.png&w=384&q=75)
Введение
Современное развитие технологий искусственного интеллекта характеризуется переходом от использования изолированных больших языковых моделей (LLM) к созданию мультиагентных систем (MAS), обеспечивающих достижение системного интеллекта через координацию действий множества агентов [6]. Традиционно взаимодействие в таких системах строится на основе обмена текстовыми сообщениями на естественном языке, который выступает универсальным посредником между участниками процесса [4, с. 51991-52008]. Однако использование текста накладывает существенные ограничения на эффективность функционирования системы. Естественный язык является средой с низкой пропускной способностью обмена данными, создающей семантическое «узкое горлышко» [1, 2]. Высокоразмерные внутренние представления моделей при текстовой коммуникации принудительно сжимаются в линейные последовательности дискретных символов, что неизбежно ведет к потере значимой семантической информации. Кроме того, процесс посимвольной генерации текста и его последующее повторное кодирование приемником вносят значительные задержки в работу системы, снижая её общую вычислительную производительность [3, 11].
Существующие подходы к реализации мультиагентных систем, такие как AutoGen, CAMEL или ReAct, ориентированы на явную вербализацию промежуточных шагов (цепочек рассуждений), что, несмотря на повышение интерпретируемости, способствует накоплению ошибок и увеличивает операционные затраты [7, 10]. В качестве альтернативы были предложены методы латентных рассуждений, например, Coconut, демонстрирующие преимущества внутреннего поиска в непрерывном скрытом пространстве, однако они ограничиваются рамками одной модели [3]. Стратегии прямой передачи семантики, такие как Cache-to-Cache, позволяют обмениваться данными через кэш ключей и значений (KV-кэш), но они преимущественно ориентированы на наследование контекста и не обеспечивают полноценной совместной работы агентов в скрытом пространстве [2]. Таким образом, в современной науке существует потребность в разработке единой архитектуры, объединяющей внутреннее латентное мышление агентов с механизмами бесшовной передачи знаний между ними.
Целью настоящего исследования является выявление ключевых преимуществ и ограничений метода латентной коллаборации по сравнению с традиционными текстовыми подходами.
Для достижения поставленной цели в статье решаются следующие задачи:
- Проведение сравнительного анализа текстовых и латентных подходов к организации взаимодействия в мультиагентных системах.
- Систематизация механизмов архитектуры LatentMAS, включая процессы авторегрессионной генерации скрытых мыслей и передачи латентной рабочей памяти.
- Оценка выигрыша в вычислительной сложности и точности при использовании латентной коллаборации на основе анализа экспериментальных данных.
Научная новизна работы состоит в систематизации и проведении сравнительного анализа эффективности текстовых и латентных подходов к взаимодействию агентов. На основе сопоставления архитектур (AutoGen, CAMEL, ReAct, Coconut, Cache-to-Cache и LatentMAS) обосновано теоретическое и практическое превосходство передачи непрерывных представлений (KV-кэша) над дискретным текстовым обменом, что позволяет рассматривать латентную коллаборацию как наиболее перспективный вектор развития мультиагентных систем.
Обзор литературы
Развитие мультиагентных систем (MAS) на базе больших языковых моделей (LLM) обусловлено необходимостью перехода от изолированного решения задач к коллективному интеллекту, где взаимодействие агентов позволяет декомпозировать сложные проблемы на подзадачи [5, 7]. В рамках данного обзора существующие подходы классифицированы по среде взаимодействия: текстовые системы, основанные на естественном языке, и латентные методы, использующие непрерывные внутренние представления моделей.
Классические текстовые мультиагентные системы
Традиционные подходы опираются на текстовое взаимодействие как универсальную среду обмена информацией. Одной из ключевых работ в этом направлении является программная среда AutoGen, которая предоставляет гибкую инфраструктуру для создания MAS. Агенты в AutoGen характеризуются способностью к ведению диалога, настраиваемостью и возможностью интеграции инструментов или человеческого участия. Основным отличием данной системы является поддержка различных паттернов взаимодействия, включая динамические групповые чаты и иерархические структуры [7].
