
Важной составляющей реформирования информационной системы является внедрение электронных информационных систем, позволяющих автоматизировать все основные процессы, связанные с работой предприятий, и обеспечивающих обмен информацией, которые поддерживают возможности интеграции с другими системами и приложениями. В связи с этим, обоснованный выбор программных решений для взаимодействия между сервисами таких прикладных систем приобретает все большее значение в информационной среде, что и обуславливает актуальность темы исследования.
Целью исследования является проведение анализа необходимых программных решений для создания эффективного взаимодействия в распределенной сервисно-ориентированной архитектуре информационной системы посредством сравнительной характеристики между Apache Kafka и RabbitMQ.
RabbitMQ и Apache Kafka – это две системы с открытым кодом и коммерческой поддержкой, применяемые предприятиями. Выпущенная в 2007 году RabbitMQ являлась основным компонентом обмена сообщениями для систем с сервисно-ориентированной архитектурой (SOA). Сегодня она также используется для случаев с интенсивными потоками сообщений. Apache Kafka – это новейший инструмент, разработанный в 2011 году специально для потоковых сценариев, где связь может быть синхронной или асинхронной.
По архитектуре Apache Kafka – устойчивая, быстрая и масштабируемая платформа сообщений и потоков публикаций-подписок. Это долгосрочное хранилище сообщений функционирует как журнал, запущенный в кластере серверов, сохраняющий потоки сообщений в темах Kafka (topic).
Сообщения состоят из значения, ключа и метки времени. Apache Kafka сохраняет все сообщения в течение определенного периода времени. В отдельных случаях требуются внешние службы для запуска, например, Apache Zookeeper [1, c. 31].
Apache Kafka предлагает гораздо более высокую эффективность, чем брокеры сообщений, такие как RabbitMQ. Она может достигнуть высокой пропускной способности (миллионы сообщений в секунду) с помощью ограниченных ресурсов, что необходимо в случаях использования больших массивов данных. RabbitMQ также может обрабатывать миллион сообщений в секунду, но требует больше ресурсов.
Использовать RabbitMQ для тех же случаев, что и Apache Kafka, возможно, но нужно будет совмещать его с другими инструментами, такими как Apache Cassandra.
Apache Kafka предоставляет функцию брокера сообщений и была разработана для сценариев обработки потоков. Apache Kafka поддерживает метрики, отслеживание активности, агрегирование журналов, обработку потоков, журналы коммитов и источник событий. Особенно подходит для Apache Kafka следующие сценарии обмена сообщениями: программы, требующие историю потока при условии «сообщения прочитаны хотя бы один раз»; потоковая обработка данных в многоступенчатых конвейерах, где конвейеры генерируют графики потоков данных в реальном времени.
RabbitMQ целесообразно использовать, когда веб-серверы должны быстро реагировать на запросы. Это избавляет от необходимости выполнять ресурсоемкие действия, пока пользователь ждет результата. RabbitMQ также удобен для передачи сообщений разным получателям для потребления или для распределения нагрузок между работающими сервисами под большой нагрузкой (20 тысяч и более сообщений в секунду). Сценарии использования RabbitMQ включают: программы, которые должны поддерживать устаревшие протоколы, такие как STOMP, MQTT, AMQP, 0-9-1; подробный контроль согласованности (набора) гарантий на основе каждого сообщения.
Процесс работы платформы Kafka включает в себя четыре основных API:
- Producer API позволяет публиковать поток сообщений по конкретной теме Kafka (topic);
- Consumer API позволяет прослушивать одну или несколько тем и обрабатывать потоки записей по ним;
- API Streams предоставляет возможность выполнять потоковую функцию процессора, работая с входным и выходным потоками, эффективно превращая один в другой;
- API Connector позволяет создавать и запускать многоразовых продюсеров (producer) или потребителей (consumer), подключающих темы Kafka (topics) к существующим приложениям или базам данных [2, c. 62].
Схему работы платформы Kafka можно представить на рис. 1.
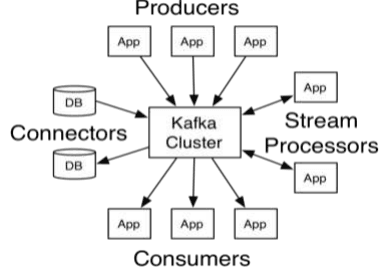
Рис. 1. Схема Kafka API
RabbitMQ написан на Erlang, на нешироко используемом языке программирования, но хорошо приспособленном для таких задач. Конфигурация RabbitMQ устанавливается в файле rabbitmq.config и содержит множество настраиваемых параметров. В терминах клиентского API RabbitMQ поддерживает длинный список языков и некоторые стандартные протоколы, например, STOMP, AMQP доступны с помощью плагина. Очереди и темы (topics) могут создаваться либо через веб-интерфейс, либо через клиентский API напрямую.
