.png&w=384&q=75)
Introduction
Generative artificial intelligence (GenAI) is rapidly penetrating all major stages of software creation, from code generation and test automation to requirements management and documentation. According to McKinsey, 71% of organizations now regularly use GenAI in at least one business function, whereas in 2023 this figure stood at only 33% [1]. Approximately 25% of all code produced within Google is already generated by AI systems, while developers who use GitHub Copilot on a systematic basis increase their coding output by 12–15% [2]. The total volume of private investment in GenAI reached $25.2 billion, while the AI security market is projected to attain $60.24 billion by 2029 [5].
Yet the acceleration of development carries a substantial security burden. According to Dark Reading analysis, at least 48% of code snippets generated by five popular models contained vulnerabilities [3, 19]. Gartner predicts that by 2027, more than 40% of AI-related data breaches will be caused by the improper use of generative AI across borders [4, 20]. Lakera AI further indicates that, by 2025, the continued expansion of generative AI adoption will increase spending on application and data protection by more than 15% [5]. In that sense, the intensified use of GenAI tools in software development is creating a fundamentally new risk configuration, one that calls for a serious reconsideration of established secure development paradigms.
Against the backdrop of the intensive practical use of LLMs in software engineering, a notable scholarly gap has emerged within both academic and professional communities: existing security assurance methodologies, including the classic DevSecOps model, the OWASP Top 10, and the NIST Secure Software Development Framework (SSDF), were developed without accounting for the attack vectors introduced by LLM-based systems. The present study seeks to address this gap through a comprehensive analysis of emerging threats and through the synthesis of an adapted conceptual security governance model.
The purpose of the study is to carry out a systematic analysis of how the threat landscape of the secure software development life cycle is being transformed under the influence of GenAI tools and to formulate recommendations for the creation of an adapted security governance system, the GSGF, suitable for practical application in an international context.
The scientific novelty of the study lies in the systematization of security threats specific to GenAI-enabled SDLC environments and in the development of a conceptual multilevel model, the GSGF, which integrates governance, process, and technical control layers into a unified structure tailored to the distinctive features of applying large language models in software development.
The authorial hypothesis rests on the assumption that integrating LLMs into the software development life cycle not only amplifies classical security threats but also generates fundamentally new attack vectors that cannot be mitigated by existing security tools without targeted adaptation of processes and governance methods. This hypothesis is tested through the analysis of documented cases and a comparative examination of existing frameworks.
Materials and Methods
The methodological basis of the study includes four complementary approaches that jointly ensure both breadth of coverage across the subject area and sufficient depth of analytical synthesis.
The systematic literature review was conducted in accordance with adapted PRISMA principles. The core databases used were IEEE Xplore, the ACM Digital Library, and Scopus, including Springer and ScienceDirect. The inclusion criteria were as follows: the presence of primary empirical data or a systematic review, publication in peer-reviewed outlets, and relevance to the subject domain, including LLM security, AI-assisted development, and DevSecOps. The exclusion criteria covered blogs, press releases, and non-peer-reviewed materials.
The case study method was employed to illustrate specific security incidents documented in authoritative technical sources: the GitLab Duo vulnerability case (2025, Legit Security) [6], the empirical findings reported by Pearce et al. (2022) [9, p. 754-768] and Perry et al. (2023) [7, p. 2785-2799], as well as the study of iterative security degradation in AI-generated code by Schreiber and Tippe (2025) [15]. All cases were selected according to the criteria of verifiability and documentary support. For each case, specific metrics were recorded, including the share of vulnerable code, the vulnerability type, and the scale of the incident.
Comparative analysis made it possible to contrast classical secure development frameworks OWASP Top 10, NIST SSDF, and ISO/IEC 27001:2022 with standards specifically oriented toward GenAI, including the OWASP Top 10 for LLM Applications (2025) [10], the NIST AI Risk Management Framework, GenAI Profile (2024) [16], and the EU AI Act (2024) [17]. This comparison made it possible to identify systemic blind spots within existing regulatory and technological approaches.
