
Вступление. Создавая базу данных, пользователь стремится упорядочить информацию по различным признакам для быстрого получения нужных сведений с произвольным сопряжением критериев поиска. Необходимость автоматизации различных типов учета (складской, Бухгалтерский, учет кадров и т.п.) В рамках предприятия в некоторых случаях ведет к использованию «универсальных» учетных систем. Этот подход имеет ряд недостатков, среди которых перегруженность центральной базы данных (БД), низкая отказоустойчивость, уязвимость системы и недостаточно развитые механизмы учета большинства направлений автоматизации [1-2].
Анализ публикаций и последних достижений. Использование отдельных специализированных решений может решить приведенные недостатки, но ведет к появлению различных платформ систем управления базами данных (СКБД), требующих дальнейшей синхронизации. Поэтому, в развитии современных информационных систем прослеживается тенденция перехода от локальных БД к распределенным [3]. Основной задачей, распределенной СКБД является обеспечение управления доступом к данным многих потребителей, целостности и согласованности данных в условиях использования сети. То есть основная функция таких СКБД – это координирование совместной работы многих пользователей с распределенной информацией [5-7].
Решение проблемы автономности работы пользователей распределенной системы создает много специфических проблем в организации данных. Комбинированная стратегия распределения данных объединяет два подхода, связанных с распределением без дублирования и с дублированием данных, с целью использования их преимуществ [8]. Но при ее использовании, кроме задачи синхронизации дублированной информации, актуальной встает задача оптимального проектирования структуры БД с точки зрения принадлежности данных к категории того или иного узла распределенной БД. Кроме того, производительность системы напрямую будет зависеть от принятия решения о необходимости частичного или полного дублирования данных.
Обзор информационных систем при решении задач автоматизации различных типов учета в рамках одной организации и недостатков использования универсальных учетных систем [1-4] дал возможность обосновать необходимость оптимизации структуры удаленных узлов распределенной базы данных (РБД) путем определения полезных данных и минимизации объемов ее узла [8].
Целью работы является повышение уровня общей доступности данных в отдельном узле РБД и эффективности использования программных систем по работе с данными БД за счет уменьшения количества распределенных запросов. Цель достигается путем оптимизации структуры узла РБД и минимизации объемов данных, хранящихся в нем.
Во время выполнения исследования для достижения сформулированной цели были решены следующие задачи: выполнено исследование методов создания и использования формальных грамматик и разработана подсистема парсинга кода SQL-запросов к центральной БД; разработана модель и реализована подсистема учета пользовательской активности на основе профайлинга SQL-запросов по различным аналитическим характеристикам; выполнена детализация обращений пользовательских запросов к отношениям БД на уровне множеств атрибутов и кортежей; разработана информационная технология поддержки принятия решений при проектировании структуры узла распределенной БД и определении количества необходимых данных.
Изложение основного материала. При использовании комбинированного подхода представления данных в RBD выбор типа репликации зависит от нескольких факторов, в том числе от того, является ли тип запроса удаленным или распределенным. В случае удаленного запроса, когда взаимодействие с другими узлами необходимо только для обеспечения репликации данных, считается целесообразным использование асинхронной репликации [9-10]. Подобное решение обосновано возможностью исключить из транзакции все «лишние» узлы, оставив лишь один, на котором, фактически, находятся данные (рис. 1).

Рис. 1. Сравнение режимов репликации в случае удаленного запроса
При синхронизации данных в случае распределенного запроса взаимодействие с удаленными узлами не может быть вынесено за пределы транзакции. Это обусловлено тем фактом, что в распределенную транзакцию в любом случае входят фрагменты данных, хранящиеся на других узлах и не представленные на узле выполнения запроса. Учитывая этот факт, не представляется целесообразным вынесение процесса репликации за пределы транзакции [9, 11], поскольку уменьшение времени выполнения транзакции незначительно по сравнению с возможными противоречиями в данных, связанными с несинхронностью обновления (рис. 2).
Исходя из приведенного, при проектировании удаленного узла распределенной БД главной задачей на пути к повышению уровня общей доступности и эффективности использования программных систем по работе с данными БД является уменьшение количества распределенных запросов, в которых задействованы данные нескольких узлов БД, и замена их локальными [12-13].
