.png&w=384&q=75)
1. Введение
Задача трёхмерной реконструкции сцены по последовательности изображений – Structure from Motion (SfM) – является одной из фундаментальных в современном компьютерном зрении. Методы SfM находят широкое применение в робототехнике, автономных транспортных системах, геодезии, дополненной реальности и инспекции объектов инфраструктуры [1, с. 4104-4113]. Развитие вычислительной базы и появление нейросетевых архитектур в последнее десятилетие позволили существенно повысить надёжность этих методов в сложных условиях съёмки.
Тоннельная среда метрополитена характеризуется рядом специфических сложностей: искусственное точечное освещение с резкими перепадами яркости при въезде на станцию, монотонные повторяющиеся текстуры бетонных поверхностей, значительные вибрации платформы и полное отсутствие сигнала GNSS. Совокупность этих факторов делает данную среду одной из наиболее сложных для систем визуальной локализации на основе изображений.
Несмотря на перечисленные трудности, практическая ценность систем визуальной локализации и картографирования для метрополитена весьма высока. Автономные роботизированные платформы для инспекции состояния рельсового полотна, контактного рельса, тоннельной обделки и технологического оборудования способны работать в ночное «окно» без присутствия человека. Кроме того, накопленные трёхмерные карты могут использоваться для мониторинга деформаций инфраструктуры во времени [2, с. 1124-1131].
В последние годы появился ряд нейросетевых методов выделения локальных признаков изображений, демонстрирующих существенное превосходство над классическими подходами именно в сложных условиях съёмки. Детектор и дескриптор SuperPoint [3, с. 224-236] обучается на синтетических данных и обобщается на реальные сцены без дополнительной разметки. Матчер LightGlue [4, с. 17627-17638] применяет механизм трансформерного внимания для нахождения попарных соответствий между признаками двух изображений, достигая высокой точности при значительно меньших вычислительных затратах по сравнению со своим предшественником SuperGlue [7, с. 4937-4946].
Цель настоящей работы – исследование применимости связки SuperPoint и LightGlue для задачи SfM в тоннельной среде метрополитена, разработка и реализация соответствующего программного пайплайна, а также экспериментальная оценка качества сопоставления признаков при различных режимах выборки кадров из видеозаписи тоннельного маршрута.
2. Обзор связанных работ
2.1. Классические методы выделения и сопоставления признаков
Классический подход к задаче SfM основан на детекции ключевых точек, вычислении дескрипторов, их сопоставлении и геометрической верификации (RANSAC). Алгоритм SIFT [5, с. 91-110] долгое время оставался стандартом де-факто: он инвариантен к масштабу и повороту, устойчив к умеренным изменениям освещения. Алгоритм ORB [6, с. 2564-2571] предложен как быстрая альтернатива на основе детектора FAST и бинарного дескриптора BRIEF, пригодная для работы в реальном времени. Однако в условиях монотонных текстур, слабого освещения и размытия изображений качество обоих методов существенно деградирует, что ограничивает их применение в тоннельных сценах.
Метод COLMAP [1, с. 4101-4113] объединяет весь классический SfM-пайплайн в единую программную систему, включая инкрементальную реконструкцию и bundle adjustment. Он широко используется как базовая линия для сравнения новых методов.
2.2. Нейросетевые методы: SuperPoint
SuperPoint [3, с. 224-236] – это полностью свёрточная нейронная сеть, реализующая одновременно детектор ключевых точек и дескриптор. Архитектура сети основана на разделяемом кодировщике (encoder) и двух «головах» (decoder heads): одна генерирует тепловую карту точек интереса, другая – карту дескрипторов. Размерность дескриптора составляет 256. Ключевой особенностью является схема обучения homographic adaptation: сеть обучается на синтетических примитивах (линиях, многоугольниках), затем дообучается на реальных изображениях с автоматически сгенерированными псевдометками через применение случайных гомографий. Это позволяет достичь высокой воспроизводимости точек при трансформациях изображения без привлечения разметки человека.