Параллельно развивалась концепция ролевых игр, реализованная в проекте CAMEL. В основе данного фреймворка лежит метод «inception prompting» (инцептивное инструктирование), который направляет агентов к выполнению задачи, сохраняя соответствие намерениям пользователя. Автономная кооперация между агентом-пользователем и агентом-помощником осуществляется через последовательный обмен инструкциями и решениями, что позволяет минимизировать вмешательство человека в процесс планирования [4, с. 51991-52008].
Важным этапом в эволюции текстовых MAS стало внедрение парадигмы ReAct, которая обеспечивает синергию рассуждения и действия. Метод предполагает чередование генерации цепочек рассуждений (thoughts) и специфических для задачи действий (actions). Рассуждения помогают модели обновлять планы и обрабатывать исключения, в то время как действия позволяют взаимодействовать с внешними источниками, такими как базы знаний или программные интерфейсы [10].
Несмотря на эффективность, текстовые MAS сталкиваются с рядом фундаментальных ограничений. Естественный язык в качестве канала связи создает семантическое «узкое горлышко»: высокоразмерные внутренние представления сжимаются в дискретные токены, что ведет к потере информации [11]. Кроме того, посимвольная генерация вносит вычислительную избыточность и увеличивает задержку вывода [1, 2].
Латентные методы и оптимизация взаимодействия
В ответ на ограничения текстовых систем были предложены методы, использующие скрытое пространство (latent space) LLM для процессов мышления и коммуникации. Подход Coconut (Chain of Continuous Thought) предлагает перенести процесс рассуждения из лингвистической области в непрерывную среду. Вместо декодирования скрытых состояний в токены, Coconut напрямую подает последнее скрытое состояние последнего слоя трансформера на вход для следующего итерационного шага. Теоретический анализ и эксперименты показывают, что такие «непрерывные мысли» обладают более высокой выразительностью и позволяют реализовывать стратегии поиска, аналогичные поиску в ширину (BFS), что повышает точность решения логических задач [3].
Проблема эффективной передачи данных между различными моделями рассматривается в исследовании Cache-to-Cache (C2C). Авторы предлагают парадигму прямой семантической коммуникации через кэш ключей и значений (KV-кэш). C2C использует нейронную сеть для проекции и слияния KV-кэша модели-источника с кэшем модели-приемника, что обеспечивает бесшовную передачу знаний без промежуточной генерации текста. Экспериментально подтверждено, что данный подход превосходит текстовый обмен данными по точности на 3,0–5,0% при двукратном ускорении вывода [2].
Дополнительные исследования в области совместного использования слоев KV-кэша (Cross-Layer KV Sharing) демонстрируют возможности значительного сокращения потребления памяти (до 2 раз) при сохранении конкурентоспособности моделей. Методы, подобные LCKV и YOCO, оптимизируют внутреннюю работу трансформера, вычисляя ключи и значения только для подмножества слоев, что закладывает основу для более эффективной латентной обработки данных [8, с. 396-403; 9].
Анализ литературы показывает, что до появления LatentMAS исследования развивались фрагментарно: либо в сторону латентных рассуждений внутри одной модели (Coconut), либо в сторону передачи контекста между двумя моделями (C2C). Не существовало единой методологии, которая объединяла бы генерацию латентных мыслей и системную межагентную коллаборацию в скрытом пространстве без необходимости повторного обучения весов. LatentMAS закрывает этот пробел, предлагая универсальный фреймворк для полной латентной коллаборации, обеспечивающей lossless (без потерь) передачу информации и существенное снижение вычислительной сложности по сравнению с традиционными текстовыми MAS [11].
