.png&w=384&q=75)
Introduction
Modern software systems increasingly adopt microservice architectures to achieve scalability and maintainability. However, this architectural paradigm introduces significant operational complexity, as applications are decomposed into numerous loosely coupled services that communicate through intricate dependency graphs [1, p. 1-12]. When failures occur, on-call engineers must correlate symptoms across multiple services, analyze heterogeneous telemetry data (metrics, logs, and traces), and understand complex inter-service dependencies – a process that becomes increasingly impractical at scale.
The emergence of Large Language Models (LLMs) has opened new possibilities for automating complex reasoning tasks in software operations. According to recent market analysis, the global LLM observability platform market reached $1.97 billion in 2025 and is projected to grow at a CAGR of 36.3% to reach $2.69 billion in 2026 [2]. However, practical deployment faces substantial challenges. Independent benchmarking reveals significant gaps: OTelBench evaluated frontier LLMs on OpenTelemetry instrumentation tasks and found that even the best-performing model achieved only a 29% pass rate, compared to 80.9% on standard coding benchmarks [3].
This paper provides a concise analysis of the current landscape of LLM integration in observability. The contributions are: (1) a review of recent LLM-based incident management frameworks; (2) an analysis of key performance metrics; and (3) a discussion of critical success factors and future directions.
Background and Key Challenges
Observability relies on three primary types of telemetry data: metrics, logs, and traces [1, p. 1-12]. Metrics are structured quantitative measurements (e.g., latency, error rates); logs are timestamped event records; traces capture request execution paths across service boundaries. Each modality provides complementary diagnostic value, but manual correlation becomes overwhelming at scale. Traditional AIOps models face limitations: they are often designed for single subtasks, require expensive labeled data, and operate as “black boxes” [1, p. 1-12].
Recent research has identified persistent challenges when applying LLMs to incident management [1, p. 1-12]:
- Semantic simplification: many approaches reduce logs and traces to superficial statistical features, neglecting rich textual semantics.
- Textual data overload: the sheer volume of logs and traces exceeds processing capacity.
- LLM limitations: issues such as hallucinations and context window limits persist.
A motivating study by Sun et al. (2025) found that single LLMs produce factually incorrect diagnostic conclusions in 50% of cases when analyzing real-world incidents [1, p. 1-12]. OTelBench further quantifies these limitations, showing that even frontier models fail on fundamental instrumentation tasks like context propagation [3].
Current Research Frameworks
1. TrioXpert: Collaborative Multi-LLM Framework
TrioXpert, proposed by Sun et al. (2025) addresses single-LLM limitations through a collaborative architecture [1, p. 1-12]. Its components include:
- Multimodal Data Preprocessing: modality-specific pipelines and filtering to extract incident-relevant data.
- Multi-Dimensional System Status Representation: consolidates numerical and textual features into a unified view.
- LLMs Collaborative Reasoning: three LLM-based agents (Numerical, Textual, Incident Experts) jointly perform anomaly detection, failure triage, and root cause localization.
Evaluation on two real-world microservice datasets showed improvements: anomaly detection +4.7% to +57.7%, failure triage +2.1% to +40.6%, root cause localization +1.6% to +163.1% over baselines [1, p. 1-12].
