
Choice of machine translation engine and CAT tool
For the first stage of work with machine translation, three main stock (ready-made) machine translation (MT) engines were selected. The Smartcat system was chosen for testing due to its ease of use, configuration, and analysis.

Fig. 1. Smartcat interface systems
Fig. 2. Selecting MT engines in Smartcat
According to research by the analytics company Intento, the translation leaders for the English-Russian language pair are: Google and Yandex. DeepL also has good performance. These MT engines were selected for further testing.
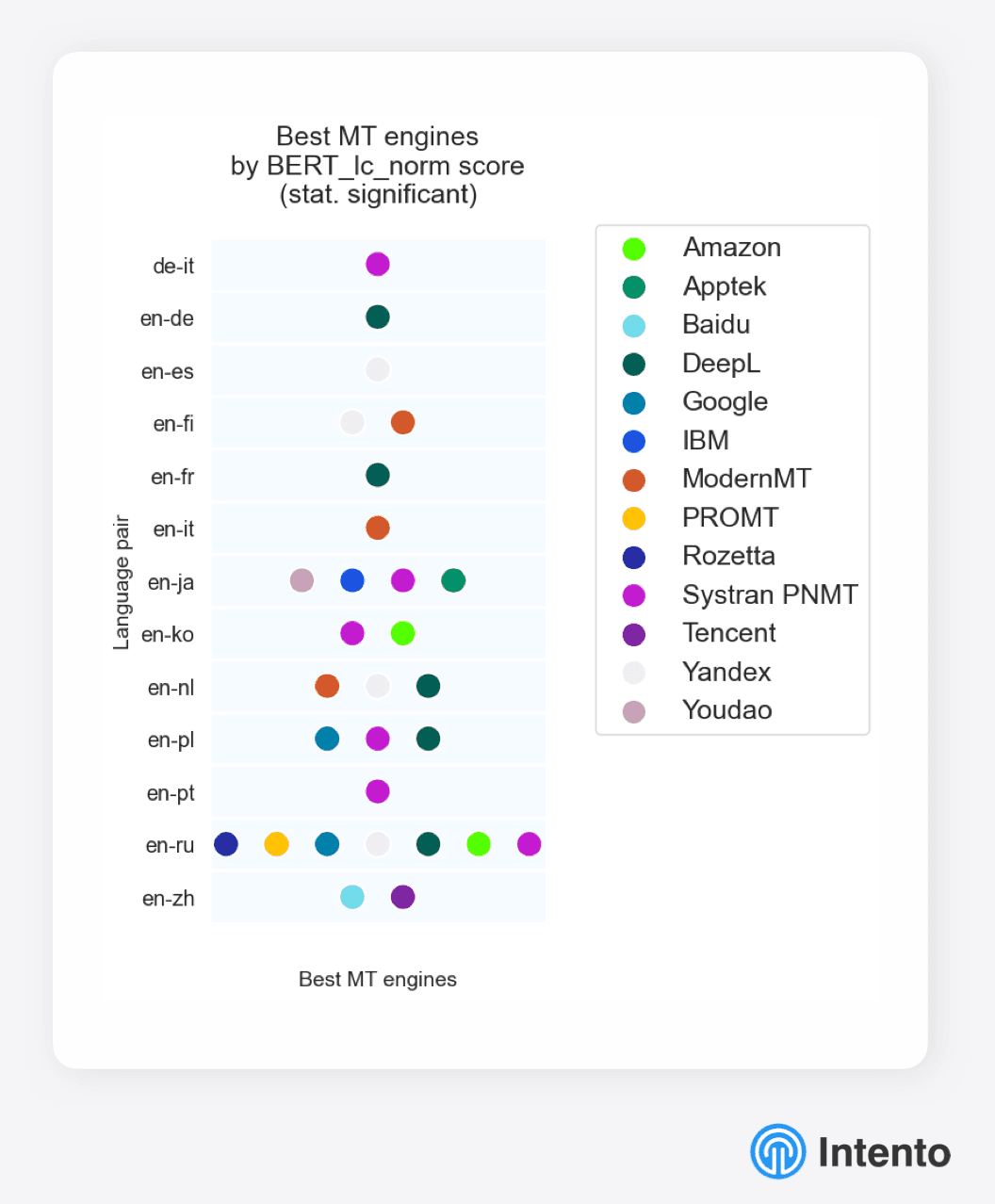
Fig. 3. Research by the analytics company Intento
Sequence of the testing process
When testing, a blind assessment of the translation of texts by experts was made. Additionally, the quality of human-translated texts, machine translation without post-editing, and machine translation with post-editing was taken into account. During the blind evaluation, two conditions were met: the experts did not know about the origin of the translation and did not evaluate the texts that they themselves edited. This method made it possible to evaluate the quality of machine and human translation, conduct a comparative analysis of the tested machine translation engines, track the growth of translation quality indicators after post-editing, and determine the average time spent post-editing texts after using each machine translation engine.