Основная часть
Архитектура и функциональные механизмы LatentMAS
Методологический базис фреймворка LatentMAS опирается на концепцию сквозной латентной коллаборации, при которой интеллектуальные агенты на базе больших языковых моделей (LLM) взаимодействуют исключительно в непрерывном скрытом пространстве, минуя этап декодирования промежуточных рассуждений в текстовые токены. Архитектура системы объединяет два ключевых функциональных механизма: внутреннюю генерацию латентных мыслей и межагентную передачу латентной рабочей памяти. В отличие от традиционных текстовых мультиагентных систем (TextMAS), где «универсальной средой» обмена данными служит естественный язык, LatentMAS реализует прямое сопряжение внутренних представлений моделей, что обеспечивает сохранение семантической полноты при существенном снижении вычислительных затрат [11].
Визуально процесс трансформации скрытых состояний и их передачи между агентами через механизм KV-кэша, объединяющий этапы генерации мыслей и коммуникации, представлен на схеме (рис. 1).
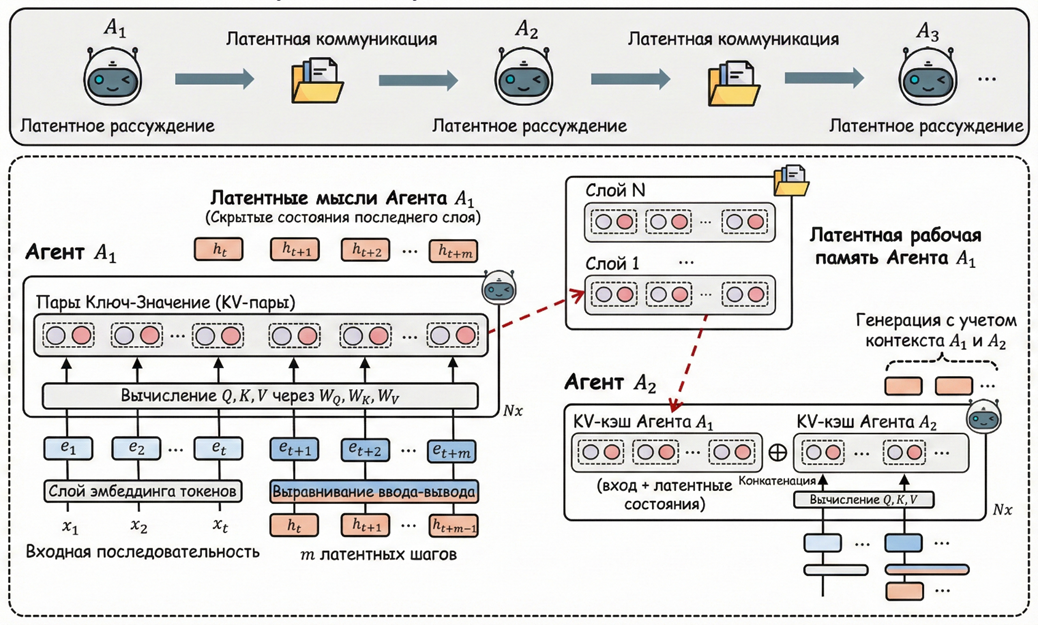
Рис. 1. Общая схема LatentMAS. Показано, как Агент 1 генерирует латентные мысли, а затем передает их через послойный KV-кэш Агенту 2
Процесс авторегрессионной генерации латентных мыслей
Внутренняя логика работы каждого агента ![]() в системе строится на модифицированном процессе авторегрессионного вывода. В стандартном режиме (TextMAS) трансформерная модель преобразует входную последовательность в скрытые представления, которые на последнем слое проецируются на пространство словаря для выбора следующего токена. В LatentMAS вместо явной генерации текста агент оперирует скрытыми векторами последнего слоя (hidden states). Полученное на текущем шаге
в системе строится на модифицированном процессе авторегрессионного вывода. В стандартном режиме (TextMAS) трансформерная модель преобразует входную последовательность в скрытые представления, которые на последнем слое проецируются на пространство словаря для выбора следующего токена. В LatentMAS вместо явной генерации текста агент оперирует скрытыми векторами последнего слоя (hidden states). Полученное на текущем шаге ![]() скрытое представление
скрытое представление ![]() напрямую подается на вход модели для шага
напрямую подается на вход модели для шага ![]() , заменяя собой стандартный процесс эмбеддинга токена [11].