Figure 1 illustrates the architecture of an LLM-based incident management pipeline
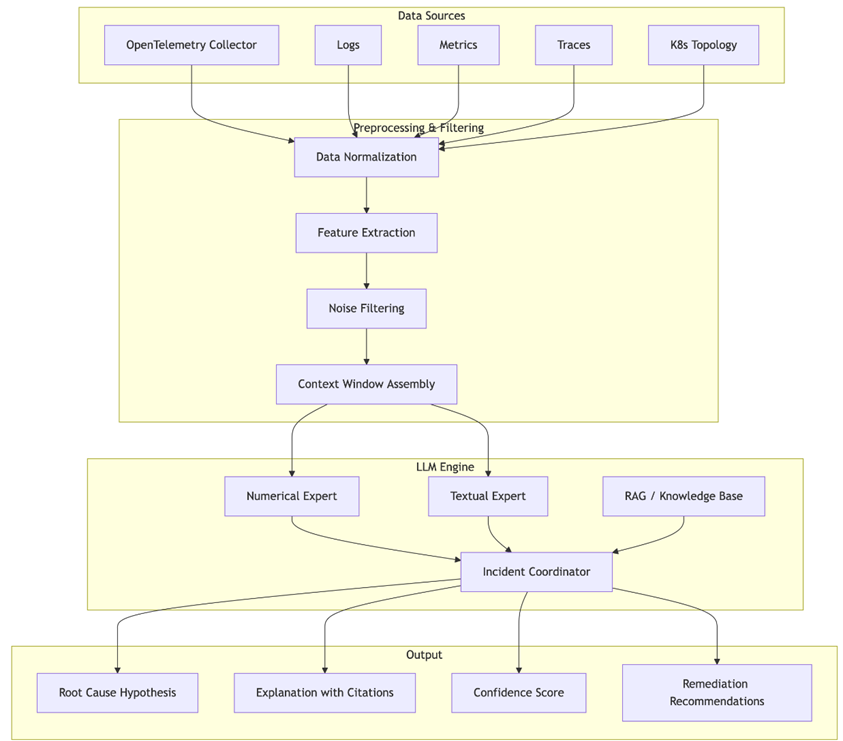
Fig. 1. Architecture of an LLM-based incident management pipeline for automated root cause analysis (adapted from [1, p. 1-12])
2. GALA: Graph-Augmented LLM Agentic Workflow
GALA (Graph-Augmented Large Language Model Agentic Workflow), introduced by Tian et al. (2025), combines statistical causal inference with LLM-driven iterative reasoning [4]. It integrates a trace-based scoring method (TWIST) with causal graph analysis and uses a multi-agent workflow to refine root cause hypotheses. GALA achieved up to 42.22% Top-1 accuracy improvement over state-of-the-art methods on the RCAEval dataset [4].
3. AgentTrace: Structured Logging for Agent System Observability
AlSayyad et al. (2026) introduced AgentTrace, a framework for dynamic observability of LLM-powered agent systems [5]. It captures structured logs across three surfaces: operational (system metrics), cognitive (chain-of-thought reasoning), and contextual (environmental interactions). AgentTrace enables more reliable agent deployment and accountability [5].
4. Additional Frameworks: Log Anomaly Detection and Recovery Assistance
De la Cruz Cabello et al. (2026) implemented a self-supervised anomaly detection framework (LogBERT) on normal syslog sequences, achieving high accuracy [6]. Bonato et al. (2025) introduced AIMA+, an incident management assistant that uses LLM-based data augmentation to predict recovery actions, improving macro F1-score from 0.2 to 0.6 [7, p. 376-379].
Industry Adoption and Empirical Benchmarks
OTelBench (January 2026) evaluated frontier LLMs on OpenTelemetry instrumentation tasks [3]. Key findings: best model achieved 29% pass rate (vs. 80.9% on SWE-Bench); context propagation proved insurmountable; no model solved a single task in Swift, Ruby, or Java. This highlights a critical gap: LLMs are not yet capable of fundamental instrumentation tasks required for production engineering [3].
Observability for LLM-powered applications introduces new telemetry dimensions: token usage, cost scaling, latency profiles (time to first token, tokens per second), response quality, prompt versioning, and agentic workflow traces [8]. Traditional monitoring gives false coverage; LLM observability is essential for reliability and cost control [8, 9].
Market growth: The LLM observability platform market grew from $1.97B in 2025 to $2.69B in 2026 (CAGR 36.3%) and is projected to reach $9.26B by 2030 [2]. Key drivers: agentic workflows, AI governance, cost optimization, and DevOps integration.
Critical Success Factors
Reliable deployment of LLMs in observability requires addressing several key factors:
- Hallucination suppression: Effective strategies include prompt engineering, knowledge graph embedding, and feedback loop mechanisms that validate outputs against system state [1, p. 1-12; 4; 9].
- Explainability and transparency: Systems must provide structured reasoning chains, evidence citation, and confidence scores. Frameworks like TrioXpert, GALA, and AgentTrace demonstrate these principles [1, p. 1-12; 4; 5].
- Multimodal data integration: Preserving modality-specific information (semantic richness) through specialized pipelines outperforms naive fusion [1, p. 1-12; 4].
- Cost-aware architecture: Selective LLM invocation, caching, and tiered model selection are essential given that cost is the top tool-selection criterion [2, 8].
Figure 2 compares sampling strategies (probabilistic, tail-based, adaptive) in terms of cost and diagnostic completeness.
