.png&w=384&q=75)
Введение
В современных компьютерных сетях выбор протокола динамической маршрутизации напрямую влияет на надёжность и скорость доставки трафика. Особенно это важно для сервисов реального времени (IP-телефония, видеоконференции и др.), поскольку время реакции сети на изменение топологии – выход из строя канала или узла – определяет качество их работы [1].
Два широко используемых протокола внутренних шлюзов – OSPF и EIGRP – принципиально различаются по подходам к обмену маршрутной информацией. OSPF (Open Shortest Path First) – это link-state протокол, стандартизованный IETF (RFC 2328), который строит полную карту связности и применяет алгоритм Дейкстры для вычисления кратчайших путей [2]. EIGRP (Enhanced Interior Gateway Routing Protocol), изначально разработанный Cisco и опубликованный как стандарт (RFC 7868) в 2016 году, представляет собой гибридный протокол: он сочетает элементы дистанционно-векторных и link-state методов и использует алгоритм DUAL для предотвращения петель и локализации перерасчётов маршрутов [3, 4].
При выборе между ними обычно приходится идти на компромисс. OSPF обеспечивает межвендорную совместимость и лучшие возможности масштабирования благодаря иерархии областей и расширенным типам областей (stub, NSSA и т. д.), что выгодно в больших распределённых сетях [5]. EIGRP, в свою очередь, проще настраивается в рамках Cisco-инфраструктуры и часто демонстрирует более быструю конвергенцию после сбоев за счёт локализованных обновлений и механики DUAL. Оба протокола значительно превосходят устаревшие алгоритмы вроде RIP по скорости сходимости, но в большинстве типовых сценариев EIGRP показывает меньшее время восстановления маршрутов.
Литература даёт подтверждение этим наблюдениям, но одновременно подчёркивает ограничения существующих исследований. Например, Farhangi et al. (2016) моделировали комбинацию EIGRP, OSPF и IS-IS в полумеш-топологии и зафиксировали снижение end-to-end задержек и джиттера для голосового трафика при совместном использовании трёх протоколов [6]. Однако авторы отмечали возрастание сложности сети и необходимость аккуратной настройки redistribution, а моделирование в OPNET не учитывало реальную загрузку CPU маршрутизаторов, что ограничивает применимость выводов в продакшене. Аналогично, работы Mardedi & Rosidi и Kaur & Mir показывают преимущество EIGRP по времени конвергенции в симуляциях, но также указывают на сильные стороны OSPF в плане детерминированности и межвендорной совместимости [7,8].
В этой статье описывается методика моделирования и сравнительного анализа OSPF и EIGRP в эмуляционной среде PNetLab. Для воспроизводимости эксперимента заданы идентичная топология, адресация и параметры линков; отдельно приводятся настройки процессов маршрутизации, команда мониторинга и сценарии отказов. Основное внимание уделено измерению времени сходимости при отключении канала и восстановлении связи, а также влиянию выбора протокола на стабильность таблиц маршрутов и нагрузку на оборудование.
Топология сети и ее настройки представлены ниже:
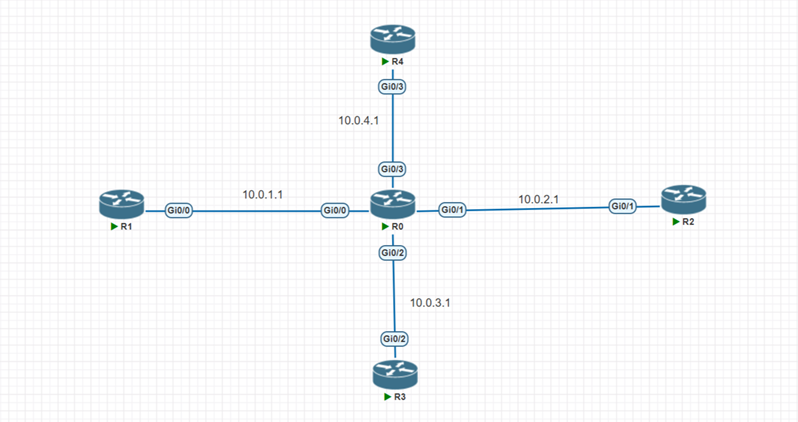
Рис. 1. Топология сети в PnetLab
Таблица 1
Первичные данные для настройки
Маршрутизатор | Интерфейс | IP-адрес | Маска | Описание |
| gig0/0 | 10.0.1.1 | /30 | Соединение с R1 |
