
Выбор движка машинного перевода и системы автоматизированного перевода CAT tool
На первом этапе работы с машинным переводом были отобраны три основных стоковых (готовых) движков машинного перевода (МП). Для тестирования была выбрана система Smartcat из-за удобства работы, настройки и анализа.
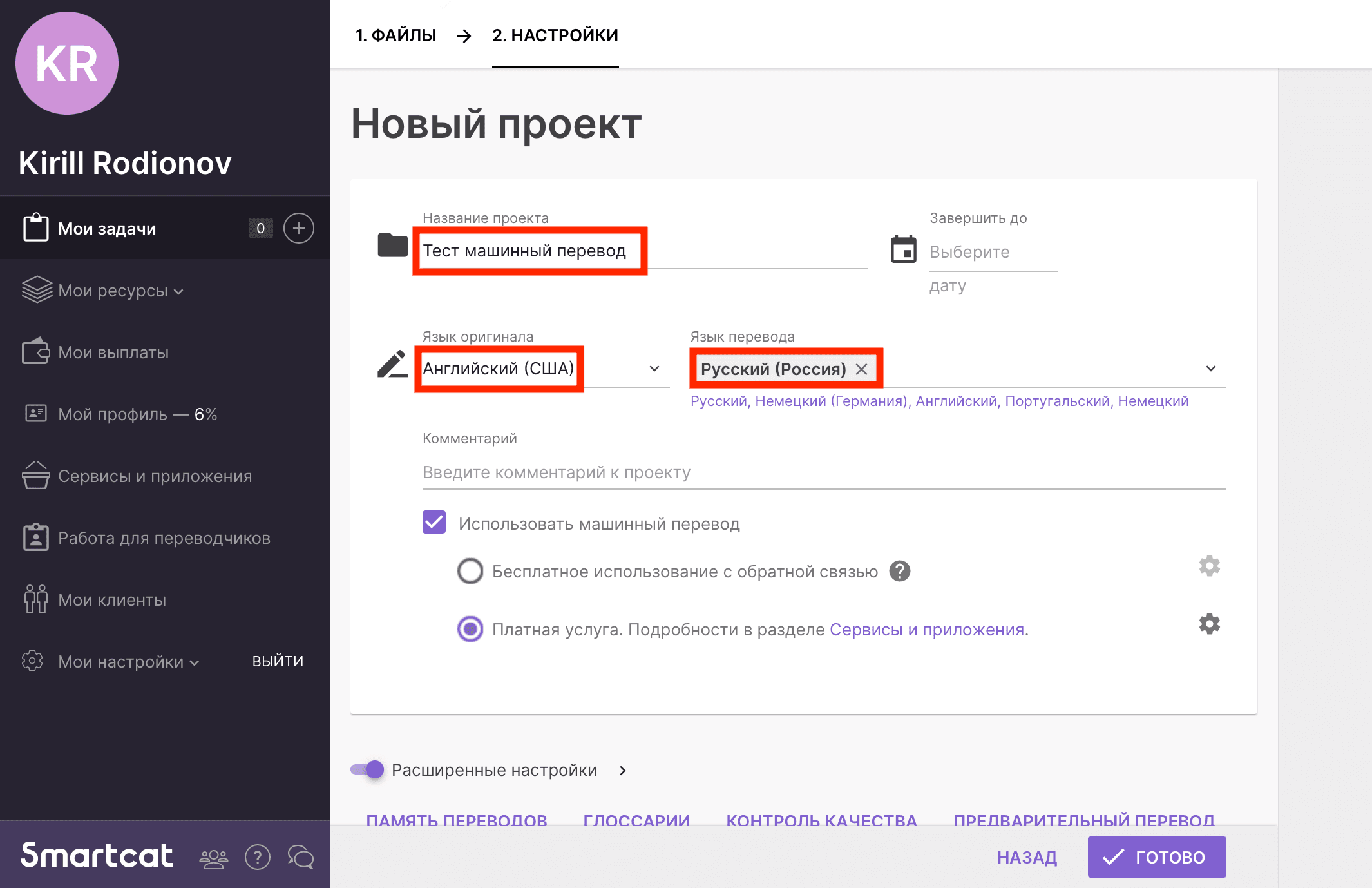
Рис. 1. Интерфейс системы Smartcat
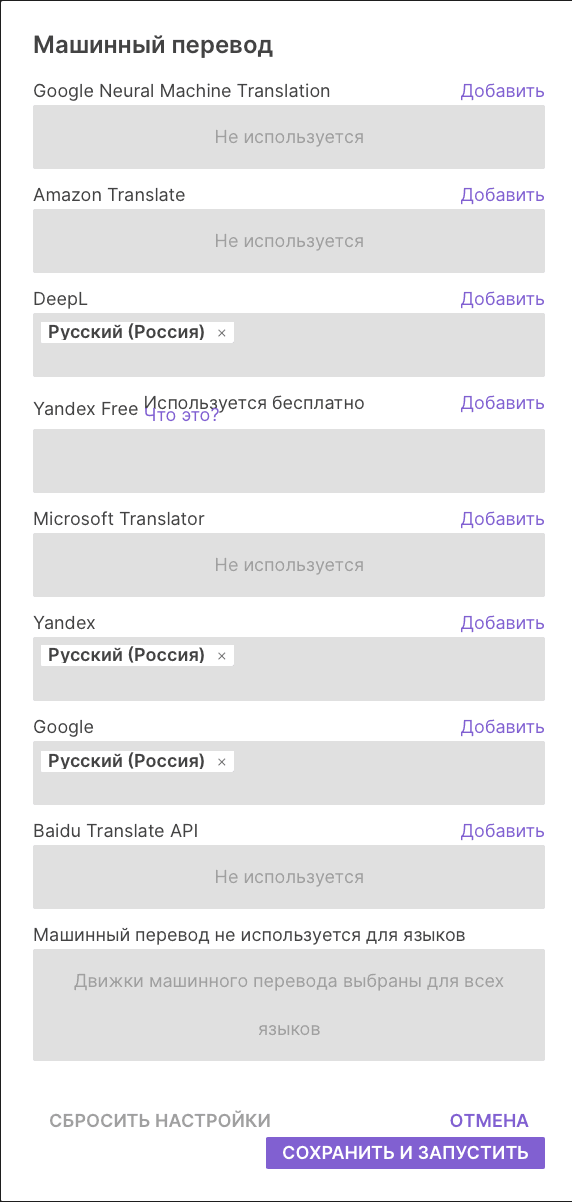
Рис. 2. Выбор движков МП в Smartcat
Согласно исследованиям аналитической компании Intento лидерами перевода в языковой паре английский-русский являются: Google и Yandex. Хорошими показателями обладает также DeepL. Данные движки МП были выбраны для дальнейшего тестирования.

Рис. 3. Исследования аналитической компании Intento
Последовательность процесса тестирования
При проведении тестирования применялась слепая оценка перевода текстов экспертами. При этом учитывалось качество текстов, переведенных человеком, машинного перевода без постредактирования и машинного перевода с постредактированием. При проведении слепой оценки выполнялись два условия: эксперты не знали о происхождении