
1. Введение
На сегодняшний день люди тратят много времени на поиск необходимой им различной информации. Чтобы помочь сократить время поиска, разрабатываются вопросно-ответные системы, которым можно задавать интересующие вопросы и получать ответы на естественном языке. Но обычному пользователю доступен лишь внешний интерфейс и в момент использования подобных систем никто не видит, как работают внутренние механизмы и мало кто об этом задумывается.
Для того, чтобы понять, как быстро и правильно получить ответ на заданный вопрос, необходимо иметь представление о таком понятии, как обработка текста. Оно включает в себя много различных этапов и является основой работы вопросно-ответной системы. На сегодняшний день разработки в области анализа текста играют большое значение и являются очень актуальной задачей.
2. Работа вопросно-ответной системы
Для того, чтобы понять, что такое вопросно-ответная система и как она работает, необходимо познакомиться понятием Natural Language Processing.
NLP (обработка естественных языков) – это создание систем, которые будут обрабатывать или понимать естественный язык ради выполнения каких-либо задач. Эти задачи могут включать:
- Формирование ответов на вопросы (Question Answering). Примером является такие системы, как Siri, Alexa и Cortana.
- Анализ эмоциональной окраски высказываний (Sentiment Analysis). Определяет, имеет ли высказывание положительный или отрицательный смысл.
- Нахождение текста, соответствующего изображению (Image to Text Mappings). Происходит генерация подписи к входному изображению.
- Машинный перевод (Machine Translation). Осуществляется перевод абзаца текста с одного языка на другой.
- Распознавание речи (Speech Recognition).
- Морфологическая разметка (Part of Speech Tagging). Определение частей речи в предложении и их аннотирование.
- Извлечение сущностей (Name Entity Recognition).
Наиболее актуальной и интересной задачей является формирование ответов на вопросы [1]. Если подробно рассмотреть существующие популярные вопросно-ответные системы, то можно заметить, что все они работают в соответствии с определенной схемой. На вход система получает вопрос от пользователя, который задается на естественном языке. После чего в системе происходит работа с текстом заданного вопроса. Сюда включена начальная обработка, где исправляются различные ошибки, удаляются ненужные символы и прочее; текст разбивается на предложения; предложения, в свою очередь, на слова; производится разбор всех слов (морфологический, синтаксический, семантический). Далее, используя базу результатов автоматической обработки создается запрос, передаваемый поисковой машине, которая выбирается документы, наиболее удовлетворяющие запросу. Текст, каждого подходящего документа подвергается обработке ровно так же, как и сам запрос на входе. После чего происходит отбор определенных фрагментов текста, которые передаются поисковой системе. Эти фрагменты она предоставляет на выход (в качестве ответа) [2]. Схема работы вопросно-ответной системы представлена ниже (рис. 1).
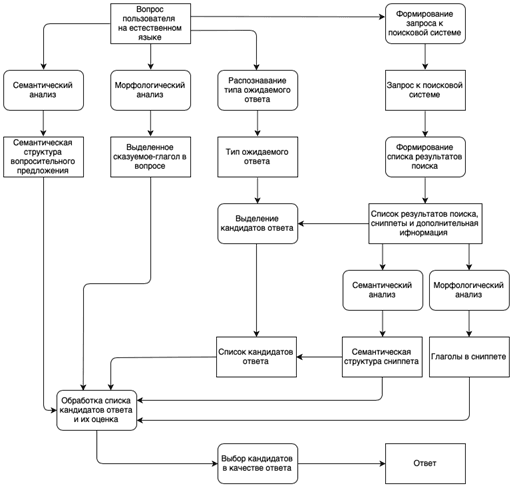
Рис. 1. Схема работы вопросно-ответной системы
3. Основные процессы в обработке естественных языков
Самым важным этапом в работе вопросно-ответной системы является обработка текста. Но чтобы понять, как именно формируются ответы на вопросы, необходимо рассмотреть основы NLP. В разработке вопросно-ответных систем раздел Natural Language Processing посвящен тому, как компьютеры анализируют естественные языки и позволяет применять алгоритмы машинного обучения для текста и речи.
NLP для текста включает в себя несколько процессов. Каждый из них по-своему важен и необходим при создании вопросно-ответной системы [1].
- Разделение текста по предложениям. Идея заключается в том, что в английском, русском и некоторых других языках, можно выделять новое предложение каждый раз, когда находится определенный знак пунктуации – точка.
- Разделение предложений на слова-компоненты. Здесь разделителем служит пробел. Стоит отметить, что в английском языке с этим могут возникнуть проблемы, ведь некоторые составные существительные в нем иногда пишутся через пробел. Но ситуацию можно исправить, применяя различные библиотеки на этапе разработки.
- Лемматизация. Процесс приведения какой-либо формы слова к его словарной форме. Слово drove имеет словарную форму drive.