| gig0/1 | 10.0.2.1 | /30 | Соединение с R2 |
R0(центральный) | gig0/2 | 10.0.3.1 | /30 | Соединение с R3 |
| gig0/3 | 10.0.4.1 | /30 | Соединение с R4 |
| loopback | 10.255.255.251 | /32 | Router-Id |
R1 | gig0/0 | 10.0.1.2 | /30 | Соединение с R0 |
| loopback | 1.1.1.1 | /30 | Router-Id |
R2 | gig0/1 | 10.0.2.2 | /30 | Соединение с R0 |
| loopback | 2.2.2.2 | /32 | Router-Id |
R3 | gig0/2 | 10.0.3.2 | /30 | Соединение с R0 |
| loopback | 3.3.3.3 | /32 | Router-Id |
R4 | gig0/3 | 10.0.4.2 | /30 | Соединение с R0 |
| loopback | 4.4.4.4 | /32 | Router-Id |
Настройки протоколов
На первом этапе экспериментальной сети запускался протокол OSPF, на втором – EIGRP (отдельно, без одновременной работы друг с другом). Для OSPF на всех маршрутизаторах настроен процесс router ospf 1, на R1–R4 выполнена команда passive-interface default с исключением активного интерфейса к R0 (чтобы избежать рассылки лишних Hello в локальную сеть loopback). Все сети /30 и /32 объявлялись в OSPF area 0 командой network. Метрики OSPF оставались по умолчанию (стоимость вычисляется от пропускной способности интерфейсов, которые у нас гигабитные Ethernet, cost = 1). Интерфейсы функционируют в режиме Broadcast (по умолчанию для Ethernet), что означает выборы DR/BDR даже на линках типа точка-точка /30 – фактически в каждой такой подсети из двух маршрутизаторов один становился DR, другой BDR. На R0, имеющем соединения с четырьмя соседями, ожидалось состояние DR на трех из них и BDR на одном (там, где удаленный выбрался DR).
Для EIGRP настроен процесс router eigrp 10 (AS номер 10) на каждом маршрутизаторе. Все интерфейсы, подключенные к транзитным сетям 10.0.X.0/30, были включены в EIGRP командой network. Loopback-интерфейсы R1–R4 для простоты в EIGRP не анонсировались (чтобы исключить влияние лишних маршрутов; router-ID EIGRP не настолько критичен для установления соседства). Метрики EIGRP также использовались по умолчанию (на основе пропускной способности и задержки; все линки равны по параметрам, поэтому метрика между любыми двумя узлами через R0 была одинаковой). Функции EIGRP stub или широковещательных оптимизаций не применялись – топология небольшая, и все маршрутизаторы, кроме R0, граничат только с R0.
После запуска процесса OSPF на всех маршрутизаторах наблюдалось успешное формирование соседских отношений. Маршрутизатор R0 установил соседство Full с каждым из R1–R4. В соответствии с алгоритмом выбора DR (Designated Router) на многодоступных сетях, R0 стал роутером (DR) на трёх из четырех сегментов, а на одном сегменте выступил в роли BDR (Backup DR), уступив DR удаленному узлу. Это объясняется тем, что на каждом point-to-point Ethernet-линке OSPF всё равно проводит выборы: поскольку на каждом таком сегменте всего 2 маршрутизатора, один из них получает статус DR, другой – BDR. В нашем случае, например, на сегменте R0–R1 роль DR досталась R1 (благодаря более высокому Router ID 1.1.1.1 против 10.0.1.1 у R0), и R0 там стал BDR; на остальных же сегментах R0 оказался DR. Вывод команды show ip ospf neighbor на R0 подтверждает данную картину (рис. 2): в списке соседей все четыре узла (RID 1.1.1.1, 2.2.2.2, 3.3.3.3, 4.4.4.4) находятся в состоянии FULL, при этом сосед 1.1.1.1 помечен как DR, а остальные (2.2.2.2, 3.3.3.3, 4.4.4.4) – как BDR, тогда как сам R0 для них является DR.
