
В прошлом распознавание лица в основном включало в себя технологии и системы, такие как получение изображения лица, предварительная обработка распознавания лица, подтверждение личности и поиск личности. Распознавание лиц теперь постепенно распространяется на обнаружение водителя, отслеживание пешеходов и даже динамическое отслеживание объектов в ADAS (Advanced Driver Assistance Systems).
Одной из основных задач компьютерного зрения является автоматическое обнаружение объекта без вмешательства человека. Например, определение человеческих лиц на изображении.
Лица людей отличаются друг от друга. Но в целом можно сказать, что всем им присущи определенные общие черты.
Существует много алгоритмов обнаружения лиц. Одним из старейших является алгоритм Виолы-Джонса. Он был предложен в 2001 году и применяется по сей день.
В настоящее время существуют различные пакеты для выполнения задач машинного обучения, глубокого обучения и компьютерного зрения. Например, OpenCV. OpenCV – это библиотека с открытым программным кодом. Она поддерживает различные языки программирования, например R и Python. Работать она может на многих платформах, в частности – на Windows, Linux и MacOS.
Надо отметить, что система распознавания лиц Python уже давно является открытым исходным кодом, а уровень распознавания в автономном режиме составляет более 99%!
Существует достаточно большое количество алгоритмов распознавания лиц но несмотря на разнообразие алгоритмов, можно выделить общую структуру процесса распознавания лиц:
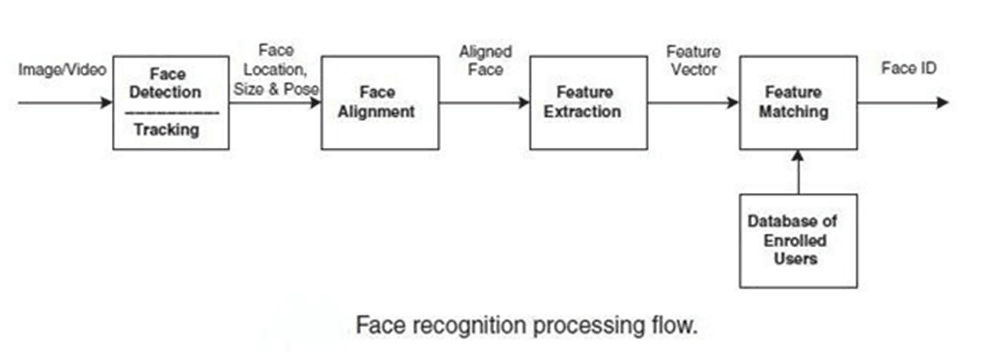
Рис. 1. Общий процесс обработки изображения лица при распознавании
На первом этапе производится детектирование и локализация лица на изображении. На этапе распознавания производится выравнивание изображения лица (геометрическое и яркостное), вычисление признаков и непосредственно распознавание – сравнение вычисленных признаков с заложенными в базу данных эталонами. Основным отличием всех представленных алгоритмов будет вычисление признаков и сравнение их совокупностей между собой.
1. Метод гибкого сравнения на графах (Elastic graph matching) [1].
Суть метода сводится к эластичному сопоставлению графов, описывающих изображения лиц. Лица представлены в виде графов со взвешенными вершинами и ребрами. На этапе распознавания один из графов – эталонный – остается неизменным, в то время как другой деформируется с целью наилучшей подгонки к первому. В подобных системах распознавания графы могут представлять собой как прямоугольную решетку, так и структуру, образованную характерными (антропометрическими) точками лица.
В вершинах графа вычисляются значения признаков, чаще всего используют комплексные значения фильтров Габора или их упорядоченных наборов – Габоровских вейвлет (строи Габора), которые вычисляются в некоторой локальной области вершины графа локально путем свертки значений яркости пикселей с фильтрами Габора.
Недостаток метода гибкого сравнения на графах – это высокая вычислительная сложность процедуры распознавания. Низкая технологичность при запоминании новых эталонов. Линейная зависимость времени работы от размера базы данных лиц.
2. Нейронные сети
В настоящее время существует около десятка разновидности нейронных сетей (НС). Одним из самых широко используемых вариантов являться сеть, построенная на многослойном перцептроне, которая позволяет классифицировать поданное на вход изображение/сигнал в соответствии с предварительной настройкой/обучением сети.