перевода и не оценивали тексты, которые сами редактировали. Такой метод позволил оценить качество машинного и человеческого перевода, провести сравнительный анализ тестируемых движков машинного перевода, отследить рост показателей качества перевода после постредактирования, а также определить среднее затраченное время на постредактирование текстов после применения каждого движка машинного перевода.
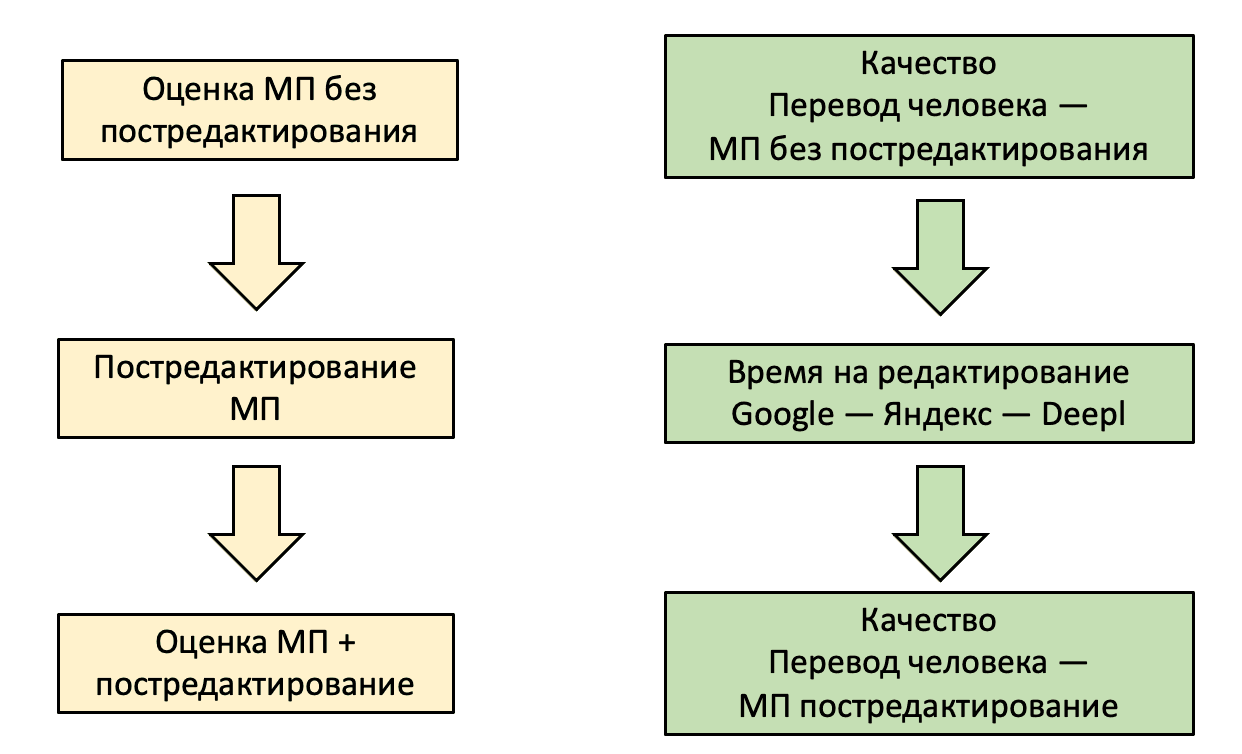
Рис. 4. Схема проведения тестирования
Выбор текстов для проведения тестирования
Для тестирования мной были отобраны 20 текстов примерно по 250 слов технической тематики в направлении русский>английский и английский>русский. Тексты состояли из длинных связных предложений с минимальным содержанием HTML тегов, так как они иногда мешают переводу (МП распознают их как разделитель предложения). Названия текстов были зашифрованы и обозначали номер текста, языковую пару, способ перевода, движок машинного перевода. Участниками проекта данная шифровка была непонятна. Исходный текст преподносился как есть, то есть без форматирования и упрощения структуры.
