.png&w=384&q=75)
Актуальность
Процесс составления смет в строительной отрасли характеризуется высокой трудоемкостью и субъективностью ошибок, обусловленных ручным преобразованием неструктурированных текстовых описаний в формализованные позиции. Существующие автоматизированные системы демонстрируют ограниченную эффективность при обработке естественно-языковых описаний, что актуализирует разработку методов машинного понимания семантики технических текстов.
Цель исследования
Разработка и валидация методологии автоматического преобразования свободных текстовых описаний строительных работ в структурированные сметные документы на основе адаптированных языковых моделей большого размера (LLM) с интеграцией в существующие сметные системы.
Методология
Предлагается многоэтапный подход:
- Подготовка аннотированного корпуса пар «текстовое описание – формализованная смета»;
- Специализированный fine-tuning LLM-моделей с применением техник LoRA (Low-Rank Adaptation) и instruction tuning;
- Разработка многоуровневой архитектуры, включающей модули семантического анализа, извлечения сущностей, сопоставления с базой расценок и формирования иерархического вывода;
- Комплексная валидация с использованием метрик precision, recall, F1-score для NER и precision@5, MRR для модуля интеллектуального сопоставления.
Научная новизна
Работа представляет междисциплинарное исследование на стыке компьютерной лингвистики, строительного нормирования и машинного обучения. Теоретический вклад включает: формализацию онтологии сметного домена для задач NLP, разработку модели преобразования free-text → structured-data для технических текстов, методологию оценки адекватности генерации нормативных документов.
Практическая значимость
Внедрение системы позволит снизить трудоемкость подготовки смет на 60–80%, минимизировать арифметические и семантические ошибки, унифицировать форматы документации. Технологические инновации включают архитектуру гибридной системы (LLM + rule-based валидация), механизм confidence scoring для автоматической маркировки непредсказуемых фрагментов и протокол API-интеграции с базами текущих цен и BIM-системами.
Основной текст
В строительной отрасли, где цифровая трансформация затрагивает в первую очередь проектирование (BIM) и управление, одна из самых консервативных и трудоемких процедур – составление смет – долгое время оставалась на обочине прогресса. Инженер-сметчик по-прежнему тратит часы, а иногда и дни, на расшифровку текстов описаний работ из технических заданий, вручную сопоставляя их с тысячами позиций в базах коммерческих расценок. Это не только неэффективно, но и чревато ошибками – «человеческий фактор» в сметном деле напрямую конвертируется в финансовые потери.
Наш проект «ПростоСмета» ставит амбициозную цель: создать ИИ-помощника для, инженера-сметчика, способного понимать свободное описание строительных работ и автоматически формировать корректную, структурированную смету. Результатом должна стать система, сокращающая время создания сметы с часов до минут при сохранении, а в идеале – повышении точности.
Архитектура: модульный монолит с интеллектуальным ядром
Мы спроектировали систему по принципу модульного монолита – единого приложения с четко разделенными ответственностями внутри. Это позволяет достичь высокой производительности за счет отсутствия сетевых издержек между компонентами, сохраняя при этом архитектурную чистоту для будущего масштабирования. Система состоит из пяти ключевых модулей.
Модуль 1: система управления данными и знаниями (Data & Knowledge Core)
Модуль отвечает за хранение всех данных проекта (СУБД PostgreSQL с расширением pgvector). Он хранит:
- базу коммерческих расценок (500,000+ позиций);
- их предрасчитанные семантические эмбеддинги – векторные представления, полученные с помощью fine-tuned версии модели sentence-transformers/paraphrase-multilingual-mpnet-base-v2. Это позволяет выполнять мгновенный семантический поиск в пространстве эмбеддингов с помощью оператора косинусного сходства;
- онтологию строительных работ (граф связей «работа → требует материал»). Подробнее об этом – ниже, в одноименном разделе;
- датасет обратной связи – журнал всех исправлений, вносимых пользователями, для непрерывного обучения системы.
Модуль 2: движок семантического анализа текста (Text Processing Engine)
Первое интеллектуальное звено, его задача – понять, о чем говорит пользователь. Модуль получает на вход «сырой» текст описания работ в свободной форме. На выходе – векторное представление указанной размерности.
Для решения этой задачи выполняется:
- Предварительная обработка и нормализация текста. На вход принимается необработанный текст (объёмом до 2000 символов). На выходе: очищенный текст, список нормализованных токенов, числовые значения.
- Распознавание и извлечение именованных сущностей – на основе fine-tuned модели BERT, обученной на размеченном датасете из 20,000+ строительных описаний. Пример классификации: «стяжка» – это работа, «пескобетон» – материал, «50 мм» – параметр.
