
Целью данной статьи является исследование влияния стемминга и лемматизации на качество бинарной классификации по тональности кратких текстовых комментариев на английском и русском языках социальной сети Twitter.
Размеченные данные для обучения были получены с платформы Kaggle [3] и сайта корпуса текстов твитов на русском [1]. Оба источника представляют собой тексты комментариев социальной сети Twitter. Количество русских комментариев: 226834. Количество английских комментариев: 1600000. Размеченные классы: положительные комментарии и отрицательные комментарии (имеется в виду тональность текста). Классы в корпусах сбалансированы. Для того, чтобы разница качества классификации не была вызвана превосходящим размером набора данных английских комментариев, для анализа из него было случайным было отобрано количество равное русским.
В качестве инструмента для проведения исследования был использован язык программирования Python (версия 3.8.2). Процесс получения результата был реализован следующим образом. Для начала были взяты комментарии из английского и русского корпусов соответственно. Слова-упоминания, хештеги и ссылки (то есть все, что начинаются на «@», «#», «http») были удалены в силу того, что они понижают обобщающую способность классификации и приемлемы только для того промежутка времени, когда были использованы. Далее были получены стемматизованные и лемматизованные варианты этих корпусов при помощи библиотек nltk и pymorphy2. Затем при помощи библиотеки sklearn была проведена векторизация текста по методу TF-IDF (Term Frequency – частота термов, Inversed Document Frequency – обратная частота термов) c приведением к нижнему регистру и ограничением словаря в сто тысяч слов. В качестве модели классификации использовалась логистическая регрессия. Качество оценивалось по методу кросс-валидации с разбиением на десять частей. В качестве метрики качества были выбраны ROC-AUC (Receiving Operating Сharacteristic – рабочая характеристика приемника, Area Under Curve – площадь под кривой) и F1-мера. Результаты представлены на рис. 1 и рис. 2.
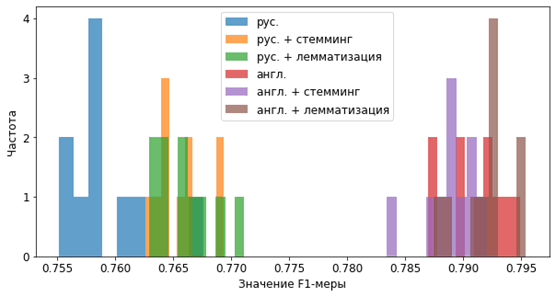
Рис. 1. Результаты для F1-меры
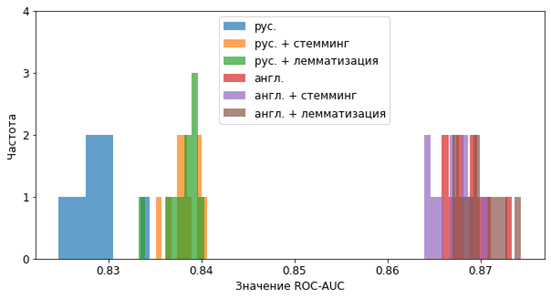
Рис. 2. Результаты для ROC-AUC
На приведенных рисунках видно явное различие между классификацией двух языков, причем стемминг и лемматизация для русского работают заметно лучше, что скорее всего обосновано большим разнообразием форм слов. Следует отметить, что визуальной оценки может быть недостаточно: для каждого разбиения результаты отличаются, то есть имеют некоторую случайную составляющую. Чтобы ответить на вопрос: «насколько значимы видимые различия?», используем непараметрический тест Манна-Уитни на различие медиан [2] выборок. Выберем уровень значимости в 5%. Результаты для F1-меры представлены на табл. 1. Результаты для ROC-AUC на табл. 2.
Таблица 1
Сравнение качества с использованием F1-меры
|
Сравниваемые подходы |
Медиана метрики качества |
p-value |
|---|---|---|
|
рус. |
0.758245 |
0.000853 |
|
рус. + стемминг |
0.764769 | |
|
рус. |
0.758245 |
0.000657 |
|
рус. + лемматизация |
0.765707 | |
|
рус. + стемминг |
0.764769 |
0.366865 |
|
рус. + лемматизация |
0.765707 | |
|
англ. |
0.791854 |
0.034769 |
|
англ. + стемминг |
0.789028 | |
|
англ. |
0.791854 |
0.236338 |
|
англ. + лемматизация |
0.792440 | |
|
англ. + стемминг |
0.789028 |
0.007010 |
|
англ. + лемматизация |
0.792440 |
Таблица 2
Сравнение качества с использованием ROC-AUC
|
Сравниваемые подходы |
Медиана метрики качества |
p-value |
|---|---|---|
|
рус. |
0.828686 |
0.000091 |
|
рус. + стемминг |
0.838230 | |
|
рус. |
0.828686 |
0.000123 |
|
рус. + лемматизация |
0.838250 | |
|
рус. + стемминг |
0.838230 |
0.395668 |
|
рус. + лемматизация |
0.838250 | |
|
англ. |
0.868252 |
0.060612 |
|
англ. + стемминг |
0.867032 | |
|
англ. |
0.868252 |
0.120661 |
|
англ. + лемматизация |
0.869588 | |
|
англ. + стемминг |
0.867032 |
0.010567 |
|
англ. + лемматизация |
0.869588 |
Судя по полученным результатам, стемминг и лемматизация значимо влияют на результаты классификации русского языка по сравнению с их отсутствием, но отличие медианы качества стемматизиванного от лемматизованного набора данных невелико.
Для данных на английском языке результаты получились противоположные: для данных с предобработки и без предобработки недостаточно оснований отвергнуть нулевую гипотезу о разнице медиан. Различия в метриках стемматизиванного и лемматизованного наборов данных являются значимыми. Дополнительно следует отметить, что стемминг значимо снизил качество F1-меры относительно метода, где предобработка отсутствует.
Обобщая полученные результаты, можно сделать вывод о том, что лемматизация является наиболее пригодным методом для получения максимального качества классификации по выбранным метрикам. Следует отметить, что этот метод более вычислительно сложный, чем стемминг, и, в условиях ограниченности вычислительных ресурсов, возможно, придется делать выбор в сторону подходов с меньшим качеством.