Исполнители
В данное исследование я пригласил десять опытных технических переводчиков. Они выполнили оценку текстов до и после постредактирования и выполнили постредактирование.
Методы и показатели оценки качества
Для данного проекта я выбрал систему оценки качества на основе концепции Quality Triangle Metrics. Данная система состоит из двух метрик целостного восприятия текста и показателя качества текста на атомарном уровне (предложения, слова). Для текстов, подразумевающих постредактирование, было решено добавить учет затраченного времени.

Рис. 5. Quality Triangle Metrics
Адекватность перевода показывает, насколько точно передан смысл исходного текста, не произошло ли в результате перевода какие-либо расхождения между исходным и целевым текстом. Адекватность оценивается по шкале от 1 до 5, где 1 – смысл исходного текста был искажен до неузнаваемости, а 5 – смысл исходного текста был сохранен полностью без каких-либо отклонений.
Удобство чтения показывает, насколько легко читать и понимать переведенный текст. Оценивается по шкале от 1 до 5, где 1 – перевод непригоден для чтения и непонятен, представляет собой бессмысленную последовательность слов, а 5 – перевод легко читается, смысл абсолютно ясен и недвусмыслен.
Учет затраченного времени редактирования показывает, сколько усилий потребовалось для постредактирования текста, чтобы сделать его пригодным для дальнейшего использования. Оценивается по шкале от 1 до 5, где 1 – постредактирование потребовало минимум усилий, а 5 – перевод должен быть полностью переписан.