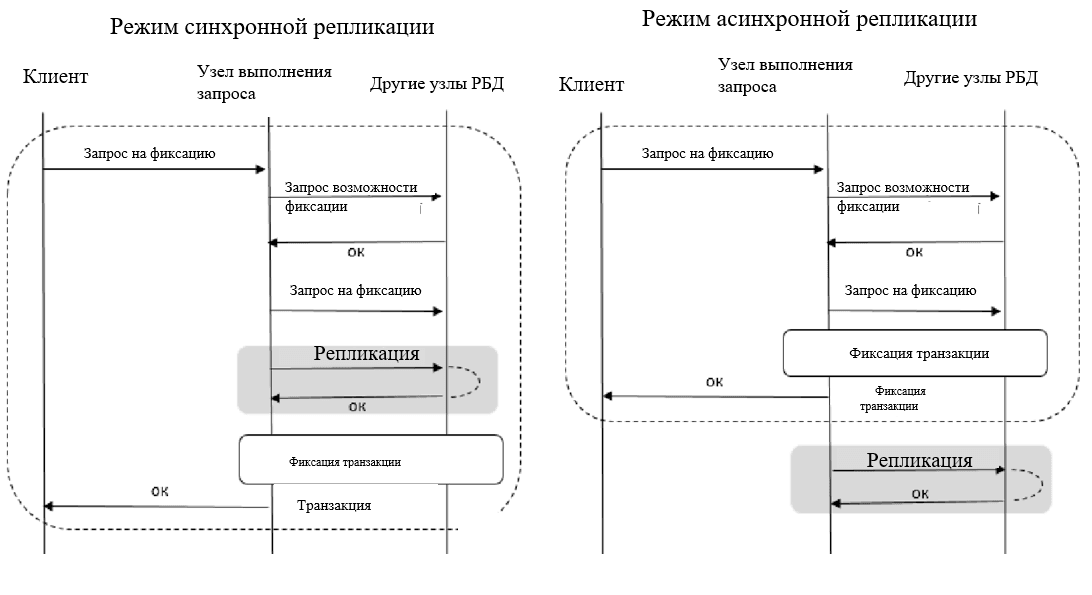 Рис. 2. Сравнение режимов репликации в случае распределенного запроса
Рис. 2. Сравнение режимов репликации в случае распределенного запроса
Для минимизации количества распределенных транзакций [14] в пределах удаленного узла РБД была создана подсистема учета пользовательских запросов с классификацией в соответствии с принадлежностью к тому или иному автоматизированному рабочему месту, географическому местоположению, роли пользователя и другим критериям, что возможно добавить к системе динамически при ее использовании согласно особенностям той или иной предметной области. Даталогическая архитектура разработанной модели приведена на рис. 3.
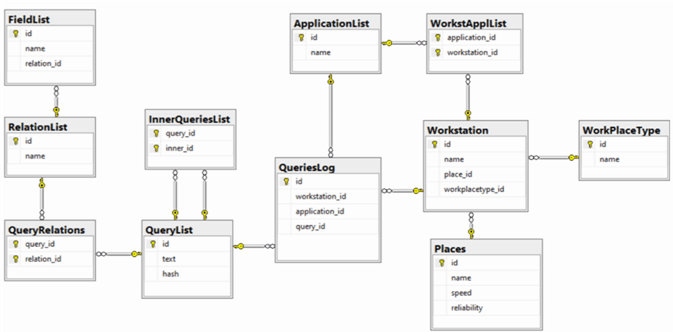
Рис. 3. Даталогическая модель подсистемы профайлинга пользовательских SQL-запросов
Центральное место занимают журнал и справочник пользовательских запросов (таблицы QueriesLog и QueryList). Если запрос является вложенным или имеет несколько уровней, его древовидная структура описывается с помощью таблицы InnerQueriesList. Запросы классифицируются по типу программного обеспечения, рабочей станции, пользователя и местоположения (привязка к будущим узлам RBD), из которого они поступают (таблицы Workstation, Places, ApplicatioList, WorksAppList и WorkPlaceType). Исходя из приведенной структуры, также видим, что введение в систему дополнительных аналитических характеристик, которые могут понадобиться в зависимости от той или иной предметной области, не потребует больших изменений в БД. После выполнения парсинга кода SQL-запросов (парсинг – процесс преобразования исходного кода в структурированный вид), они также разбиваются по списку таблиц БД, которые встречаются в запросе, а также, после выполнения более глубинного анализа, по списку атрибутов и кортежей отношения (таблицы QueryRelations, RelationList и FieldList).
Наполнение разработанной модели входными данными реализовано с помощью механизмов профайлинга СКБД. В рамках исследования был выбран программный продукт SQL Profiler, входящий в стандартный установочный пакет SQL Server. Этот выбор обусловлен достаточным перечнем аналитических свойств, придающим функционал программному обеспечению (ПО), и совместимостью с версией СКБД, используемой на предприятии – базе автоматизации. При изменении входных условий выбор может быть изменен в пользу другого ПО.
