.png&w=384&q=75)
1. Введение
Современные фронтенд-приложения все чаще выполняют локальный анализ данных прямо в браузере: загружают файлы пользователя, парсят табличные форматы и немедленно визуализируют результат. Как только объем входных данных приближается к сотням мегабайт, синхронная обработка CSV в main thread начинает конкурировать с рендерингом, обработкой ввода и обновлением интерфейса. В результате пользователь наблюдает долгие блокировки, пропущенные кадры и рост latency даже в тех сценариях, где сама вычислительная задача детерминирована и хорошо распараллеливается.
Вклад работы
Разработано воспроизводимое фронтенд-приложение для сравнения трех способов локальной CSV-обработки; реализован скриптовый генератор детерминированных наборов данных без хранения огромных артефактов в репозитории; подготовлены сводные таблицы результатов, скриншоты интерфейса и PNG-иллюстрации, пригодные для непосредственного включения в публикацию.
2. Теоретическая основа
2.1. Web Workers и параллелизм JavaScript
Параллельное исполнение в браузере обычно строится вокруг Web Workers, однако выигрыш от распараллеливания зависит не только от количества вычислений, но и от реального поведения JavaScript VM, браузерного scheduler и межпоточного обмена сообщениями. Масштабирование worker-based приложений и выбор числа workers уже рассматривались в литературе [1, с. 105-108], а использование workers для распределения нагрузки в реальном времени показало практическую применимость подхода еще на ранних HTML5-сценариях [2, с. 381-395]. Более общие работы по параллельному JavaScript и data-parallel scheduling также подчеркивают, что выигрыш определяется гранулярностью задач и стоимостью координации [3, 4].
Для CPU-нагруженных фронтенд-сценариев недостаточно ограничиться абстрактным тезисом о вынесении всех вычислений из main thread. Автоматическое распараллеливание и offloading-подходы показывают, что полезный эффект появляется только при балансировке вычислительной части и коммуникационных накладных расходов [5, с. 461-477; 6, с. 170-185]. Поэтому в прикладном эксперименте важно сравнивать не только однопоточный и многопоточный варианты, но и разные способы доставки байтовых данных в workers.
2.2. Общая память и метрики отзывчивости
Отдельного внимания требует shared-memory режим. В более широком контексте browser-side offloading и распределения вычислений для web-приложений рассматриваются как схемы горизонтального offloading между устройствами, так и mobile-cloud подходы [7, с. 145-161; 8, с. 405-448; 9; 10]. В настоящей работе изучается более узкий, но практически востребованный сценарий, в котором все вычисления остаются внутри браузера пользователя, однако освобождают основной поток от CPU-нагруженного разбора CSV и позволяют контролировать длительные блокировки интерфейса.
3. Архитектура разработанного приложения
В рамках исследования разработано одностраничное React/Vite-приложение в темной минималистичной теме. Интерфейс показывает источник данных, число workers, текущий метод обработки, прогресс выполнения, итоговые агрегаты и сравнительную диаграмму по всем режимам. Вычислительные метрики фиксируются непосредственно внутри страницы с помощью performance.now(), PerformanceObserver и requestAnimationFrame, поэтому пользователь видит не только итоговое время обработки, но и влияние выбранного режима на плавность работы интерфейса.

Рис. 1. Интерфейс benchmark-приложения с выбором режима обработки, набора данных и таблицей итоговых результатов
3.1. Генерация входных данных
Входные данные генерируются отдельным скриптом generate-csv.mjs, который потоково записывает ASCII CSV-файлы в каталог public/datasets и рядом сохраняет manifest.json с точными размерами, числом строк и seed. В рамках статьи использовались три пресета: small (311401 строк, 24 МБ), medium (931537 строк, 72 МБ) и large (2565927 строк, 200 МБ). Каждая строка содержит идентификатор, временную метку, регион, сегмент, канал, несколько числовых полей и вычисляемые показатели, чтобы нагрузка была связана не только с операциями ввода-вывода, но и с реальными вычислениями на процессоре.
3.2. Три режима обработки
Режим main-thread выполняет fetch, decode, построчный split, нормализацию и агрегацию непосредственно в основном потоке интерфейса. Режим worker-pool-transfer разбивает входной буфер на 16 диапазонов байтов, выравнивает их по границам строк и передает соответствующие чанки в пул из 8 выделенных workers через transfer list. Режим worker-pool-shared предварительно формирует один SharedArrayBuffer, а workers получают только диапазоны и возвращают компактные частичные агрегаты. В отличие от распределенных offloading-моделей [7, с. 145-161; 8, с. 405-448; 9; 10], рассматриваемая архитектура сознательно ограничена одним браузерным контекстом и изолирует влияние локального worker pool без участия сети, edge-узлов или облачной инфраструктуры.