Атомарное качество оценивалось по критериям ассоциации LISA, где каждая ошибка оценивается в баллах:
- Пропущенные фразы
- Добавленные фразы
- Непереведенные фразы
- Неправильная терминология
- Неправильный перевод
- Порядок слов
- Формат
- Пунктуация
- Стилистика
После оценки качества перевода экспертам было предложено определить вид перевода: перевод человеком, машинный перевод без постредактирования, машинный перевод с постредактированием.
Результаты
Целостное восприятие текста
Ниже на диаграммах представлены усредненные результаты оценки текстов по критериям целостного восприятия. Добавлю, что человеческий перевод, эксперты оценили не на 5, а в пределах 4,4–4,8 баллов. Человеческий перевод не идеален.
Также необходимо отметить, что согласно результатам выбрать лидера среди МП на основании полученных данных не удалось. Адекватность и удобность чтения текстов, переведенных с помощью МП без постредактирования, оценивается в пределах 3,4–3,8 баллов. Затратность времени на редактирование оценивается на 3–3,2 балла, что почти в два раза превышает аналогичный показатель для перевода, выполненного человеком.
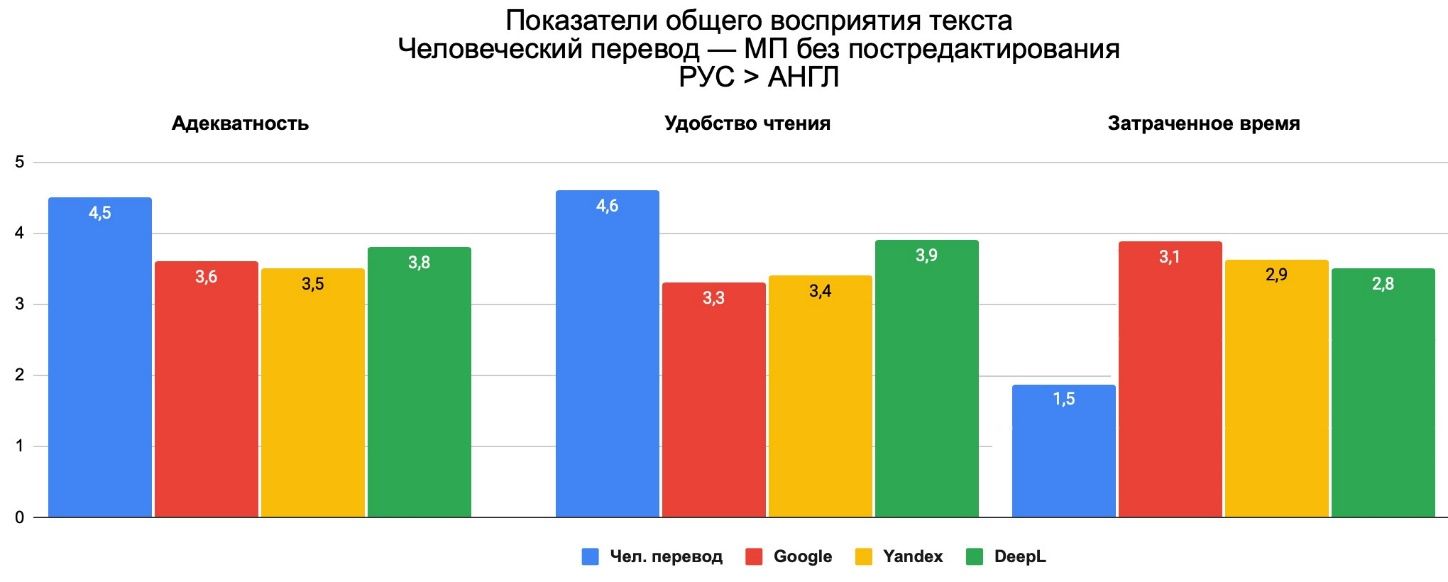 Рис. 6. Общее восприятие переведённого текста с русского на английский: человеческий перевод – машинный перевод без постредактирования
Рис. 6. Общее восприятие переведённого текста с русского на английский: человеческий перевод – машинный перевод без постредактирования

Рис. 7. Общее восприятие переведённого текста с английского на русский: человеческий перевод – машинный перевод без постредактирования
