
Introduction
The increasing ubiquity of high‐volume, high‐velocity data has driven organizations across diverse industries to adopt data‐centric (or data‐driven) strategies for decision‐making [1, 598-607; 2, p. 10-25]. Within this context, machine learning (ML) and artificial intelligence (AI) methodologies have become pivotal in extracting actionable insights, optimizing operational workflows, and fostering innovation [3; 4, p. 1-22]. Numerous studies highlight that harnessing complex datasets through ML allows businesses not only to understand historical trends but also to predict future market behavior with remarkable accuracy [5, p. 101-110; 6, p. 109810-109825]. Consequently, the deployment of advanced ML techniques, such as deep neural networks and anomaly detection algorithms, has emerged as a fundamental component of modern business analytics [7, p. 1735-1780; 8, p. 436-444].
In an era defined by rapid shifts in consumer preferences and market volatility, forecasting demand and analyzing sales patterns represent essential tasks for sustaining competitive advantage [9, p. 5-12; 10, p. 1-15]. Accurate demand forecasting enables more efficient inventory management, reduced operational costs, and targeted promotional strategies [11, p. 43-56]. Meanwhile, sales analysis grounded in advanced ML models has proven instrumental for personalized marketing and for uncovering latent consumer segments [12, 1-127; 13, p. 45-58]. Equally critical is the detection of anomalies – deviations from expected patterns in transaction data, inventory flows, or customer behavior [14, p. 1135-1144]. Such anomalies may signal fraudulent activities, logistical inefficiencies, or sudden market shocks [6, p. 109810-109825; 15, p. 785-794]. Anomaly detection techniques, including cluster‐based and deep autoencoder approaches, support real‐time alerts and facilitate preemptive responses to mitigate financial and reputational risks [16; 17, p. 1-12]. As evidenced by Boppiniti [3] and corroborated by Rachakatla et al. [4, p. 1-22], the adoption of AI‐powered predictive tools for demand and anomaly analysis is a cornerstone in the ongoing transformation toward data‐driven industries.
Building on the existing body of research [1, p. 598-607; 3; 4, p. 1-22], this article aims to identify core ML techniques – including both traditional algorithms and deep learning architectures – relevant to demand forecasting and anomaly detection in sales data. It additionally demonstrates how to integrate these predictive models into various industrial domains to enhance operational efficiency, improve resource allocation, and inform strategic planning. By bridging theoretical insights with empirical applications, the article seeks to elucidate the interplay between ML approaches and practical business imperatives, highlighting the strengths and limitations of different models as well as the infrastructural requirements for deploying them in real‐world environments [13, p. 45-58; 18].
To achieve these objectives, the methodological framework of this study encompasses a comprehensive review of prior investigations into ML‐enabled forecasting, sales analytics, and anomaly detection, drawing upon peer‐reviewed journals and conference proceedings [1, p. 598-607; 5, p. 101-110]. It further includes a comparative evaluation of supervised, unsupervised, and deep learning architectures in terms of their application scope and performance trade‐offs [2, p. 10-25; 7, p. 1735-1780], followed by a case‐based examination of how predictive analytics solutions have been deployed in retail, finance, and manufacturing [3; 4, p. 1-22]. After this Introduction, the article proceeds with an in‐depth discussion of ML techniques suited for forecasting and anomaly detection, then explores a range of industry examples, and finally concludes with overarching insights, limitations, and potential directions for future research in AI‐driven business analytics.
1. Approaches to demand forecasting and sales analysis in data-driven industries
Contemporary enterprises rely on predictive models to capture complex market dynamics and consumer behaviors. Classical approaches, including linear regression and time series analysis, remain foundational due to their interpretability and relatively modest data requirements [19]. Linear regression approximates the relationship between predictor variables x and an outcome y as ![]() , yet it often struggles with non‐linear patterns and irregularities in large datasets [5, p. 101-110]. Traditional time series methods, such as ARIMA, decompose temporal data into trend, seasonality, and noise, showing strong performance in settings where patterns are stable and changes are incremental [20, p. 75-85]. However, they may be outperformed when faced with volatile or high‐dimensional data generated by modern, data‐driven operations [1, p. 598-607; 11, p. 43-56].
