
Цифровые технологии стремительно меняют все сферы жизни современного общества. В бизнесе, науке, журналистике и многих других сферах всё большую роль играет анализ данных, количество которых накапливается с возрастающей скоростью. Не стала исключением и область гуманитарных исследований, внутри которой возникло новое направление – цифровая гуманитаристика (англ. Digital Humanities), объединяющие методики и практики гуманитарных, социальных и вычислительных наук с целью изучения возможностей применения и интерпретации новых цифровых и информационно-коммуникационных технологий в гуманитарных науках и образовании. Одной из тенденций развития цифровой гуманитаристики является постепенное всё более широкое использование методов интеллектуального анализа данных и технологий машинного обучения. Поскольку историческая наука преимущественно имеет дело с письменными источниками, для нас наибольший интерес должны представлять методы интеллектуального анализа текста (англ. text mining). Интеллектуальный анализ текстов – это одно из направлений сферы искусственного интеллекта, цель которого автоматическое получение информации из коллекций текстовых документов на основе методов обработки естественного языка (англ. natural language processing, NLP) и машинного обучения (англ. machine learning) [11, p. 1–15]. Однако, несмотря на точность и надежность современных методов интеллектуального анализа текстов, их широкое применение сталкивается с множеством проблем [12]. Связано это, в первую очередь, с незнанием историками хотя бы основ программирования. Большинство проектов использующих методы интеллектуального анализа текстов реализуются при помощи библиотек на языке программирования Python, реже R. Определенным выходом в такой ситуации является использование инструментов, не требующих знания программирования. Самыми известными примерами подобных бесплатных инструментов можно назвать Voyant Tools (https://voyant-tools.org/) и AntConc (http://www.laurenceanthony.net/software/antconc/).
В данной статье мы предполагаем раскрыть возможности визуальной среды анализа данных Orange 3 [https://orangedatamining.com/] по созданию конкордансов текстовых коллекций, на конкретном примере конкорданса для латиноязычного текста «О происхождении и деяниях гетов» Иордана – одно из крупнейших произведений эпохи раннего европейского средневековья. Результатом станет готовый проект, применимый к другим текстовым коллекциям.
Конкорданс – это упорядоченный список всех употреблений заданных слов (или выражений) в контексте со ссылками на источник в заданном тексте или в работах отдельных авторов [1; 13, p. 7; 14, p. 8]. Конкорданс был исторически первым вариантом текстового корпуса. В XIII веке кардиналом Гуго де Сент-Шером был составлен конкорданс к латиноязычному тексту Библии – Вульгате. Работа потребовала привлечение 500 монахов-доминиканцев. Первым конкордансом, созданным с использованием компьютерной техники, стал Index Thomisticus – конкорданс полного собрания сочинений Фомы Аквинского. Примерами современных конкордансов могут служить конкорданс произведений У. Шекспира [7], публицистики Ф. Достоевского [5], текстов М. Ломоносова [2].
Конкорданс являются эффективными инструментами изучения текста. Компьютерный конкорданс позволяет легко выявить и сравнить все контексты употребления слова, значительно повысить эффективность отбора, обработки и вывода результатов. В лингвистике конкордансы используются для решения следующих задач: 1) сравнение различных вариантов использования одного и того же слова; 2) анализ ключевых слов; 3) анализ частотности слов и словосочетаний; 4) поиск и исследование фраз и идиом; 5) поиск перевода терминологии (для двуязычных конкордансов); 6) создание списков слов при публикации [6]. Кроме того конкордансы используются при изучении языка. Для историков, как нам кажется, конкорданс полезен прежде всего основной своей функцией – способностью найти все варианты употребления того или иного слова в объемных корпусах текста, для уточнения их значений.
Для автоматического составления конкордансов существуют специальные программы – конкордансеры. В исторических исследованиях наибольшей популярностью пользуется бесплатный AntConc. Но его существенным недостатком является отсутствие морфологического анализатора. В результате он не подходит для работы с языками, отличающимися развитой морфологией. Это ограничение можно преодолеть, используя сторонние лемматизаторы [4]. Но на наш взгляд наиболее удобным способом будет использование визуальной среды анализа данных Orange 3 [8, 9]
Orange 3 – это бесплатный инструмент с открытым исходным кодом для интеллектуального анализа данных, визуализации и построения моделей машинного обучения. Orange разработан в лаборатории биоинформатики на факультете компьютерных и информационных наук Университета Любляны. Работа с Orange производится на основе графического интерфейса и не предполагает написание кода. В ходе анализа данных пользователь выстраивает так называемый рабочий процесс (англ. workflow) – последовательность шагов или действий, выполняемых над данными. Рабочий процесс создается путём манипуляций с иконками – виджетами, которые мышкой выкладываются на рабочий стол приложения. Каждый виджет представляет собой программный блок, который каким-либо образом обрабатывает поступившую на его вход информацию и передаёт её дальше для обработки, визуализации или сохранения следующим виджетом. Orange можно свободно скачать с сайта проекта (https://orangedatamining.com/). Также он входит в состав платформы для анализа данных Anaconda (https://www.anaconda.com/). В нашей работе мы использовали портативный вариант Orange версии 3.30.2.