The content analysis of technical documentation included an examination of the requirements set forth by the OWASP GenAI Security Project (2025) [10], the recommendations contained in Gartner’s Hype Cycle for Application Security (2025) [4], as well as industry reports published by Legit Security [6], GitGuardian [14], and other analytical materials from 2024-2025 [5]. Academic publications from Frontiers in Big Data [12, p. 1386720], Information and Software Technology [8, p. 107572], and conference proceedings including IEEE Security & Privacy [18, p. 73-81], ACM CCS [7, p. 2785-2799], IEEE/ACM ICPC [13, p. 1-13], and related venues were also analyzed separately.
The source base was classified into the following categories: (1) academic articles in peer-reviewed journals and conference proceedings (IEEE, ACM, Frontiers in Big Data, ScienceDirect), accounting for approximately 70% of all sources; (2) normative and technical documents issued by international organizations (OWASP, NIST, ISO), accounting for approximately 15%; and (3) verifiable analytical reports (Gartner, McKinsey, Legit Security, GitGuardian), accounting for no more than 15% [1, 4, 6, 10, 14, 16]. This proportion is consistent with the conventions of academic peer review in computer science.
Results and Discussion
To understand the scale of the transformation taking place in software development, it is essential to assess the pace at which GenAI tools are entering production processes. According to GitHub Octoverse 2024, 73% of developers involved in open-source projects use AI tools for writing code and documentation [2]. Google reports that approximately one quarter of all code is now created with the assistance of AI-based systems, while developers save at least two hours per week through such use [2]. More broadly, the rapid spread of AI-assisted development suggests that coding assistants are moving from an auxiliary role toward a structurally embedded component of contemporary software engineering workflows [1, 2].
At the same time, the security problem is becoming more acute. According to the Legit Security study (2025), which covered 400 security professionals and developers, an average of 17% of an organization’s repositories use AI tools without adequate code review procedures, while 98% of respondents indicated the need to strengthen controls over the use of GenAI solutions [6]. The situation is marked by a certain paradox: 76% of developers believe that AI tools generate safer code than humans do, yet 59% of those same specialists express concern about the security of AI-generated code [3]. This phenomenon, which may be described as a “false sense of security,” is broadly consistent with academic findings showing that developers often overestimate the reliability of AI-assisted outputs or fail to identify insecure patterns when generated suggestions appear plausible and syntactically convincing [7, p. 2785-2799; 9, p. 754-768; 11, p. 435-444; 12, p. 1386720; 18, p. 73-81]. Emerging first at the level of the individual developer, this distortion gradually acquires a systemic character at the organizational scale, substantially reducing the effectiveness of human oversight over AI-generated code (fig. 1).
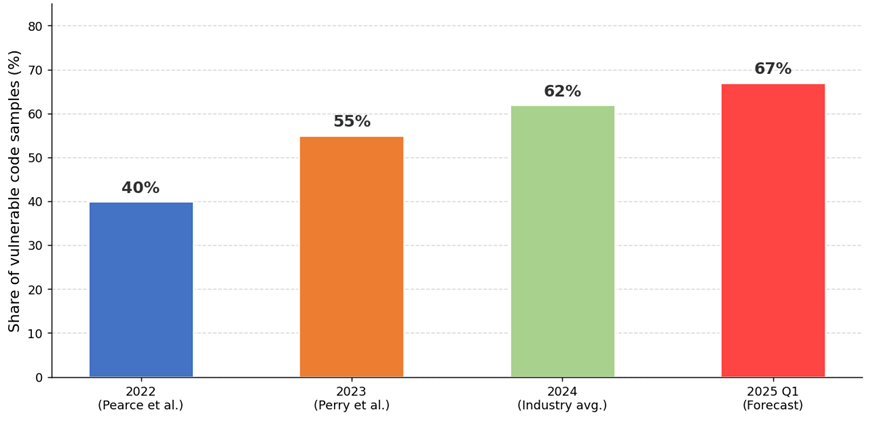
Fig. 1. Share of Vulnerable Code in AI-Generated Software Products (compiled by the author based on [3; 6; 7, p. 2785-2799])
As Figure 1 shows, the share of vulnerable code generated by LLMs displays a stable upward trajectory, rising from 40% in the earliest empirical studies of 2022 to 62% according to 2024 evidence [9, p. 754-768; 11, p. 435-444]. This increase is not explained by a deterioration in the quality of LLM models per se, but rather, and more importantly, by the substantial expansion in the volume and complexity of tasks delegated to AI assistants: from simple line-level code autocompletion to the generation of full modules and architectural components. It is especially telling that, as of June 2025, AI-generated code was introducing more than 10,000 new vulnerabilities per month, a tenfold increase compared with December 2024 [6]. This statistic makes it plain enough that security assurance in the context of GenAI tool adoption requires a systemic rather than a point-by-point response.