, заменяя собой стандартный процесс эмбеддинга токена [11].
Данный итерационный цикл повторяется в течение латентных шагов, в результате чего формируется последовательность ![]() , определяемая как «латентные мысли» агента. Теоретическое обоснование данного подхода, сформулированное в рамках гипотезы линейного представления, указывает на то, что такие непрерывные мысли обладают значительно более высокой экспрессивной способностью по сравнению с дискретными символами. Согласно теореме об экспрессивности, один латентный шаг способен передать объем информации, эквивалентный длинной последовательности текстовых токенов, что делает процесс мышления в скрытом пространстве на порядки эффективнее вербализованных цепочек рассуждений (CoT) [11].
, определяемая как «латентные мысли» агента. Теоретическое обоснование данного подхода, сформулированное в рамках гипотезы линейного представления, указывает на то, что такие непрерывные мысли обладают значительно более высокой экспрессивной способностью по сравнению с дискретными символами. Согласно теореме об экспрессивности, один латентный шаг способен передать объем информации, эквивалентный длинной последовательности текстовых токенов, что делает процесс мышления в скрытом пространстве на порядки эффективнее вербализованных цепочек рассуждений (CoT) [11].
Механизм выравнивания входных и выходных распределений
Критическим аспектом архитектуры является проблема несовпадения статистических распределений: векторы скрытых состояний последнего слоя ![]() по своей структуре отличаются от обученных векторов входных вложений (embeddings). Прямая подача выходных векторов на вход без корректировки может привести к активациям, выходящим за пределы нормы (out-of-distribution), что дестабилизирует работу модели [11].
по своей структуре отличаются от обученных векторов входных вложений (embeddings). Прямая подача выходных векторов на вход без корректировки может привести к активациям, выходящим за пределы нормы (out-of-distribution), что дестабилизирует работу модели [11].
Эффективность применения оператора линейного выравнивания для корректировки дрейфа скрытых векторов и их возвращения в область допустимых значений входных эмбеддингов продемонстрирована на графиках плотности распределения (рис. 2).
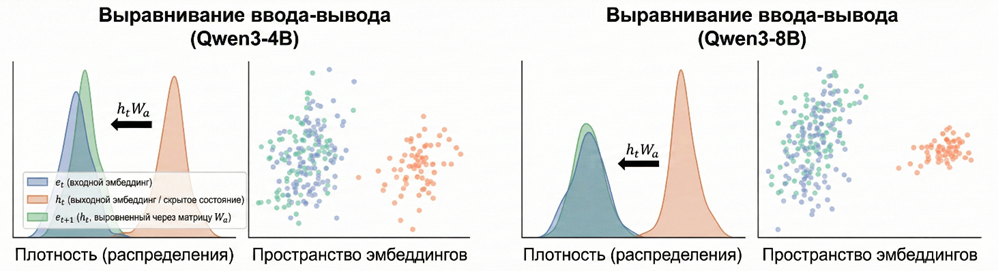
Рис. 2. Демонстрация эффективности выравнивания ввода-вывода. Показывает, как выравнивание возвращает смещенные векторы обратно в исходное пространство эмбеддингов
Для решения этой задачи во фреймворке реализован оператор линейного выравнивания. На основе матриц входных (![]() ) и выходных (
) и выходных (![]() ) вложений агента вычисляется проекционная матрица
) вложений агента вычисляется проекционная матрица ![]() , которая отображает вектор
, которая отображает вектор ![]() в пространство, соответствующее входным параметрам модели:
в пространство, соответствующее входным параметрам модели: ![]() . Для обеспечения численной стабильности и предотвращения дрейфа представлений матрица
. Для обеспечения численной стабильности и предотвращения дрейфа представлений матрица ![]() рассчитывается методом гребневой регрессии (ridge regression), что минимизирует расстояние Вассерштейна между распределениями токенов и выровненных латентных векторов. Данный механизм является полностью автономным и не требует дополнительного обучения или настройки весов основной модели, что сохраняет универсальность подхода [11].