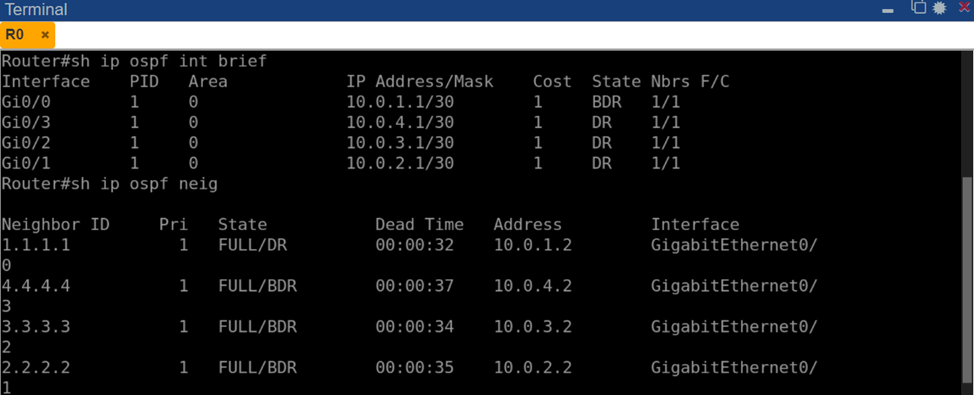
Рис. 2. Соседство маршрутизаторов OSPF на R0: все четыре удалённых узла достигли состояния Full (R0 – DR для сегментов к R2, R3, R4 и BDR для сегмента к R1)
Обмен маршрутной информацией между маршрутизаторами завершился успешно: каждый узел получил сведения о сетях своих соседах. Например, на R0 таблица маршрутов show ip route содержала записи об удалённых подсетях 10.0.2.0/30, 10.0.3.0/30, 10.0.4.0/30 (ведущих к R2, R3, R4 соответственно) с типом OSPF (маршруты типа O, внутриплощадочные) и указанием следующего хопа – адреса R0 (10.0.1.1). Также присутствовали маршруты к loopback-адресам 2.2.2.2/32, 3.3.3.3/32, 4.4.4.4/32 через R0.
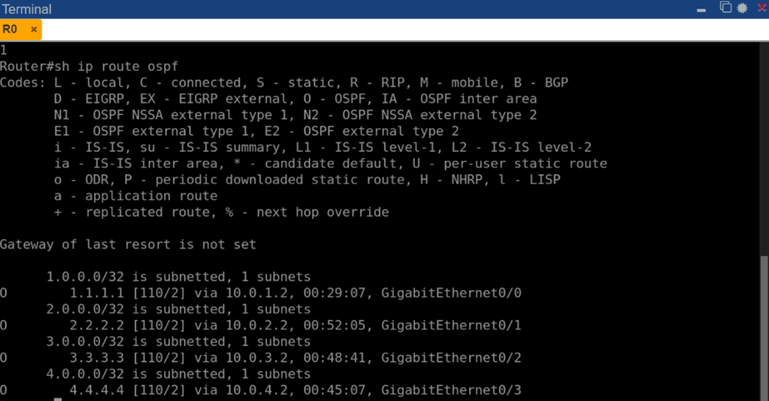
Рис. 3. Таблица маршрутов OSPF на маршрутизаторе R0 (вывод команды show ip route ospf)
Таким образом, до возникновения каких-либо сбоев связь между любыми двумя периферийными узлами осуществлялась через R0 за два перехода (2 hop). Это проверялось посредством пинга и трассировки: например, с R1 адрес R4 (10.0.4.2) успешно пинговался, а traceroute 10.0.4.2 показывал цепочку из двух узлов – сперва 10.0.1.1 (R0), затем 10.0.4.2 (R4).
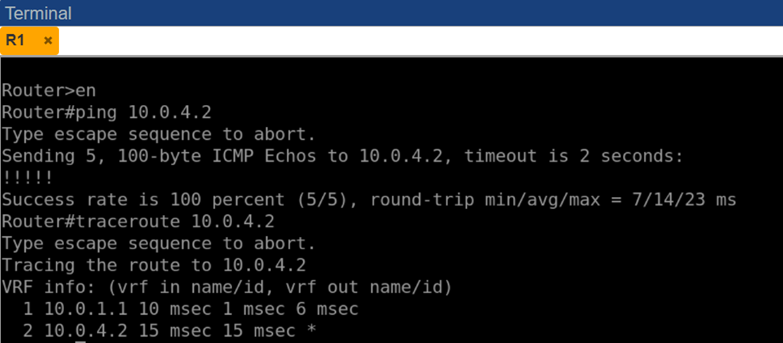
Рис. 4. Результаты команд ping и traceroute от маршрутизатора R1 до R4
В нормальном режиме нагрузка на процессор от работы OSPF была минимальной: по команде show processes cpu / include OSPF центральный маршрутизатор R0 показывал ~0.07% использования CPU планировщиком OSPF и 0% – процессом отправки Hello-пакетов.