The systematization of threats is the first, and really the foundational, step toward building an effective control framework. On the basis of the analysis of the OWASP Top 10 for LLM Applications (2025) [10], IEEE publications by Majdinasab et al. (2024) [11, p. 435-444], and the findings of the systematic review by Negri-Ribalta et al. (2024) [12, p. 1386720], the author compiled a taxonomy of security threats in a GenAI-oriented SDLC (tab. 1).
Table 1
Taxonomy of Security Threats Associated with the Use of GenAI in the SDLC (compiled by the author based on [6; 10; 13, p. 1-13; 14; 16])
Risk Category | Description | Vuln. Type (CWE) | Severity (CVSS) |
Prompt Injection | Attacker manipulates LLM behavior via crafted inputs | CWE-77 | Critical (9.1) |
Insecure Code Generation | LLM produces code with known security flaws | CWE-119, CWE-89 | High (7.8) |
Training Data Poisoning | Malicious data corrupts model training output | CWE-20 | High (8.2) |
Supply Chain Risk | Vulnerable or malicious third-party AI components | CWE-937 | High (7.5) |
Secret Leakage | LLM outputs credentials or sensitive data from training | CWE-312 | High (7.4) |
Insecure Output Handling | Insufficient validation of AI-generated content | CWE-116 | Medium (6.5) |
Model Theft (Extraction) | Adversarial queries reveal proprietary model logic | CWE-200 | Medium (6.1) |
Hallucination-Driven Defects | Fabricated API names or package references in code | CWE-703 | Medium (5.9) |
An analysis of Table 1 makes it possible to distinguish several essential features of the GenAI threat taxonomy as applied to the SDLC. First, a substantial portion of these threats is concentrated in the high and critical CVSS ranges, which indicates their direct impact on the confidentiality, integrity, and availability of systems. Second, many of these threats do not have direct analogues in traditional CWE classifications, since the behavioral specificity of LLMs gives rise to fundamentally new compromise mechanisms. Third, the threats are interconnected and may reinforce one another. Data poisoning, for instance, can establish the systematic production of code containing certain classes of vulnerabilities, including memory-safety flaws and insecure input handling, which, when combined with the absence of code review, produces a scalable attack chain [13, p. 1-13; 16].
The most important vector is prompt injection (OWASP LLM01): the attacker embeds malicious instructions into user input, thereby hijacking the behavior of the LLM assistant. A particularly illustrative example is the GitLab Duo incident in early 2025, when a remote prompt injection vulnerability was discovered in an AI assistant operating on Claude, making it possible to steal source code from private repositories and exfiltrate information about unpatched zero-day vulnerabilities [6].
A fundamentally new phenomenon specific to GenAI tools is represented by hallucination-driven defects produced by the model’s hallucinations. According to Dark Reading (2025), more than 5% of the code generated by commercial models and around 22% of the code generated by open models contain references to nonexistent packages [3]. This opens a new attack vector: the attacker registers a package under a “predictably hallucinated” name and then infects codebases written with the assistance of LLMs through a so-called package substitution attack. In a way, the issue looks deceptively mundane at first glance, just a bad package name, but the downstream consequences can be rather severe.