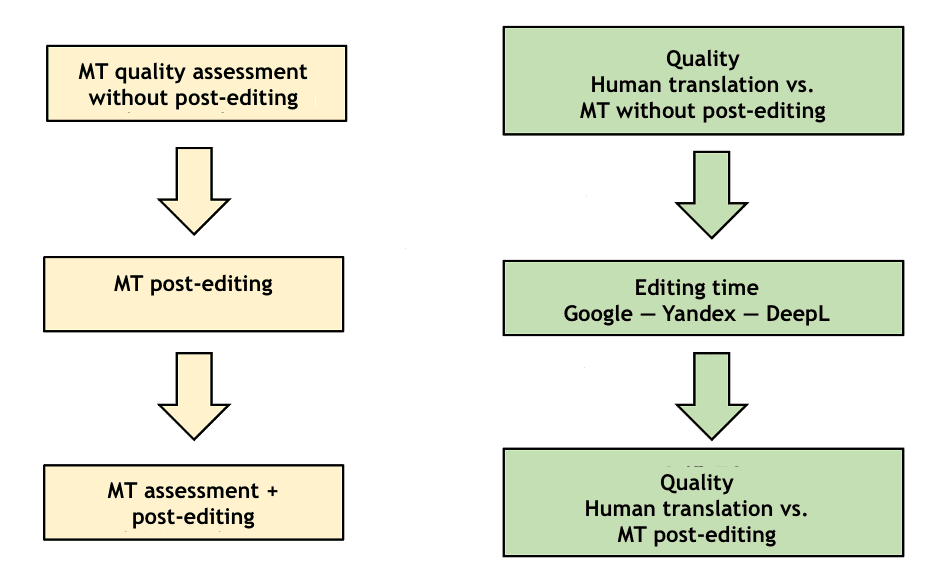
Fig. 4. Test scheme
Selection of texts for testing
For testing, I selected 20 texts, consisting of approximately 250 words, in the direction of Russian>English and English>Russian. The texts consisted of long connected sentences with minimal HTML tags, as they sometimes get in the way of translation (MT recognizes them as sentence separators). The titles of the texts were encrypted and denoted the number of the text, the language pair, the translation method, and the machine translation engine. The project participants did not understand this encryption. The source text was presented as-is, that is, without formatting and simplified structure.
Performers
In this study, I invited ten experienced technical translators. They evaluated the texts before and after post-editing and performed post-editing.
Methods and indicators of quality assessment
For this project, I chose a quality assessment system based on the concept of Quality Triangle Metrics. This system consists of two metrics for the holistic perception of the text and an indicator of the quality of the text at the atomic level (sentences, words). For texts that require post-editing, it was determined that time tracking would be added.