рассчитывается методом гребневой регрессии (ridge regression), что минимизирует расстояние Вассерштейна между распределениями токенов и выровненных латентных векторов. Данный механизм является полностью автономным и не требует дополнительного обучения или настройки весов основной модели, что сохраняет универсальность подхода [11].
Передача латентной рабочей памяти и межагентная коллаборация
Коллаборация между агентами в LatentMAS реализуется через механизм передачи латентной рабочей памяти (latent working memory). В текстовых системах после завершения работы одного агента его результат в виде строки символов добавляется в контекст следующего участника, что неизбежно ведет к потере семантических нюансов при сжатии многомерных данных в токены. В LatentMAS информация передается без потерь (lossless) путем экспорта кэша ключей и значений (KV-cache) всех слоев трансформера [11].
Латентная рабочая память агента ![]() определяется как совокупность накопленных матриц ключей и значений для всех слоев модели, инкапсулирующая как исходный вопрос, так и сгенерированные латентные мысли. При переходе к следующему агенту
определяется как совокупность накопленных матриц ключей и значений для всех слоев модели, инкапсулирующая как исходный вопрос, так и сгенерированные латентные мысли. При переходе к следующему агенту ![]() этот объем данных интегрируется в его собственную структуру через послойную конкатенацию KV-кэшей. Таким образом, последующий агент приступает к генерации собственных мыслей, уже находясь в контексте полных, неискаженных внутренних представлений предшественника [11].
этот объем данных интегрируется в его собственную структуру через послойную конкатенацию KV-кэшей. Таким образом, последующий агент приступает к генерации собственных мыслей, уже находясь в контексте полных, неискаженных внутренних представлений предшественника [11].
Теоретический анализ подтверждает, что такая форма обмена эквивалентна прямой передаче всех вычислений, но исключает избыточные повторные расчеты, которые потребовались бы при обработке текста. С точки зрения вычислительной сложности, LatentMAS демонстрирует значительное преимущество: в то время как временные затраты TextMAS растут пропорционально количеству генерируемых токенов и размеру словаря, сложность LatentMAS зависит главным образом от размерности скрытого пространства и количества латентных шагов. Это позволяет достигать высокой точности при кратно меньшем количестве итераций вывода [11].
Представленная архитектура является инвариантной относительно конкретных стратегий взаимодействия и может быть успешно внедрена как в последовательные конвейерные системы (planner-critic-refiner), так и в иерархические структуры с разделением по дисциплинарным областям (code-math-science) [11].
Гибкость архитектуры позволяет реализовывать различные топологии взаимодействия агентов, включая последовательные и иерархические схемы, структура которых проиллюстрирована ниже (рис. 3).
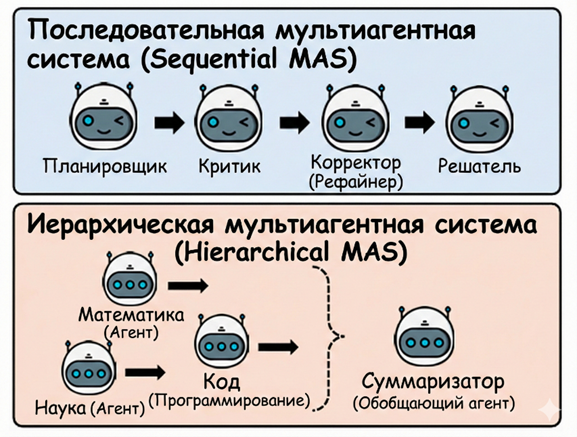
Рис. 3. Иллюстрация последовательной (Sequential) и иерархической (Hierarchical) схем работы мультиагентной системы
Сравнительная оценка эффективности и точности коллаборации
В данном подразделе проводится сопоставительный анализ фреймворка LatentMAS с традиционными мультиагентными системами, основанными на текстовом взаимодействии (TextMAS), и одиночными моделями (Single Model). Оценка осуществляется по трем ключевым критериям: вычислительная сложность, эффективность использования ресурсов (объем токенов и скорость вывода) и точность решения задач в различных предметных областях.