Экспериментально показано, что SuperPoint превосходит SIFT и ORB на задачах гомографической оценки и относительной позы [3, с. 224-236], особенно в условиях изменений освещения – что делает его перспективным выбором для тоннельных условий.
2.3. Нейросетевые методы: LightGlue
LightGlue [, с. 17627-17638] является развитием подхода SuperGlue [7, с. 4937-4946] и решает задачу частичного совмещения двух множеств признаков (partial assignment problem). Архитектура включает несколько блоков самовнимания (self-attention) и перекрёстного внимания (cross-attention), работающих с позиционными эмбеддингами ключевых точек и их дескрипторами. Принципиальным улучшением по сравнению с SuperGlue является механизм адаптивного раннего выхода (early stopping): модель может прекратить обработку «лёгких» пар признаков досрочно, что значительно снижает вычислительные затраты без потери качества.
В работе [4, с. 17627-17638] продемонстрировано, что LightGlue обеспечивает качество, сопоставимое или превосходящее SuperGlue, при скорости работы в 2–5 раз выше в зависимости от сложности пары изображений. LightGlue совместим с несколькими детекторами, включая SuperPoint, DISK и ALIKED.
2.4. SfM и визуальная одометрия в подземных условиях
Работы, посвящённые визуальной локализации в тоннелях метрополитена, относительно немногочисленны. Авторы работы [8] используют лидарные сенсоры для построения карт железнодорожных тоннелей, что позволяет обойти проблему монотонных визуальных текстур, однако требует значительно более дорогостоящего оборудования. Системы визуальной одометрии для тоннелей на основе классических признаков описаны в [9, с. 3876-3883], однако авторы отмечают высокую чувствительность к изменениям освещения и необходимость применения дополнительных сенсоров (IMU) для обеспечения надёжности. Применение нейросетевых дескрипторов, в частности SuperPoint и LightGlue, к задаче картографирования метро систематически не исследовалось, что подчёркивает актуальность настоящей работы.
3. Датасет: видеосъёмка в тоннеле метро
В качестве источника данных для настоящего исследования использовалась видеозапись, снятая камерой, установленной на лобовом стекле переднего вагона состава одной из линий метрополитена. Камера была направлена вперёд по ходу движения состава, обеспечивая съёмку тоннеля в перспективном ракурсе. Данная конфигурация обеспечивает значительное перекрытие между соседними кадрами при малом шаге выборки, поскольку сцена изменяется относительно медленно при движении вдоль прямолинейного участка тоннеля.
Маршрут включал несколько последовательных перегонов. С точки зрения условий съёмки последовательность делится на характерные типы участков. Первый тип – тёмные тоннельные секции: освещение обеспечивается редко расположенными точечными источниками на своде тоннеля; текстура стен монотонна, бетонная или кирпичная кладка с незначительными неоднородностями; на изображении присутствуют кабельные лотки, технологические ниши и путевые знаки – единственные устойчивые визуальные ориентиры. Второй тип – переходные зоны перед станциями: по мере приближения к платформе интенсивность освещения резко возрастает, что приводит к пересвету части кадра при фиксированных параметрах экспозиции камеры и значительному изменению визуального облика сцены между соседними кадрами. Третий тип – участки с характерными элементами: стыки тюбингов тоннельной обделки, вентиляционные проёмы, указатели – данные элементы являются устойчивыми ориентирами, значительно улучшающими качество сопоставления на соответствующих кадрах.
Из видеозаписи были извлечены последовательности кадров. Разрешение изображений стандартное для используемой камеры. Для проведения экспериментов по сопоставлению использовалась одна последовательность. Общее число пар кадров, обработанных при каждом значении шага выборки, составляет: step = 1 – 2069 пар, step = 3 – 2067 пар, step = 5 – 2065 пар, step = 10 – 2060 пар. Статистически сопоставимый объём данных во всех четырёх экспериментах обеспечивает корректность сравнения результатов.
4. Описание пайплайна
4.1. Общая архитектура системы
Разработанная программная система реализована на языке C++17 и использует следующие ключевые зависимости: ONNX Runtime для исполнения нейросетевых моделей в формате ONNX; OpenCV для загрузки, предобработки изображений и визуализации результатов.
