
Актуальность исследования
В современных корпоративных backend-системах обеспечение высокой доступности, отказоустойчивости и непрерывности бизнес-процессов – задача первоочередная. С увеличением сложности распределённых систем, ростом нагрузки и числа взаимодействующих сервисов, отказы компонентов становятся статистически неизбежными. Непредсказуемость отказов (самых разных причин – сбои железа, сети, ПО, человеческий фактор) требует подхода, в котором способность системы продолжать работу даже под влиянием проблем закладывается заранее.
Концепция Design-for-Failure, являющаяся базовым принципом строительства облачных архитектур (в AWS, Netflix, Google Cloud и др.), предлагает активно моделировать нештатные сценарии и проектировать цепочки восстановления на уровне архитектуры. Несмотря на это, многие корпоративные системы, особенно построенные на основе монолитов или legacy-инфраструктур, недостаточно эффективно реализуют подход отказоустойчивого дизайна. В результате инциденты приводят к простоям, потерям клиентов и существенным финансовым издержкам.
Таким образом, исследование принципа Design-for-Failure в контексте корпоративных backend-систем сегодня крайне актуально для повышения надёжности, устойчивости и минимизации рисков бизнеса.
Цель исследования
Цель данной работы – проанализировать и систематизировать применение концепции Design-for-Failure при проектировании корпоративных backend-систем.
Материалы и методы исследования
Исследование основано на анализе публикаций ведущих технологических компаний (Amazon, Netflix, Google, IBM), научных статей и инженерных блогов, а также практических кейсов из открытых источников.
Использованы методы системного анализа, архитектурного сравнения, типологии паттернов и эмпирического обобщения подходов, применяемых в реальных высоконагруженных системах.
Результаты исследования
Понятие Design‑for‑Failure основано на осознании неизбежности сбоев в распределённых и облачных системах. Design for Failure (дизайн на отказ) – базовый принцип проектирования облачных сервисов AWS [4].
Amazon-Netflix ввели Chaos Engineering – практику умышленного провоцирования сбоев («Chaos Monkey»), чтобы убедиться, что архитектура выдерживает реальные сбои [5].
Принципы проектирования отказоустойчивых систем представлены в таблице 1.
Таблица 1
Принципы проектирования отказоустойчивых систем
| Принцип | Описание |
|---|---|
| Быстрый отказ | Компонент должен немедленно завершать работу при обнаружении ошибки, не пытаясь «тянуть» дальше. Это облегчает диагностику и предотвращает распространение сбоя на другие части системы |
| Плавная деградация | При возникновении проблем система должна сохранять частичную функциональность. Например, временно отключить неключевые функции, чтобы сохранить основную логику |
| Избыточность | Критически важные компоненты (серверы, БД, каналы) дублируются, чтобы при отказе одного узла другой мог взять на себя его функции без перерыва в обслуживании |
| Репликация | Данные дублируются между несколькими серверами или зонами, что обеспечивает их сохранность и доступность при сбоях. Используется в БД и хранилищах |
| Тайм-ауты | Ограничение времени выполнения операций. При превышении установленного времени запрос прерывается, что предотвращает «зависания» системы |
| Повторы с интервалами | При временном отказе система повторяет операцию с задержками. Используется в сетевых вызовах, например, API-запросах |
| Предохранитель | Если сервис постоянно выдаёт ошибки, цепочка вызова разрывается, чтобы не нагружать зависимый сервис и дать ему восстановиться. Похож на предохранитель в электросети |
| Отсековая изоляция | Разделение системы на независимые модули или «отсеки». Если один из них выходит из строя, остальные продолжают функционировать |
| Балансировка нагрузки | Распределение нагрузки между несколькими экземплярами сервисов для предотвращения перегрузки одного узла и повышения отказоустойчивости |
| Проверка состояния | Автоматический мониторинг компонентов системы. Нездоровые узлы исключаются из работы, автоматически перезапускаются или заменяются |
| Хаос-инжиниринг | Преднамеренное внесение сбоев в систему для оценки её устойчивости и выработки механизмов автоматического восстановления |
| Автоматическое восстановление | Система должна самостоятельно восстанавливаться после сбоев – например, перезапускать сломанный контейнер или переключаться на резервный сервер |
Современные микросервисные архитектуры – классическая среда реализации принципа Design‑for‑Failure. Они строятся на независимых сервисах, связанных через API‑шлюз и балансировщики нагрузки, что упрощает удержание отказов локализованными и позволяет масштабировать критичные компоненты.
Классические паттерны устойчивости включают:
- Повторы запросов с экспоненциальными задержками (Retry with Backoff) используются для смягчения эффектов временных сбоев и сетевых лагов.
- Circuit Breaker предотвращает каскадные отказы за счёт перехода цепи обслуживания в «открытое» состояние при повторяющихся ошибках, с последующей возможностью восстановления через короткий период «half‑open».