Moving from taxonomy to concrete practice, it is worth considering documented security cases. Table 2 systematizes the most significant incidents and experimental findings, making it possible to assess the real consequences of using GenAI tools in the SDLC.
Table 2
Case Studies: Documented Incidents and Security Threats Associated with the Use of GenAI in the SDLC (compiled by the author based on [3; 6; 7, p. 2785-2799; 8, p. 107572; 9, p. 754-768; 15])
Case/Tool | Finding/Incident | Security Impact | Key Metric |
GitHub Copilot (2022) | 1,689 generated programs evaluated | 40% of the code contained vulnerabilities; about 50% of the code was written in the C programming language. | 40% vuln. |
GitHub Copilot (2023) | User study vs. manual coding | Users wrote significantly less secure code; false sense of security | User study |
GitLab Duo (2025) | Remote prompt injection discovered | Exfiltration of source code from private repos; zero-day leakage | CVE reported |
Multi-LLM Study (2025) | Five popular models, snippet evaluation | At least 48% of snippets contained vulnerabilities | 48% vuln. |
Iterative Generation (2025) | 400 samples, 40 refinement rounds | 37.6% increase in critical vulnerabilities after five iterations | +37.6% |
Enterprise Survey (2025) | 400 security professionals surveyed | 98% say security teams lack sufficient GenAI visibility | 98% gap |
A comparative analysis of the data presented in Table 2 reveals three key patterns. The first is that, over time, the share of vulnerable code is not declining but increasing, despite declared improvements in the security performance of newer LLM versions. The second is that vulnerabilities are not confined to the code level; they extend to the infrastructure layer, including access control and secret management, and to the process layer, where the absence of code review becomes a critical weakness. The third pattern, and perhaps the most practically significant one, is the observed phenomenon of iterative security degradation.
This phenomenon is documented in detail in the work of Schreiber and Tippe (2025) [15]. In a controlled experiment involving 400 snippets, 40 “improvement” cycles, and four prompting strategies, the author has recorded a 37.6% increase in critical vulnerabilities after five iterations. The most serious security problems were observed under performance-oriented prompting strategies. Only 27% of iterations with security-oriented prompts led to an actual improvement in security, and even then, mostly within the first three iterations. This finding is of fundamental importance for practice because it directly challenges the widespread assumption that repeated iteration with an LLM assistant automatically improves code quality. It does not, at least not reliably. What it does support, quite strongly, is the necessity of mandatory human oversight.
A critical analysis of existing methodological approaches shows that the frameworks currently in use suffer from a persistent structural gap when applied to GenAI-specific threats. The traditional OWASP Top 10 addresses web application threats, yet it does not include threat models for LLMs as components of the development process. OWASP developed a separate document, the LLM Top 10 (2025) [10], precisely because the attack surface is fundamentally different.
The NIST Secure Software Development Framework (SSDF) offers a mature methodology for managing security requirements, but it does not account for the specificity of AI-assisted development tools. The NIST AI RMF (2024) [16] closes part of this gap in relation to AI systems as products, yet it addresses, only to a limited extent, the security of development processes carried out with AI. The EU AI Act (2024) [17] introduces a risk categorization for AI systems and establishes mandatory documentation requirements, but it remains focused primarily on AI as an end product.
Thus, no existing framework fully covers the scenario in which GenAI is used as a code-writing instrument in a production environment. This gap constitutes the fundamental justification for the GSGF model proposed by the author. What matters here is that the GSGF neither duplicates nor replaces existing frameworks. Rather, it is embedded within their structure, adding the missing layer of GenAI-specific controls (fig. 2).