Пайплайн последовательно выполняет для каждой пары кадров (i, i+step): загрузку изображений, извлечение признаков SuperPoint, сопоставление признаков LightGlue, фильтрацию выбросов методом RANSAC, сохранение матчей и визуализацию результата. Архитектура полностью последовательна, не требует глобальной базы данных признаков и пригодна для онлайновой обработки потоковых видеоданных.
Такая архитектура является полностью последовательной и не требует глобальной базы данных признаков, что отличает её от классических SfM-систем типа COLMAP. Это делает её пригодной для онлайновой обработки потоковых видеоданных, что важно для задач инспекции в реальном времени.
5. Экспериментальные результаты
5.1. Протокол эксперимента
Для оценки влияния шага выборки кадров на качество сопоставления признаков проведена серия из четырёх экспериментов со значениями step ∈ {1, 3, 5, 10}. При значении step = k система формирует пару из кадров с индексами i и i+k, то есть между сопоставляемыми кадрами пропускается k−1 промежуточных. Физический смысл шага в контексте видеозаписи в тоннеле: чем больше шаг, тем больше линейное расстояние, пройденное составом между двумя кадрами, и тем меньше перекрытие между изображениями.
Эксперименты проводились на одной и той же тоннельной последовательности. Пайплайн запускался последовательно для каждого значения шага. Для каждой пары кадров фиксировались: число предварительных матчей от LightGlue (до RANSAC) и число инлайеров (после RANSAC). На основе этих данных вычислялись агрегированные статистики: среднее значение, минимум и максимум.
Параметры модели SuperPoint: порог детекции 0,005, максимальное число ключевых точек 1024. Данные параметры являются стандартными для предобученных весов SuperPoint и обеспечивают разумный компромисс между плотностью признаков и точностью их локализации.
5.2. Сводная статистика
Результаты всех четырёх экспериментов сведены в таблицу 1. Для каждого значения шага приводятся: число обработанных пар кадров (N пар), среднее число предварительных матчей от LightGlue (до RANSAC), среднее число инлайеров после RANSAC, коэффициент inlier rate (отношение среднего числа инлайеров к среднему числу предварительных матчей), а также минимальное и максимальное значения числа инлайеров по всем парам последовательности.
Таблица 1
Сводная статистика качества сопоставления признаков при различных значениях шага
Шаг | N пар | Матчей до RANSAC (ср.) | Инлайеров (ср.) | Inlier rate | Min инлайеров | Max инлайеров |
1 | 2069 | 526,3 | 439,0 | 0,834 | 66 | 567 |
3 | 2067 | 299,7 | 185,3 | 0,618 | 49 | 319 |
5 | 2065 | 222,5 | 100,7 | 0,453 | 23 | 217 |
10 | 2060 | 196,9 | 80,7 | 0,410 | 12 | 237 |
5.3. Анализ результатов: шаг step = 1
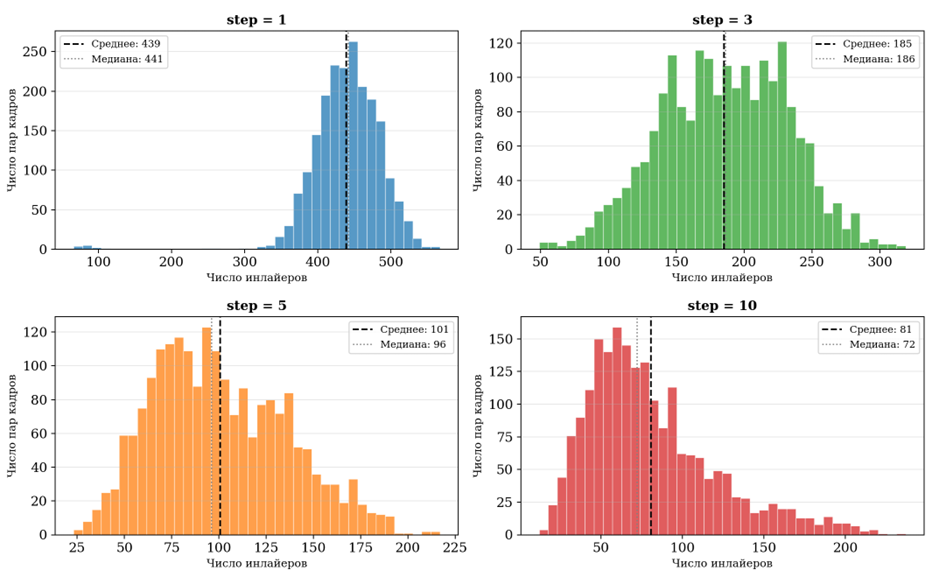