- создание семантических эмбеддингов – векторного представления указанной размерности из структурированного представление описания работ
Модуль 3: система интеллектуального сопоставления (Intelligent Matching System)
Сердце ИИ-логики. Этот модуль получает структурированный запрос и решает основную задачу: «какие именно расценки из базы соответствуют описанию»? Мы отказались от простого поиска, по ключевым словам, в пользу гибридного подхода:
- Сначала семантический поиск по эмбеддингам отбирает широкий пул кандидатов. Используется векторный поиск по предрассчитанным эмбеддингам расценок, реализованный в модуле 1;
- Затем ML-ранжировщик (re-ranker), обученный на 150,000+ пар «запрос-релевантная расценка», переоценивает этот пул, выстраивая позиции по степени соответствия контексту всего описания.
Формирование и использование базы знаний строительных работ (подробнее – в разделе «Онтология») позволяет реализовать стратегию декомпозиции и множественного поиска. Например, для запроса «устройство фундаментной плиты» система автоматически генерирует не один, а набор запросов: «фундамент плита», «земляные работы котлован», «бетонные работы фундамент». В итоговую смету включаются все расценки, чья оценка уверенности превышает порог (например, >0.75). Таким образом, система автоматически «разбивает» сложную работу на элементарные сметные позиции – от котлована до бетонирования и гидроизоляции.
Модуль 4: ядро сметного проекта (Estimate Core)
Оркестратор и бизнес-логика. Этот модуль управляет всем workflow: принимает сырой текст, вызывает последовательно Модуль 2 и Модуль 3, получает список расценок, рассчитывает объемы и стоимости на основе извлеченных параметров, и формирует итоговый сметный документ в требуемых форматах (XLSX, XML). Он же обеспечивает целостность данных и работу с черновиками.
Диаграмма ниже описывает workflow при создании сметы из текстового описания работ в свободной форме:
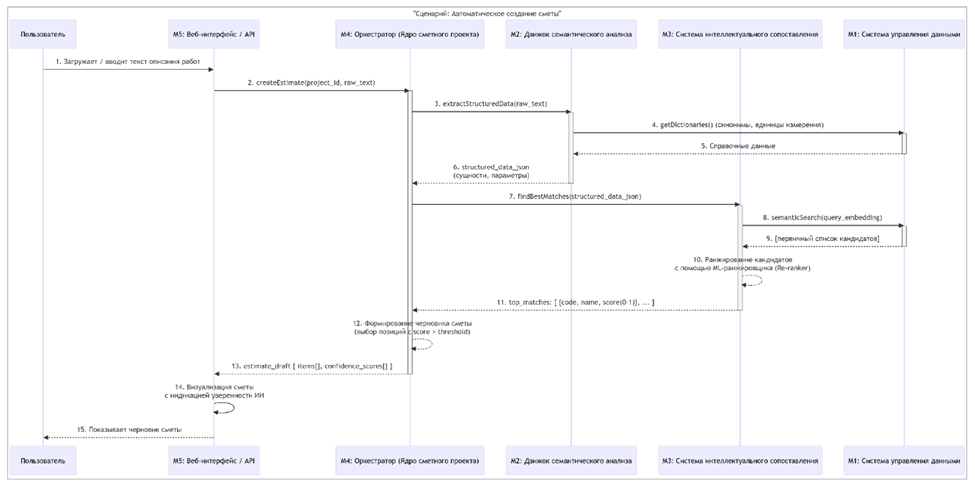
Рис.
Модуль 5: пользовательский интерфейс и API
Лицо системы. Веб-интерфейс для сметчиков спроектирован не просто для отображения, а для эффективного сбора обратной связи. Каждое действие пользователя по исправлению предложения ИИ логируется и отправляется в Модуль 1, становясь новым учебным примером.
В перспективе REST API позволит интегрировать «ПростоСмету» в существующие CRM, ERP и CAD-системы заказчиков.
Онтология строительных работ: как мы кодируем экспертные знания для ИИ
Онтология – это смысловой скелет системы, формализованное представление знаний о предметной области. В контексте «ПростоСметы» онтология отвечает на вопросы: «Из чего состоит каждая работа?», «Что ей нужно?», «Что с ней связано?». Это не просто справочник, а графовая база знаний, которая позволяет системе «мыслить» как инженер-технолог.
Ключевые типы связей в онтологии:
- HAS_PART (агрегация) – «Фундамент состоит из котлована, подготовки, бетонирования»;
- REQUIRES (зависимость) – «Бетонирование требует наличие опалубки»;
- PRECEDES (последовательность) – «Гидроизоляция предшествует бетонированию»;
- ALTERNATIVE_TO (альтернатива) – «Гидроизоляция рулонная vs обмазочная»;
- HAS_PARAMETER (параметризация) – «Стяжка имеет параметр «толщина».
