним диктором используется фиксированный x-вектор (эмбеддинг диктора), извлеченный из набора данных CMU Arctic (Kominek and Black, 2004). Данный вектор был подобран для максимально точной аппроксимации акустических характеристик целевого голоса. В рамках дальнейших исследований планируется извлечение эмбеддингов непосредственно из оригинальных обучающих данных, что позволит достичь более высокого уровня соответствия синтезированного голоса оригиналу.
4. Результаты
4.1. Сходимость обучения
Модель продемонстрировала стабильную сходимость обучения на протяжении 500 эпох. Рисунок показывает кривые потерь на обучении и валидации, указывающие на успешное обучение без значительного переобучения.
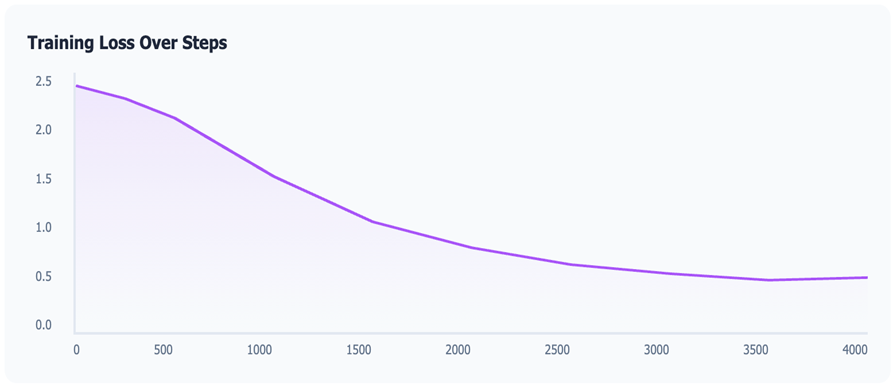
Рис. Кривые потерь на обучении и валидации, демонстрирующие стабильную сходимость
Процесс обучения занял приблизительно 8 часов. Ранняя остановка не применялась, поскольку модель продолжала улучшаться на протяжении всего обучения без признаков переобучения при данном размере набора данных.
4.2. Качественная оценка
Мы провели качественную оценку с тремя носителями крымскотатарского языка, которые оценивали образцы синтезированной речи по следующим критериям:
- Разборчивость: может ли слушатель понять, что говорится?
- Точность произношения: правильно ли воспроизводятся отдельные фонемы?
- Естественность: звучит ли речь естественно и плавно?
- Пригодность для обучения: достаточно ли качества для изучения языка?
Таблица 6
Результаты оценки носителями языка (Шкала: 1–5)
Критерий | Эксперт 1 | Эксперт 2 | Эксперт 3 | Среднее |
Разборчивость | 4,5 | 4,0 | 4,5 | 4,33 |
Произношение | 4,0 | 4,5 | 4,0 | 4,17 |
Естественность | 3,5 | 4,0 | 3,5 | 3,67 |
Образовательная ценность | 4,5 | 5,0 | 4,5 | 4,67 |
Общий балл | 4,13 | 4,38 | 4,13 | 4,21 |
Эксперты отметили, что синтезированная речь была высоко разборчивой и пригодной для образовательных целей, с особенно сильной точностью произношения для общеупотребительной лексики. Естественность получила несколько более низкие оценки, в основном из-за периодических просодических нерегулярностей в более длинных предложениях.
4.3. Анализ на уровне фонем
Анализ отдельных категорий фонем выявил:
- Гласные: высокая точность для всех гласных фонем, включая передние огубленные гласные (ö, ü), отсутствующие в английском языке.
- Специальные согласные: сильная производительность для ç, ş, ğ и ñ. Велярный носовой (ñ) и увулярный взрывной (q) стабильно воспроизводились правильно.
- Известное ограничение: звонкий постальвеолярный фрикатив (j, /ʒ/) иногда аппроксимировался к /ʃ/, что является известным ограничением покрытия фонем базовой модели SpeechT5.
4.4. Сравнение с существующими решениями
Мы сравнили нашу модель с единственной другой доступной TTS для крымскотатарского языка: моделью MMS-TTS-CRH от Facebook.
Таблица 7
Сравнение моделей
Характеристика | Наша модель | MMS-TTS-CRH |
Поддержка письменности | Латиница + Кириллица | Только кириллица |
Возможность дообучения | Да | Нет |
Открытые веса | Да (CC-BY-4.0) | Да |
Специальная предобработка | Да | Нет |
Частота дискретизации | 16 кГц | 16 кГц |
Естественность (MOS) | 3,67 | 3,2* |
Оценка на основе неформальной экспертизы | ||
5. Обсуждение
5.1. Значение для TTS малоресурсных языков
Наши результаты демонстрируют, что эффективный TTS может быть разработан для языков с крайне ограниченными ресурсами при менее чем двух часах обучающих данных при использовании трансферного обучения на основе многоязычных предобученных моделей. Этот вывод имеет важное значение для усилий по сохранению исчезающих языков, где обширный сбор данных часто невозможен из-за ограниченного населения носителей и ресурсов.