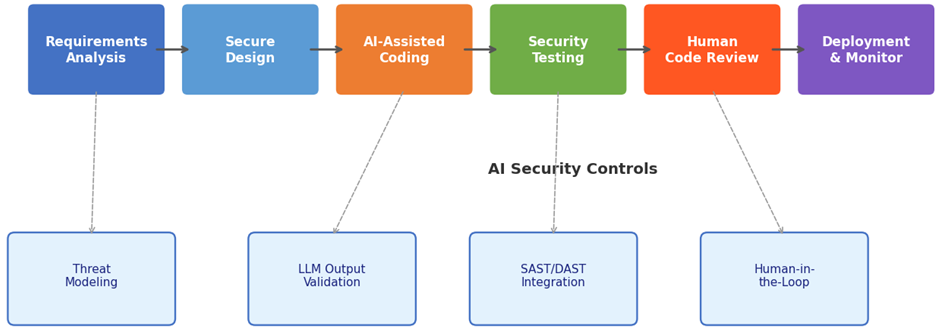
Fig. 2. Model of a Secure SDLC with GenAI Integration (AI-SecSDLC) (compiled by the author based on [10; 12, p. 1386720; 16])
Figure 2 presents the author’s conceptual model for integrating AI assistants into a secure software development life cycle, referred to as the AI-Secure SDLC. The model identifies four key control insertion points corresponding to the most critical nodes of compromise.
First, at the requirements analysis stage, the model prescribes formalized threat modeling that explicitly accounts for AI-specific threats. This is necessary because the use of LLMs in development introduces risks that are poorly captured by conventional secure design assumptions and therefore require early-stage identification in the architecture and requirements phase [10; 12, p. 1386720; 16].
Second, at the stage of AI-assisted coding, the central control is the validation of LLM-generated outputs. In this context, generated code cannot be treated as presumptively trustworthy merely because it is syntactically correct or functionally plausible. On the contrary, the model assumes that every AI-produced fragment should be regarded as potentially unsafe until verified against secure coding requirements and contextual development constraints [10; 12, p. 1386720].
Third, within security testing, the model provides for the integration of SAST and DAST procedures with specialized rules tailored to AI-generated code. This point is especially important because conventional static and dynamic analysis pipelines are often configured for human-written code and may fail to detect defects specific to LLM-generated outputs, including insecure dependency references, hallucinated calls, and reproducible vulnerability patterns inherited from unsafe training distributions [10; 12, p. 1386720].
Fourth, at the stage of code review, the model requires the mandatory participation of a human expert. This element is fundamental rather than auxiliary. The accumulated empirical evidence suggests that iterative interaction with AI assistants does not eliminate the need for expert review; in some cases, it actually increases the probability that insecure solutions will pass into production if human oversight is weakened or treated as optional [12, p. 1386720]. In this sense, the human reviewer functions not as a redundant checkpoint, but as the final interpretive and accountability layer within the secure development process.
Taken together, these controls form a protective perimeter that neutralizes the principal threat classes identified in Table 1 without requiring organizations to abandon GenAI tools altogether. The logic of the model is therefore not prohibitive but adaptive: GenAI is treated neither as an inherently secure accelerator nor as a technology that must be categorically excluded, but as a high-variance instrument whose benefits are achievable only under conditions of structured governance and layered control [10; 12, p. 1386720; 16].
For the structured prioritization of threats and to justify the allocation of resources, the author developed a risk matrix (fig. 3) reflecting both the likelihood of realization and the potential impact of each threat on the basis of OWASP materials, Gartner assessments, and academic sources [4; 10; 12, p. 1386720].