Подсистема имеет пользовательский интерфейс, состоящий из форм ввода и редактирования данных для основных сущностей. Предусмотрены механизмы импорта данных из текстовых И.csv файлов для возможности взаимодействия со сторонними программными продуктами (например, при решении задач получения списков пользователей, программного обеспечения или рабочих станций). Некоторые объекты также могут быть заполнены данными на основе результатов статистической выборки пользовательских SQL-запросов.
Для выполнения дальнейшего аналитического анализа накопленных статистических данных необходимо выделение конкретных отношений (а также ссылок на их атрибуты и кортежи) из текста пользовательских запросов. Для решения этой задачи использованы средства разбора и лингвистического анализа текста. SQL, как и каждый язык программирования, имеет правила, определяющие синтаксическую структуру корректных программ. Синтаксис конструкций языка программирования может быть описан с помощью контекстно-свободных грамматик или нотации БНФ (Backus-Naur Form, форм Бэкуса-Наура).
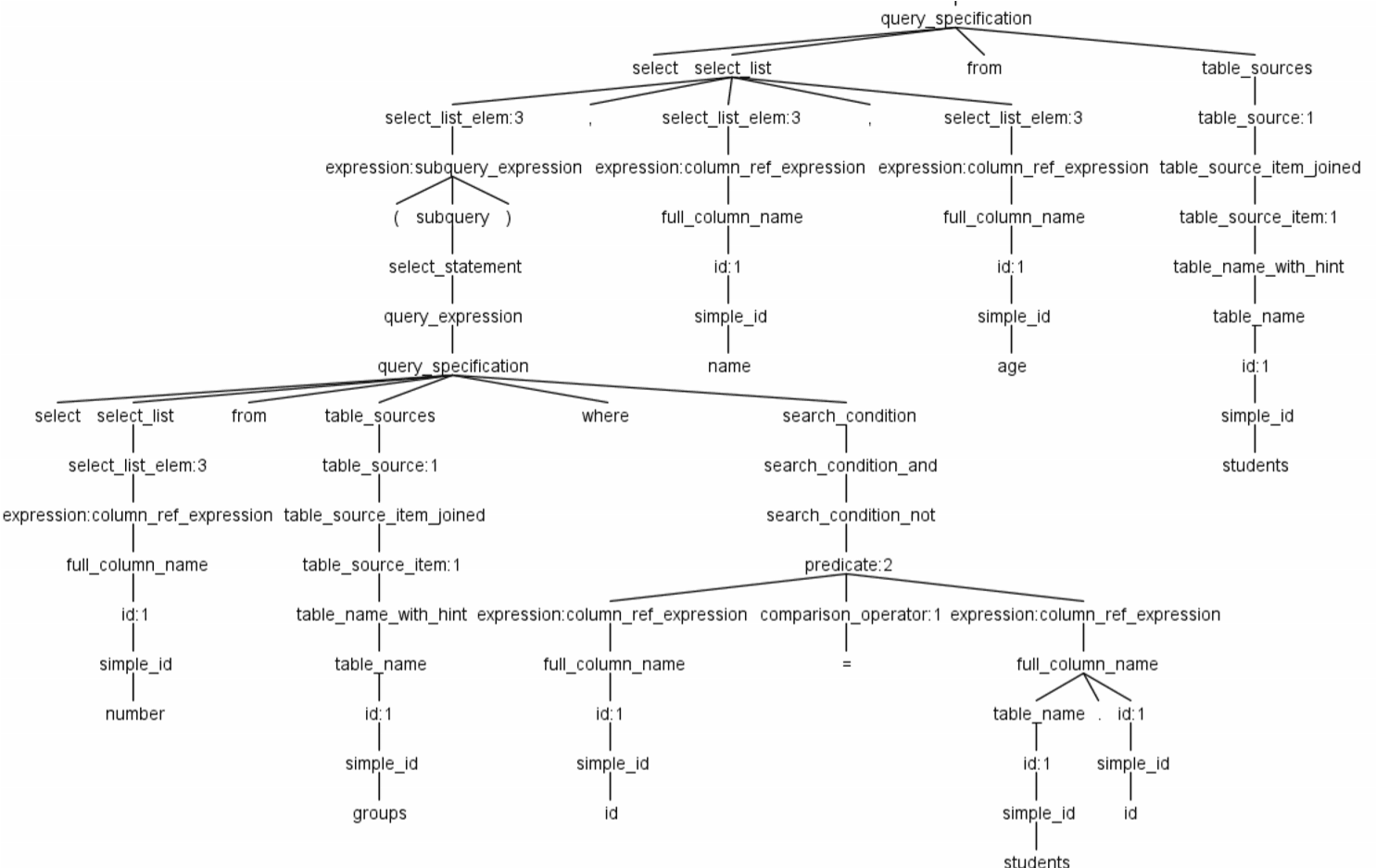
Рис. 4. Дерево парсинга запроса T-SQL
Использованный в рамках исследования генератор парсеров ANTLR является LL ( * ), он существует уже более 20 лет, а в 2013 г. вышла его 4-я версия. Сейчас его разработка ведется на GitHub. В настоящее время он позволяет создавать Парсеры на языках Java, C#, Python2, Python3, JavaScript. Начальным этапом реализации подсистемы парсинга T-SQL запросов является создание грамматики. Далее, сгенерированные классы лексера и парсера дают возможность представить код запроса в виде древовидной модели, на базе которой происходит определение списка отношений и атрибутов, которые были использованы в запросе. На рисунке 4 показано дерево иерархии элементов для запроса «select (select number from groups where id=students.id), name, age from students», что обращается к нескольким атрибутам и имеет в своем составе один вложенный запрос.