Постредактирование значительно повлияло на адекватность и удобство читаемости. Ниже показано, что показатели выросли до 4,0–4,6, что практически соответствует показателям перевода человеком. Затраченное время на редактирование при этом сократилось почти в два раза, достигнув диапазона значений 1,3–2. Таким образом переводы, выполненные с помощью МП с постредактированием, становятся близки к человеческому переводу. Благодаря постредактированию качество почти поднялось до уровня перевода с нуля профессиональным переводчиком.
Данные тенденции распространяются на все движки МП, что снова не позволяет определить лидера.
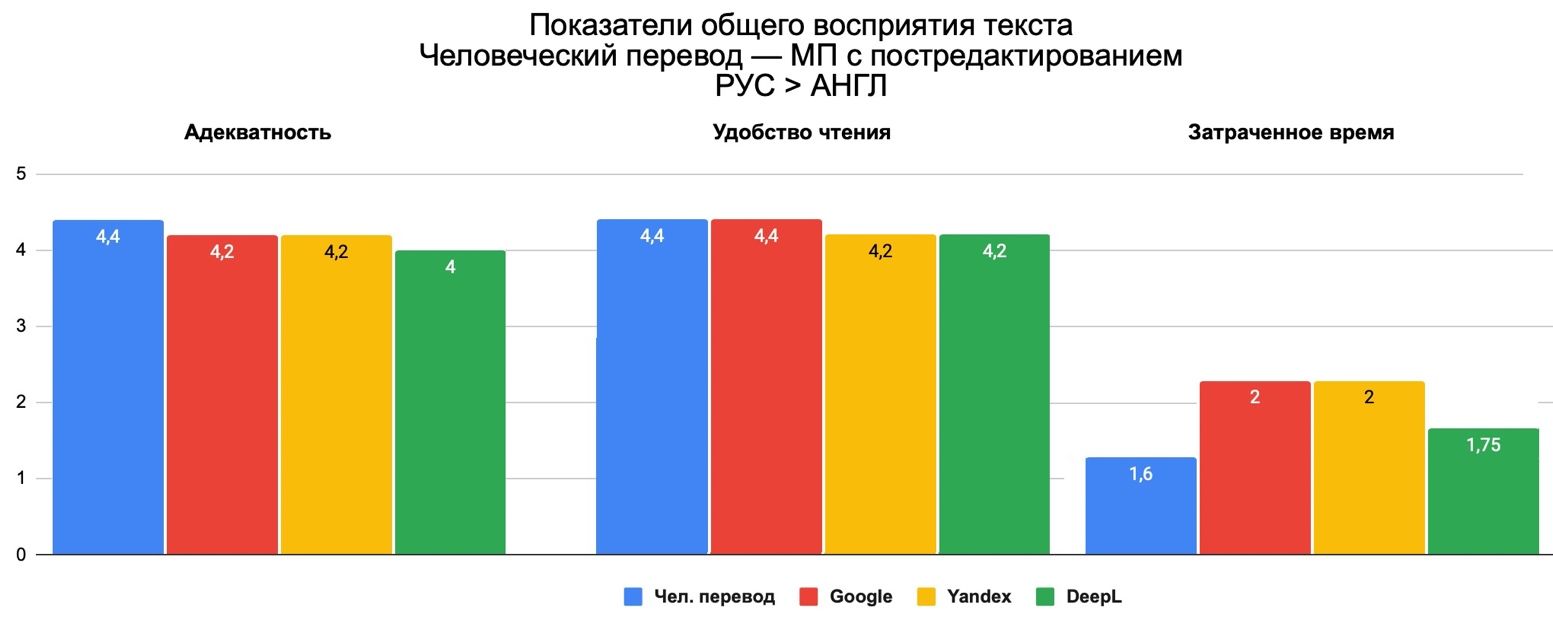 Рис. 8. Общее восприятие переведённого текста с русского на английский: человеческий перевод – машинный перевод с постредактированием
Рис. 8. Общее восприятие переведённого текста с русского на английский: человеческий перевод – машинный перевод с постредактированием
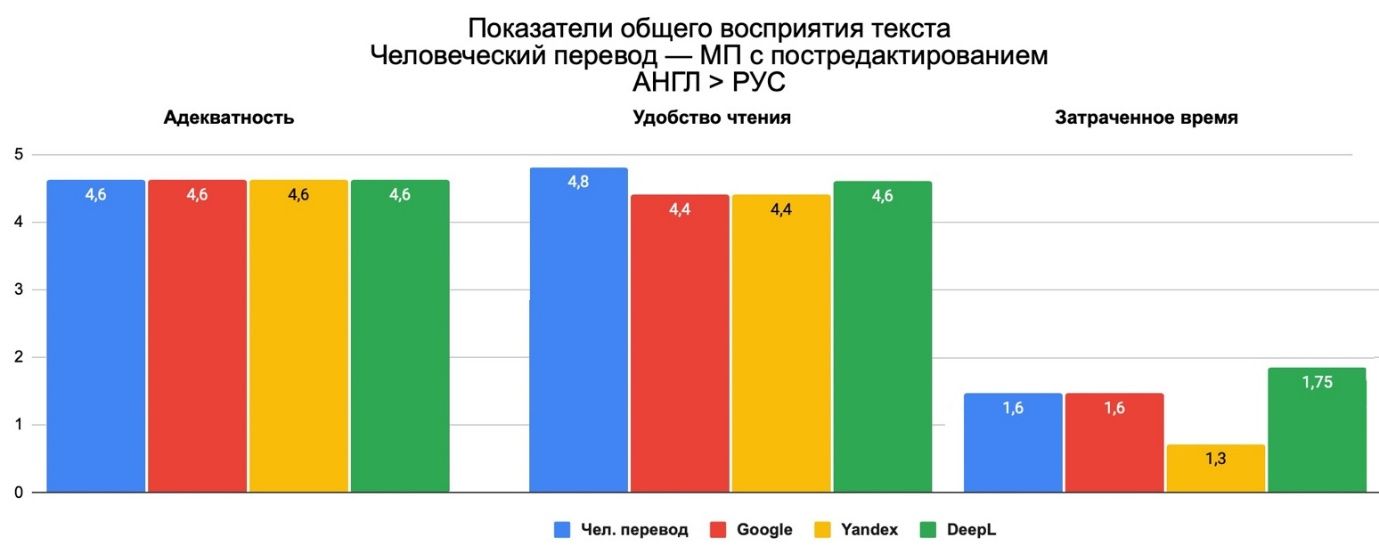
Рис. 9. Общее восприятие переведённого текста с английского на русский: человеческий перевод – машинный перевод без постредактирования
Определение происхождения перевода
Экспертам было предложено определить происхождение оцениваемого перевода, исходя из собственных ощущений. Только 40% экспертов смогли точно определить текст, переведенный человеком. В остальных случаях эксперты ошиблись.
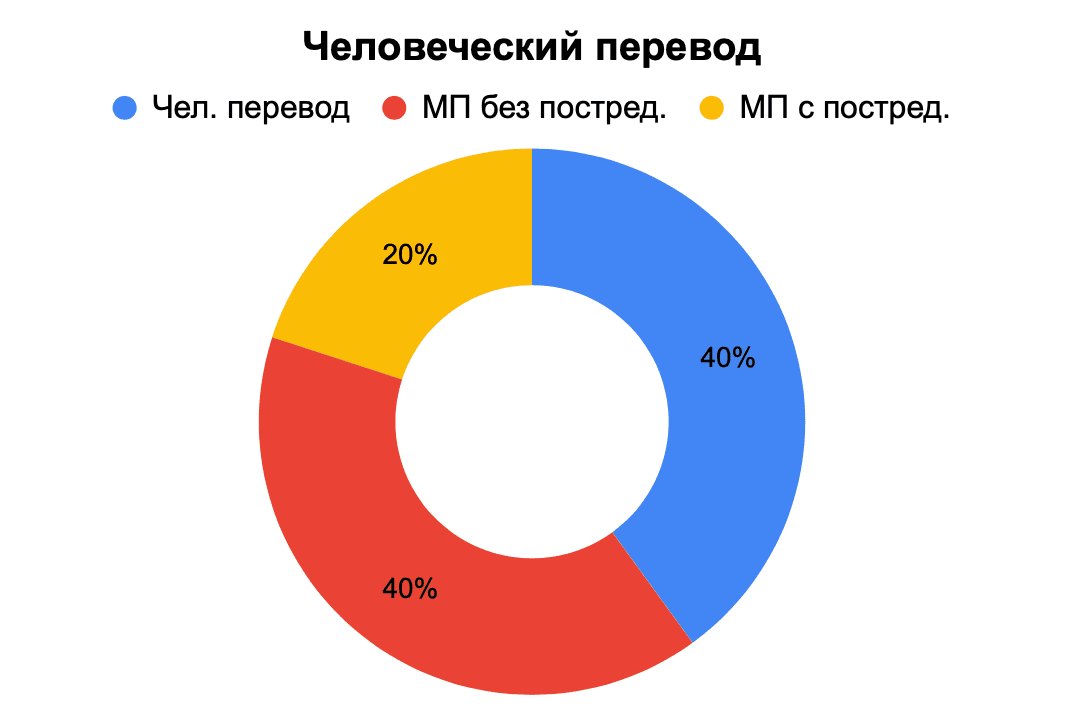
Рис. 10. Определение происхождения перевода – человеческий перевод
Но машинный перевод без редактирования они смогли определить правильно.