Обучаются нейронные сети на наборе обучающих примеров. Суть обучения сводится к настройке весов межнейронных связей в процессе решения оптимизационной задачи методом градиентного спуска. В процессе обучения НС происходит автоматическое извлечение ключевых признаков, определение их важности и построение взаимосвязей между ними. Предполагается, что обученная НС сможет применить опыт, полученный в процессе обучения, на неизвестные образы за счет обобщающих способностей.
Наилучшие результаты в области распознавания лиц (по результатам анализа публикаций) показала Convolutional Neural Network или сверточная нейронная сеть, которая является логическим развитием идей таких архитектур НС как когнитрона и неокогнитрона. Успех обусловлен возможностью учета двумерной топологии изображения, в отличие от многослойного перцептрона.
Отличительными особенностями СНС являются локальные рецепторные поля (обеспечивают локальную двумерную связность нейронов), общие веса (обеспечивают детектирование некоторых черт в любом месте изображения) и иерархическая организация с пространственными сэмплингом (spatial subsampling). Благодаря этим нововведениям СНС обеспечивает частичную устойчивость к изменениям масштаба, смещениям, поворотам, смене ракурса и прочим искажениям.
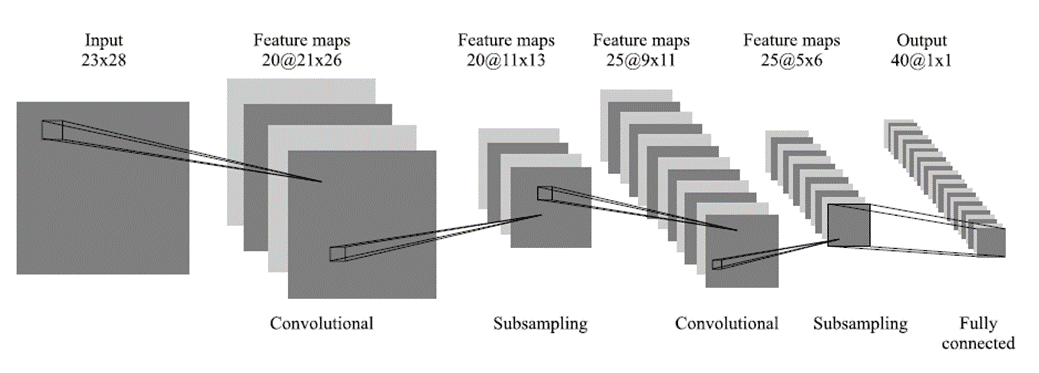
Рис. 2
Тестирование СНС на базе данных ORL, содержащей изображения лиц с небольшими изменениями освещения, масштаба, пространственных поворотов, положения и различными эмоциями, показало 96% точность распознавания.
Свое развитие СНС получили в разработке DeepFace, которую приобрел Facebook для распознавания лиц пользователей своей соцсети. Все особенности архитектуры носят закрытый характер.
Недостатки нейронных сетей: добавление нового эталонного лица в базу данных требует полного переобучения сети на всем имеющемся наборе (достаточно длительная процедура, в зависимости от размера выборки от 1 часа до нескольких дней). Проблемы математического характера, связанные с обучением: попадание в локальный оптимум, выбор оптимального шага оптимизации, переобучение и т. д. Трудно формализуемый этап выбора архитектуры сети (количество нейронов, слоев, характер связей). Обобщая все вышесказанное, можно заключить, что НС – «черный ящик» с трудно интерпретируемыми результатами работы.
3. Скрытые Марковские модели (СММ, HMM)
Одним из статистических методов распознавания лиц являются скрытые Марковские модели (СММ) с дискретным временем. СММ используют статистические свойства сигналов и учитывают непосредственно их пространственные характеристики. Элементами модели являются: множество скрытых состояний, множество наблюдаемых состояний, матрица переходных вероятностей, начальная вероятность состояний. Каждому соответствует своя Марковская модель. При распознавании объекта проверяются сгенерированные для заданной базы объектов Марковские модели и ищется максимальная из наблюдаемых вероятность того, что последовательность наблюдений для данного объекта сгенерирована соответствующей моделью.
Недостатки: необходимо подбирать параметры модели для каждой базы данных,СММ не обладает различающей способностью, то есть алгоритм обучения только максимизирует отклик каждого изображения на свою модель, но не минимизирует отклик на другие модели.