Рис. 2. Архитектура benchmark-приложения: скриптовая генерация данных, три вычислительных контура и единый слой агрегации результатов
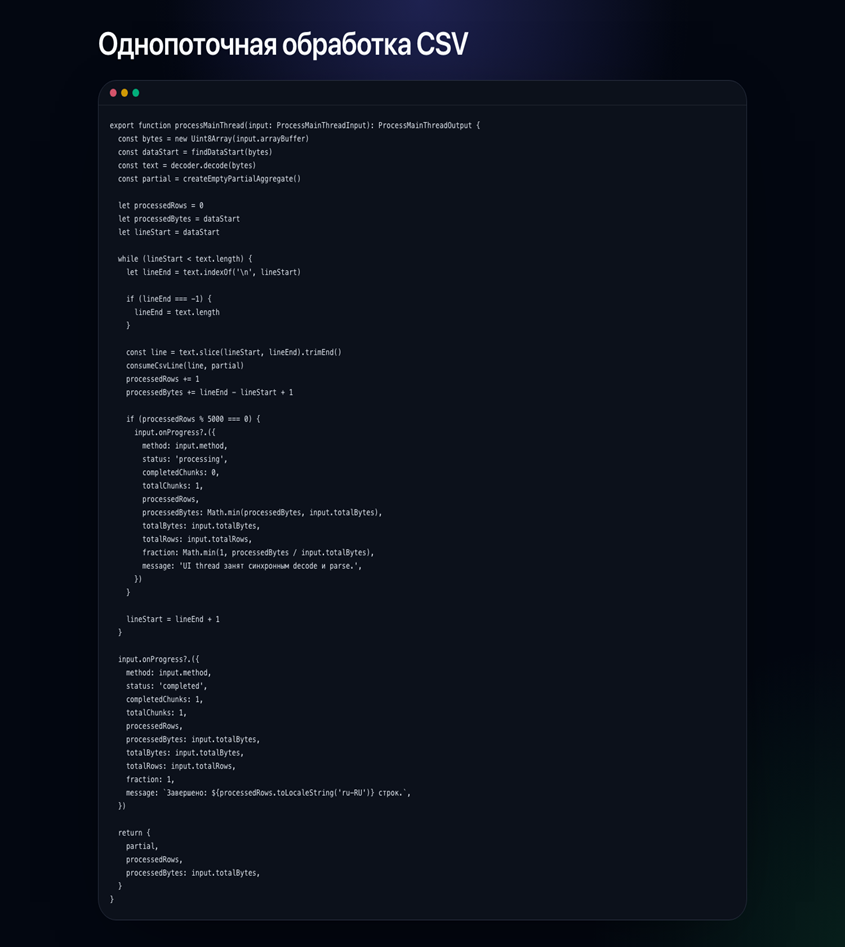
Рис. 3. Ключевой фрагмент однопоточного пути, в котором декодирование, построчный разбор, обновление прогресса и возврат агрегата выполняются в основном потоке интерфейса
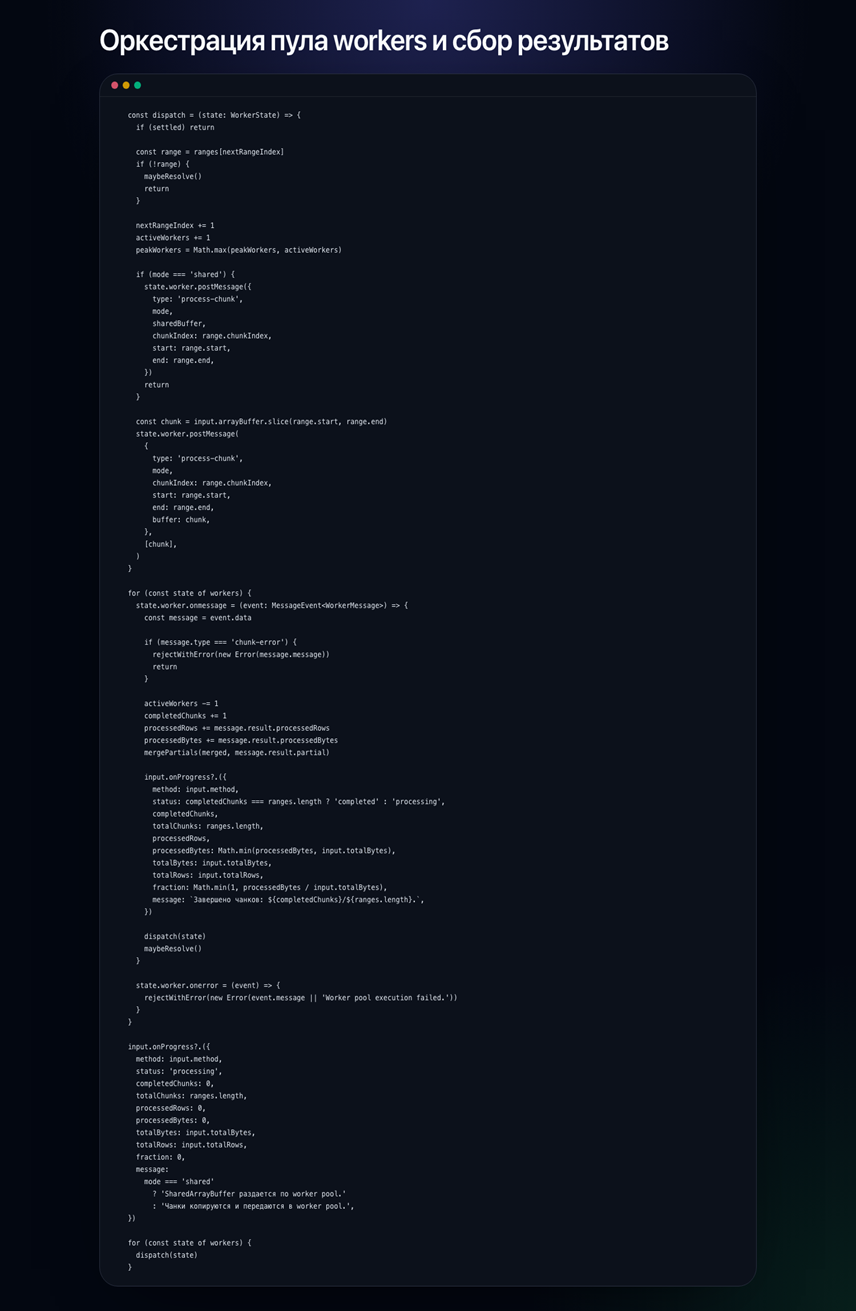
Рис. 4. Фрагмент оркестрации `worker pool`, в котором dispatch чанков, обработка сообщений workers и слияние частичных агрегатов выполняются в одном управляющем контуре
4. Методика эксперимента
Экспериментальная среда оставалась неизменной для всех прогонов. Для каждого сочетания набора данных и метода выполнялось по три повторения. Время обработки измерялось внутри страницы через performance.now(), а показатели плавности интерфейса фиксировались посредством requestAnimationFrame и PerformanceObserver. Такой дизайн позволяет сравнивать локальные стратегии worker-распараллеливания в контролируемых условиях и не смешивать их с эффектами сетевого offloading, которые характерны для более широких архитектур [7, с. 145-161; 8, с. 405-448].
Кроме totalParseMs фиксировались rowsPerSecond, mbPerSecond, avgFrameIntervalMs, longTaskCount50ms, longFrameCount50ms, число чанков и фактическое число занятых workers. Такой набор метрик позволяет одновременно оценить чистую вычислительную производительность и влияние выбранной архитектуры на доступность основного потока для рендеринга и реакции на ввод.