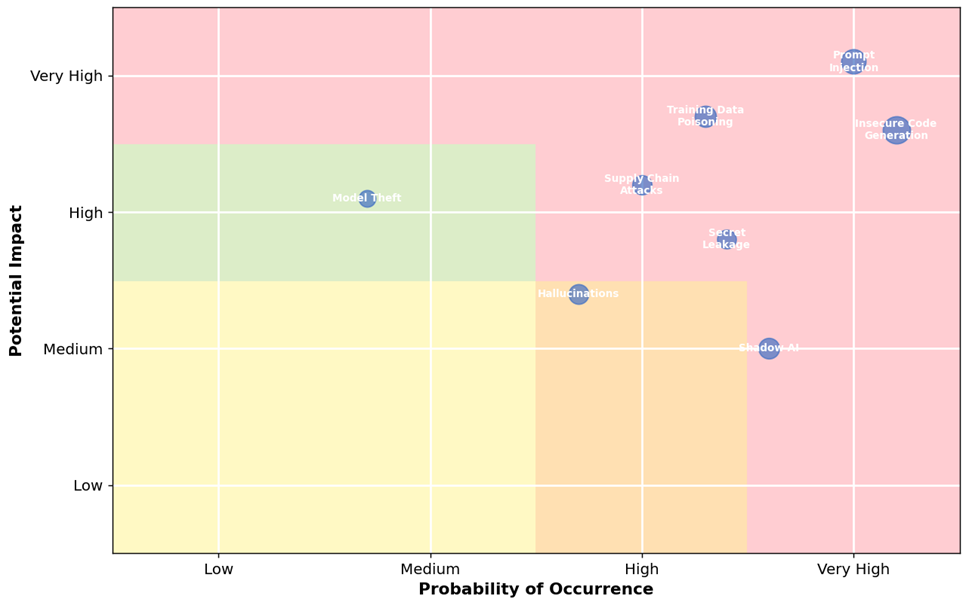
Fig. 3. Risk Matrix of GenAI Security Threats in the SDLC (compiled by the author based on [4; 10; 11, p. 435-444; 16])
The analysis of the matrix reveals three priority groups of threats. The highest-priority zone, combining high likelihood with high impact, includes Prompt Injection and Insecure Code Generation threats that require the immediate deployment of specialized technical controls. The high-priority zone, defined by medium-to-high likelihood and medium-to-high impact, includes Training Data Poisoning, Supply Chain Attacks, and Secret Leakage. The monitoring zone includes Hallucinations and Model Theft, which may not always produce immediate large-scale damage, yet remain strategically important because of their capacity to evolve into more severe compromise scenarios when combined with weak governance and insufficient validation procedures. Gartner’s assessments likewise indicate that attacks against AI-enabled systems will increasingly exploit weaknesses in access management and instruction handling, including direct and indirect prompt-based manipulation [4].
A distinctive authorial observation concerns the special position of Shadow AI within the matrix. Although its direct damage may appear comparatively moderate, it functions as a systemic amplifier of nearly all other threats. The use of unauthorized GenAI tools creates blind spots within the security architecture, making it impossible to apply the controls prescribed by the GSGF model in a consistent manner. According to executive survey evidence, a substantial share of security leaders already acknowledge incidents involving corporate data leakage through unsanctioned GenAI tools [1]. Consequently, the governance of Shadow AI should be treated not as an auxiliary administrative matter but as a necessary precondition for the effectiveness of any technical protection measures.
On the basis of the analysis conducted, the author proposes the conceptual model GenAI Security Governance Framework (GSGF). The principal distinction between the GSGF and existing frameworks lies in three aspects. First, it applies the principle of defence in depth, specifically adapted to LLM-related threats across all three layers of the model. Second, the GSGF explicitly takes into account the phenomenon of iterative security degradation [15], embedding mandatory human checkpoints into every cycle of AI-assisted development. Third, the model integrates the current regulatory requirements of the EU AI Act (2024) [17] and the NIST AI Risk Management Framework (2024) [16] as they relate to SDLC processes (fig. 4).