Вычислительная эффективность и ресурсы
Теоретический анализ вычислительной сложности подтверждает значительное превосходство латентной коллаборации над текстовой. Согласно данным базового исследования, временная сложность работы каждого агента в системе LatentMAS определяется как ![]() , где
, где ![]() – размерность скрытого пространства,
– размерность скрытого пространства, ![]() – количество латентных шагов,
– количество латентных шагов, ![]() – длина входной последовательности, а
– длина входной последовательности, а ![]() – число слоев трансформера. В отличие от этого, текстовое взаимодействие (TextMAS) требует существенно больших затрат для достижения эквивалентной выразительной способности, поскольку сложность генерации и последующего кодирования дискретных токенов растет пропорционально размеру словаря
– число слоев трансформера. В отличие от этого, текстовое взаимодействие (TextMAS) требует существенно больших затрат для достижения эквивалентной выразительной способности, поскольку сложность генерации и последующего кодирования дискретных токенов растет пропорционально размеру словаря ![]() и количеству итераций вывода. Латентный подход позволяет передавать информацию в
и количеству итераций вывода. Латентный подход позволяет передавать информацию в ![]() раз эффективнее, что для моделей масштаба 14B означает преимущество в экспрессивности более чем в 470 раз по сравнению с текстом [11].
раз эффективнее, что для моделей масштаба 14B означает преимущество в экспрессивности более чем в 470 раз по сравнению с текстом [11].
Экспериментальные данные, подтверждающие кратное ускорение вывода и значительное сокращение объема используемых токенов по сравнению с текстовыми системами и одиночными моделями, приведены на диаграммах (рис. 4).
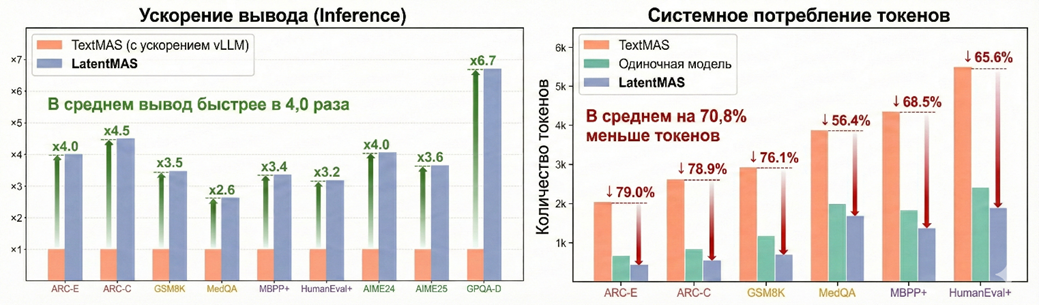
Рис. 4. Графики ускорения и сокращения использования токенов. Показывают преимущество LatentMAS над TextMAS
Эмпирические результаты подтверждают теоретические выводы: LatentMAS демонстрирует кратное ускорение работы системы. Средний показатель ускорения сквозного вывода (end-to-end inference speed) составляет от 4,0x до 4,3x по сравнению с TextMAS. Примечательно, что данный выигрыш сохраняется даже при использовании оптимизированных бэкендов, таких как vLLM, обеспечивающих ускорение базовых текстовых систем. Столь высокая производительность обусловлена отказом от трудоемких процессов посимвольного декодирования промежуточных рассуждений. Вместо генерации десятков тысяч токенов для построения цепочек рассуждений (CoT), агентам LatentMAS требуется менее 50 латентных шагов для достижения сопоставимых или более высоких результатов в математических и логических задачах [11].
Параллельно с ростом скорости наблюдается радикальное снижение потребления токенов. В последовательных конфигурациях MAS объем генерируемых данных сокращается на 70,8%, а в иерархических структурах – на 83,7%. В задачах повышенной сложности, таких как MedQA или HumanEval+, сокращение объема токенов достигает 87,9%. Это объясняется тем, что взаимодействие происходит через прямую передачу латентной рабочей памяти (KV-кэша), а не через лингвистическое посредничество, которое требует избыточных синтаксических конструкций. Таким образом, LatentMAS перераспределяет вычислительную нагрузку: основная часть работы выполняется в непрерывном пространстве, а текстовый вывод используется только на финальном этапе для формирования ответа пользователю [11].