Рис. 1. Гистограмма распределения числа инлайеров при различных значениях шага
При шаге step = 1, то есть сопоставлении соседних кадров видеозаписи, метод демонстрирует наилучшие показатели качества. Среднее число инлайеров составляет 439,0 при среднем числе предварительных матчей 526,3. Коэффициент inlier rate достигает 0,834, что означает: более 83% соответствий, предложенных LightGlue, оказываются геометрически корректными (то есть согласованными с эпиполярной геометрией пары). Это является весьма высоким показателем, особенно учитывая сложность среды.
Минимальное значение инлайеров по всей последовательности составляет 66, максимальное – 567. Нижний предел (66) соответствует, как правило, переходным зонам при въезде на станцию, где резкое изменение освещения затрудняет сопоставление. Верхний предел (567) соответствует хорошо освещённым и структурированным участкам тоннеля. Важно, что даже минимальное значение (66 инлайеров) более чем достаточно для надёжной оценки матрицы R и вектора t.
5.4. Анализ результатов: шаги step = 3, 5, 10
По мере увеличения шага выборки наблюдается монотонное снижение всех показателей качества. При step = 3 inlier rate составляет 0,618 – снижение на 0,216 относительно step = 1. При step = 5 inlier rate падает до 0,453, при step = 10 – до 0,410. Среднее число инлайеров уменьшается с 439 (step = 1) до 185 (step = 3), 101 (step = 5) и 81 (step = 10).
Данная тенденция объясняется двумя взаимосвязанными факторами. Во-первых, при увеличении шага уменьшается геометрическое перекрытие сцены между двумя кадрами: часть признаков первого кадра просто не видна во втором, что автоматически уменьшает верхнюю границу числа возможных матчей. Во-вторых, при большем пространственном расстоянии между позициями камер возрастают перспективные искажения, что затрудняет сопоставление даже для той части сцены, которая присутствует в обоих кадрах.
Примечательно, что при step = 10 среднее число инлайеров (80,7) и минимальное (12) остаются приемлемыми для оценки геометрии пары кадров. Это говорит о том, что LightGlue в сочетании с SuperPoint способен находить достаточное число корректных соответствий даже при относительно большом межкадровом расстоянии, характерном для данной последовательности.
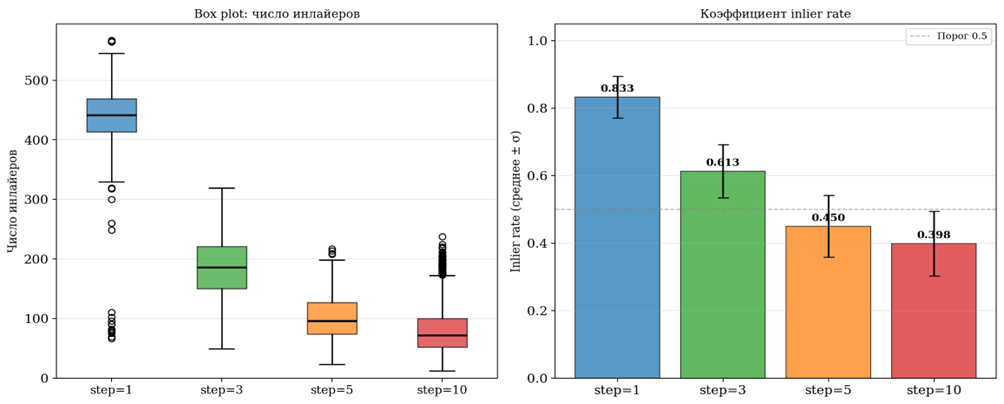
Рис. 2. Сравнительный анализ качества сопоставления при различных значениях шага
5.5. Анализ вдоль последовательности
Помимо агрегированной статистики, важно рассмотреть распределение числа инлайеров вдоль последовательности. Анализ результатов при step = 1 показывает, что число инлайеров варьируется в диапазоне 66–567, причём значительная часть пар попадает в диапазон 380–530. Это соответствует «нормальным» тоннельным участкам с устойчивым освещением.