5. Результаты
Полученные результаты показывают устойчивый выигрыш от вынесения CPU-heavy CSV-обработки из main thread. На наборе medium worker pool с передачей чанков снизил среднее время с 610,2 мс до 181,3 мс, а режим с общей памятью – до 195,7 мс. На наборе large однопоточный режим потребовал 1849,6 мс, тогда как worker-pool-transfer и worker-pool-shared завершили обработку за 566,3 мс и 543,2 мс соответственно, что соответствует ускорению 3,27x и 3,40x по отношению к базовому варианту.
Таблица
Средние результаты эксперимента по трем наборам данных и трем режимам обработки
Набор данных | Метод | Время, мс | Ускорение | MB/s | Долгие задачи > 50 ms |
Малый (24 МБ) | main-thread | 233,4 | 1,00x | 104,1 | 1,0 |
Малый (24 МБ) | worker-pool-transfer | 109,5 | 2,13x | 257,2 | 0,0 |
Малый (24 МБ) | worker-pool-shared | 106,5 | 2,19x | 225,7 | 0,0 |
Средний (72 МБ) | main-thread | 610,2 | 1,00x | 118,0 | 1,0 |
Средний (72 МБ) | worker-pool-transfer | 181,3 | 3,37x | 397,6 | 0,0 |
Средний (72 МБ) | worker-pool-shared | 195,7 | 3,12x | 368,7 | 0,0 |
Крупный (200 МБ) | main-thread | 1849,6 | 1,00x | 109,4 | 1,0 |
Крупный (200 МБ) | worker-pool-transfer | 566,3 | 3,27x | 372,2 | 0,0 |
Крупный (200 МБ) | worker-pool-shared | 543,2 | 3,40x | 374,7 | 0,0 |
Примечание: во всех 27 прогонах контрольная сумма агрегатов оставалась одинаковой внутри каждого набора данных, что подтверждает эквивалентность вычислений при смене способа исполнения.