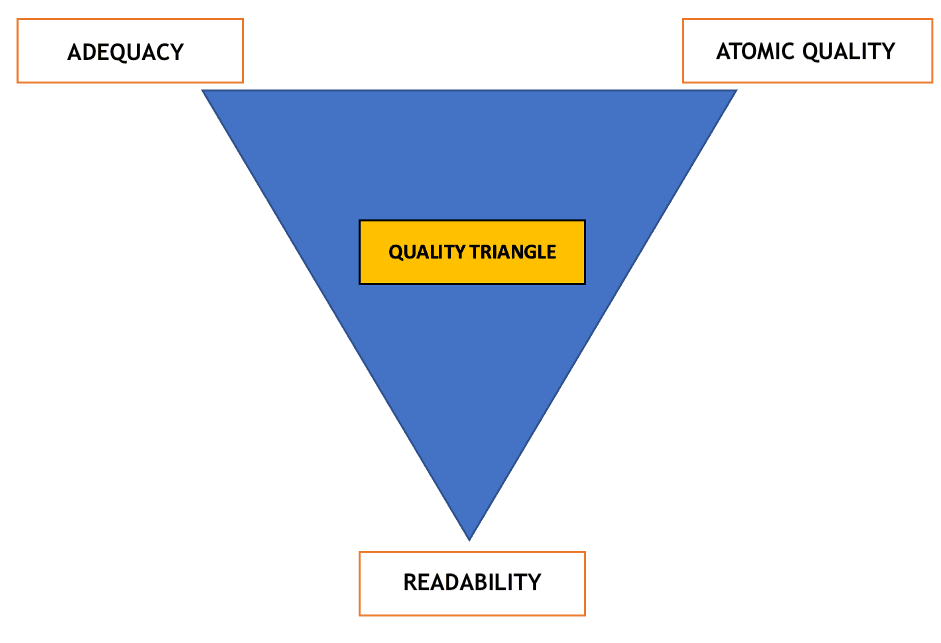
Fig. 5. Quality Triangle Metrics
The adequacy of the translation shows how accurately the meaning of the source text is conveyed and whether there were any discrepancies between the source and target text as a result of the translation. Adequacy is assessed on a scale from 1 to 5, where 1 indicates that the meaning of the original text was distorted beyond recognition and 5 indicates that the meaning of the original text was completely preserved without any deviations from the source text.
Readability refers to how easy it is to read and understand the translated text. It is scored on a scale of 1 to 5, with 1 meaning the translation is unreadable and incomprehensible and is a meaningless sequence of words, while 5 means the translation is easy to read, with the meaning being absolutely clear and unambiguous.
Editing time records show how much effort was required to post-edit the text to make it usable. It is rated on a scale of 1 to 5, where 1 means post-editing required minimal effort and 5 means the translation needs to be completely rewritten.
Atomic quality was assessed according to the LISA association criteria, where each error is scored:
- Missing phrases
- Added phrases
- Untranslated phrases
- Wrong terminology
- Wrong translation
- Word order
- Format
- Punctuation
- Stylistics
After assessing the quality of the translation, the experts were asked to determine the type of translation: human translation, machine translation without post-editing, or machine translation with post-editing.
Results
Holistic perception of the text
The diagrams below show the averaged results from the evaluation of the texts according to the criteria of holistic perception. I will add that the experts did not rate the human translation as 5, but between 4.4–4.8 points. Human translation is not perfect.
I also want to note that, according to the results, it was not possible to choose a leader among the SEs based on the data received. The adequacy and readability of texts translated with the help of MT without post-editing is estimated at 3.4–3.8. Editing time is estimated at 3-3.2, which is almost twice as much as for human translation.