Интересные результаты получились при оценке экспертами редактированного машинного перевода. Google с постредактированием определили как профессиональный человеческий перевод 6 экспертов из 10, Yandex и DeepL – 3 из 10.

Рис. 11. Определение происхождения перевода – Google
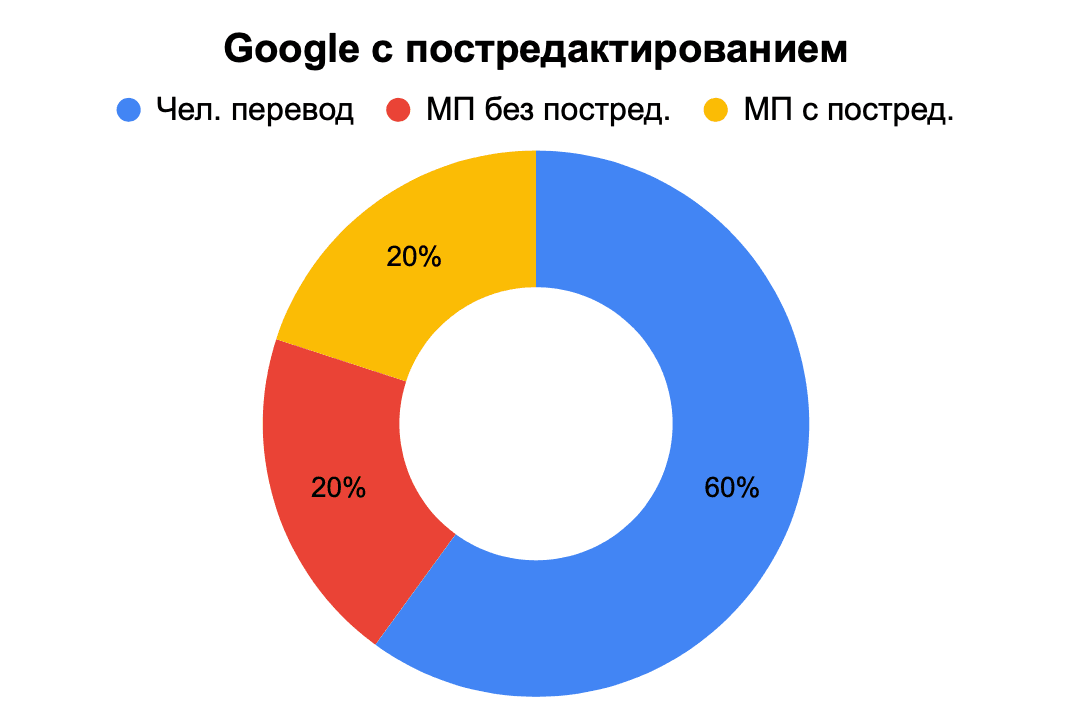
Рис. 12. Определение происхождения перевода – Google c постредактированием
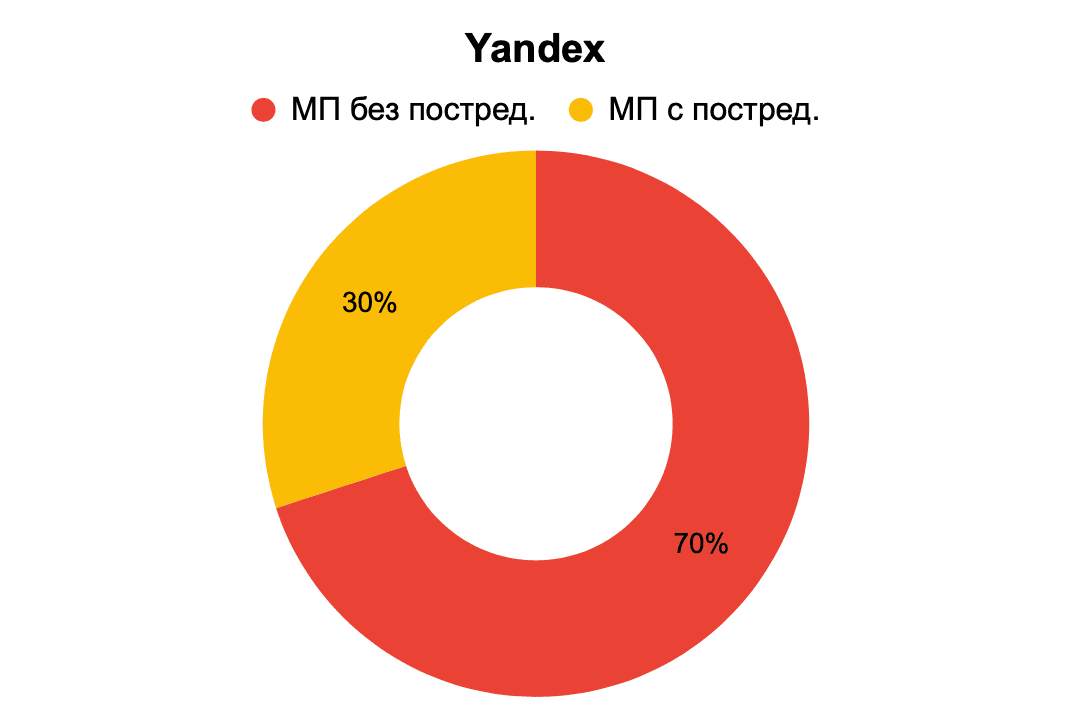
Рис. 13. Определение происхождения перевода – Yandex

Рис. 14. Определение происхождения перевода – Yandex c постредактированием
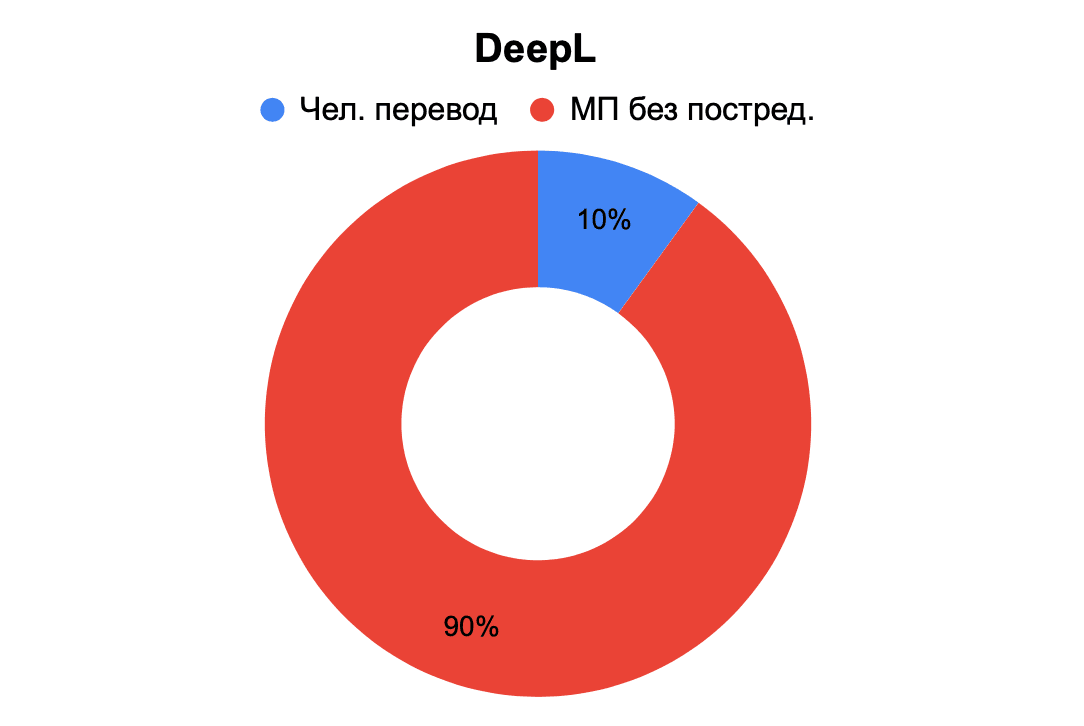
Рис. 15. Определение происхождения перевода – DeepL