Как мы собирали данные для онтологии
Формирование базы знаний сметного дела оказалось самой трудоемкой и неопределенной (в плане отсутствия априорных алгоритмов) задачей в проекте «ПростоСмета», которая составила около 70% всех работ.
Во-первых, мы произвели анализ весов и attention-механизмов модели NER (Модуль 2). Когда модель BERT определяет, что «стяжка» – это работа, мы можем заглянуть внутрь и понять, на основе чего она это решила.
def extract_concepts_from_ner_model(model, tokenizer, corpus):
"""
Извлекает семантические кластеры понятий из NER-модели
"""
concept_clusters = {}
for text in corpus:
# Получаем предсказания и attention-веса
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs, output_attentions=True)
# Анализируем attention между токенами
attentions = outputs.attentions[-1] # Последний слой
tokens = tokenizer.convert_ids_to_tokens(inputs['input_ids'][0])
# Находим связи между токенами-сущностями
for i, token_i in enumerate(tokens):
if token_i in ['[CLS]', '[SEP]', '[PAD]']:
continue
for j, token_j in enumerate(tokens):
if i == j: continue
# Если внимание между токенами выше порога
attention_score = attentions[0, :, i, j].mean().item()
if attention_score > 0.3: # Порог
concept_clusters.setdefault(token_i, []).append({
'token': token_j,
'score': attention_score,
'context': text
})
# Группируем связанные понятия
return cluster_related_concepts(concept_clusters)
Модель показывает, что, когда она видит «стяжка», она обращает внимание на «пол», «цемент», «мм». Это потенциальные связи для онтологии.
Во-вторых, мы изучили ошибки модели интеллектуального сопоставления (Модуль 3). Когда модель ошибается, анализ ошибок становится золотой жилой для пополнения и корректировки онтологии:
def analyze_matching_errors(validation_dataset, model_predictions):
"""
Анализирует, какие ошибки совершает модель сопоставления
"""
error_patterns = []
for true_item, pred_item in zip(validation_dataset, model_predictions):
if true_item['price_id'] != pred_item['price_id']:
# Находим семантически близкие, но разные расценки
true_work = extract_main_work(true_item['price_text'])
pred_work = extract_main_work(pred_item['price_text'])
# Если модели сложно различать эти работы
if semantic_similarity(true_work, pred_work) > 0.8:
error_patterns.append({
'confused_pair': (true_work, pred_work),
'context': true_item['query_text'],
'frequency': 1
})
# Группируем частые ошибки
error_clusters = cluster_errors(error_patterns)
# Предлагаем эксперту уточнить различия
for cluster in error_clusters:
if cluster['frequency'] > 5: # Частая ошибка
suggest_ontology_refinement(
work_a=cluster['work_a'],
work_b=cluster['work_b'],
reason=f"Модель путает в {cluster['frequency']} случаях",
suggested_relation="ALTERNATIVE_TO или уточнить различия"
)
В-третьих, существенная доля закономерностей была получена в результате статистического анализа исторических данных и датасетов:
Анализ совместной встречаемости в исторических сметах. Мы анализируем тысячи уже составленных смет (исторические данные) как готовые «рецепты» от опытных сметчиков. Если две работы часто встречаются вместе в одних и тех же проектах, между ними с высокой вероятностью есть смысловая связь. В результате получаем статистически подтвержденные связи с коэффициентами уверенности. Например: «Устройство опалубки → Устройство арматурного каркаса (вероятность совместной встречаемости: 85%)»;
Анализ временных последовательностей в работах. Мы изучаем порядок выполнения работ по структуре уже составленных смет. Это позволяет выявить технологические последовательности – что за чем должно следовать по правилам строительства. В результате получаем граф отношений «предшествует» (PRECEDES) с указанием вероятности соблюдения последовательности. Например: «Монтаж каркаса → Обшивка ГКЛ (соблюдается в 95% проектов)»;
Обнаружение иерархий через кластеризацию. Мы берем векторные представления (эмбеддинги) всех строительных работ (полученные из языковых моделей) и с помощью алгоритмов кластеризации группируем семантически близкие работы. Затем определяем, какое общее понятие объединяет каждую группу:
1. Кластеризация: алгоритм автоматически группирует работы в кластеры по семантической близости;
2. Анализ кластеров: смотрим, какие работы попали в одну группу:
- Кластер 1: «стяжка», «наливной пол», «мозаичный пол»;
- Кластер 2: «штукатурка», «шпатлевка», «грунтовка».
3. Определение родителя: для каждого кластера находим обобщающее понятие:
- Кластер 1 → «Устройство покрытий пола»;
- Кластер 2 → «Подготовка поверхностей стен».