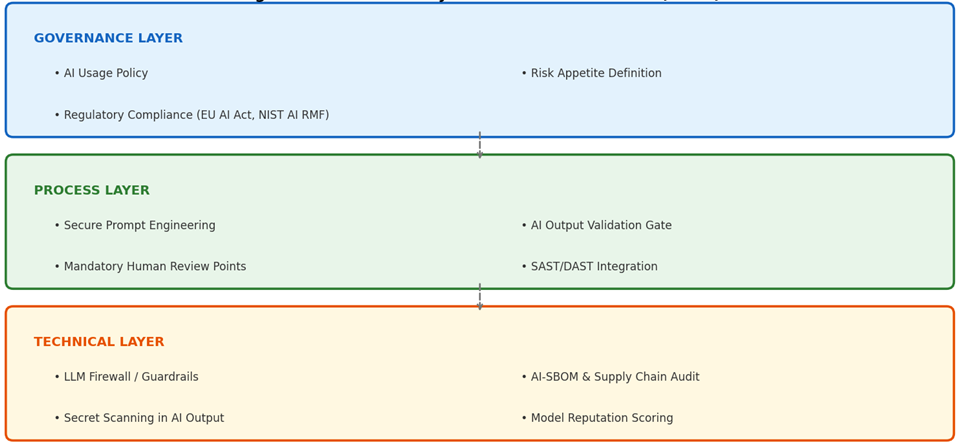
Fig. 4. GenAI Security Governance Framework (compiled by the author based on [10, 16, 17])
The Governance Layer covers the following elements:
- An AI Usage Policy, including the list of approved LLM tools, prohibited use scenarios, the classification of data permitted for processing by AI assistants, and the boundaries of acceptable use;
- A formalized definition of risk appetite as applied to GenAI, with measurable threshold values, for example, the maximum permissible share of AI-generated code allowed to enter the workflow without verification;
- Assurance of compliance with the EU AI Act and the NIST AI Risk Management Framework, particularly in the areas of governance, accountability, documentation, and risk treatment [16, 17]. Without this layer, technical controls will almost inevitably be bypassed through Shadow AI practices.
The Process Layer provides for Secure Prompt Engineering in the form of corporate prompt libraries with mandatory security context and role-based templates; an AI Output Validation Gate, including automated SAST checks directly in the CI/CD pipeline, with merge prohibition where vulnerabilities meeting criticality thresholds are detected; Human Review Checkpoints, requiring the mandatory involvement of a senior developer or security specialist in the review of critical modules written with AI participation; and the integration of specialized SAST/DAST rules for AI-specific vulnerabilities. This layer directly addresses the phenomenon of iterative security degradation documented in [15].
The Technical Layer includes LLM Firewall / Guardrails systems for filtering model inputs and outputs in order to detect prompt injection attempts; AI-SBOM (Software Bill of Materials), meaning the documentation of all AI components in use together with reputation assessment and a policy restricting the use of low-rated or insufficiently verified models; automated Secret Scanning of AI-generated code for, according to GitGuardian (2025), 6.4% of repositories using GitHub Copilot expose at least one secret, which is 40% higher than the rate observed in repositories without AI assistants [14]; and a Model Reputation Scoring mechanism applied before integration into the SDLC.
A more detailed description of the GSGF components, the required practices, and their normative alignment is presented in Table 3.
Table 3
GSGF Components: Required Practices and Regulatory Alignment (compiled by the author based on [4, 10, 14, 16, 17])
GSGF Layer | Component | Required Practice | Regulatory Alignment |
Governance | AI Usage Policy | Define approved LLMs, prohibited use cases, and data classification | EU AI Act; NIST AI RMF |
Governance | Risk Appetite | Quantify acceptable vulnerability introduction rate per sprint | ISO/IEC 27001:2022 |
Process | Secure Prompt Engineering | Mandatory security context injection; role-based prompt templates | OWASP LLM07 |
Process | AI Output Validation Gate | SAST scan before merge; deny merge if critical findings exceed accepted thresholds | NIST-aligned secure development practice |
Process | Human Review Checkpoints | Mandatory senior review for AI-generated critical modules | Gartner recommendations, 2025 |
Technical | LLM Firewall / Guardrails | Input/output filtering; prompt injection detection layer | OWASP LLM01 |
Technical | AI-SBOM | Bill of materials for all AI models; reputation scoring policy | EU AI Act; AI governance best practices |
Technical | Secret Scanning | Pre-commit hooks to detect credentials in LLM output | GitGuardian, 2025 |
An objective analysis of the proposed model requires acknowledging the barriers that currently constrain its practical implementation. The first, and perhaps the most significant, barrier is organizational: the structural divide between development teams and information security teams. Gartner indicates that, in the coming years, a growing share of application vulnerabilities may emerge from forms of so-called “vibe coding,” situations in which GenAI is used without any meaningful security controls [4]. Eliminating this barrier requires organizational change that extends well beyond purely technical solutions.