, yet it often struggles with non‐linear patterns and irregularities in large datasets [5, p. 101-110]. Traditional time series methods, such as ARIMA, decompose temporal data into trend, seasonality, and noise, showing strong performance in settings where patterns are stable and changes are incremental [20, p. 75-85]. However, they may be outperformed when faced with volatile or high‐dimensional data generated by modern, data‐driven operations [1, p. 598-607; 11, p. 43-56].
Owing to these limitations, the field has embraced advanced machine learning (ML) paradigms that include both supervised (e.g., Random Forests, Gradient Boosting) and unsupervised (e.g., clustering, dimensionality reduction) techniques [3; 4, p. 1-22]. Algorithms like Random Forests aggregate multiple decision trees to lower variance and mitigate overfitting, while Gradient Boosting [15, p. 785-794] iteratively refines weak learners, yielding high predictive accuracy. These models can handle non‐linearities and diverse feature sets, thereby improving demand forecasts and supporting more granular sales insights [2, p. 10-25]. For even higher complexity and larger datasets, deep neural networks – particularly Recurrent Neural Networks (RNNs), Long Short‐Term Memory (LSTM) architectures, Convolutional Neural Networks (CNNs), and transformers–are increasingly deployed [8, p. 436-444; 21, p. 5998-6008]. RNNs and LSTM variants model temporal dependencies in sequential sales data [7, p. 1735-1780], while CNNs are adept at extracting spatial‐like features that may arise in grid‐structured data [9, p. 5-12]. Transformers, with their self‐attention mechanisms, have shown promise for capturing long‐range dependencies and complex correlations [3; 4, p. 1-22].
In tandem with forecasting models, organizations increasingly focus on anomaly detection to identify outliers, fraud, or drastic shifts in sales volume [17, p. 1-12]. Anomalies constitute data points that deviate significantly from historical or normative patterns, and their rapid identification is vital for mitigating revenue loss or reputational harm [13, p. 45-58; 16]. Traditional techniques, including clustering algorithms such as DBSCAN or K‐Means, can reveal groups of normal data points, isolating those that deviate excessively [14, p. 1135-1144]. Statistical process control methods (e.g., z‐scores or Shewhart charts) are similarly employed to detect anomalies when assumptions about normal data distributions hold [2, p. 10-25]. Recent advancements leverage autoencoders–neural networks trained to reconstruct normal patterns but failing for anomalous inputs – and Generative Adversarial Networks (GANs) to synthesize representative normal data, thereby refining anomaly detection boundaries [8, p. 436-444; 10, p. 1-15]. These methods grant firms the ability to detect irregular events in sales, from potential fraud to sudden demand spikes, often in real‐time.
A robust ML pipeline requires careful data preparation, feature engineering, and domain expertise [4, p. 1-22; 6, p. 109810-109825]. Data quality remains a cornerstone: missing values, inconsistencies, or irrelevant features can distort predictive models [11, p. 43-56]. Feature engineering might involve transforming raw sales data to capture seasonality or special events [11, p. 43-56]. Domain expertise ensures the selection of relevant variables – for instance, economic indicators or regional factors – while discarding confounding information that may yield spurious correlations [3]. Organizations typically adopt big data frameworks like Hadoop or Apache Spark for distributed computing, allowing them to process and store large‐scale sales transactions efficiently [9, p. 5-12]. Cloud platforms such as AWS, Google Cloud, and Microsoft Azure further facilitate the elasticity and scalability needed to handle large, variable workloads [10, p. 1-15].
Automation strategies (MLOps) integrate continuous integration/continuous delivery (CI/CD) pipelines for deploying and monitoring ML models in production [5, p. 101-110]. By automating model training, validation, and performance diagnostics, firms achieve faster iteration cycles and mitigate risks associated with model drift, where real‐world data distributions evolve [13, p. 45-58]. MLOps also promotes reproducibility and ensures consistent oversight of the end‐to‐end process – from data ingestion to retraining – thereby expediting how demand forecasts and anomaly alerts are integrated into daily operations [3]. Table 1 highlights some key distinctions between classical and modern ML approaches, with an emphasis on their practical considerations for forecasting and anomaly detection.