Далее был проведен главный эксперимент – имитация отказа канала между R0 и R4. В момент времени t=0 c на интерфейсе R0 Gi0/3 (ведущем к R4) была выполнена команда shutdown. Это привело к немедленному разрыву L2-сессии на данном линке. Для OSPF физическое состояние интерфейса играет ключевую роль: при down-событии интерфейса маршрутизатор мгновенно сообщает остальным узлам об уходе соседа. В нашем случае R0 сразу перестал получать Hello от R4 и удалил соседа 4.4.4.4 из списка, не дожидаясь истечения полного тайм-аута (Dead Interval по умолчанию 40 секунд) [9]. R0 сгенерировал обновление LS Update об изменении топологии – фактически, о недоступности сети R4. Остальные маршрутизаторы (R1–R3) приняли этот LSU и обновили свою базу состояния. В результате узлы R1, R2, R3 вычислили новую карту сети, из которой исчезли маршруты, проходящие через R4. На практике, поскольку топология звезда и альтернативных путей нет, маршрутизаторы R1–R3 просто удалили из таблиц маршрут к сети 10.0.4.0/30 и к петлевой 4.4.4.4/32.
Со стороны пользователя отказ проявился как потеря доступности R4. Непрерывный пинг, запускавшийся с R1 на адрес 10.0.4.2, сначала выдавал стабильные ответы, но после отключения линка начали фиксироваться пропуски. На рисунке 3 показан фрагмент вывода команды ping на R1 в момент непосредственно после отказа: символы. обозначают отсутствие ответа на ICMP-запрос (таймаут), а символ U означает получение сообщения Destination Unreachable (источник – сам R1 либо R0 уведомил об отсутствии маршрута). Видно, что сразу после разрыва связи несколько пакетов не получили ответов, что соответствует периоду перестройки маршрутов.
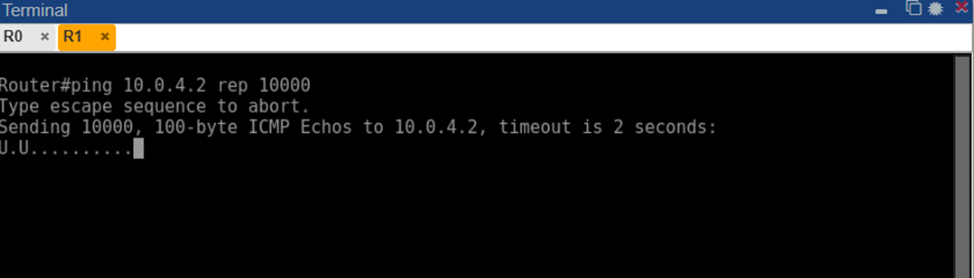
Рис. 5. Фрагмент вывода непрерывного ping на R1 во время отказа линка OSPF: серия точек и символ "U" свидетельствуют об отсутствии связи с R4
Полное время, за которое OSPF-сеть пришла в новое состояние без R4, составило порядка 50 секунд. Эта оценка получена исходя из числа подряд потерянных ping-пакетов и значения интервала между ними. Всего из 10000 отправленных пакетов около 52 не получили ответа (успешность 99%, см. вывод на рис. 4), то есть связь отсутствовала примерно 50–52 секунды. Следует отметить, что большая часть этого времени – это срабатывание механизма обнаружения отказа на периферийных узлах. Хотя R0 уведомил соседей быстрее (через обновление LSA), маршрутизаторы R1–R3 должны были дождаться нового расчета SPF. Кроме того, на момент самого отключения могли быть пакеты в процессе, которые также считались потерянными.
Спустя 50 с после начала сбоя сетевой протокол достиг устойчивого состояния, в котором R4 отсутствовал. Таблица соседей OSPF на R0 теперь содержала только три записи (R1–R3), что подтверждает разрыв соседства с R4. Проверка на R1 показала, что маршрут до 10.0.4.2 исчез из таблицы (что естественно). Пинг продолжал выдавать только ошибки, не пытаясь более отправлять запросы к R4 (маршрутизатор R1 сразу возвращал «U – Destination Unreachable», зная об отсутствии маршрута).
Через некоторое время после этого был произведен обратный шаг – восстановление связи. На интерфейсе R0 Gi0/3 была введена команда no shutdown, на R4 интерфейс поднят автоматически (при восстановлении питания или по включению администратора). R0 мгновенно зафиксировал восстановления линии L2, и OSPF сразу начал обмен Hello с R4. Поскольку до сбоя R4 уже был известен сети, процесс повторного соседства прошел быстрее полной первоначальной синхронизации: R0 и R4 обменялись пакетом Database Description (DBD), затем LS Request/LS Update для актуализации базы (Wireshark-захват на интерфейсе R0–R4 показал серию OSPF пакетов типа DB Description, LS Request, LS Update в первые секунды после восстановления соединения). Спустя ~5–6 секунд после поднятия интерфейса соседство R0-R4 перешло в состояние Full. Маршрутизатор R0 разослал остальным обновленные LSAs с включением R4, те выполнили SPF и добавили маршруты к сетям R4 обратно. В итоге, примерно через 6–8 секунд после физического восстановления канала вся сеть вновь стала полностью связной. Команда ping на R1 возобновила получение ответов от 10.0.4.2 (серия символов «!» в выводе). На рисунке 4 приведена заключительная статистика пинга, свидетельствующая о 99% успешности – то есть потеря ~52 пакетов, как упоминалось ранее.