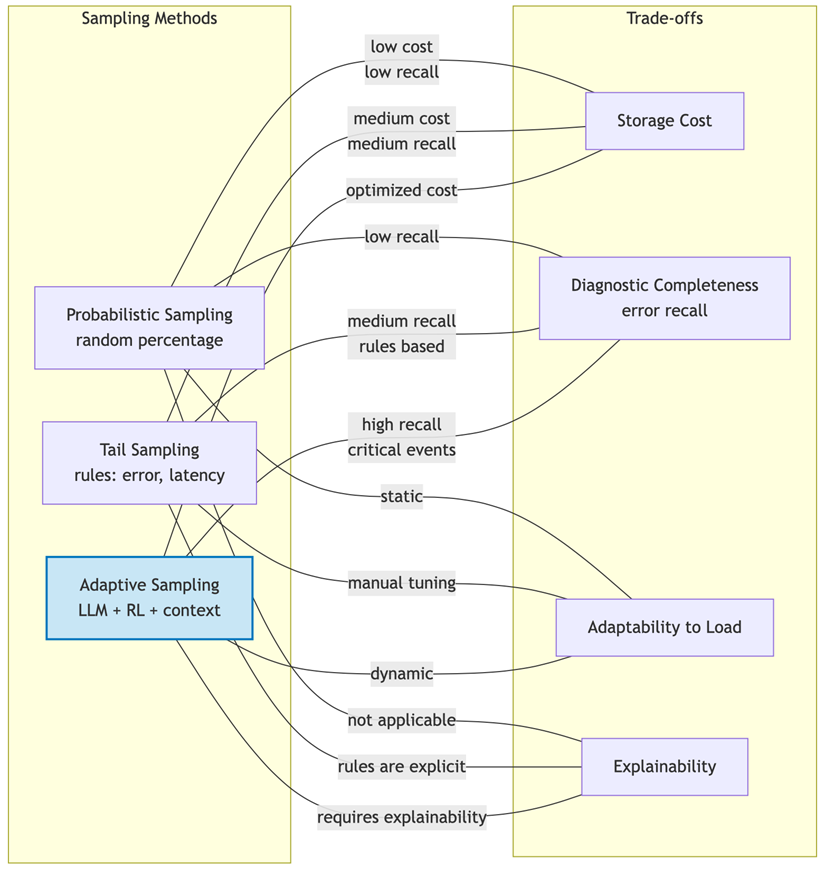
Fig. 2. Comparison of telemetry sampling methods
Performance Analysis
Table summarizes key performance results.
Table
Performance metrics of LLM-based observability approaches
Framework/Method | Task | Metric | Result |
TrioXpert [1, p. 1-12] | Anomaly Detection | Improvement | +4.7% to +57.7% |
TrioXpert [1, p. 1-12] | Failure Triage | Improvement | +2.1% to +40.6% |
TrioXpert [1, p. 1-12] | Root Cause Localization | Improvement | +1.6% to +163.1% |
GALA [4] | Top-1 RCA Accuracy | Improvement | +42.22% |
OTelBench [3] | OpenTelemetry Instrumentation | Pass rate | 29% |
LogBERT [6] | Log Anomaly Detection | Accuracy | High (qualitative) |
AIMA+ [7, p. 376-379] | Recovery Action Prediction | Macro F1 improvement | 0.2 → 0.6 |
Key Metrics Formulas
![]() , (1)
, (1)
![]() , (2)
, (2)
![]() , (3)
, (3)
Challenges and Future Directions
Current limitations include hallucination risks [1, p. 1-12; 3], context window constraints [1, p. 1-12], explainability gaps [4], cost pressures [2, 8], and real-time processing latency [3]. Future research should focus on:
- Hallucination-resistant architectures with validation loops [1, 1-12; 4];
- Efficient multimodal fusion preserving semantic information;
- Standardized evaluation frameworks (e.g., SURE-Score, OTelBench) [3, 4];
- Adaptive cost management and agentic AI for remediation [5, 8, 9].
Conclusion
This paper has examined the integration of Large Language Models into observability, analyzing recent frameworks and benchmarks. TrioXpert demonstrates substantial improvements in incident management through collaborative multi-LLM reasoning [1, p. 1-12]; GALA advances RCA accuracy via graph-augmented agentic workflows [4]; AgentTrace provides structured observability for LLM-powered agents [5]. However, OTelBench reveals that frontier LLMs achieve only a 29% pass rate on fundamental instrumentation tasks, indicating they are best positioned as intelligent co-pilots rather than autonomous decision-makers [3]. The bidirectional relationship between LLMs and observability will shape both domains, with future advances in hallucination suppression, multimodal fusion, and cost-aware architectures essential for reliable production deployment [8, 9].