The second barrier is technological: the growth in the volume of AI-generated code far outpaces the expansion of the analytical capacity available to security teams. According to Legit Security (2025), AI-generated code was introducing more than 10,000 new vulnerabilities per month by June 2025, a tenfold increase over a six-month period [6]. Under conditions of constrained security resources, this dynamic all but guarantees the accumulation of security technical debt.
The third barrier is regulatory: the EU AI Act and the broader European data protection regime do not yet fully cover scenarios in which AI is used as a software development instrument, thereby creating legal uncertainty regarding responsibility for vulnerabilities introduced by LLM systems [16, 17]. The issue here is not simply one of formal compliance, but of attribution, accountability, and enforceable control boundaries.
In the author’s view, the key condition for overcoming these barriers is the development of an AI security awareness culture, within which every developer understands the specific risk profile of LLM-based tools and accepts responsibility for validating AI-generated code. The study by Negri-Ribalta et al. (2024) confirms that AI tools may either strengthen or weaken security depending on the competence and judgment of their users [12, p. 1386720]. Technical controls are therefore necessary, but not sufficient; without a cultural shift, their effect will remain limited. The combined organizational, procedural, and technical measures embodied in the GSGF are aimed precisely at creating a systemic environment in which AI-aware security becomes part of the corporate development culture.
Conclusion
The study makes it possible to formulate several key conclusions that confirm both the stated research objective and the author’s hypothesis. First, the integration of GenAI tools into the software development life cycle does indeed transform the nature of security threats: alongside traditional vulnerabilities, fundamentally new vectors emerge, including prompt injection, data poisoning, supply chain compromise through AI components, and hallucination-driven defects. The available empirical evidence indicates a persistently high share of vulnerable AI-generated code across recent studies, while the volume of newly introduced vulnerabilities rose sharply in the first half of 2025. In that sense, the author’s hypothesis regarding a qualitative, and not merely quantitative, transformation of the threat landscape is supported.
Second, it has been established that existing security frameworks OWASP Top 10, NIST SSDF, and BSIMM, in their conventional form, contain systematic gaps when applied to GenAI-specific threats: none of them was originally designed with LLMs in mind as active components of the development process. This gap creates a real operational risk for organizations that continue to rely exclusively on traditional security mechanisms.
Third, the proposed conceptual model, the GSGF, fills the identified gap by offering a three-layer structure governance process, technically adapted to the specificity of GenAI-related threats and aligned with the current regulatory requirements of the EU AI Act and the NIST AI RMF. A central normative element of the model is the mandatory inclusion of a human expert in every cycle of AI-assisted development involving critical modules. This approach directly counteracts the documented phenomenon of iterative security degradation.
The practical significance of the study lies in the fact that the formulated recommendations and the components of the GSGF may be used directly by organizations when developing internal policies governing the use of GenAI tools, when building AI-integrated CI/CD pipelines with embedded security controls, and when assessing compliance with the EU AI Act and the NIST AI RMF.
Further directions for research include the quantitative assessment of the effectiveness of individual GSGF components on the basis of A/B experiments in production environments; the development of an AI Security Maturity Model; and a comparative analysis of vulnerabilities generated by different LLM models in light of sector-specific requirements, including the financial sector, medical software, and critical infrastructure.