- Timeouts и Fallback предотвращают зависания и давят на взаимозависимые сервисы, если время ответа превышено, запускается запасной механизм.
- Bulkhead Isolation защищает систему путём логической сегментации потоков – отказ внутри одного контура не распространяется на другие.
- Service Discovery и Load Balancing обеспечивают автоматическое распределение запросов между репликами сервисов, что критично для восстановления и масштабирования инфраструктуры.
- Health Checks & Auto‑Healing – непрерывный мониторинг через readiness и liveness probes в Kubernetes, перезапуск «больных» подов и выключение проблемных экземпляров.
- Много‑региональные (multi‑region/multi‑AZ) архитектуры с репликацией состояния и баз данных, способные выдержать полные отключения регионов посредством Kubernetes‑кластеров и CockroachDB.
- Cell‑based architecture (cell‑подход) предлагает разбиение системы на автономные «ячейки», каждая со своим набором сервисов и данных. При сбое одной ячейки другие остаются работоспособными.
- Chaos Engineering – стратегический подход к устойчивости системы через регулярное, контролируемое инжектирование отказов (удаление pod'ов, сеть, дисковые I/O и пр.). Такие эксперименты (Chaos Monkey, Chaos Mesh, Gremlin) выявляют скрытые уязвимости и улучшают надежность.
Часто технические решения комбинируются, формируя целостные resilient‑архитектуры: сервисный шлюз обеспечивает retry/circuit‑breaker, за ними следует балансировка, health‑чек, autorecovery, затем репликация и cell‑разбиение – всё это завершается регулярным тестированием через chaos‑engineer‑практики в Kubernetes‑окружении.
Применение Design‑for‑Failure в корпоративных backend‑системах включает:
- переход к микросервисной архитектуре с независимыми компонентами;
- автоматизацию управления отказами и восстановлением через SRE‑практики;
- повышение устойчивости инфраструктуры через мультибакенд‑развёртки и репликацию;
- регулярное тестирование отказов через chaos‑engineering для выявления скрытых уязвимостей.
Эти подходы уже доказали эффективность в крупных экосистемах (банки, телекомы, облачные поставщики), подтверждая снижение MTTR, рост SLA и уменьшение инцидентов [1, с. 119].
Внедрение подхода Design‑for‑Failure часто сталкивается с препятствиями, обусловленными существованием legacy‑систем – устаревшей инфраструктуры и монолитных приложений, которые слишком сложны для рефакторинга и интеграции современных паттернов. Унаследованная архитектура характеризуется жесткой связностью компонентов, отсутствием автоматических тестов и документации, что резко увеличивает риски изменений и снижает гибкость системы. Кроме того, недостаток квалифицированных специалистов по таким системам усугубляет проблему: программисты, знающие детали legacy‑решений, зачастую уже покинули компании.
Важное ограничение – технический долг. Быстрые временные решения на ранних этапах разработки накапливают «процент» долгов, что усложняет последующее внедрение resilient‑паттернов, таких как retry, circuit breaker и bulkhead. Параллельно, необходимость обхода единой точки отказа (SPOF) требует значительных усилий – точное выявление и устранение всех таких узких мест в крупной системе может потребовать месяцы на аналитические работы и реконфигурацию.
Гибкость и масштабируемость инфраструктуры – третий вызов. Например, внедрение multi‑AZ или multi‑region подходов требует средств, навыков и поддержки со стороны поставщиков. Кроме того, любая архитектура с репликацией и failover нуждается в продуманной стратегии RTO/RPO и учёте сетевых задержек, что значительно усложняет проектирование и тестирование
Особую сложность представляет внедрение Chaos Engineering в продуктивной среде. С одной стороны, эти практики помогают выявлять неизвестные сбои, но с другой – сами по себе могут вызвать инциденты и даже потерю данных, если не сопровождаются надёжным мониторингом и планом отката. Помимо этого, они требуют значительного технического оснащения – инструментов автоматизации, наблюдения, квалифицированных специалистов и согласованных сценариев экспериментов.
Также, наличие разрозненных каналов наблюдения и мониторинга увеличивает сложность управления отказами. Без единой системы логирования и метрик невозможно оперативно реагировать на отклонения, что снижает эффективность механизмов auto‑heal и health checks, запланированных в архитектуре.
С экономической точки зрения, расходы на переход к отказоустойчивым системам часто оказываются высокими: обновление инфраструктуры, лицензия на инструменты, обучение персонала — всё это увеличивает TCO (total cost of ownership), особенно для компаний без крупных бюджетов.
На рисунке 1 представлена модель распределения отказов по вероятности возникновения и влиянию на систему. Основные «шумы» приходится на человеческие ошибки и нарушения процессов. Увеличение надёжности требует автоматизации, многоуровневых подходов и резервирования.
