
Введение
Решение различных задач в области организации дорожного движения (строительство дорог и инфраструктурных объектов) требует больших затрат ресурсов, поэтому одним из важнейших подготовительных этапов является построение модели. В ходе моделирования производится оценка текущей ситуации, выявляются проблемные участки, выполняется построение различных вариантов решения и оценивается эффект, который будет достигнут в результате внедрения того или иного варианта.
Создание транспортной модели в среде моделирования состоит из нескольких шагов:
- построение улично-дорожной сети рассматриваемого участка;
- расстановка объектов дорожной инфраструктуры: светофоры, пешеходные переходы, организация движения;
- сбор данных о реальной обстановке на рассматриваемом участке: светофорные режимы, расписание общественного транспорта, подсчет трафика;
- в модели расставляются точки генерации и притяжения;
- на основании подсчитанных автомобилей строится матрица корреспонденции;
- производится моделирование текущей дорожной ситуации, результат которого должен совпадать в реальной обстановкой;
- в модель вносятся изменения в соответствии с предлагаемыми проектами строительства и оценивается их эффект.
Для построения транспортных моделей используются различные специальные среды моделирования, например, PTV Visum и Aimsun.
Самым трудоемким и времязатратным этапом является подсчет автомобилей и составление матрицы корреспонденции, поскольку на данный момент не существует никаких средств автоматизации этого процесса, вся работа выполняется вручную: человек с видеокамерой и секундомером приходит на объект и снимает проезд автомобилей на видео, а затем видео просматривается несколько раз, подсчитывается количество проехавших машин и записывается в соответствующую ячейку в матрице корреспонденции.
Основная задача данной работы - изучить возможность автоматизировать процесс подсчета автомобилей, и тем самым ускорить разработку транспортных моделей.
Алгоритмы обнаружения объекта в видеопотоке
Существует несколько различных подходов к решению задачи распознавания движущихся объектов в видеопотоке:
- методы вычитания фона;
- методы на основе машинного обучения;
- с применением глубоких нейронных сетей.
Метод вычитания фона
Методы вычитания фона содержат множество вариаций, но все они имеют общую идею - каким-либо способом выделить фон изображения, а затем, вычитая его из кадра с объектами, получать области, содержащие движущиеся объекты.
Один и способов выделения фона - метод усреднения. Среднее значение фона находится с помощью какой-либо из функций OpenCV:
void accumulate(
cv::InputArray src,
cv::InputOutputArray dst,
cv::InputArray mask=cv::noArray()
);
void accumulateWeighted(
cv::InputArray src,
cv::InputOutputArray dst,
double alpha,
cv::InputArray mask=cv::noArray()
);
Эти функции отличаются тем, что accumulate() вычисляет среднее арифметическое для каждого пикселя, это равносильно тому, что будет попиксельно произведено сложение n кадров, а затем результат поделен на общее число кадров-слагаемых.
Функция accumulateWeighted() реализует идею нахождения скользящего среднего, когда кадры, поступившие на вход функции последними, имеют больший вес, чем предыдущие.
Когда модель фона была вычислена, производится вычитание его из текущего кадра. Это можно сделать с помощью функции OpenCV absdiff().
Несмотря на простоту реализации алгоритмов вычитания фона, они имеют особенность: выделение фона будет корректным, если камера, формирующая видеопоток, находится в неподвижном состоянии. Если же камера двигается, то правильно выделить фон, не прибегая к дополнительной обработке видеоряда (например, применение методов стабилизации изображения) не получится. В этом случае, можно применить один из более сложных методов детектирования объектов.
Метод на основе машинного обучения
В библиотеке компьютерного зрения OpenCV есть встроенные модули обнаружения объектов на изображении с использованием методом машинного обучения – каскадный классификатор и детектор на основе метода опорных векторов.
Каскадный классификатор построен на основе деревьев и реализует алгоритм обнаружения лиц Виолы-Джонса.
Метод состоит из двух частей – обучение и распознавание. Перед тем, как начать обрабатывать целевые изображения, необходимо провести обучение и сформировать некоторую базу данных, состоящую из признаков. В качестве признаков используются признаки Хаара, которые были так названы из-за визуального сходства с вейвлетом Хаара (рис. 1 и рис. 2).
Высокая скорость обработки изображений достигается за счет использования интегрального представления изображений: хранящееся изображение представлено в виде матрицы, каждый элемент которой равен сумме всех элементов, которые расположены выше и левее. Интегральное представление полезно тем, что позволяет быстро вычислять сумму некоторого набора ячеек матрицы, вне зависимости от размера вычисляемой области, нахождение суммы всегда занимает константное время. Признаки Хаара применяются к какой-либо области изображения, прямоугольник с черной и белой областью накладывается как маска на изображение, находятся суммы содержимого ячеек темной и светлой области. Затем находится разность между темной и светлой областью, и в результате получается число – оно называется значением признака.
Рис. 1. Вейвлет Хаара