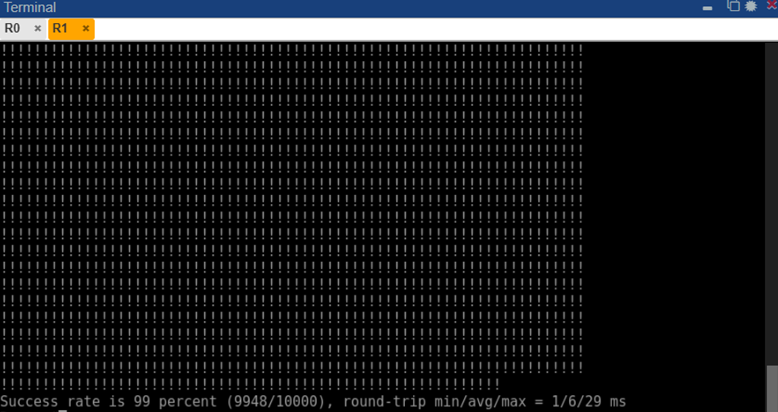
Рис. 6. Результат непрерывного пингования (10000 пакетов) с R1 до R4 через OSPF
Таким образом, в тестируемой ситуации протокол OSPF справился с отказом, но за сравнительно длительное время – порядка десятков секунд. Основной вклад в задержку восстановления вносит используемый интервал держания (Hello/Dead) и необходимость перерасчета маршрутов на всех узлах. Следует отметить, что параметры OSPF можно оптимизировать: например, включение механизма Fast Hello (уменьшение интервалов Hello/Dead до 1/3 секунд) или использование протокола BFD для контроля линков способно сократить время обнаружения падения до единиц секунд или меньше [10]. Однако в нашем эксперименте намеренно использованы стандартные настройки, чтобы сравнение с EIGRP было корректным (так как EIGRP тоже работал с настройками по умолчанию). В штатном режиме, как мы видели, нагрузка от OSPF была незначительна; во время конвергенции всплеск загрузки CPU на R0 также не превысил доли процента (для большей достоверности стоило бы замерять интервальным счётчиком, однако в маленькой топологии перегрузить процессор OSPF не смог). Тем не менее, в крупных сетях число LSAs при изменениях может быть существенным, и перерасчет SPF – ресурсоёмкая операция
Испытание EIGRP проводилось на той же топологии после выключения процессов OSPF и очистки таблиц маршрутизации. Сразу после запуска процесса router eigrp 10 на всех узлах маршрутизаторы установили EIGRP-соседство по схеме «каждый с R0». Маршрутизатор R0 обнаружил четырех соседей (R1–R4) через мультикаст-адрес 224.0.0.10, используемый EIGRP для рассылки Hello. Команда show ip eigrp neighbors на R0 отобразила список из 4 соседних адресов (10.0.1.2, 10.0.2.2, 10.0.3.2, 10.0.4.2) – по одному на каждый интерфейс, все в состоянии Up. В выводе этой команды также видны значения Hold time (в начале ~15 секунд, которые будут отсчитываться при отсутствии пакетов Hello) и время с момента установления соседства (Uptime). На рис. 5 приведен фрагмент такого вывода: можно видеть, что к моменту снимка каждый сосед был в сети уже более 10 минут, что свидетельствует о стабильности соседств до проведения аварийных мероприятий.
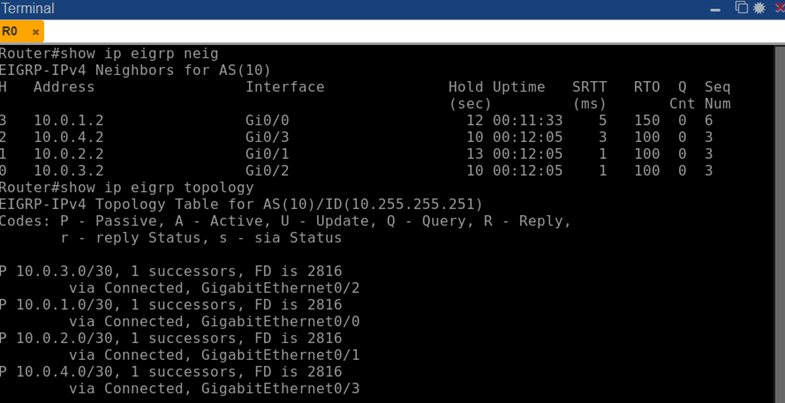
Рис. 7. Соседние маршрутизаторы EIGRP на R0 (фрагмент вывода show ip eigrp neighbors): R0 имеет 4 соседа (R1–R4) по AS 10, время с момента установления превышает 10 минут, все пакеты (Q cnt = 0) доставлены, задержка (SRTT) порядка 1–5 мс.