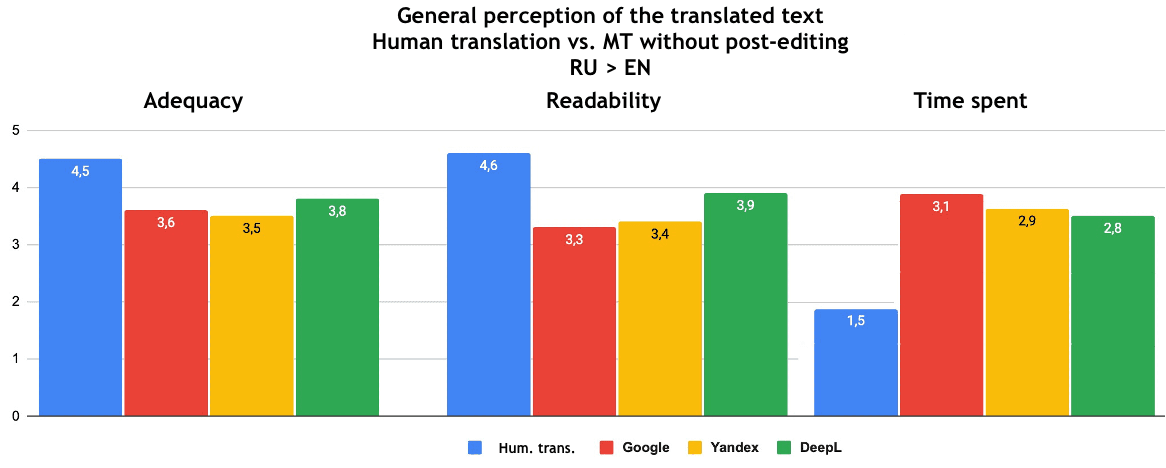 Fig. 6. General perception of the translated text from Russian into English: human translation - machine translation without post-editing
Fig. 6. General perception of the translated text from Russian into English: human translation - machine translation without post-editing
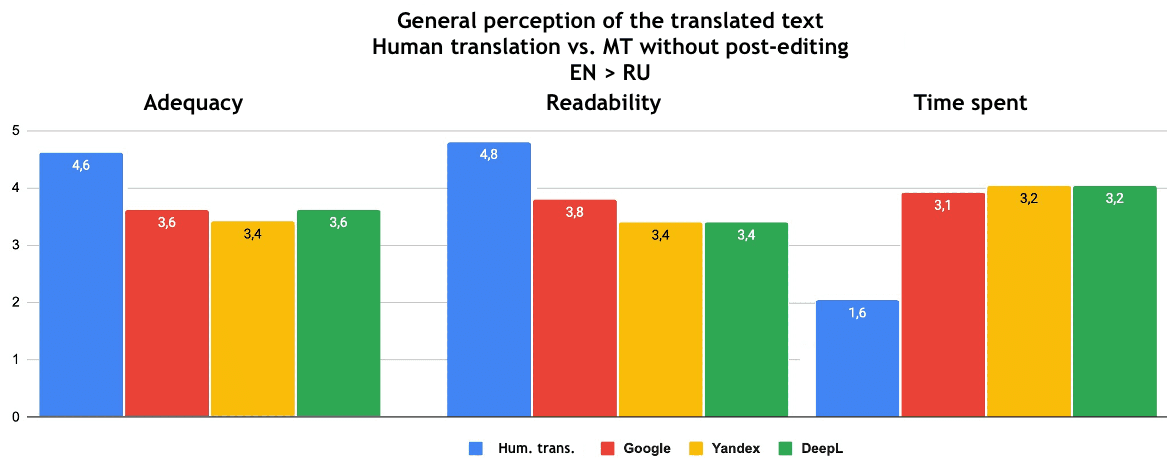
Fig. 7. General perception of the translated text from English to Russian: human translation - machine translation without post-editing
Post-editing significantly affected adequacy and readability. The graphs below show that the scores rose to 4.0-4.6, which is close to human translation scores. At the same time, the time spent on editing was almost halved, reaching the range of 1.3–2. Thus, the scores for translations made with MT with post-editing are close to those for human translation. Thanks to post-editing, the quality almost reaches the level of translations performed from scratch by a professional translator.
These trends apply to all MT engines, which again does not allow us to determine the leader.
