.png&w=384&q=75)
Введение
Рекомендательные системы являются важным компонентом современных информационных сервисов, включая электронную коммерцию, мультимедийные платформы и социальные сети. Их основная задача заключается в предоставлении пользователям персонализированных рекомендаций на основе анализа различных источников данных, таких как история взаимодействий, характеристики объектов и контекстные параметры.
Развитие рекомендательных систем (РС) прошло путь от простых эвристик до сложных ансамблей моделей. Одной из ключевых проблем остается поиск «золотой середины» между использованием метаданных объектов и историей взаимодействий. Ранее исследованные методы автоматического переключения (Switching Hybrid) эффективно решают проблему «холодного старта», однако они обладают существенным недостатком – дискретностью принятия решения. В момент переключения система резко игнорирует один тип данных в пользу другого, что может приводить к потере точности в переходных состояниях профиля пользователя.
Целью данной работы является разработка метода динамического взвешивания разнородных признаков в гибридных рекомендательных системах, позволяющего адаптивно изменять вклад различных компонентов модели в зависимости от характеристик пользователя и объектов.
Объекты и методы исследования
Объектом исследования являются гибридные рекомендательные системы, использующие несколько источников данных для формирования рекомендаций.
Рассмотрим математическую модель гибридизации. Основная идея метода заключается в формировании итогового прогнозного рейтинга как линейной комбинации результатов двух независимых моделей:
![]() , (1)
, (1)
Где:
- PCB(u,i) – прогноз контентно-ориентированной модели (Content-Based);
- PCF(u,i) – прогноз модели коллаборативной фильтрации (Collaborative Filtering);
- ωc, ωf – весовые коэффициенты, причем ωc + ωf = 1.
Для извлечения признаков объектов используется модель векторного пространства. Каждый объект описывается вектором весов TF-IDF. Сходство между профилем пользователя pu (формируемым как среднее векторов объектов, которые ему понравились) и кандидатом qi рассчитывается через косинусное расстояние:
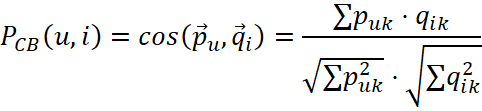 , (2)
, (2)
Это позволяет системе рекомендовать объекты, похожие по описанию на те, что пользователь выбирал ранее, даже если у этих объектов еще нет истории оценок.
В качестве второго компонента используется алгоритм матричной факторизации SVD++, который учитывает не только явные рейтинги, но и неявную обратную связь (просмотры без оценки). Модель раскладывает матрицу взаимодействий на матрицы скрытых факторов пользователей U и объектов V:
| (3) |
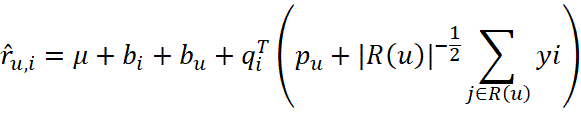
Здесь μ – общий средний рейтинг, bi и bu – смещения (bias) объекта и пользователя, yj – векторы неявных предпочтений, а R(u) – это набор объектов, с которыми пользователь взаимодействовал (смотрел, кликал, добавлял в корзину), но не обязательно ставил оценку.
Новизна предлагаемого подхода – алгоритма динамического взвешивания – заключается в расчете веса ωc на основе «информационной зрелости» профиля пользователя. Мы вводим функцию доверия к коллаборативному методу f(Nu), зависящую от количества оценок пользователя Nu:
![]() , (4)
, (4)
Где N0 – точка перегиба (например, 20 оценок), а k – коэффициент крутизны перехода. Таким образом, для новых пользователей доминирует контентный подход (![]() ), а по мере накопления данных система плавно переходит к коллаборативному анализу, не отключая контентную составляющую полностью.
), а по мере накопления данных система плавно переходит к коллаборативному анализу, не отключая контентную составляющую полностью.
Результаты и их обсуждение
Для проведения экспериментальной оценки был использован набор данных MovieLens 100k, содержащий 100 000 оценок от 943 пользователей по 1682 фильмам. Плотность матрицы взаимодействий составила приблизительно 6.3%, что является репрезентативным показателем для исследования проблемы разреженности данных. Данные были разделены на обучающую (80%) и тестовую (20%) выборки.
Для измерения точности предсказания вещественного рейтинга использовалась метрика MAE (Mean Absolute Error):
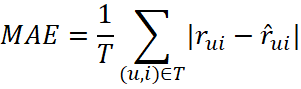 , (5)
, (5)
Для оценки качества ранжирования (топ-N рекомендаций) – метрика nDCG:
![]() , (6)
, (6)
В таблице представлены сравнительные характеристики разработанной взвешенной модели и базовых подходов.
Таблица
Результаты тестирования моделей
Метод | MAE (общий) | MAE (холодный старт) | nDCG |
Контентная модель (TF-IDF) | 0.812 | 0.825 | 0.612 |
Коллаборативная фильтрация (SVD) | 0.745 | 1.210 | 0.695 |
Метод переключения (Switching Hybrid) | 0.712 | 0.854 | 0.738 |
Предлагаемая взвешенная модель | 0.684 | 0.821 | 0.782 |
Результаты экспериментального тестирования (табл) демонстрируют превосходство предлагаемой взвешенной модели над классическими и комбинированными подходами по всем ключевым метрикам:
- Минимизация ошибки (MAE): Разработанная модель показала самый низкий уровень ошибки (0.684), что на 3.9% точнее метода переключения и на 8.2% точнее чистой коллаборативной фильтрации. Это говорит о высокой точности предсказания конкретных оценок пользователей.
- Решение проблемы «холодного старта»: В условиях дефицита данных о пользователях предлагаемый метод (MAE 0.821) работает стабильнее всех. Он не только исправляет критический провал SVD-алгоритма (1.210), но и оказывается эффективнее метода переключения, обеспечивая более плавную адаптацию к профилю пользователя.
- Качество ранжирования (nDCG): Рост метрики до 0.782 свидетельствует о том, что система стала значительно лучше распределять объекты в списке рекомендаций, поднимая наиболее релевантные позиции вверх.
Переход от жесткого переключения к динамическому взвешиванию позволил объединить сильные стороны контентного и коллаборативного анализов, обеспечив стабильно высокое качество рекомендаций как для новых, так и для активных пользователей.
Заключение
В данной статье представлен и исследован метод взвешенной гибридизации в рекомендательных системах. Основным научным результатом является разработка механизма динамической адаптации весов, который обеспечивает плавный переход от контентного анализа к учету коллективного опыта. Полученные данные подтверждают, что такая архитектура более устойчива к изменениям объема пользовательских данных и обеспечивает более качественное ранжирование в условиях разреженных матриц.
Дальнейшие исследования будут направлены на внедрение в модель механизмов глубокого обучения (Deep Hybrid Models) для автоматического извлечения признаков из неструктурированных данных.