Можно выделить следующие компоненты RabbitMQ:
- producer – клиент, который создает сообщения;
- consumer – клиент, который получает сообщения;
- queue – неограниченная по размеру очередь, которая хранит сообщения;
- exchange – компонент, который позволяет переправлять отправляемые в него сообщения на различные очереди.
RabbitMQ – простой в использовании, поддерживает огромное количество платформ для разработки. Он хорошо масштабируется при добавлении большего числа серверов.
RabbitMQ обладает следующими свойствами:
- содержит сообщения, опубликованные в очереди (через обменные пункты);
- несколько потребителей могут подключиться к очереди;
- брокер сообщений распространяет сообщения среди всех доступных потребителей;
- сообщение может быть переадресовано, если потребитель не ответит;
- заказ на доставку гарантирован для очередей с одним потребителем (это невозможно, если очередь имеет несколько потребителей).
RabbitMQ поддерживает:
- протоколы HTTP, XMPP и STOMP;
- клиентские библиотеки AMQP для Java и. NET Framework (поддержка других языков программирования реализована в ПО других поставщиков);
- различные плагины (для мониторинга и управления через HTTP или веб-интерфейс, а также для передачи сообщений между брокерами).
RabbitMQ позволяет обрабатывать порядка 20000 сообщений в секунду на одну машину.
В отличие от RabbitMQ, Kafka обладает такими ценными качествами, как скорость работы, масштабируемость, способность секционировать и множество раз фиксировать одни и те же данные в памяти.
Можно выделить следующие основные отличия Kafka от традиционных систем обмена сообщениями:
- платформа Kafka изначально создавалась и позиционируется как распределенная программа – следовательно, она приспособлена к масштабированию;
- система обладает отличной производительностью – как в случае публикации сообщений, так и в случае подписки на них;
- Kafka сохраняет сообщения на диске и, таким образом, может использоваться для пакетной передачи данных (например, для ETL-процессов (Extract, Transform, Load – «извлечение, трансформирование, загрузка») [3, c. 10].
Также можно выделить основные компоненты архитектуры Apache Kafka:
- поток сообщений (message) определенного типа в терминах службы называется темой (topic). Сообщение – это полезный для некоего процесса комплект данных, тогда как тема – это категория, в соответствии с которой публикуется то или иное сообщение;
- продюсер (producer) – это любой процесс, публикующий сообщения в соответствующей теме;
- опубликованные сообщения затем отправляются на хранение на кластер серверов, именуемых брокерами (brokers) или кластером Kafka;
- потребитель (consumer) может подписаться на одну или несколько тем и использовать сообщения, полученные от брокеров.
Можно представить следующую архитектуру платформы Apache Kafka на рис. 2.
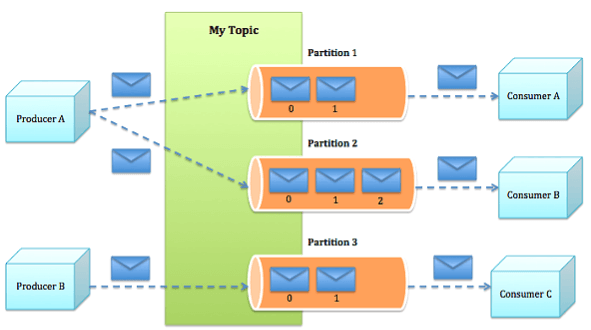
Рис. 2. Архитектура платформы Apache Kafka
Поскольку Kafka по своей природе является распределенной системой, кластер состоит из нескольких брокеров. Для удобства тема разбивается на секции, и каждый брокер отвечает за хранение одной или нескольких секций. Это дает возможность множеству продюсеров и потребителей публиковать и использовать сообщения для своих целей одновременно.
Объем потребляемых данных определяется не брокером, а потребителем. Брокер не обладает никакой информацией насчет того, принял ли потребитель сообщение или нет. Однако для Kafka это не проблема, а преимущество: сообщение удаляется автоматически, если оно задерживается у брокера дольше определенного времени. При этом потребитель может в любой момент сделать «повторный заказ» на то или иное сообщение. Во-вторых, всем известна основная проблема распределенных систем: она заключается в невозможности определить в любой момент времени, какой сервер активен, а какой нет. Из этой проблемы вытекают более конкретные и пугающие – безопасность данных, отказы системы и прочие «слабые места» распределенных систем. В рамках Apache Hadoop решением подобных вопросов занимается служба координации ZooKeeper, которая обладает необходимыми «плюшками» вроде скорости работы, отказоустойчивости и – естественно – распределенной архитектуры. Так вот, поскольку Kafka, как и любая распределенная система, будет неизбежно сталкиваться с присущими этому классу проблемами, очень важно иметь под рукой интегрированный инструмент, который снизит риски и позаботится о вопросах безопасности и восстановления после отказов. В этом свете большим преимуществом Kafka является полная интеграция службы с ZooKeeper – симбиоз во всей красе.
В зависимости от размера batch Apache Kafka имеет разную пропускную способность. При размере batch = 10, Kafka имеет пропускную способность порядка 35 000 сообщений в секунду, а при batch =100 достигается пропускная способность в 89000 в секунду на одну машину.