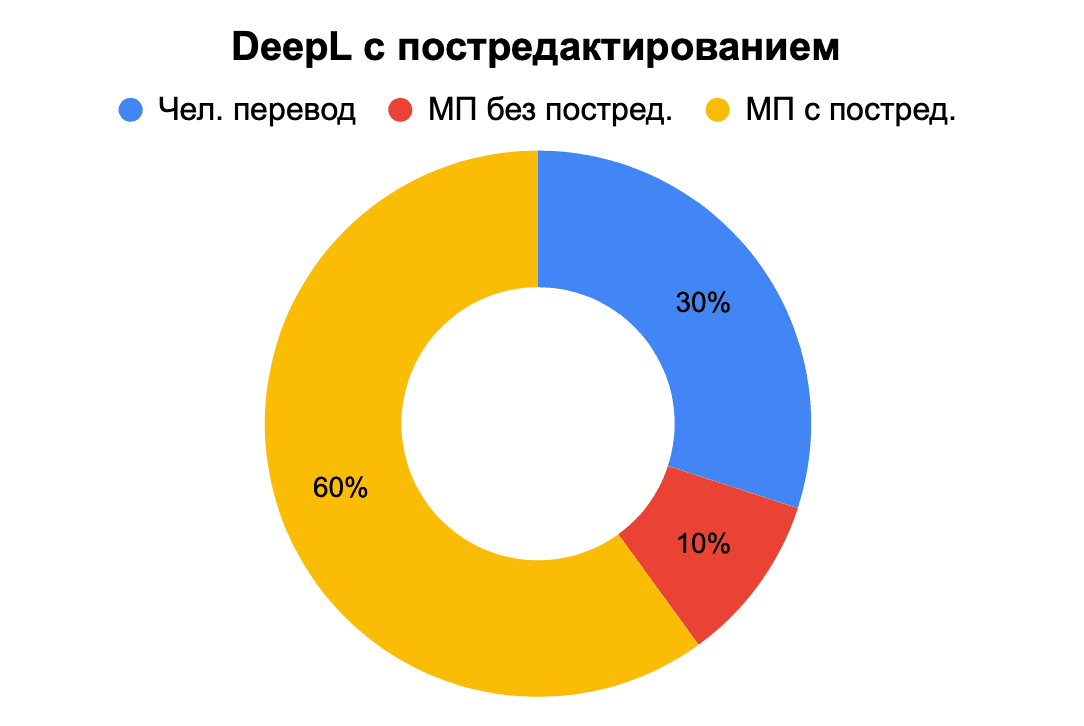
Рис. 16. Определение происхождения перевода – DeepL c постредактированием
Качество на атомарном уровне
В человеческих переводах встречалось меньше всего ошибок. Отсюда можно сделать вывод о высоком показателе атомарного качества таких текстов. Кроме того ошибки каждого типа встречались в 2-5 переводах каждого МП движка. Исключение составили пропущенные и добавленные понятия, а также пунктуация (в одном тексте Yandex и в одном – DeepL). Показатели атомарного качества текста одинаково низкие для всех тестируемых движках МП. Однозначно определить лидера по данному критерию оказалось снова невозможным.