Table 1
Key distinctions between classical and modern ML approaches
Approach | Key characteristics | Typical use cases |
| Classical Methods (e.g., ARIMA, Linear Regression) |
|
|
| Advanced ML (e.g., Random Forests, Gradient Boosting) |
|
|
| Deep Learning (RNN, LSTM, CNN, Transformers) |
|
|
One of the most common loss functions to evaluate forecasting accuracy is the Mean Squared Error (MSE), defined as:
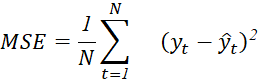 | (1) |
Where ![]() and
and ![]() represent actual and predicted values for time t, respectively [22]. Minimizing MSE is critical for stable predictions, especially when deploying ML solutions to high‐impact operations like supply chain logistics or financial modeling [3; 15, p. 785-794]. Beyond metrics, successfully launching predictive systems hinges on aligning modeling choices with organizational objectives, data availability, and risk tolerance [18].
represent actual and predicted values for time t, respectively [22]. Minimizing MSE is critical for stable predictions, especially when deploying ML solutions to high‐impact operations like supply chain logistics or financial modeling [3; 15, p. 785-794]. Beyond metrics, successfully launching predictive systems hinges on aligning modeling choices with organizational objectives, data availability, and risk tolerance [18].
In sum, successful demand forecasting and sales analysis within data‐driven industries require bridging classical statistical approaches with newer, more flexible ML methods. Deep architectures, while powerful, necessitate carefully managed pipelines, quality data, and adequate computational infrastructure, especially when real‐time anomaly detection is integral to revenue protection or fraud prevention. As organizations continue to adopt MLOps principles and expand their data infrastructure, the synergy between these predictive models and practical business requirements will likely deepen, paving the way for more accurate, robust, and automated analytical solutions in dynamic market environments.
2. Practical case studies and comparative analysis
Case 1: Retail and E-Commerce
The retail sector has witnessed rapid digital transformation, making it an ideal testing ground for data‐driven forecasting and anomaly detection techniques [3]. One prevalent approach involves Recurrent Neural Networks (RNNs) and, more specifically, Long Short‐Term Memory (LSTM) architectures. Such models accommodate temporal dependencies in sales data–including seasonality, promotions, and exogenous factors like weather or regional events [7, p. 1735-1780]. Their baseline equation often expresses hidden state updates as follows:
![]() , (2)
, (2)
Where ![]() is the input at time t (e.g., sales or promotional signals) and
is the input at time t (e.g., sales or promotional signals) and ![]() the hidden state capturing accumulated information. This recurrent formulation allows more nuanced modeling of demand swings than simpler statistical techniques like ARIMA [20, p. 75-85].
the hidden state capturing accumulated information. This recurrent formulation allows more nuanced modeling of demand swings than simpler statistical techniques like ARIMA [20, p. 75-85].
Retailers further leverage AI‐powered recommendation modules to increase average order value and tailor suggestions for individual shoppers [18]. Deep matrix factorization and neural collaborative filtering have become common for personalizing product bundles, dynamic pricing, and real‐time promotion strategies [8, p. 436-444]. These methods often utilize user‐item interaction matrices enhanced by contextual features (e.g., location, browsing history) for refined targeting [5, p. 101-110].
Alongside demand forecasting, anomaly detection is crucial for promptly identifying sudden drops or spikes in sales. Approaches like clustering (e.g., DBSCAN) and autoencoders [2, p. 10-25] isolate atypical transaction volumes, especially during flash sales or unforeseen market disruptions. The autoencoder reconstructs normal patterns by minimizing reconstruction error:
![]() , (3)
, (3)
Where ![]() is the original input and
is the original input and ![]() is the autoencoder output. Excessive errors signal anomalous instances [14, p. 1135-1144]. By integrating these detection mechanisms, retailers can quickly respond to fraudulent orders or supply‐chain inconsistencies [3]. Table 2 contrasts key metrics for short‐term demand forecasting and anomaly detection in a typical e‐commerce setting.
is the autoencoder output. Excessive errors signal anomalous instances [14, p. 1135-1144]. By integrating these detection mechanisms, retailers can quickly respond to fraudulent orders or supply‐chain inconsistencies [3]. Table 2 contrasts key metrics for short‐term demand forecasting and anomaly detection in a typical e‐commerce setting.