Обмен маршрутами в EIGRP завершился практически мгновенно после установления соседств: EIGRP отправляет обновления (Update-пакеты) сразу при формировании соседства, передавая полный набор известных маршрутов. В результате маршруты появились во всех таблицах.
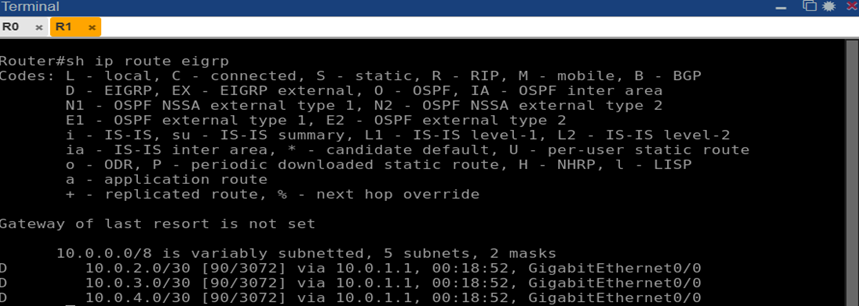
Рис. 8. Таблица маршрутов EIGRP на маршрутизаторе R1 (вывод команды show ip route eigrp)
Пример для R1: команда show ip route eigrp на R1 показала префиксы 10.0.2.0/30, 10.0.3.0/30, 10.0.4.0/30 с отметкой D (EIGRP) и метриками, а также указанием следующего хопа 10.0.1.1 (R0). Маршруты до loopback’ов 2.2.2.2/32 и т. д. на R1 отсутствовали, так как мы их не объявляли, но связь между узлами R1–R4 обеспечивалась через соответствующие транзитные сети. Проверка связности показала успешный сквозной обмен: пинг с R1 до R4 (10.0.4.2) проходил, траекторией были R1 → R0 → R4 (2 хопа). Средняя задержка ICMP эхо примерно 7–10 мс.
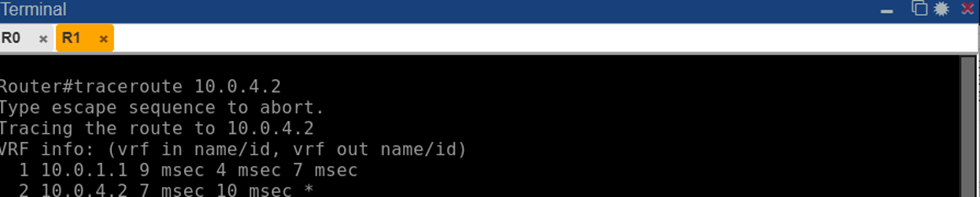
Рис. 9. Трассировка маршрута от маршрутизатора R1 к R4
Рис. 10
В нормальных условиях фоновые процессы EIGRP потребляли минимум ресурсов: show processes cpu / include EIGRP на R0 дал 0% использования CPU задачами EIGRP и Hello.