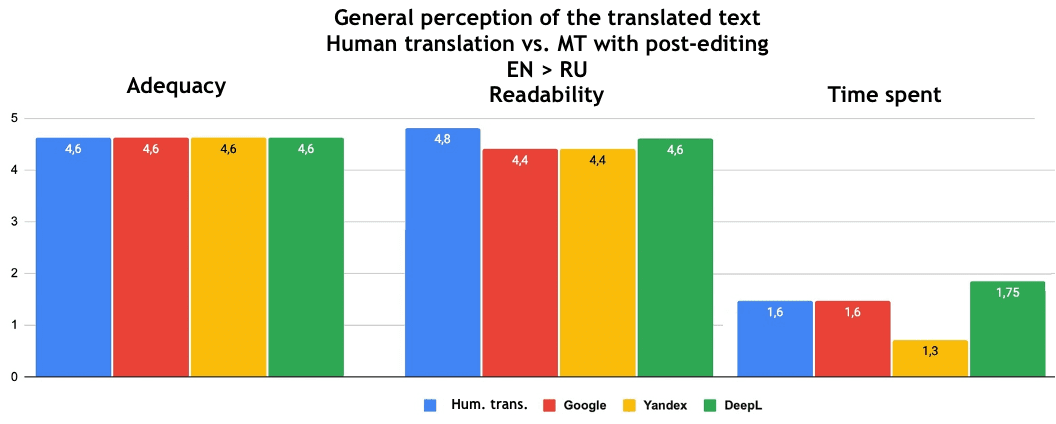 Fig. 8. General perception of the translated text from Russian into English: human translation - machine translation with post-editing
Fig. 8. General perception of the translated text from Russian into English: human translation - machine translation with post-editing
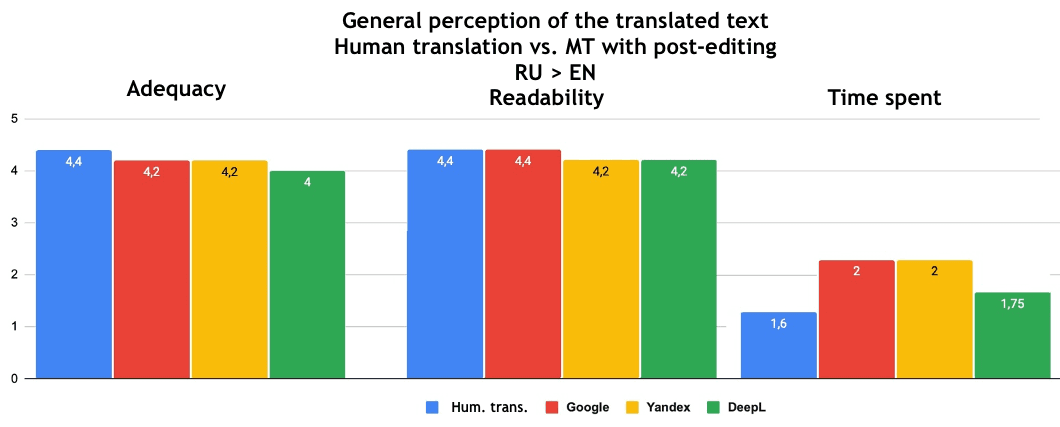
Fig. 9. General perception of the translated text from English to Russian: human translation - machine translation with post-editing
Determining the origin of a translation
The experts were asked to determine the origin of the evaluated translation based on their own impressions. Only 40% of the experts were able to accurately identify the human-translated text. In other cases, the experts were wrong.

Fig. 10. Determining the origin of a translation – human translation
However, they were able to correctly identify machine translation without editing.
Interesting results were obtained when the experts evaluated the edited machine translation. Google with post-editing was defined as a professional human translation by 6 experts out of 10, and for Yandex and DeepL - 3 out of 10.