Точность и качество интеллектуальной деятельности
Анализ точности (Accuracy) на девяти репрезентативных наборах данных показывает, что LatentMAS стабильно превосходит как одиночные модели, так и текстовые мультиагентные системы. Средний прирост точности по сравнению с одиночной моделью составляет 14,6% в последовательной архитектуре и 13,3% в иерархической. При сравнении с TextMAS, использующей те же алгоритмы планирования и те же базовые модели, латентная коллаборация обеспечивает дополнительный прирост в 2,8–4,6%. Превосходство наблюдается во всех категориях задач: математическое и научное рассуждение (GSM8K, AIME, GPQA), понимание здравого смысла (ARC) и генерация программного кода (MBPP+, HumanEval+) [11].
Детальные численные показатели точности, скорости и расхода токенов для последовательной конфигурации системы на различных бенчмарках (ARC, GSM8K, MedQA и др.) обобщены в таблице (рис. 5).
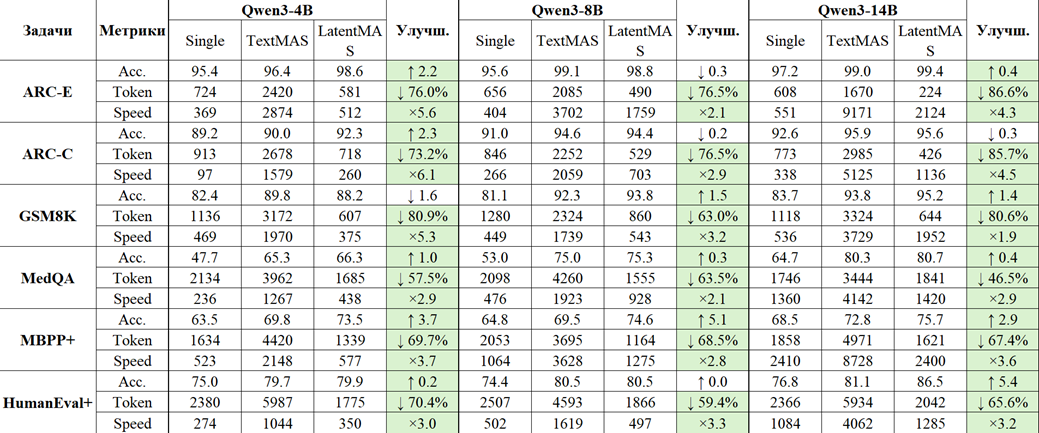
Рис. 5
Ключевым фактором повышения точности является высокая выразительная способность латентных мыслей. Визуализация распределений скрытых состояний подтверждает, что латентные представления в LatentMAS не только охватывают семантическое пространство правильных текстовых ответов, но и обладают большей плотностью и разнообразием. Это позволяет моделям кодировать нюансы и альтернативные пути решения, которые теряются при принудительной дискретизации в токены. Теоретически обосновано, что один шаг латентного рассуждения передает объем информации, недоступный короткой последовательности слов [11].
Визуализация пространства эмбеддингов подтверждает, что сгенерированные латентные мысли охватывают более широкий семантический спектр по сравнению с дискретными текстовыми токенами, обеспечивая более глубокую выразительную способность (рис. 6).