В текстах МП с постредактированием показатели атомарного качества текста значительно лучше, но терминологические ошибки и неверный перевод понятий все равно присутствовали в текстах всех движков МП.
Наиболее частотные типы ошибок указаны ниже.

Рис. 17. Типы ошибок МП и их встречаемость в тексте
Причиной высокой частотности терминологических ошибок и ошибок неверного перевода стало использование стоковых движков МП. Такие движки обучаются на текстах общей тематики и переводят специализированные тексты без учета отраслевых норм, стандартов и контекста сферы.
|
Оригинал |
МП |
Верный термин |
|---|---|---|
|
server |
официант |
сервер |
|
single |
холостяк |
одиночный |
|
bearing |
отношение |
подшипник |
|
drive |
драйв |
привод |
|
work pressure |
рабочее давление |
требования к персоналу |
|
vessel |
судно |
сосуд |
|
clear solution |
ясное решение |
прозрачный раствор |
В переведенных текстах также часто встречались ошибки форматирования (отсутствовал курсив, неправильный буквенный регистр, несоблюдение формата подстрочных/надстрочных знаков, лишние пробелы, разные кавычки).
|
Оригинал |
МП |
|---|---|
|
The TLS70 has an Enable/Disable switch |
На TLS70 есть переключатель Enable/Disable. |
|
Adjusting switch B1 |
Регулировочный переключатель B1 |
|
Период полувыведения (Т1/2) из плазмы составляет 2-3 часа. |
The half-life (T1/2) of plasma is 2-3 hours. |
|
Wind speed is over 20 m/s. |
Cкорость ветра более 20 м / с. |
|
см. раздел «Настройка датчика поворота» |
see «rotating sensor adjustment» |
|
By moving the joystick forward... |
При перемещении джойстика вперед... |
Объем работы и затраченное время на постредактирование оказались неожиданно большими. Связано это с недостаточным опытом экспертов в работе с МП. Эксперты старались сделать из машинного перевода максимально приближенный к человеческому. То же касалось и оценки атомарного качества перевода: эксперты отмечали ошибки, допустимые для машинного перевода, например, незначительное нарушение порядка слов, пропущенные слова, которые не влияли на смысл высказывания и так далее. То есть было оказано излишнее внимание к мелочам.
Выводы
- Машинный перевод определенно стоит использовать в проектах с низким требованием к качеству (внутренняя документация, перевод «для понимания» и т.д.) и с минимальными сроками выполнения работы.
- На начальном этапе внедрения машинного перевода можно выбрать любой стоковый движок, так как оказалось, что большой разницы в показателях качества МП движков-кандидатов нет. После успешного внедрения и проведения аналитики необходимо перейти к обучению движка.
- Самая частая проблема машинного перевода – несоблюдение терминологии и отраслевой специфики, что является вполне ожидаемым результатом для стоковых «универсальных» движков МП, переводящих технические тексты.
- Недостаточный опыт постредакторов приводит к лишним правкам, что сокращает выгоду применения МП. При внедрении МП необходимо разработать и внедрить обучающий курс для исполнителей.
Как можно улучшить тестирование?
- При выборе исполнителей делать упор не на экспертизу в определенной сфере (в данном случае – технический перевод), а на опыт работы с машинным переводом.
- При оценке атомарного качества текста присваивать коэффициент. Он может варьироваться в зависимости от тематики. Например, в технической документации стилистические ошибки не так критичны, как в маркетинговых текстах. Такой подход существенно упростит анализ результатов.
- При возможности разбить тематику на подтематики и подобрать достаточное количество текстов по каждой. Таким образом будут учтены особенности языкового оформления текстов для каждого узкого направления. В итоге появится понимание о возможностях движков МП и их применимости к переводу различных текстов интересующей нас тематики.
- При тестировании использовать один текст, разделенный на несколько одинаковых отрывков. Это сделает полученные данные более надежными, а структурные и/или языковые различия текстов будут минимально влиять на показатели качества перевода будет минимизировано.