Kafka – это инновационная система для обработки больших объемов данных. Ее архитектура позволяет потребителям самим регулировать скорость, с помощью которой они будут получать данные.
Kafka очень хорошо подходит для требований большой производительности и низкого использования ресурсов [4, c. 97].
Можно представить производительность серверов очередей Apache Kafka и RabbitMQ на рис. 3.
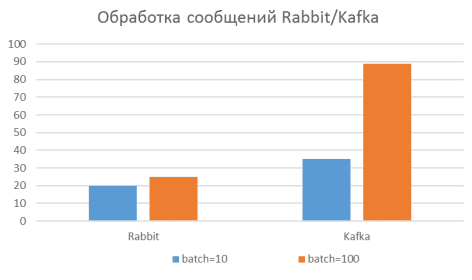
Рис. 3. Пропускная способность Apache Kafka и RabbitMQ
RabbitMQ поддерживает несколько языков программирования (Perl, Python, Ruby, PHP), а также обеспечивает горизонтальное масштабирование для построения кластерных решений. Поэтому RabbitMQ, который неформально называют «Кролик», довольно часто применяется в различных Big Data проектах. Однако, в связи с некоторыми его технологическими особенностями реализации, он не является полноценной заменой Apache Kafka.
В упрощенном виде управление сообщениями выполняется в RabbitMQ следующим образом:
- отправители (publishers) посылают сообщения на обменники (exchange);
- обменники отправляют сообщения в очереди и в другие обменники;
- при получении сообщения RabbitMQ отправляет подтверждения отправителям;
- получатели (consumers) поддерживают постоянные TCP-соединения с RabbitMQ и объявляют, какую очередь они получают;
- RabbitMQ «проталкивает» (push) сообщения получателям;
- получатели отправляют подтверждения успеха или ошибки получения сообщения;
- после успешного получения сообщение удаляется из очереди [5, c. 12285].
Можно представить следующую схему работы RabbitMQ на рис. 4.
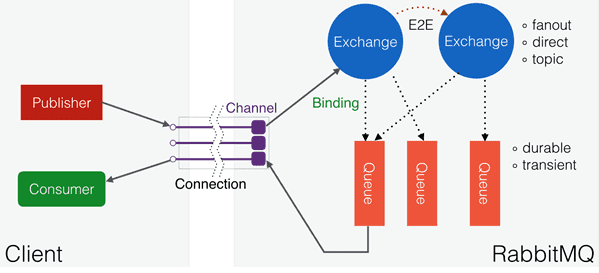
Рис. 4. Схема работы RabbitMQ
Целесообразно выделить следующие общие сходства систем Apache Kafka и RabbitMQ:
- Прикладное назначение – Apache Kafka и RabbitMQ являются брокерами программных сообщений и используются для обмена информацией между различными приложениями.
- Схема обмена сообщениями – оба брокера работают по схеме «издатель-подписчик» (отправитель-получатель), когда источники данных направляют потоки информации, а получатели обрабатывают их по мере необходимости.
- Потоки и пакеты сообщений – Кафка и Кролик в первую очередь позиционируются для работы с непрерывными потоками информации, однако, они позволяют объединять сообщения в пакеты. Kafka делает это более явно, повышая эффективность от пакетирования благодаря своим возможностям по распределению пакетов, а в RabbitMQ пакетирование является скорее «мнимым» из-за пассивной модели приема, не препятствующей конфликтам получателей.
- Уведомления о сообщениях – Kafka и RabbitMQ обмениваются сигналами с отправителями и получателями при отправке и получении сообщений.
- Стратегии доставки – оба брокера способны реализовать стратегии «как максимум однократная доставка» и «как минимум однократная доставка», что позволяет сократить риски потери или дублирования сообщений.
- Репликация – обе системы обеспечивают репликацию сообщений.
- Гарантии отправки – Apache Kafka и RabbitMQ гарантируют порядок отправки сообщений с помощью уведомлений и стратегий доставки.
Основные отличия Apache Kafka и RabbitMQ обусловлены принципиально разными моделями доставки сообщений, реализуемыми в этих системах. В частности, Kafka действует по принципу вытягивания (pull), когда получатели (consumers) сами достают из темы (topic) нужные им сообщения. RabbitMQ, напротив, реализует модель проталкивания, отправляя необходимые сообщения получателям [6].
Таким образом, выбор того или иного брокера в первую очередь зависит от нагрузки, в которой предполагается его использование. В случае адекватного применения каждая из этих систем обмена сообщениями будет эффективным инструментом реализации Big Data проекта. Применять Apache Kafka следует если поток данных генерирует 100k событий в секунду, которые вам нужно доставить в партиционированном порядке со смесью потоковых и пакетных потребителей, если есть необходимость в перечитывании сообщений. Применять RabbitMQ следует если поток сообщений 20000+ в секунду, которые необходимо перенаправлять сложными способами к потребителям, если необходимо гарантировать доставку по одному сообщению.