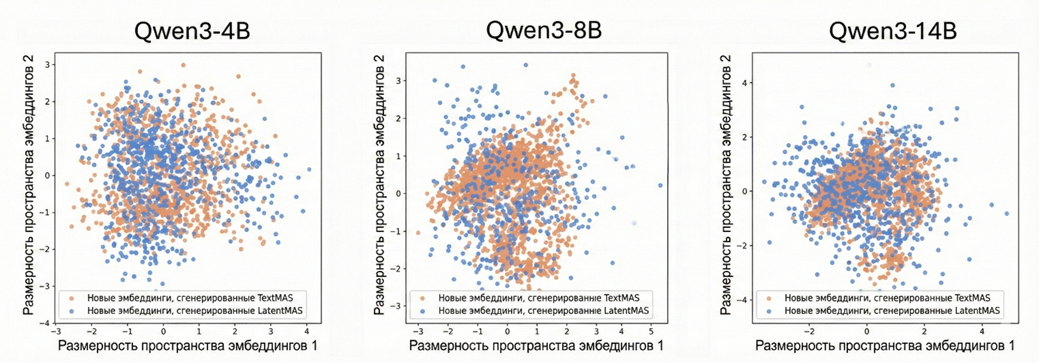
Рис. 6. Диаграмма рассеяния, показывающая, что новые эмбеддинги LatentMAS покрывают пространство более плотно и широко, чем текстовые
Особое значение имеет способность латентной коллаборации противодействовать накоплению ошибок (error compounding), характерному для текстовых конвейеров. В системах TextMAS ошибки и неверные интерпретации, допущенные агентом-планировщиком, фиксируются в тексте и неизбежно ограничивают пространство поиска для последующих агентов (критика и исполнителя). В LatentMAS агенты обмениваются «мягкими» непрерывными представлениями. Это дает последующим участникам возможность переосмысливать и корректировать логику предшественников, не ограничиваясь рамками однажды сгенерированного ошибочного текста. Результаты тестирования на задачах GSM8K показывают, что там, где текстовые агенты заходят в тупик из-за неверной промежуточной вербализации, латентные агенты находят верное решение благодаря сохранению полной семантической истории в рабочей памяти [11]. Таким образом, переход в скрытое пространство обеспечивает не только количественное ускорение, но и качественное изменение динамики коллективного рассуждения, делая его более гибким и устойчивым к деградации логики.
Заключение
Проведенное исследование подтверждает, что переход от текстового взаимодействия к прямой коллаборации в скрытом пространстве является необходимым этапом эволюции мультиагентных систем. В работе продемонстрировано, что использование естественного языка как исключительной среды взаимодействия интеллектуальных агентов создает критическое «узкое горлышко», ограничивающее как выразительную способность моделей, так и общую вычислительную эффективность системы.
Основные выводы исследования свидетельствуют о высокой эффективности рассмотренного фреймворка LatentMAS. Реализация механизмов авторегрессионной генерации скрытых мыслей в сочетании с послойной передачей латентной рабочей памяти позволила устранить этапы избыточного декодирования и повторного кодирования информации. Это привело к качественному скачку в производительности: скорость сквозного вывода увеличилась более чем в 4 раза, в то время как объем генерируемых данных сократился на 70,8–83,7% в зависимости от архитектуры взаимодействия.
Особое теоретическое значение имеет подтверждение гипотезы о превосходстве непрерывных представлений над дискретными токенами. Математический анализ показал, что латентные шаги обладают кратно более высокой экспрессивностью, позволяя кодировать сложные семантические структуры, которые теряются при принудительной вербализации. С практической точки зрения это выразилось в устойчивом приросте точности решения логических и математических задач (до 14,6%), а также в способности системы эффективно противодействовать накоплению ошибок, характерному для традиционных текстовых цепочек рассуждений.
Научная новизна работы подтверждается результатами систематизации универсальной методологии, которая не требует дополнительного обучения или настройки весов моделей, что делает её легко интегрируемой в существующие корпоративные ИИ-ландшафты. Проанализированный метод линейного выравнивания распределений успешно решает проблему стабильности скрытых состояний, обеспечивая предсказуемость работы системы.
В качестве перспективных направлений для дальнейших изысканий следует выделить адаптацию механизмов латентной коллаборации для гетерогенных систем, объединяющих модели различных семейств и размерностей. Разработка обучаемых переходных интерфейсов (адаптеров) позволит расширить область применения LatentMAS, обеспечивая бесшовный обмен знаниями в мультимодальных средах и сложных распределенных сетях искусственного интеллекта.