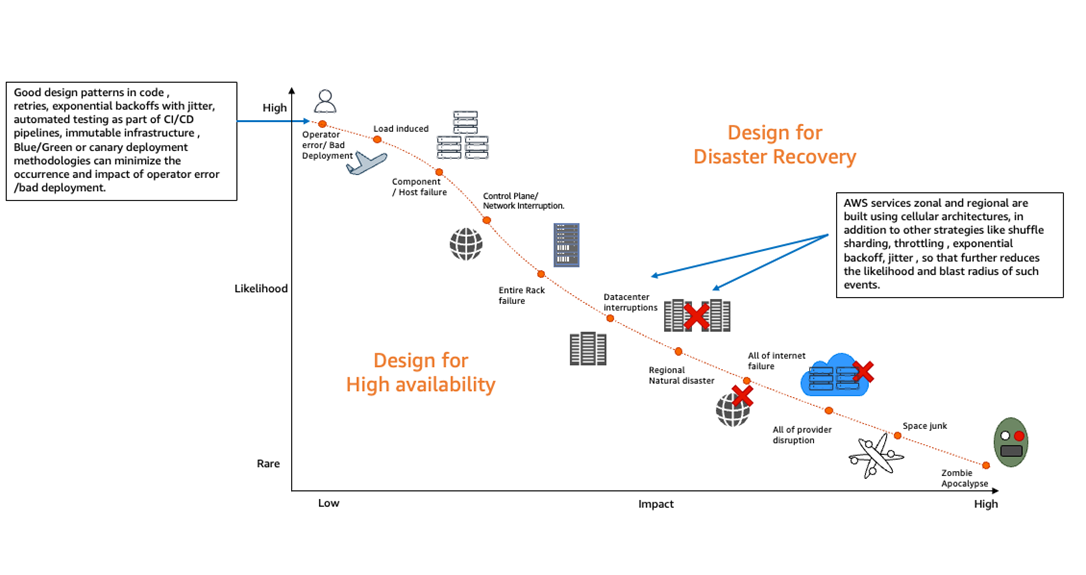
Рис. 1. Архитектура отказоустойчивой backend-системы в AWS с мультизональной изоляцией
На диаграмме представлены три уровня защиты от отказов:
- Зона доступности (Availability Zone) – каждый компонент развернут в нескольких изолированных дата-центрах.
- Автоматическая балансировка нагрузки (Load Balancer) – распределяет трафик между рабочими экземплярами, минимизируя влияние отказов отдельных инстансов.
- Механизмы восстановления (Auto Healing, Health Checks) – обеспечивают автоматическое перезапускание компонентов в случае сбоя.
Такая архитектура позволяет минимизировать время восстановления (MTTR), повысить доступность сервисов (SLA ≥ 99.99%) и устранить каскадные отказы, соответствуя принципам Design-for-Failure.
Программно-конфигурируемая сеть с отказоустойчивым распределенным контуром управления должна включать в себя четыре основных уровня (рисунок 2) [2, с. 105]:
- Контур данных.
- Инфраструктура подключения OpenFlow.
- Распределенная платформа управления.
- Межконтроллерная коммуникационная инфраструктура.
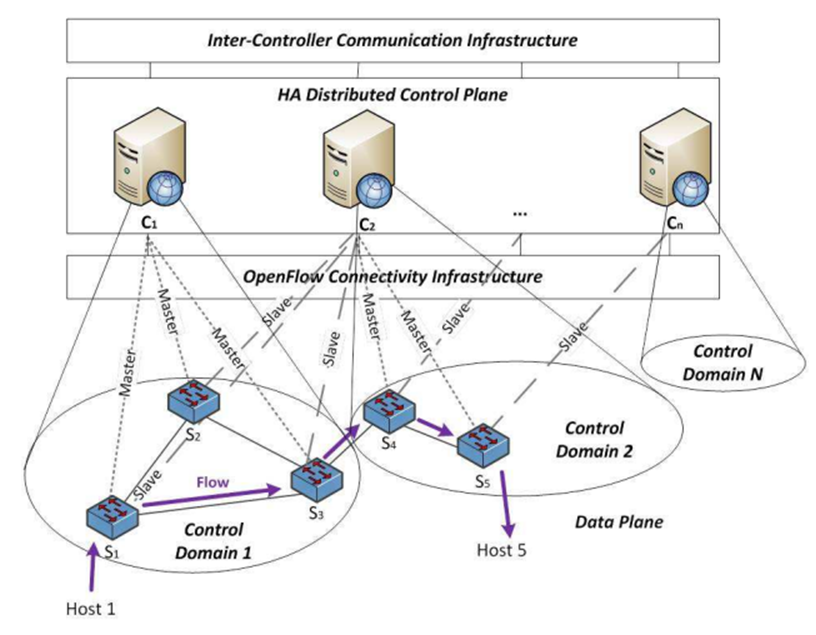
Рис. 2. Модель отказоустойчивой распределенной платформы управления ПКС
Несмотря на широкое распространение подхода Design-for-Failure в облачных и микросервисных архитектурах, его внедрение в корпоративных backend-системах сопряжено с рядом проблем и ограничений. В таблице 2 представлены основные барьеры, с которыми сталкиваются компании при реализации отказоустойчивых архитектур, а также описание их причин и последствий.