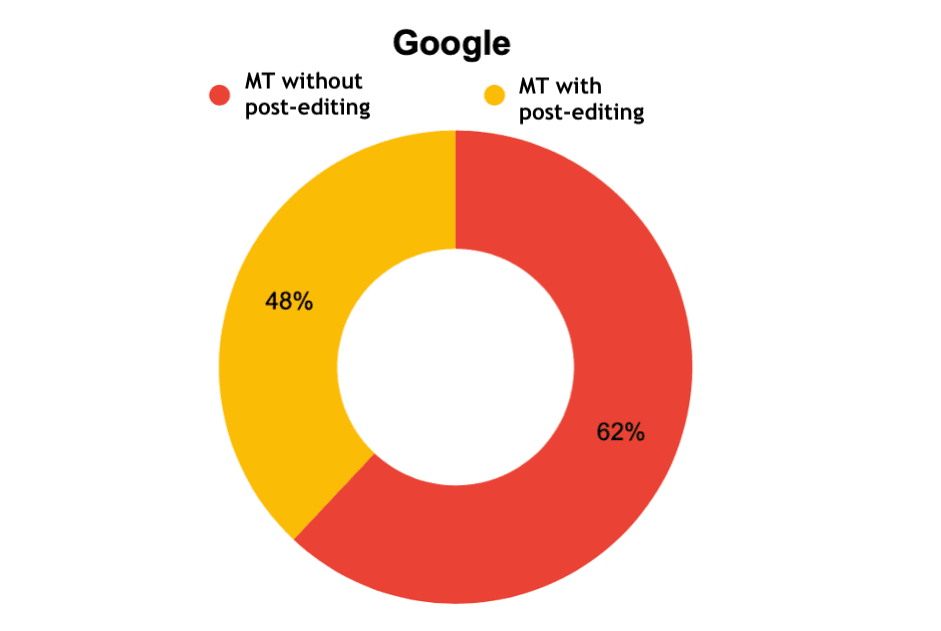
Fig. 11. Determining the origin of a translation – Google
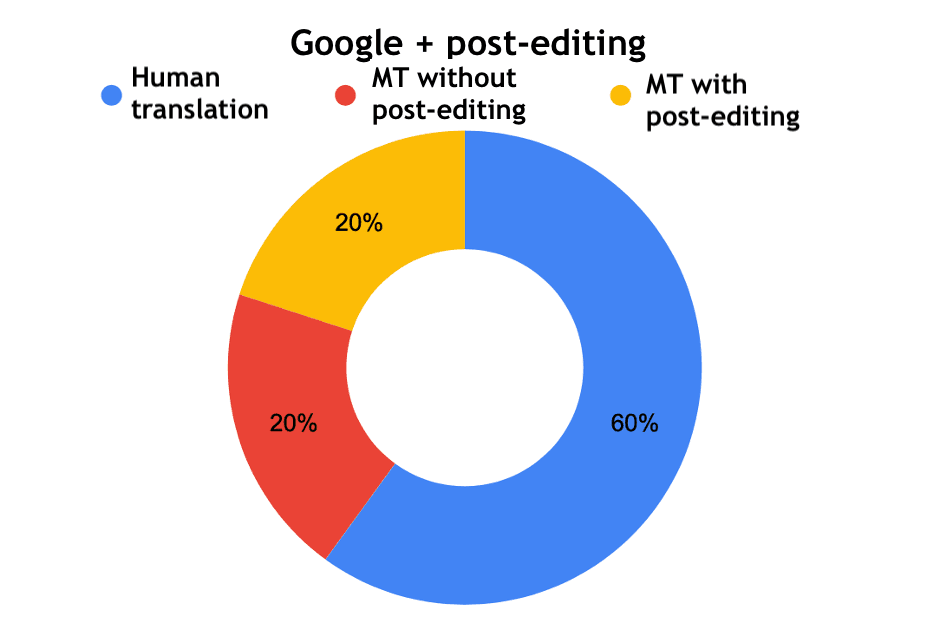
Fig. 12. Determining the origin of a translation - Google with post-editing

Fig. 13. Determination of the origin of the translation – Yandex
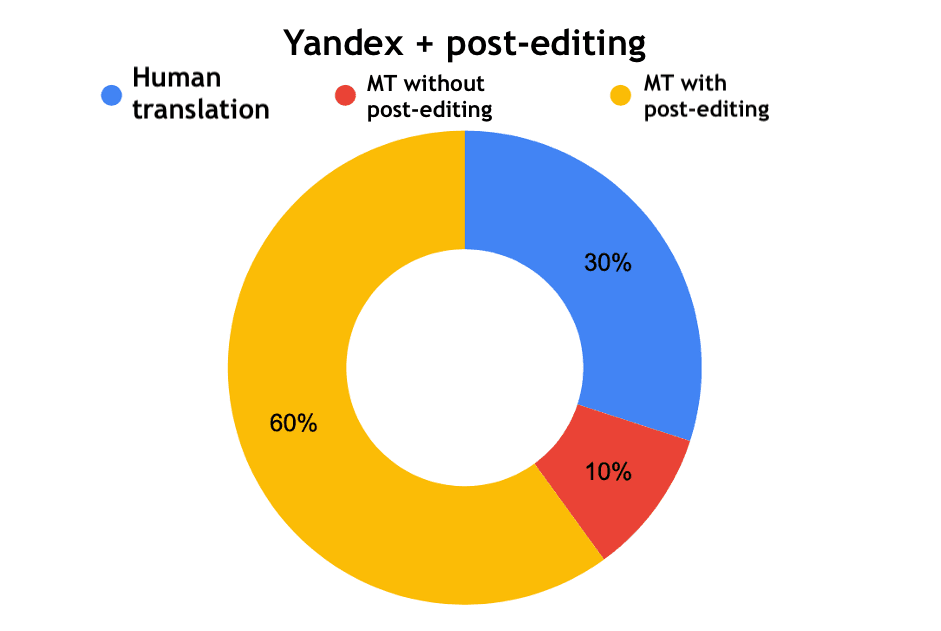
Fig. 14. Determination of the origin of the translation - Yandex with post-editing

Fig. 15. Determination of the origin of a translation – DeepL
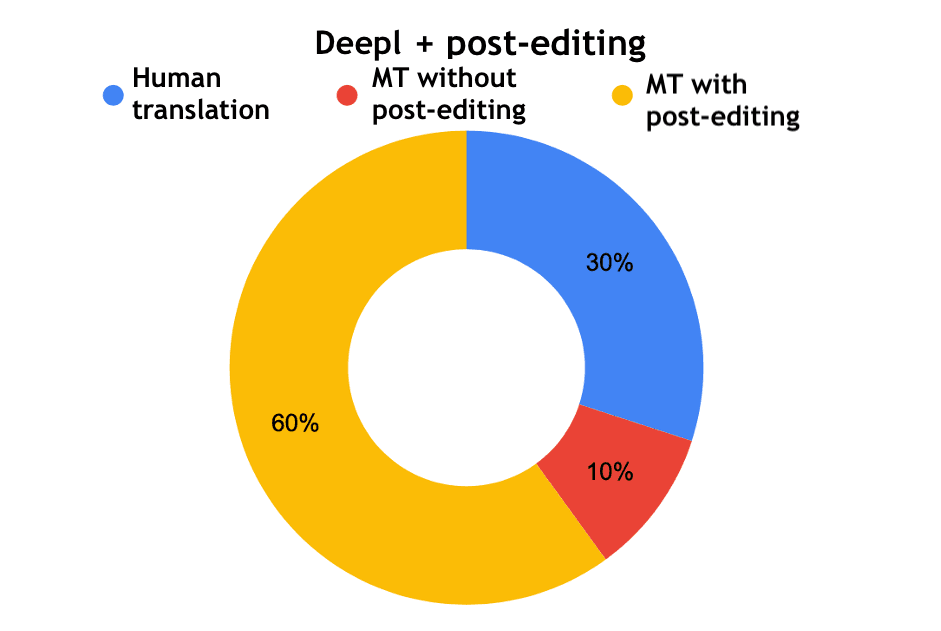
Fig. 16. Determination of the origin of a translation - DeepL with post-editing
Quality at the atomic level
Human translations had the fewest errors. From this we can conclude that the atomic quality of such texts is high. In addition, errors of each type were encountered in 2-5 translations from each MT engine. The exception was missing and added concepts, as well as punctuation (in one Yandex text and in one DeepL text). Text atomic quality indicators are equally low for all tested MT engines. It turned out to be impossible to unequivocally determine the leader according to this criterion.