Table 2
Key metrics for short‐term demand forecasting and anomaly detection in a typical e‐commerce setting
Metric | Short-term demand forecasting | Anomaly detection in sales |
Objective | Predict near-future item demand (daily/weekly) | Identify outliers in volume, fraud, or unexpected transactions |
Common Algorithms | LSTM, GRU, ARIMA | Autoencoders, DBSCAN, Isolation Forest |
Key Data Features | Sales history, seasonal variables, promotions, external signals | Transaction timestamps, user behavior logs, price fluctuations |
Performance Metrics | MSE, MAE, RMSE, MAPE | Precision, Recall, F1-score, ROC-AUC |
Implementation Challenges | High data dimensionality, concept drift over time | Imbalanced class distributions, real-time processing constraints |
Case 2: Financial sector
Financial institutions increasingly adopt AI models to predict demand for credit products, insurance policies, and specialized investment offerings [4, p. 1-22]. Demand forecasts in this domain require integrating macroeconomic variables (e.g., interest rates, GDP growth), demographic data, and internal banking records [15, p. 785-794]. ML algorithms such as gradient boosting and random forests have proven effective for forecasting credit uptake, since they accommodate non‐linearities and complex interactions in applicant profiles [2, p. 10-25].
Fraud detection serves as another pivotal application in finance. High‐value transactions demand near‐instant screening for anomalies, which can stem from identity theft, card skimming, or unauthorized account access [11, p. 43-56]. Deep learning approaches – ranging from CNNs to LSTMs – excel at modeling sequential user behavior, while autoencoders and Generative Adversarial Networks (GANs) can identify subtle fraud patterns by comparing observed data against learned representations of “normal” usage [6, p. 109810-109825]. Moreover, regulators impose high standards of model interpretability, making techniques such as LIME (Local Interpretable Model‐Agnostic Explanations) and SHAP (SHapley Additive exPlanations) indispensable for elucidating why certain anomalies trigger alerts [14, p. 1135-1144]. Table 3 offers a comparative view of anomaly detection approaches within finance, highlighting their interpretability and computational complexities.
Table 3
Comparative view of anomaly detection approaches within finance
Anomaly detection method | Interpretability | Computational complexity | Usage in finance |
Statistical Thresholding | High (simple rules, clear threshold) | Low (works well on small data) | Quick checks, small-scale fraud screening |
Autoencoders | Moderate (black-box structure, can use reconstruction error) | Moderate to High (neural training overhead) | Detailed fraud detection, insider trading, unusual transaction patterns |
GAN-based Methods | Low to Moderate (GANs can be opaque) | High (training generator + discriminator) | Complex pattern extraction, high-volume transaction analysis |
SHAP/LIME (Explanations) | N/A (they complement the above methods) | Varies (depends on model size) | Regulatory compliance, clarifying suspicious transactions for audit |
Due to strict regulatory requirements, banks and insurers implement thorough explainability frameworks around AI systems [17, p. 1-12]. For instance, an insurance provider might deploy SHAP to interpret premium‐pricing models, ensuring compliance with anti‐discrimination statutes and justifying rates to oversight bodies [4, p. 1-22]. Incorporating domain expertise (e.g., actuaries, financial analysts) further refines feature engineering and makes the resultant models more transparent and robust [13, p. 45-58].
Case 3: Manufacturing and supply chains
While digital platforms have thrived in retail and finance, manufacturing and supply chains represent an equally compelling area for advanced forecasting and anomaly detection. Predictive models inform production scheduling and inventory replenishment, integrating classical time series methods with CNN or LSTM architectures that capture seasonal production cycles, batch runs, and fluctuations in raw material availability [20, p. 75-85]. Where ![]() might represent sensor inputs such as vibration or temperature in equipment monitoring, an RNN can map
might represent sensor inputs such as vibration or temperature in equipment monitoring, an RNN can map ![]() to predictions of failure probabilities, thus reducing downtime [18].
to predictions of failure probabilities, thus reducing downtime [18].