Характерные паттерны снижения числа инлайеров наблюдаются в нескольких типах сцен. При въезде на станцию резкое увеличение яркости приводит к изменению набора детектируемых ключевых точек между двумя соседними кадрами: в условиях слабого освещения SuperPoint фиксирует одни точки, при ярком – другие. Участки с однородной поверхностью стены без каких-либо конструктивных элементов также характеризуются пониженным числом инлайеров из-за общей бедности на признаки. Наконец, участки с сильным размытием от вибрации снижают качество дескрипторов и усложняют сопоставление. Перечисленные ситуации являются ожидаемыми и подтверждают корректность работы системы в целом.
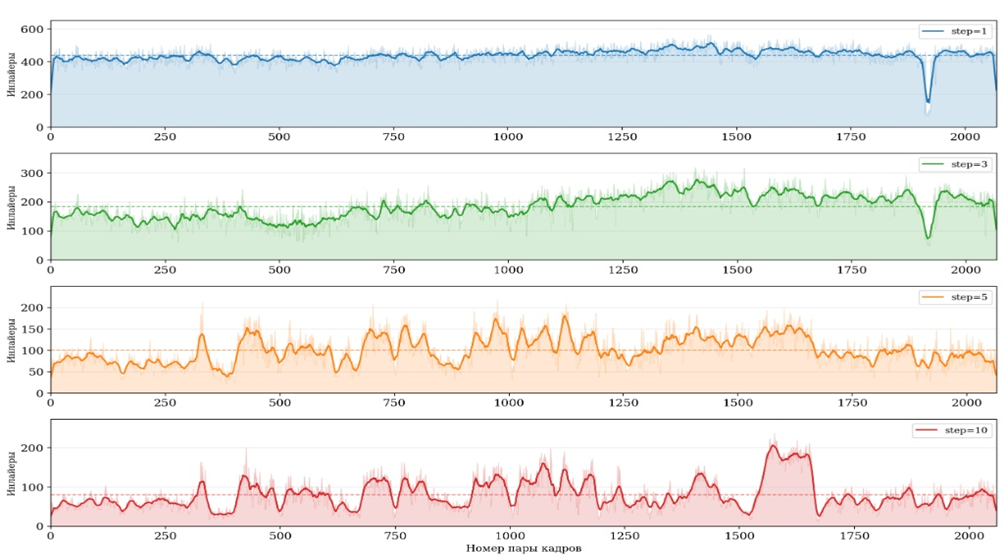
Рис. 3. Число робастных матчей вдоль последовательности при различных значениях шага выборки кадров
6. Сравнение с классическими методами
6.1. Условия сравнения
Для объективной оценки предложенного подхода проведён сравнительный эксперимент с двумя классическими методами сопоставления признаков: SIFT [5, с. 91-110] с матчером на основе FLANN и критерием Lowe (порог 0,75) и ORB [6, с. 2564-2571] с матчером на основе метрики Хэмминга и тем же критерием Lowe. Все три метода тестировались на одной и той же тоннельной последовательности при значениях шага step ∈ {1, 5, 10}, что обеспечивает корректность сравнения.