4. Построение иерархии: создаем отношения «родитель-потомок».
В результате получаем иерархическую структуру строительных работ, где общие понятия находятся выше, а конкретные работы – ниже.
В-четвертых, онтологические связи могут быть получены из текстовых описаний технических заданий через паттерны «включает», «требует» и т. д. Например:
- «Устройство полов включает в себя стяжку, гидроизоляцию и финишное покрытие» → HAS_PART;
- «Монтаж ГКЛ требует устройства каркаса» → REQUIRES.
В перспективе мы планируем реализовать оперативное автоматическое добавление новых связей из датасета обратной связи. Например, если пользователи часто добавляют к «стяжке» работу «шлифовка», система добавляет новую связь HAS_PART. Это позволит рассматривать платформу «ПростоСмета», как самообучающуюся систему, адаптирующуюся под специфику своей организации и/или направления деятельности.
Пример работы в сценарии «Фундаментная плита»
Предположим, пользователь вводит исходный запрос: «Устройство монолитной плиты 10x10x0.5м».
Действия системы «ПростоСмета» с онтологией:
- Находит узел work_foundation_slab;
- По связям HAS_PART получает список составных работ: разработка котлована; устройство щебеночной подготовки; устройство гидроизоляции; монтаж опалубки; армирование; бетонирование; уход за бетоном;
- Используя правила из онтологии, рассчитывает: объем котлована volume_excavation = 10 * 10 * (0.5 + 0.3) = 80 м³ (0.3 м – запас по глубине из онтологии); площадь гидроизоляции area_waterproofing = 10 * 10 = 100 м²;
- После формирования сметы проверяет, что гидроизоляция предшествует бетонированию (связь PRECEDES).
Как мы измеряем успех: ключевые метрики
Качество системы оценивается по строгим, общепринятым в ML-сообществе метрикам:
- Для Модуля 2 (семантический анализ): F1-мера на отложенной тестовой выборке. Цель: >0.91. Это означает, что модель правильно находит и классифицирует более 9 из 10 сущностей в тексте;
- Для Модуль 3 (интеллектуальное сопоставление): две ключевые метрики: Precision@5: >0.95. В 95% случаев правильная расценка будет среди пяти первых предложенных вариантов. Это гарантия, что пользователю не придется листать бесконечные списки; Средний Reciprocal Rank (MRR): >0.75. Это «золотая» метрика поисковых систем. Она показывает, насколько высоко в списке находится первый правильный ответ. MRR=0.75 означает, что в большинстве случаев нужная расценка будет на первой или второй позиции, что соответствует опыту работы с высококвалифицированным ассистентом.
- Сквозная метрика системы: доля полностью корректных позиций в итоговой смете (не требующих правки). Цель для MVP: >80%. Остальные 20% будут помечены системой как «низкая уверенность» для обязательной проверки человеком.
Планы на будущее
В ближайших планах по развитию продукта:
- Доработка интерфейса в сторону user friendly (удобные контекстные меню);
- Обмен данными с другими сметными программами через АРПС;
- Параллельная работа со сметами нескольких пользователей;
- Undo/Redo для возврата и отмены действий.
Текущая версия системы создает сметы в коммерческих расценках. После того как мы доведем ее до состояния стабильного продукта, в планах сделать аналогичную систему для нормативных смет, составленных по федеральной сметно-нормативной базе (ФСНБ-2022), с использованием ресурсно-индексного метода для расчета сметной стоимости.
Заключение
Проект «ПростоСмета» – это не попытка заменить инженера-сметчика. Это инструмент когнитивного усиления, который берет на себя рутинную, энергоемкую работу по первичному сопоставлению и поиску расценок, позволяя специалисту сосредоточиться на сложных, нестандартных случаях, переговорах и контроле качества. Архитектура, построенная вокруг модульного монолита и двух специализированных моделей машинного обучения, создает баланс между производительностью, точностью и возможностью эволюционного развития.
Мы строим не просто программу, а самообучающуюся систему, которая со временем будет понимать специфику своей организации и предпочтения конкретного сметчика, становясь по-настоящему персональным ИИ-ассистентом в мире сметного дела.
Но наша работа только начинается. Самые совершенные алгоритмы бессильны без обратной связи от специалистов-практиков. Чтобы превратить «ПростоСмету» в действительно полезный инструмент для ежедневной работы, нам критически важны:
- отзывы после тестирования (в каких случаях сформированные расценки оказались неточными, какие позиции упущены или добавлены не по делу);
- конструктивная критика (что раздражает в интерфейсе, какие функции работают нелогично, чего не хватает для комфортной работы);
- предложения по улучшению (какие сценарии использования мы упустили, что из вашего профессионального опыта должно быть заложено в логику системы).