Изначально Orange содержит пять групп виджетов для загрузки и работы с данными, визуализации, набор алгоритмов машинного обучения, кросс-валидации. Для интеллектуального анализа текстов необходимо дополнительно загрузить расширение Orange3 Text. Это расширение предоставляет доступ к публичным данным, таким как архив NY Times, Twitter, Википедия и PubMed, а также добавляет в меню виджеты для предварительной обработки текстов, построения векторных пространств, анализа текстов и визуализации.
Важной для нас особенностью Orange является то, что эта платформа позволяет работать с текстами на более чем 50 языках. Благодаря подключению к виджету Preprocess Text набора обученных моделей UDPipe [15] появилась возможность проводить предварительную обработку не только современных языков, но и латыни (3 модели), древнегреческого (2 модели), готского, коптского языков и др.
Конкорданс строился на основе латиноязычного текста памятника с сайта проекта «The Latin Library» [10]. Текст был разделен на главы, сохраненные в отдельные файлы. В системе Orange 3 был создан проект и построен рабочий процесс (рисунок).
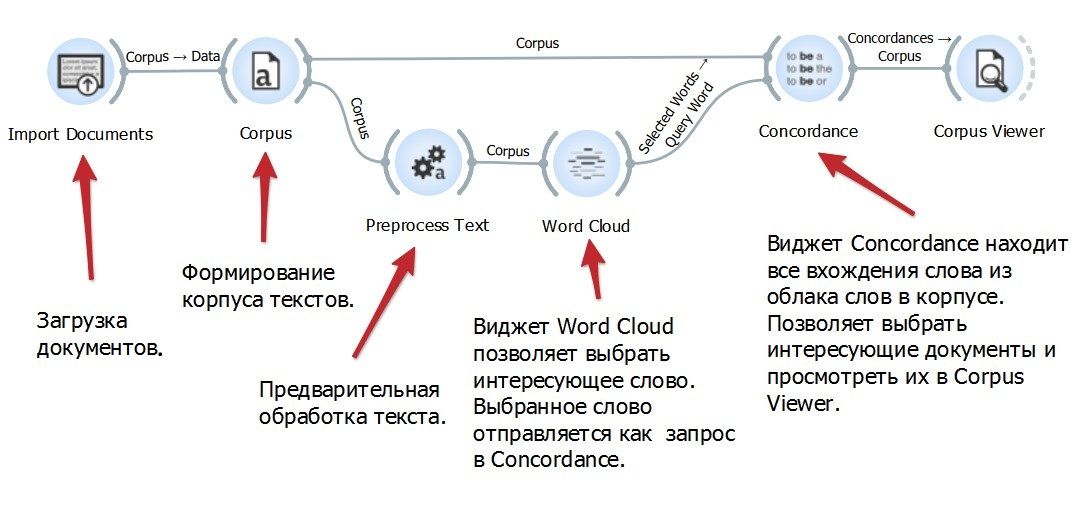
Рис. Рабочий процесс составления конкорданса в Orange 3
Файлы с главами произведения Иордана были импортированы и преобразованы в текстовый корпус. Тексты были подвергнуты предварительной обработке: буквы приведены к нижнему регистру, текст разбит на слова, слова лемматизированы, т.е. приведены к словарной форме. Виджет Word Cloud позволяет выбрать интересующее нас слово в списке передать его виджет Concordance, который выводи все контексты употребления этого слова в тексте. В итоге можно посмотреть конкретные документы с интересующим контекстом через виджет Corpus Viewer.
Все материалы проекта доступны на странице [3]. Составленный конкорданс выполняет основные исследовательские функции, подобно иным компьютерным конкордансам: позволяет составить полный список слов из корпуса текстов, определить контексты их употребления и дать ссылку на конкретные документы. Файл проекта позволяет использовать его для составления конкордансов из иных текстов. Достаточно импортировать в него интересующие тексты через виджет Import Documents. Надеемся, что он может быть полезен другим исследователям для проведения собственных изысканий.