4. Метод главных компонент или principal component analysis (PCA)
Одним из наиболее известных и проработанных является метод главных компонент, основанный на преобразовании Карунена-Лоева.
Первоначально метод главных компонент начал применяться в статистике для снижения пространства признаков без существенной потери информации. В задаче распознавания лиц его применяют главным образом для представления изображения лица вектором малой размерности (главных компонент), который сравнивается затем с эталонными векторами, заложенными в базу данных.
Главной целью метода главных компонент является значительное уменьшение размерности пространства признаков таким образом, чтобы оно как можно лучше описывало «типичные» образы, принадлежащие множеству лиц. Используя этот метод можно выявить различные изменчивости в обучающей выборке изображений лиц и описать эту изменчивость в базисе нескольких ортогональных векторов, которые называются собственными (eigenface).
Полученный один раз на обучающей выборке изображений лиц набор собственных векторов используется для кодирования всех остальных изображений лиц, которые представляются взвешенной комбинацией этих собственных векторов. Используя ограниченное количество собственных векторов, можно получить сжатую аппроксимацию входному изображению лица, которую затем можно хранить в базе данных в виде вектора коэффициентов, служащего одновременно ключом поиска в базе данных лиц.
Суть метода главных компонент сводится к следующему. Вначале весь обучающий набор лиц преобразуется в одну общую матрицу данных, где каждая строка представляет собой один экземпляр изображения лица, разложенного в строку. Все лица обучающего набора должны быть приведены к одному размеру и с нормированными гистограммами.
Затем производится нормировка данных и приведение строк к 0-му среднему и 1-й дисперсии, вычисляется матрица ковариации. Для полученной матрицы ковариации решается задача определения собственных значений и соответствующих им собственных векторов (собственные лица). Далее производится сортировка собственных векторов в порядке убывания собственных значений и оставляют только первые k векторов по правилу:

5. Active Appearance Models (AAM) и Active Shape Models (ASM)
Активные модели внешнего вида (Active Appearance Models, AAM) – это статистические модели изображений, которые путем разного рода деформаций могут быть подогнаны под реальное изображение. Данный тип моделей в двумерном варианте был предложен Тимом Кутсом и Крисом Тейлором в 1998 году. Первоначально активные модели внешнего вида применялись для оценки параметров изображений лиц.
Активная модель внешнего вида содержит два типа параметров: параметры, связанные с формой (параметры формы), и параметры, связанные со статистической моделью пикселей изображения или текстурой (параметры внешнего вида). Перед использованием модель должна быть обучена на множестве заранее размеченных изображений. Разметка изображений производится вручную. Каждая метка имеет свой номер и определяет характерную точку, которую должна будет находить модель во время адаптации к новому изображению.
Сейчас все больше компаний делают распознавание лиц в Китае, и их приложения очень обширны. Среди них Hanwang Technology имеет самую высокую долю рынка. Направления исследований и текущее состояние крупных компаний:
- Технология Hanwang: Технология Hanwang в основном используется для идентификации личности, в основном используется в системах контроля доступа, системах посещаемости и так далее.
- HKUST Xunfei: При поддержке команды профессора Tang Xiaoou из китайского университета Гонконга HKUST Xunfei разработал технологию распознавания лиц, основанную на гауссовском процессе – лицо по Гассу, уровень распознавания этой технологии в LFW составляет 98,52%. Уровень распознавания на LFW достиг 99,4%.
- Чуан Дажи побеждает: В настоящее время основные достижения компании – это трехмерное распознавание лиц, которое было распространено на индустриализацию трехмерных камер с полным лицом и так далее.
- Компания Shangtang Technology: в основном эта компания, которая ставит перед собой цель добиться прорывов в технологии «глубокого обучения» в области искусственного интеллекта и создания отраслевых решений для искусственного интеллекта и анализа больших данных. В настоящее время она занимается распознаванием лиц, распознаванием текста, распознаванием людей, распознаванием транспортных средств, распознаванием объектов. И обработка изображений очень конкурентоспособна. В распознавании лиц есть 106 ключевых точек распознавания лиц.
В исследовательской работе рассмотрены существующие методы, системы распознавания лиц и выполнено распознавание лица с использованием системы распознавания лиц OpenCV Python.