Таблица 2
Проблемы и ограничения применения Design-for-Failure в корпоративных backend-системах
| Проблема / Ограничение | Описание и последствия |
|---|---|
| Высокая сложность архитектуры | Реализация отказоустойчивой системы требует глубоких знаний и комплексных решений (circuit breaker, backoff, chaos). Это усложняет поддержку, тестирование и эксплуатацию. |
| Рост стоимости инфраструктуры | Необходимость дублирования сервисов, использования балансировщиков, многоузловых БД, логирования и мониторинга ведёт к увеличению затрат на ресурсы и обслуживание. |
| Зависимость от облачной инфраструктуры | Реализация некоторых механизмов (например, multi-region failover) требует облачных решений, которые недоступны в on-premise или локальных дата-центрах. |
| Сопротивление внутри команды / культуры | Переход к DfF требует зрелой DevOps-культуры, понимания концепций resiliency и отказа от привычной «монолитной» логики, что вызывает сопротивление у команды. |
| Проблемы при миграции с legacy-систем | Старые корпоративные системы сложно адаптировать под принципы отказоустойчивости без полной переработки архитектуры, что требует больших временных и трудовых затрат. |
| Сложность тестирования отказов | Реализация хаос-инжиниринга, тестов на деградацию и самовосстановление требует специфических инструментов и опыта, а ошибки при тестировании могут повлиять на прод. |
| Переусложнение при избыточной защите | Чрезмерное количество «страховок» (механизмы повторов, предохранителей, кэширования и fallback) могут приводить к избыточной задержке, дублированию или ложным отказам. |
С учётом растущей сложности корпоративных ИТ-систем и требований к их надёжности подход Design-for-Failure продолжает эволюционировать. Одним из ключевых направлений развития является интеграция искусственного интеллекта и машинного обучения для предсказания отказов. AIOps-платформы (например, IBM AIOps, Google SRE) анализируют логи и метрики, выявляют аномалии и автоматически инициируют восстановление, снижая MTTR и повышая SLA.
Развивается также применение самовосстанавливающихся инфраструктур на базе Kubernetes и GitOps, где система автоматически воссоздаёт состояние компонентов при сбоях. Это повышает управляемость и отказоустойчивость в динамичных средах.
Важным вызовом остаётся адаптация DfF к регулируемым отраслям (финансы, медицина, оборона), где отказоустойчивость должна быть формализована и соответствовать нормативным требованиям. Это требует новых подходов к сертифицированному архитектурному дизайну.
Отдельное внимание уделяется развитию Chaos Engineering: современные инструменты (Gremlin, Chaos Mesh, LitmusChaos) позволяют тестировать поведение систем под отказами не только в продакшене, но и на стадии разработки как часть CI/CD и DevOps [3].
Кроме того, растёт интерес к формализации оценки устойчивости архитектур: разрабатываются метрики и модели, позволяющие не только фиксировать инциденты, но и прогнозировать архитектурные уязвимости.
Таким образом, перспективы дальнейших исследований охватывают автоматизацию, формализацию, применение ИИ и встраивание DfF в процессы проектирования, тестирования и сопровождения систем с высоким уровнем ответственности.
Выводы
Принцип Design-for-Failure представляет собой эффективную стратегию построения устойчивых backend-систем, способных продолжать функционирование при сбоях компонентов, нарушениях сетевого взаимодействия и деградации инфраструктуры. Его применение требует перехода к микросервисной архитектуре, внедрения автоматических механизмов восстановления, отказоустойчивых паттернов (bulkhead, fallback, timeout и др.) и постоянного тестирования надёжности системы. Внедрение таких подходов особенно актуально в условиях роста SLA-требований и масштабов цифровых сервисов, однако сопряжено с рядом ограничений: архитектурной сложностью, техническим долгом, зависимостью от облачных провайдеров и сопротивлением изменениям внутри команд.
Перспективы дальнейшего развития концепции связаны с автоматизацией через AIOps, развитием Chaos Engineering, формализацией архитектурной надёжности и внедрением отказоустойчивого проектирования в регулируемых отраслях. Системный подход к внедрению Design-for-Failure позволяет существенно снизить MTTR, повысить стабильность и обеспечить непрерывность бизнес-процессов.