- Стемминг. Это процесс, в котором отрезается все «лишнее» от корня слова. Например, слова cat, cats, cat’s сводятся к одной форме – cat.
- Стоп-слово. Такие слова исключаются из текста до или после обработки. Обычно это артикли, союзы и т.д., так как они не несут никакой смысловой нагрузки, а лишь создают шум в процессе обработки.
- Регулярные выражения. Некоторая последовательность символов, которая определяет шаблон поиска. Другими словами, для поиска используется строка-образец, состоящая из символов и метасимволов, которая задает правило поиска.
- Мешок слов. Это техника, при использовании которой на естественном языке каждый документ или текст выглядит как неупорядоченный набор слов без какой-либо информации о связи между ними. Любая информация о порядке или структуре слов игнорируется, отсюда и название.
Каждый из этих процессов помогает понять, как лучше разработать вопросно-ответную систему [3]. Ведь знание основы выделения признаков позволит использовать их как входные данные для алгоритмов машинного обучения.
4. Алгоритмы распознавания схожести текста
Для разработки вопросно-ответных систем используются различные алгоритмы, которые способны распознавать на сколько тексты похожи друг на друга. Они позволяют оценить, правильно ли система отвечает на заданные ей вопросы. Наиболее известными алгоритмами являются коэффициент Жаккара и коэффициент Сёренсена.
Коэффициент Жаккара. Иначе называется мерой Жаккара или коэффициентом сходства. Основан на использовании информации о множестве общих символов [4]. Вычисляется, как отношение количества уникальных символов в двух множествах к общему числу уникальных символов в двух множествах. Используется формула .
Для наилучшего понимания работы этого алгоритма, следует рассмотреть пример. Один человек делает запрос и пишет в поисковой строке слово «молоко». Второй человек оказывается менее грамотным и допускает ошибку, написав в поисковой строке «малоко». По смыслу запросы абсолютно одинаковы, ведь оба имели в виду один и тот же напиток, но написание оказалось разным. Вопросно-ответная система, в свою очередь, должна каким-то образом интерпретировать орфографически не правильный запрос. Чтобы это сделать, ей необходимо оценить, измерить похожесть запросов, выдав количественную оценку степени этой похожести. Именно здесь на помощь приходит коэффициент Жаккара.
Коэффициент Сёренсена. Бинарная мера сходства, эквивалентная (связанная одной монотонно возрастающей зависимостью) мере Жаккара. По сути, они оба эквивалентны в том смысле, что, учитывая значение коэффициента Серенсена S, можно рассчитать соответствующее значение индекса Жакара J и наоборот, используя уравнения J = S / (2-S) и S = 2J / (1 + J) [5].
Данные алгоритмы будут сравниваться с алгоритмом Рэтклиффа-Обершельпа, который производит сопоставление с образцом и помогает решить проблему опечаток в текстах. Чтобы увидеть, как работают алгоритмы, необходимо взять некоторую базу данных. В ней содержатся вопросы и ответы на них, а также перефразированные вопросы, которые по смыслу идентичны исходным, но состоят из других слов.
Далее происходит работа с этой базой данных. В программу на языке Python загружается файл с вопросами и начинается основная работа. Все символы текста приводятся к нижнему регистру, удаляются знаки пунктуации, различные небуквенные символы и цифры. Каждая строка разбивается на список составляющих ее слов и удаляются стоп-слова, а также используется лемматизация.
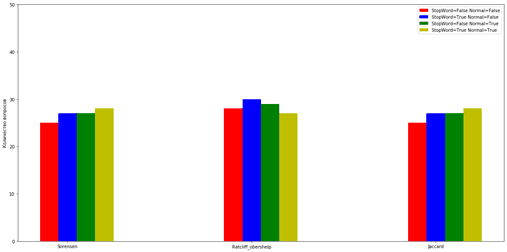
Рис. 2. Результат работы программы
В программе сравниваются два вопроса, похожих между собой и к ним применяются вышеуказанные алгоритмы. В конце выводится процент сравнения. Чем он выше, тем лучше работает тот или иной алгоритм. Результатом программы является график сравнения работы двух алгоритмов с алгоритмом Рэтклиффа-Обершельпа (рис. 2), исходя из которого видно, что алгоритм Серенсена и Жаккара не сильно отличаются друг от друга, но явно уступают алгоритму Рэтклиффа-Обершельпа.
5. Заключение
Вопросно-ответные системы играют важную роль в поиске информации. На сегодняшний день они умеют отвечать на вопросы пользователей, заданных на естественном языке. Но основным этапом в процессе их создания является обработка текста, для которой используются различные алгоритмы, способные распознавать на сколько тексты похожи друг на друга. Они позволяют оценить, правильно ли система отвечает на заданные ей вопросы.
Проанализировав в ходе статьи результаты работы некоторых алгоритмов схожести текста, стало очевидно, какой из них лучше справляется с обработкой входных данных.