Anomalies in manufacturing often manifest as equipment malfunctions, quality control deviations, or supply chain bottlenecks [1, p. 598-607]. IoT sensors generate real‐time telemetry, enabling anomaly detection through specialized ML pipelines [3]. For instance, deep autoencoders reconstruct normal operational signals and flag any substantial reconstruction errors as potential failures. Concurrently, supply chain disruptions – e.g., sudden port closures–can be detected if demand or lead times depart significantly from historical norms [4, p. 1-22].
Organizations further benefit from implementing MLOps practices, where continuous integration and continuous delivery (CI/CD) pipelines automate model retraining, versioning, and deployment [5, p. 101-110]. This is particularly vital in manufacturing, where global supply networks can shift abruptly, requiring rapid adjustments to predictive models [9, p. 5-12]. Domain experts in process engineering, logistics, and procurement collaborate with data science teams to identify relevant parameters, ensure data integrity, and interpret model outputs in the broader context of risk management [13, p. 45-58].
Comparative Perspectives
Across these three sectors – retail, finance, and manufacturing – advances in ML have enabled more accurate demand forecasting, targeted anomaly detection, and the adoption of scalable infrastructures [3; 4, p. 1-22]. Despite sector‐specific nuances (e.g., retail promotions vs financial compliance vs manufacturing schedules), certain factors are universally critical:
- Data Quality: Incomplete or noisy datasets hamper model reliability and increase false positives in anomaly detection [1, p. 598-607].
- Model Selection and Explainability: While deep networks can yield higher predictive power, interpretability may be limited; hence the use of LIME, SHAP, or rule extraction methods remains vital [14, p. 1135-1144].
- Infrastructure: Distributed computing frameworks such as Spark or Kubernetes orchestrations enable real‐time analytics and large‐scale batch processing [9, p. 5-12].
- MLOps and Continuous Improvement: Frequent retraining avoids performance degradation when data distributions shift, exemplified by abrupt market shocks or equipment aging processes [5, p. 101-110].
Each case underlines the interplay between domain expertise, algorithmic sophistication, and infrastructure readiness. Models that work well in one industry might need substantial feature engineering or interpretability enhancements in another [18]. Overall, these sectoral insights reinforce the strategic imperative for data‐driven transformations, aligning advanced forecasting and anomaly detection methods with the business’s specific regulatory, operational, and consumer contexts.
Conclusion
Demand forecasting, sales analysis, and anomaly detection have become pillars of a data-driven paradigm, reshaping how businesses navigate evolving market landscapes. As demonstrated through retail, financial, and manufacturing case studies, the incorporation of machine learning techniques–from classical regression and time series models to state-of-the-art deep neural networks – offers significant gains in predictive accuracy and strategic responsiveness. Notably, advanced architectures such as LSTM, CNN, and transformers allow for granular insights into temporal, spatial, or contextual data patterns. These innovations are further strengthened by robust data pipelines, cloud-based infrastructures, and MLOps practices, which ensure that models remain current in the face of volatile consumer demand, regulatory pressures, and technological disruptions.
A critical takeaway is the necessity to balance high-performing “black box” algorithms with interpretability. Stakeholders across industries – ranging from marketing teams to compliance officers – require transparent justifications for model outputs. Thus, explainable AI tools and frameworks remain integral to the adoption and trustworthiness of ML solutions. Moreover, continuous retraining and domain-informed feature engineering play decisive roles in mitigating issues such as data drift and model decay, highlighting the iterative nature of real-world analytics.
This integrated perspective underscores the transformative potential of AI-driven methodologies for demand prediction, targeted sales initiatives, and real-time anomaly detection. As organizations continue to scale up their data architectures, the interplay between domain expertise, advanced ML algorithms, and operational best practices will define the next phase of data-driven innovation. By aligning technical solutions with broader strategic goals, businesses can harness the full power of predictive insights to sustain competitiveness, foster customer loyalty, and enable agile adaptation to future market shifts.