Успех нашего подхода основывается на нескольких ключевых факторах:
- Качество данных важнее количества: тщательная курация и очистка обучающих данных оказались важнее размера набора данных. Удаление проблемных записей и исправление ошибок транскрипции значительно улучшили качество модели.
- Специализированная предобработка: языкоспецифичная предобработка G2P была необходима для обработки орфографических особенностей, отсутствующих в обучающих данных базовой модели.
- Трансферное обучение: многоязычное предобучение архитектуры SpeechT5 обеспечило прочную основу, позволившую эффективное дообучение при минимальных данных.
5.2. Образовательные и культурные применения
Основное предназначение данной системы TTS – поддержка образования на крымскотатарском языке и культурного сохранения. Модель уже развёрнута в мобильном приложении-словаре «Qirimtatar lugati» (Osmanov 2019), где она обеспечивает руководство по произношению для словарных статей. Это реальное развёртывание демонстрирует практическую полезность системы для изучающих язык и подтверждает качество, достигнутое нашей методологией.
Конкретные варианты использования включают:
- Интеграция со словарями: внедрение функции синтеза речи в онлайн-платформы и мобильные приложения (например, «Qirimtatar lugati») для обеспечения аудиовизуального сопровождения словарных статей.
- Приложения для изучения языка: создание инструментов отработки корректного произношения для лиц, изучающих крымскотатарский как наследственный язык (heritage language) в условиях диаспоры.
- Обеспечение доступности (Accessibility): разработка аудиоверсий текстового контента для лиц с нарушениями зрения и других категорий пользователей с особыми потребностями.
- Сохранение культурного наследия: озвучивание оцифрованных исторических текстов, архивных материалов и произведений художественной литературы для поддержания языковой среды.
5.3. Ограничения
Необходимо выделить ряд факторов, ограничивающих текущую версию модели:
- Специфика диктора: модель обучена на данных одного диктора, что ограничивает вариативность генерируемых голосов и может приводить к воспроизведению индивидуальных речевых паттернов конкретного исполнителя.
- Фонемный охват: наблюдается нестабильное воспроизведение фонемы /ʒ/ (j), что требует разработки дополнительных алгоритмических решений для корректной обработки слов, содержащих данный звук.
- Просодические характеристики: просодия на уровне предложения, несмотря на общую удовлетворительность, демонстрирует меньшую вариативность в сравнении с естественной речью, что особенно заметно в длинных высказываниях.
- Масштаб верификации: для получения более статистически значимых данных о качестве синтеза требуется проведение расширенного тестирования по методике Mean Opinion Score (MOS) с привлечением репрезентативной выборки носителей языка.
5.4. Обобщаемость
Предложенная методология может быть непосредственно адаптирована для других малоресурсных тюркских языков со сходными фонологическими характеристиками, таких как карачаево-балкарский, кумыкский и гагаузский. К числу ключевых переносимых компонентов относятся:
- алгоритм курации и очистки наборов данных;
- архитектура конвейера предобработки G2P (при условии адаптации правил отображения под конкретный язык);
- конфигурация процесса обучения и выбранные значения гиперпараметров;
- методология оценки качества синтеза.
6. Заключение
В настоящей статье представлена разработка системы синтеза речи (TTS) для крымскотатарского языка. Результаты исследования подтверждают, что применение трансферного обучения на базе предобученных многоязычных моделей позволяет создавать эффективные решения для синтеза речи на языках с критически ограниченными ресурсами. Использование всего 2,53 часа верифицированных обучающих данных в сочетании с дообучением модели SpeechT5 позволило достичь высокого уровня разборчивости и качества синтеза, пригодного для образовательных целей, что подтверждено оценками носителей языка.
Научный и практический вклад работы заключается в следующем:
- представлена первая публично доступная и адаптируемая для дообучения TTS-модель для крымскотатарского языка;
- опубликован очищенный набор речевых данных под открытой лицензией;
- задокументирована методология разработки, применимая к другим исчезающим языкам;
- подтверждена эффективность стратегии трансферного обучения в сценариях с крайне ограниченным объемом данных;
- продемонстрирована практическая значимость исследования через интеграцию системы в мобильное приложение «Къырымтатар лугъаты».
Направления дальнейших исследований будут сосредоточены на:
- переходе к многодикторному синтезу за счет привлечения дополнительных голосовых данных;
- коррекции воспроизведения фонемы /ʒ/ посредством точечного дообучения на специфических выборках;
- создании специализированных пользовательских приложений для изучения языка;
- масштабировании разработанной методологии на родственные тюркские языки.
Все ресурсы проекта – обученная модель, датасет и программный код – предоставлены в открытом доступе для поддержки дальнейших исследований и инициатив по сохранению языкового наследия.