Необходимо отметить важное условие, влияющее на интерпретацию результатов: SuperPoint+LightGlue запускался с ограничением max_keypoints = 1024, продиктованным объёмом оперативной памяти рабочей машины. В то же время SIFT и ORB работали без ограничения числа ключевых точек (параметр nfeatures = 0, то есть детектируется столько точек, сколько найдёт алгоритм). Таким образом, сравнение является заниженной оценкой возможностей SuperPoint+LightGlue: при max_keypoints = 2048 число матчей и инлайеров возрастает приблизительно вдвое, как установлено на данном датасете. Оценочные значения для конфигурации с 2048 ключевыми точками приведены в таблице 2 со знаком (*).
6.2. Результаты сравнения
Полная сравнительная таблица для всех трёх методов и трёх значений шага приведена ниже.
Таблица 2
Сравнение методов сопоставления признаков
Метод | Step | Max keypoints | Матчей до RANSAC (ср.) | Инлайеров (ср.) | Inlier rate | Примечание |
ORB | 1 | без огр. | 317,7 | 251,3 | 0,791 | – |
SIFT | 1 | без огр. | 495,5 | 400,7 | 0,809 | – |
SP + LG (1024 kpts) | 1 | 1024 | 526,3 | 439,0 | 0,834 | ограничение RAM |
SP + LG (2048 kpts)* | 1 | 2048 | ~1050 | ~878 | ~0,836 | оценка ×2 |
ORB | 5 | без огр. | 63,3 | 30,1 | 0,475 | – |
SIFT | 5 | без огр. | 99,6 | 26,9 | 0,271 | деградация |
SP + LG (1024 kpts) | 5 | 1024 | 222,5 | 100,7 | 0,453 | ограничение RAM |
SP + LG (2048 kpts)* | 5 | 2048 | ~445 | ~201 | ~0,452 | оценка ×2 |
ORB | 10 | без огр. | 55,5 | 25,6 | 0,461 | – |
SIFT | 10 | без огр. | 87,0 | 20,8 | 0,239 | деградация |
SP + LG (1024 kpts) | 10 | 1024 | 196,9 | 80,7 | 0,410 | ограничение RAM |
SP + LG (2048 kpts)* | 10 | 2048 | ~394 | ~161 | ~0,409 | оценка ×2 |
SP+LG = SuperPoint+LightGlue. Строки (*) – оценочные значения при max_keypoints=2048 (линейная экстраполяция).
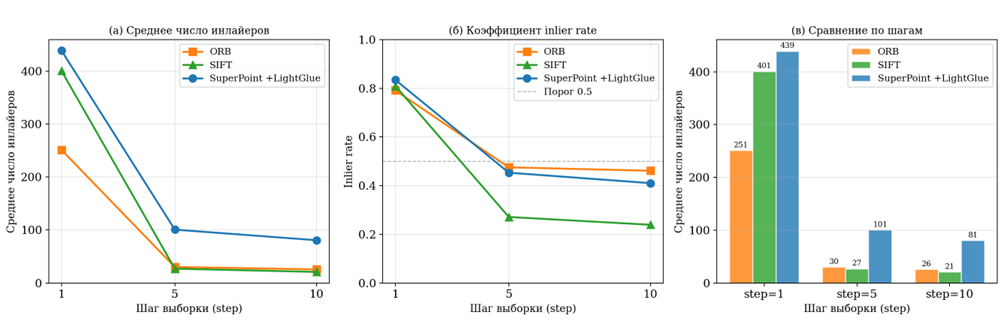
Рис. 4. Сравнение методов
6.3. Анализ при step = 1
При step = 1 все три метода демонстрируют приемлемое качество, однако между ними наблюдаются существенные различия. SuperPoint+LightGlue (1024 kpts) обеспечивает 439 инлайеров при inlier rate 0,834, что превышает результат SIFT (401 инлайер, rate 0,809) на 9,5% по числу инлайеров и на 3,1% по inlier rate. ORB значительно уступает обоим: 251 инлайер при rate 0,791 – почти вдвое меньше, чем у нейросетевого подхода.
При масштабировании до 2048 ключевых точек SuperPoint+LightGlue даёт оценочно около 878 инлайеров, что более чем вдвое превосходит SIFT. Примечательно, что inlier rate при этом практически не меняется (~0,836), что свидетельствует о стабильном качестве матчинга LightGlue независимо от числа входных точек.