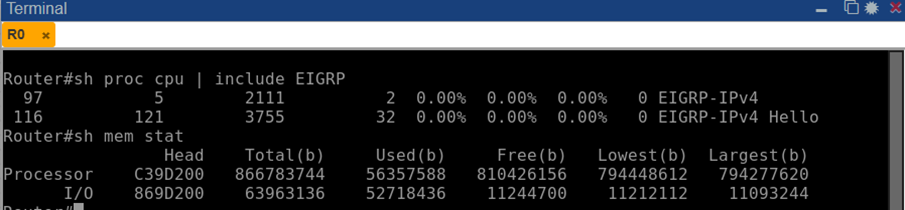
Рис. 11. Использование процессора процессами EIGRP на маршрутизаторе R0
Для анализа поведения EIGRP при сбое был проведен аналогичный эксперимент: отключение связи между R0 и R4. В момент t=0 интерфейс R0 Gi0/3 (AS 10) отключался. В отличие от OSPF, EIGRP также чувствителен к физическому статусу линка: падение интерфейса привело к немедленному удалению соседства R0–R4 без ожидания Hold-time. То есть маршрут R4 сразу пометился как недоступный у R0. Однако, особенностью EIGRP является необходимость проверить, нет ли альтернативных путей к пропавшей сети. Как только R0 заметил потерю соседа, он запустил процедуру Diffusing Update Algorithm (DUAL) для затронутых маршрутов. В нашем случае это маршруты, ведущие через R4 (а именно сеть 10.0.4.0/30 и, гипотетически, любые сети за R4). R0, не найдя у себя альтернатив (feasible successor) для этих маршрутов, сформировал EIGRP Query-пакеты и разослал всем остальным соседям (R1, R2, R3) запрос: не знает ли кто-либо из них путь до потерянных префиксов. Захват трафика на R0 подтверждает это:
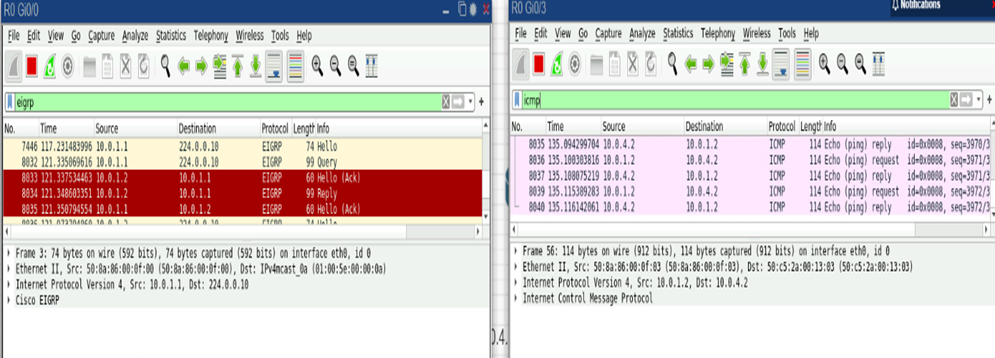
Рис. 12. Анализ трафика EIGRP (Hello, Query, Reply) и ICMP (Echo Request/Reply) в Wireshark
Таким образом, R0 убедился, что ни у кого другого пути до R4 не существует, и окончательно удалил проблемные маршруты из таблицы. DUAL гарантирует при этом отсутствие каких-либо петель и завершение алгоритма за конечное число шагов.
После восстановления связи (интерфейс R0 Gi0/3 no shut) процесс обратный: R0 мгновенно сформировал новое соседство с R4 (Hello/ACK обменяны, затем Update). R0 узнал от R4 о сети 10.0.4.0/30 и распространил эту информацию. Благодаря тому, что в EIGRP объявления рассылаются надежно и быстро (мультикаст + подтверждения), уже через несколько сотен миллисекунд узлы R1–R3 получили Update о возврате маршрута и внесли его обратно в таблицу. Пинг с R1 после паузы сразу вновь стал получать ответы.
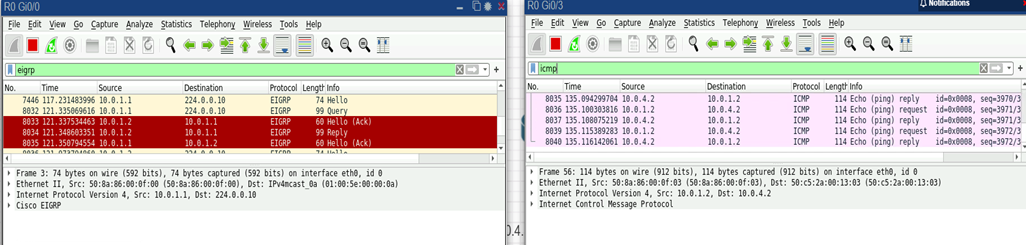
Рис.. 13. Анализ трафика EIGRP (Hello, Ack) и ICMP (Echo Request/Reply) в Wireshark после восстановления связи
Количество потерянных пакетов при отказе EIGRP оказалось значительно меньше, чем в сценарии с OSPF. При длительном тесте (25000 ping-запросов) успешность составила 99,8% – потеряно всего 44 пакета (рис. 6). Это соответствует периоду недоступности около 15 с, что в три раза быстрее, чем у OSPF (≈50 с). При этом основная задержка связана не с реакцией протокола, а с ручной паузой перед восстановлением связи. Фактическая конвергенция EIGRP заняла менее секунды после отказа и несколько секунд после восстановления, что согласуется с настройками таймеров по умолчанию (Hold Time 15 с против Dead Interval 40 с у OSPF) и отсутствием необходимости пересылки LSAs.