Далее каждый запрос представляется в виде объекта, имеющего следующие атрибуты: рабочая станция, пользователь и ПО, от которых поступил запрос; сам текст запроса; коллекция таблиц, к которым обращается запрос; и коллекция вложенных запросов, если таковые имеют место. Сущность «таблица» (TsqlRelation) в этом случае является подмножеством таблицы БД и содержит имя таблицы, набор атрибутов, задействованных в запросе, и набор значений первичного ключа таблицы в соответствии с набором кортежей, возвращаемых в результате работы запроса [15, 16]. Фрагмент диаграммы классов информационной технологии парсера SQL-запросов изображен на рис. 5.

Рис. 5. Классы, отвечающие за представление запросов в модели
Итак, на этом этапе у нас есть множество отношений с атрибутами, используемыми в запросе. Этого достаточно для определения списка таблиц, представленных в узле РБД, и для ограничения общего количества данных из-за выполнения операции проекции к ним. Однако этого может быть мало, поскольку обычно в БД учетных систем существуют таблицы с большим количеством кортежей, занимающие много места на диске и создающие дополнительную нагрузку при выполнении запросов к ним. При этом, в том или ином узле РБД реально используется достаточно небольшой процент от общего объема входящих в них данных.
Следующий шаг-определение множества кортежей, используемых в том или ином запросе. Для этого дополняем класс TsqlRelation коллекцией типа TsqlField, определяющей первичный ключ отношения. В случае, если первичный ключ в отношении отсутствует или он состоит из большого количества атрибутов нечислового типа данных, и, как следствие, имеет большой объем, на уровне БД может быть создано уникальное автоинкрементное поле not null, которое будет использоваться в дальнейшем для идентификации кортежа.
Далее, если запрос имеет в своем составе вложенные запросы, каждый из них обрабатывается отдельно. Для каждой таблицы из коллекции отношений запроса выполняется дополнительный запрос к БД, список атрибутов в котором заменяется на первичный ключ отношения. Результат запроса запоминается как набор атрибутов таблицы, используемых текущим запросом. Так, например, в случае поступления запроса, выбирающего фамилии студентов с номерами студенческих групп из двух таблиц с использованием вложенного запроса для фильтрации по специальности (рис. 6), он будет разбит на следующий набор запросов (рис. 7).

Рис. 6. Пример входящего запроса

Рис. 7. Список запросов для получения множеств атрибутов отношений, используемых входным запросом
После обнаружения множеств атрибутов появляется возможность определения полезного для узла РБД подмножества данных с использованием фильтрации таблиц по значению первичного ключа, что дает возможность разместить подавляющее большинство необходимых узлу данных локально и, соответственно, снизить количество распределенных запросов. При этом объем данных локального узла также является минимальным, что, в свою очередь, минимизирует потребность в синхронизации различных версий одних и тех же данных.
Однако в процессе эксплуатации описанной технологии возникает проблема, связанная с модификацией данных БД: когда к таблицам добавляются новые данные, существующие модифицируются или удаляются. В этом случае самым простым вариантом решения проблемы является репликация удаленного узла БД всех новых или измененных данных (поскольку мы не знаем степени их полезности для узла). Когда же объем этих данных достигает некой критической точки, исходя, например, из соображений нагрузки при выборке данных или их синхронизации, необходимо заново провести анализ SQL-запросов и выполнить обновление базы использования атрибутов и кортежей таблиц БД удаленным узлом.