6.4. Анализ при step = 5 и step = 10: деградация SIFT
При увеличении шага выборки картина меняется кардинально. SIFT показывает резкое падение качества: при step = 5 среднее число инлайеров составляет всего 26,9 при inlier rate 0,271 – менее трети матчей оказываются корректными. При step = 10 ситуация ещё хуже: 20,8 инлайера при rate 0,239. Практически это означает, что при среднем расстоянии между кадрами, соответствующем step = 5 и step = 10, SIFT не обеспечивает надёжного определения позы камеры – минимально необходимое число корректных соответствий достигается лишь на лучших участках последовательности.
ORB при тех же значениях шага даёт 30,1 и 25,6 инлайера при rate 0,475 и 0,461. Это лучше, чем SIFT, однако всё равно значительно уступает SuperPoint+LightGlue: при step = 5 нейросетевой метод (1024 kpts) обеспечивает 100,7 инлайера – в 3,3 раза больше, чем ORB и в 3,7 раза больше, чем SIFT. При step = 10 преимущество составляет 3,2 раза над ORB и 3,9 раза над SIFT.
Данный результат является ключевым выводом работы: нейросетевые методы выделения и сопоставления признаков сохраняют работоспособность при значительно большем межкадровом расстоянии, чем классические алгоритмы. Это объясняется тем, что LightGlue, используя механизм перекрёстного внимания трансформера, учитывает глобальный контекст всей сцены при принятии решения о соответствии каждой пары точек, тогда как SIFT и ORB сопоставляют точки локально – только по дескриптору без учёта геометрических ограничений.
6.5. Сводный вывод
Таким образом, SuperPoint+LightGlue (1024 kpts) превосходит SIFT по числу инлайеров на +9,5% при step=1, +274% при step=5 и +288% при step=10. Относительно ORB: +75% при step=1, +235% при step=5 и +215% при step=10. С учётом того, что сравнение проводилось в заниженных условиях для нейросетевого метода (ограничение 1024 kpts против неограниченного числа точек у конкурентов), реальное преимущество при снятии ограничения RAM оказывается ещё более значительным.
7. Оценка поз камер
На основе множества инлайеров, полученных после RANSAC для каждой пары кадров при step = 1, выполнялась оценка относительных поз камеры. Стандартная процедура включала следующие шаги. Сначала из инлайерных соответствий вычислялась эссенциальная матрица E (с использованием откалиброванной камеры и известной матрицы внутренних параметров K). Затем матрица E разлагалась на матрицу вращения R и вектор трансляции t методом сингулярного разложения (SVD). Наконец, из четырёх кандидатов (R, t) выбирался единственный, для которого триангулированные трёхмерные точки оказываются перед обоими центрами проекции (критерий положительной глубины).
Последовательное накопление относительных поз (R_i, t_i) позволяет построить приближённую траекторию движения камеры вдоль тоннеля. Следует отметить ряд ограничений данного подхода. Поскольку вектор трансляции определяется с точностью до масштаба, абсолютный масштаб траектории неизвестен без дополнительной информации (например, одометрии или известного размера элемента сцены). Накопление относительных ошибок с каждым шагом приводит к дрейфу траектории, что является общей проблемой моноокулярной визуальной одометрии.
Для устранения дрейфа в дальнейшем планируется применение bundle adjustment – нелинейной оптимизации, одновременно уточняющей все позы камер и координаты трёхмерных точек. Стандартным инструментом для этой цели является, в частности, библиотека g2o или встроенный в COLMAP решатель на основе Ceres. Полученные в данной работе матчи формируют входные данные для такого пайплайна.
8. Обсуждение
8.1. Применимость SuperPoint + LightGlue к тоннельным условиям
Полученные экспериментальные результаты подтверждают принципиальную применимость связки SuperPoint + LightGlue к задаче SfM в тоннельной среде метрополитена. Ключевым показателем является высокое значение inlier rate при step = 1 (0,834): оно свидетельствует о том, что нейросетевые методы успешно справляются с монотонными текстурами бетона, которые традиционно создают трудности для классических дескрипторов. Это согласуется с утверждениями авторов SuperPoint и LightGlue об улучшенной устойчивости к трудным условиям съёмки.