Рис. 2. Признаки Хаара
Каскадные классификаторы, основанные на алгоритме Виолы-Джонса имеют как преимущества, так и недостатки. Они работают быстро из-за применения интегрального представления, поэтому их можно использовать для обработки видео в реальном времени, но для обучения нужна большая выборка. Работает очень точно, если искомый объект не очень сильно отличается от изображений объектов, которые были использованы при обучении, если же отличия сильные (для лиц пример – сильный наклон головы, взаимное расположение частей лица нарушается), тогда объект вообще не распознается.
Сверточные нейронные сети
Архитектура R-CNN (Regions With CNNs) была разработана для решения задачи классификации изображений. R-CNN состоит из трех независимых друг от друга сетей: сверточной сети (CNN), бинарного классификатора (SVM) и линейной регрессии. На вход сверточной сети подается часть исходного изображения (регион), которая предположительно имеет какой-либо объект. Эта сеть может обрабатывать изображения фиксированного размера – 227x227, поэтому все регионы, которые необходимо обработать, подгоняются под определенный размер.
На выходе сверточной сети получается вектор признаков региона, размером 4096 элементов, и затем он подается на вход SVM-сети, которая проводит бинарную классификацию по своему набору объектов методом опорных векторов, и определяет, есть ли тот или иной объект в переданном регионе.
Затем проводится классификация региона методом линейной регрессии. Параметры, полученные из выхода блока со сверточной сетью, анализируются на предмет того, насколько данный регион точно охватывает распознаваемый объект и насколько нужно его увеличить или уменьшить, чтобы делать это точнее (рис. 3).

Рис. 3. Схема сети R-CNN
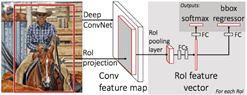
Рис. 4. Схема сети Fast R-CNN
Сеть Fast R-CNN содержит в себе несколько улучшений: через сверточную сеть проводится не набор из регионов – кандидатов, содержащий объект, а все изображение полностью, а также 3 независимых сети теперь объединены и проходят обучение вместе (рис. 4).
Faster R-CNN содержит улучшение сети Fast R-CNN в части генерации регионов-кандидатов: теперь регионы вычисляются не по изначальному изображению, а по признакам, получившимся в результате обработки исходного изображению сверточной сетью. То есть к предыдущей сети добавился еще один модуль со сверточными слоями. Архитектура Faster R-CNN представлена на рис. 5.
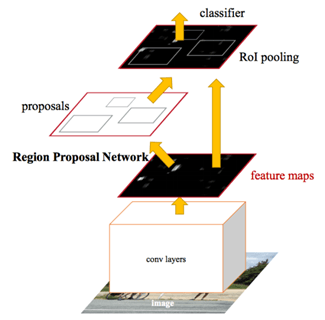
Рис. 5. Архитектура Faster R-CNN
Результаты распознавания
Имеется видеоролик, на которых зафиксированы разные автомобили. Видеоролики сняты с беспилотного летального аппарата. Кадр приведен на рис. 6.
На рис. 7 представлен результат работы программы, на кадре розовыми точками отмечены отдельные распознанные объекты. Видно, что некоторые автомобили отмечены несколькими точками и это связано с тем, что автомобиль на виде сверху - это прямоугольник, состоящий из 5 частей: капот, лобовое стекло, крыша, заднее стекло, крышка багажника. По сравнению с остальными частями крыша имеет более вытянутую форму, и если взять 2 соседних кадра и они приходятся на тот момент, когда автомобиль едет достаточно медленно, то смещение автомобиля будет меньше, чем размер крыши и разницы по цвету пикселей в области нее не будет. Поскольку остальные части автомобиля имеют гораздо меньший размер, то заметить их с помощью приведенного алгоритма проще.
Решить эту проблему можно, если брать не соседние кадры, а с пропусками. В этом случае возникает проблема с выделением автомобилей, которые едут слишком быстро и на тех кадрах, которые были пропущены, на место предыдущего автомобиля переместился другой.

Рис. 6. Кадр исходного видео
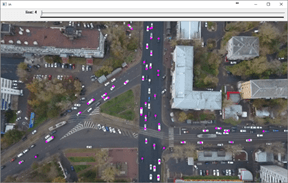
Рис. 7. Результат работы методом вычитания
Для распознавания автомобилей на виде сверху методами, использующими машинное обучение, необходим соответствующий обучающий набор изображений.
Используемая в проекте нейросеть для обучения брала изображения автомобилей, снятых с высоты 40 метров, поэтому и на проверочных изображениях она могла распознать автомобили только в том случае, если был настроен соответствующий масштаб. Пример распознавания автомобилей без увеличения масштаба приведен на рис. 8.
Если отметить все получившиеся координаты кружочками на кадре, подававшемся на вход сети, то получится результат, приведенный на рис. 9.
Выводы
Приведенные примеры позволяют сделать вывод, что использование нейронной сети подходит больше всего для решения данной задачи.
Для приведенного выше примера изображения, приемлемый результат получается при увеличении изображения в 4 раза, при этом сам кадр также делится на 4 части, и нейросеть обрабатывает 4 отдельных изображения, которые, в конечном итоге, собираются обратно в один цельный кадр.

Рис. 8. Результат работы нейронной сети с изображением с не подобранным масштабом
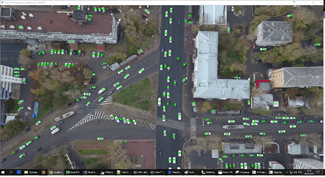
Рис. 9. Результат работы нейросети с изображением с подобранным масштабом