In MT texts with post-editing, the indicators of atomic quality of the text are much better, but terminological errors and incorrect translation of concepts were still present in the texts from all MT engines.
The most common types of errors are listed below.

Fig. 17. Types of MT errors and their occurrence in the text
The reason for the high frequency of terminological errors and mistranslation errors was the use of stock MT engines. Such engines are trained on texts of a general subject and translate specialized texts without taking into account industry norms, standards, and the context.
|
Original |
MP |
Correct term |
|---|---|---|
|
server |
waiter |
server |
|
single |
bachelor |
single |
|
bearing |
attitude |
bearing |
|
drive |
drive |
drive unit |
|
work pressure |
operating pressure |
personnel requirements |
|
vessel |
vessel |
vessel |
|
clear solution |
clear decision |
clear solution |
The translated texts also often had formatting errors (missing italics, incorrect letter case, non-observance of the subscript/superscript format, extra spaces, different quotation marks).
|
Original |
MP |
|---|---|
|
The TLS70 has an Enable/Disable switch |
The TLS70 has an Enable/Disable switch . |
|
Adjusting switch B 1 |
Control switch B 1 |
|
The elimination half-life (T 1/2 ) from plasma is 2-3 hours. |
The half-life ( T1/2 ) of plasma is 2-3 hours. |
|
Wind speed is over 20 m/s. |
C wind speed over 20 m / s . |
|
see section “Setting the turn sensor” |
see " rotating sensor adjustment " |
|
By moving the joystick... |
When moving the joystick forward... |
The amount of work and post-editing time was unexpectedly high. This is due to the lack of experience of experts in working with MPs. Experts tried to make machine translation as close to human translation as possible. The same applied to the evaluation of the atomic quality of the translation: experts noted errors that are acceptable for machine translation, for example, a slight violation of the word order, missing words that did not affect the meaning of the statement, and so on. That is, excessive attention to detail was provided.
Conclusions
- Machine translation is definitely worth using for projects with low quality requirements (internal documentation, “for understanding” translation, etc.) and with minimal turnaround times.
- At the initial stage of the implementation of machine translation, it is possible to choose any stock engine, as it turned out that there is no significant difference in the quality indicators for the MT of the candidate engines. After successful implementation and analytics, it is necessary to move on to training the engine.
- The most common problem in machine translation is terminology and industry specifics, which is an entirely expected result for stock "universal" MT engines translating technical texts.
- Insufficient experience of post-editors leads to redundant edits, which reduces the benefit of using MT. When introducing MT, it is necessary to develop and implement a training course for editors.
How can testing be improved?
- When choosing editors, focus not on expertise in a particular area (in this case, technical translation), but on experience working with machine translation.
- When evaluating the atomic quality of the text, assign a coefficient. It may vary depending on the subject. For example, in technical documentation, stylistic errors are not as critical as they are in marketing texts. This approach will greatly simplify the analysis of the results.
- If possible, break the topic into subtopics and select a sufficient number of texts for each. Thus, the peculiarities of the language design of texts for each narrow direction will be taken into account. As a result, there will be an understanding of the capabilities of MT engines and their applicability to the translation of various texts on topics of interest to us.
- When testing, use one text divided into several identical passages. This will make the received data more reliable, and the structural and/or linguistic differences of the texts will have a minimal impact on the translation quality indicators.