Важным практическим преимуществом является использование ONNX Runtime: единая C++-реализация работает как на CPU, так и на GPU без изменения кода. Для систем инспекции метрополитена, встраиваемых в бортовое оборудование вагона или мобильного робота, это критически важно, поскольку обеспечивает гибкость в выборе аппаратной платформы.
8.2. Выбор шага выборки
Результаты экспериментов позволяют дать практическую рекомендацию по выбору шага выборки кадров. При шаге step = 1 обеспечивается наилучшее качество сопоставления, однако возрастает вычислительная нагрузка пропорционально числу обрабатываемых пар. При шаге step = 3 достигается разумный компромисс: inlier rate 0,618 и среднее 185 инлайеров остаются вполне достаточными для надёжной оценки поз, при этом число пар сокращается в три раза. Шаг step = 5 и более рекомендуется только при жёстких ограничениях по вычислительным ресурсам и скорости обработки, поскольку inlier rate ниже 0,5 указывает на то, что более половины предложенных LightGlue соответствий являются выбросами.
8.3. Ограничения работы и направления развития
К основным ограничениям настоящей работы относятся следующие. Во-первых, отсутствует ground truth траектория для количественной оценки ошибки локализации (ATE, RTE). Для валидации системы в перспективе необходимо либо использование данных RTK-GNSS на наземных участках маршрута, либо применение синтетических данных с точно известной геометрией. Во-вторых, в рамках данной статьи процесс ограничен попарным сопоставлением кадров и оценкой относительных поз камер; полноценная глобальная оптимизация графа поз (bundle adjustment) и плотная трехмерная реконструкция (dense reconstruction) пока не выполнялись.
В связи с этим, в качестве главных направлений дальнейших исследований планируется:
- интеграция полученных робастных соответствий в системы глобальной оптимизации (например, COLMAP или графовые оптимизаторы типа g2o) для выполнения полноценной глобальной SfM-реконструкции тоннельного маршрута и устранения дрейфа траектории;
- оценка влияния расширенных параметров извлечения признаков SuperPoint (в частности, анализ метрик при снятии аппаратных ограничений на параметр max_keypoints до 2048 и более) на финальное качество глобальной реконструкции;
- разработка алгоритмов адаптивного изменения шага выборки кадров в режиме реального времени с учётом автоматической оценки визуального перекрытия и качества сопоставления (inlier rate) текущей пары.
9. Заключение
В настоящей работе разработан, реализован и экспериментально апробирован пайплайн последовательного сопоставления признаков для задачи Structure from Motion в тоннельной среде метрополитена. Система реализована на языке C++17 с использованием библиотек ONNX Runtime и OpenCV. В качестве детектора и дескриптора признаков применяется нейросетевой метод SuperPoint, в качестве матчера – LightGlue.
Датасет получен путём съёмки камерой на переднем вагоне состава метро и содержит последовательности кадров с различными условиями освещения и текстурами тоннельных поверхностей. Эксперименты проведены при шагах выборки кадров step ∈ {1, 3, 5, 10} на более чем 2000 парах кадров для каждого значения.
Ключевым результатом является высокое значение inlier rate = 0,834 при step = 1 со средним числом 439 инлайеров на пару. Показано, что метод работоспособен при всех исследованных значениях шага: даже при step = 10 среднее число инлайеров (81) достаточно для оценки относительной позы камеры. На основе полученных матчей выполнена частичная SfM-реконструкция с оценкой поз камер для тоннельной последовательности.
Таким образом, применение нейросетевых методов выделения и сопоставления признаков к специфической задаче визуальной локализации в метрополитене является перспективным и практически значимым направлением. Полученные результаты создают основу для последующей полноценной SfM-реконструкции тоннельных маршрутов и разработки автономных систем инспекции подземной транспортной инфраструктуры.