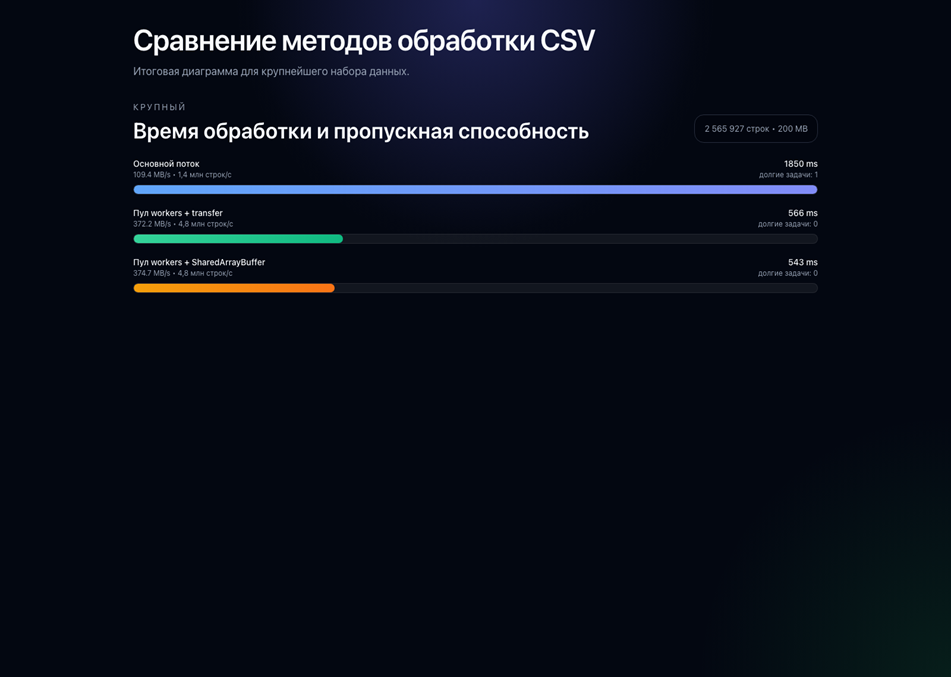
Рис. 5. Сравнение среднего времени обработки и пропускной способности для трех режимов исполнения на крупном наборе данных
Не менее важен эффект на отзывчивость интерфейса. Для набора large средний avgFrameIntervalMs в однопоточном режиме достигал 1850,5 мс, тогда как в worker-пулах он снизился до 38,4 мс и 29,4 мс. На наборе medium аналогичный показатель уменьшился с 616,7 мс до примерно 30 мс. Иными словами, даже если суммарное время вычислений у двух многопоточных режимов близко, перенос работы из основного потока интерфейса радикально уменьшает вероятность заметной «заморозки».
6. Обсуждение
Интересно, что worker-pool-shared не оказался безусловным лидером на всех наборах данных. На small и medium чуть быстрее работал worker-pool-transfer, тогда как на large преимущество перешло к режиму общей памяти. Причина состоит в том, что в данной реализации SharedArrayBuffer уменьшает накладные расходы на доставку чанков и координацию, но перед декодированием диапазон все равно преобразуется в локальное представление байтов для TextDecoder. Это означает, что режим общей памяти особенно полезен там, где размер входного буфера уже достаточен для доминирования накладных расходов на оркестрацию, но не отменяет необходимости аккуратно проектировать этап декодирования и размер чанков. В более широком прикладном контексте следующим шагом может стать сопоставление локального worker pool с межустройственным и mobile-cloud offloading, описанным в [7, с. 145-161; 8, с. 405-448; 9; 10].
7. Заключение
Для CPU-нагруженных фронтенд-сценариев, связанных с локальной обработкой больших CSV-файлов, выполнение вычислений в main thread оказывается архитектурно неоптимальным: пропускная способность ниже, долгие задачи появляются регулярно, а интерфейс перестает реагировать плавно. Переход к worker pool обеспечивает кратный выигрыш уже на десятках мегабайт, а использование общей памяти дает дополнительный эффект на самых крупных наборах. Построенный в работе воспроизводимый контур – генератор данных, встроенные средства замера, сводные таблицы результатов, скриншоты интерфейса и PNG-иллюстрации – позволяет повторять исследование в одинаковой постановке и использовать полученные артефакты непосредственно в научной публикации.