Следует заметить, что выполнение полного анализа используемости атрибутов и кортежей таблиц БД является достаточно ресурсоемкой операцией и не может выполняться часто, поэтому вышеприведенный подход является неприемлемым для больших и часто изменяемых БД. Поэтому было предложено представить проблему с решением полезности новых или измененных данных в виде задачи классификации интеллектуального анализа данных. На входе у нас есть имя таблицы и список значений ее атрибутов (новая или измененная строка), а на выходе – решение о ее полезности для удаленного узла БД. Для решения этой задачи предложено использовать нейронную сеть прямого распространения [17] с одним скрытым слоем. Обучение сети происходит на базе данных, полученных в результате анализа результатов парсинга SQL-запросов. Затем, после обучения, сеть выполняет классификацию новых и измененных данных.
Учитывая необходимость выполнения анализа накопленных данных с точки зрения множественности измерений, а также, вероятно, большие их объемы, было выполнено представление данных, необходимых для анализа, в виде многомерной модели [18]. Для этого на уровне РБД информационной системы учета пользовательских запросов вводится ряд представлений, реализующий таблицу фактов и таблицы измерений в виде схемы «звезда». Структура полученного многомерного Куба изображена на рис. 8.
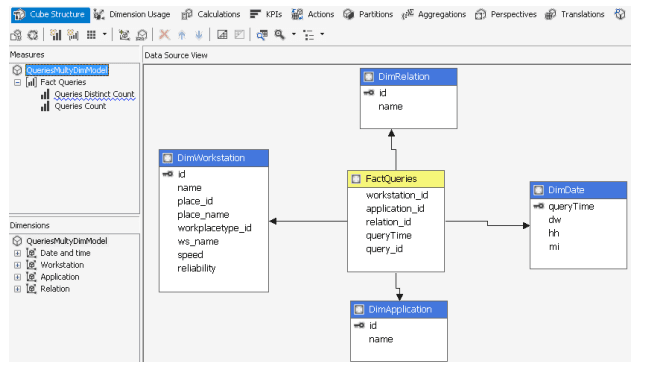
Рис. 8. Структура многомерного Куба подсистемы оперативно-аналитического анализа запросов
Выводы. В ходе исследования впервые предложено использование многоуровневых справочников аналитических характеристик пользовательских SQL-запросов с оценкой степени актуальности данных; разработана подсистема парсинга SQL-запросов, что дает возможность представить пользовательский запрос в виде множеств отношений с детализацией к использованным атрибутам и кортежам. Также впервые при анализе пользовательских SQL-запросов использована многомерная модель данных и на ее базе реализована система поддержки принятия решений при проектировании структуры удаленного автоматизированного рабочего места, что позволяет проводить оперативно-аналитический анализ SQL-запросов по измерениям, быстро и эффективно выполнять операции консолидации, детализации, вращения и среза. При модификации данных Центральной БД предлагается использовать нейронную сеть для решения задачи классификации новых или измененных данных в соответствии со степенью их полезности для удаленного узла РБД.
Результаты исследования были произведены при разработке структуры БД автоматизированного рабочего места кассира супермаркета и при реализации дальнейшей синхронизации с центральной БД. Результат выполненного сравнительного анализа при использовании централизованной и РБД приведен в таблице.
Таблица
Сравнительный анализ использования централизованного и распределенного подходов к реализации структуры БД
| Централизованная БД | БД независимого АРМ | Разница |
Объем БД, мб | 29025,63 | 174,88 | 165 раз |
Количество таблиц | 460 | 34 | 14 раз |
Время резервного копирования БД, | 7:58 | 0:13 | 37 раз |
Среднее количество подключений к БД | 59,75 | 1,02 | 58 раз |
Среднее количество запросов в Мин | 817 | 44 | 19 раз |
Среднее время обработки, мс | 5665 | 99 | 57 раз |
Время синхронизации, сек | 0 | 18 | Необходимость синхронизации данных |
Независимость от центрального сервера БД | Нет | Да | Независимость от центральной БД |
Независимость от коммуникационного оборудования | Нет | Да | Независимость от центральной БД |
Следовательно, результатом является повышение скорости работы информационной системы удаленного автоматизированного рабочего места и разгрузка центральной БД за счет оптимизации структуры РБД и минимизации распределенных транзакций и использования синхронного режима репликации данных.