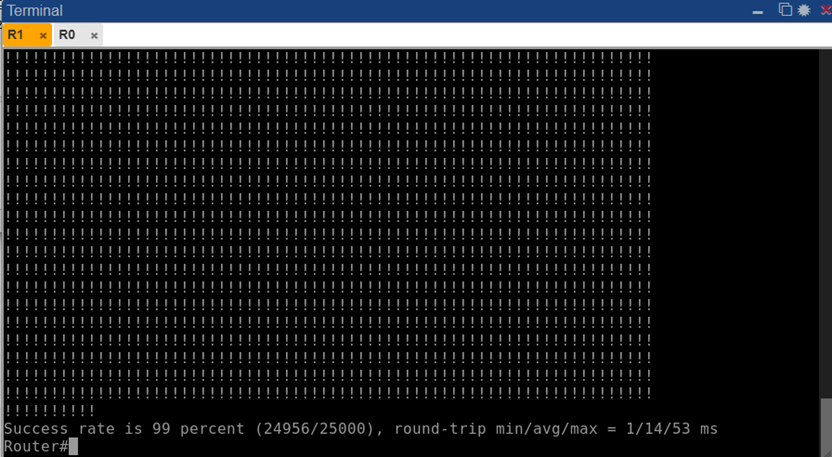
Рис. 14. Результат пинг-теста (25000 пакетов) с R1 до R4 через EIGRP
Во время конвергенции EIGRP загрузка процессора маршрутизаторов практически не изменилась. Обмен Query/Reply и обновление таблиц выполняются в памяти и не требуют значительных вычислений, так как алгоритм DUAL использует уже рассчитанные метрики. Замеры показали, что пик CPU не превышал 5–7%, включая фоновые процессы. Объём служебного трафика также оказался минимальным: EIGRP отправил лишь несколько Query и Update ближайшим соседям, тогда как OSPF передаёт LSA всем маршрутизаторам области. Это подтверждает ключевое преимущество EIGRP – локализованную реакцию на изменения без необходимости оповещения всей сети.
Результаты испытаний подтвердили различие в поведении OSPF и EIGRP при сбоях связи. На идентичной топологии EIGRP показал более быструю конвергенцию – около 15 с против 40–50 с у OSPF, что связано с разницей таймеров и механизмом DUAL, обеспечивающим мгновенную локальную реакцию. Потери пакетов при сбое составили <0,2% для EIGRP и около 1% для OSPF, что особенно важно для трафика реального времени.
После восстановления канала EIGRP обновил маршруты почти мгновенно, тогда как OSPF потребовал несколько секунд на синхронизацию базы LSDB. В обоих случаях нагрузка на процессор была минимальной, однако OSPF требует больше вычислений из-за перерасчёта всей топологии, тогда как EIGRP обрабатывает только соседние маршруты.
В целом, EIGRP продемонстрировал трёхкратное преимущество по скорости восстановления сети и меньшие потери пакетов, тогда как OSPF остаётся более универсальным решением для крупных и мультивендорных инфраструктур. Современные версии OSPF с поддержкой Fast Reroute и Partial SPF уже сокращают этот разрыв, обеспечивая время восстановления менее секунды.
Заключение
Проведённое исследование позволило сравнить работу OSPF и EIGRP в одинаковых условиях на звездообразной топологии. Результаты показали, что EIGRP обеспечивает более быструю конвергенцию – около 15 секунд против 50 секунд у OSPF, что снижает потери пакетов и делает его более подходящим для сервисов реального времени. Благодаря алгоритму DUAL EIGRP реагирует локально, обмениваясь обновлениями только с соседями, тогда как OSPF выполняет перерасчёт по всей области, создавая большую нагрузку при сбоях.
Несмотря на это, OSPF гарантирует согласованность маршрутов и остаётся предпочтительным решением для крупных и разнородных сетей благодаря поддержке иерархии областей и открытым стандартам. Оба протокола продемонстрировали стабильность и надёжность, без ложных срабатываний или колебаний маршрутов.
Оба решения могут быть оптимизированы: OSPF – с помощью Fast Hello, BFD и ускоренного SPF, EIGRP – за счёт уменьшения Hold Time и быстрой реакции на L2-события. При этом в реальных условиях эффективность повышается при наличии резервных каналов и технологий быстрого перенаправления трафика (MPLS FRR, IP Fast Reroute).
Таким образом, EIGRP рациональнее использовать в сетях с оборудованием Cisco, где важна скорость восстановления и простота конфигурации, тогда как OSPF остаётся универсальным стандартом для масштабных мультивендорных инфраструктур. Результаты эксперимента подтверждают выводы предыдущих исследований о преимуществе EIGRP по скорости сходимости и устойчивости к отказам.
