
Введение. Распределенные системы баз данных используются во многих отраслях цифровой индустрии – от онлайн-магазинов и до медицинских учреждений. Важность поддержания данных в актуальном состоянии и разрешение коллизий при их обмене выходит в таких системах на первый план. В связи с этим существует множество готовых систем, предлагающих сервис синхронизации данных с теми или иными источниками, с разной инфраструктурой и различным функционалом. Множество сервисов являются крайне громоздкими ввиду своей универсальности, и поэтому обеспечение некоторых характеристик не позволяет их использовать в определенных сценариях. Другие сервисы не предоставляют шифрование и аутентификацию при передаче чувствительных данных. В перечисленных случаях для разработчика возникает дилемма: тестировать и затем адаптировать готовое решение в свою разработку, рискуя потратить на поиск наиболее подходящего сервиса значительные ресурсы, либо создавать свою собственную специализированную систему с нуля и организовывать обмен данными в строгом соответствии с запросами системы. Эта статья призвана помочь в разработке такой системы.
Требования к системе. Обозначим здесь основные общие требования, предъявляемые к любой системе работы с данными [1, 4, 9], указав, однако и дополнительные пункты, соблюдение которых при разработке системы значительно облегчит ее интеграцию и эксплуатацию в дальнейшем:
- Обеспечение консистентности данных. Любой процесс передачи данных по каналам связи сопряжен с риском потери или искажения их на принимающей стороне. Любая система обмена информации обязана иметь механизмы по обеспечению целостности данных и их восстановлению, в случае если сбои все же происходят.
- Возможность разрешения конфликтов. Частая проблема систем работы с распределенными данными – возникновение конфликтов (коллизий) данных при обработке их в разных местах, а также при возникновении проблем в п. 1. Система должна обеспечивать учет всех изменений записей с данными, добавление и удаление записей согласно заданным бизнес-правилам.
- Скорость синхронизации. Во многих случаях, особенно если ситуация связана с сервисами предоставления информации большому числу пользователей или работа большого числа станций, скорость обмена единицей информации (записями) должна быть максимально возможной. Второе значение скорости раскрывается, когда периодически возникает потребность в синхронизации большого объема данных единовременно. Система должна обеспечить максимальную скорость передачи именно большого объема данных. Приведенные выше ситуации во многом являются взаимоисключающими, так как подготовка данных в разных случаях должна производиться по-разному. В итоге для реализации системы, удовлетворяющей второй ситуации, мы теряем на накладных расходах ресурсов в производительности при наличии первой ситуации.
- Обеспечение защиты данных при обмене. Как и любой другой обмен данными по сети, процесс синхронизации данных должен поддерживать как минимум базовую защиту информации. Существует достаточно много способов как аутентификации при осуществлении передачи данных, так и полного сокрытия исходных данных в явном виде от стороннего наблюдателя. Отдельно стоит упомянуть момент подлога сообщения – когда одно и то же сообщение, штатно аутентифицированное системой, посылается злоумышленником повторно с целью дестабилизации системы или другим разрушительным умыслом. Поэтому целесообразно заранее продумать нюансы аутентификации и обмена данными учитывая эту ситуацию.
- Использование открытого программного обеспечения. Несмотря на то, что проприетарное программное обеспечение обеспечивает необходимые стандарты качества, оно также обладает и рядом недостатков, первый из которых – невозможность внести изменения в поведение системы в произвольном порядке. Также известные системы статистически заметно чаще подвергаются атакам злоумышленников. Вследствие этого постоянно обнаруживаются те или иные уязвимости, устранение которых требует времени и подвергает дополнительному риску компрометации данных всей системы. С учетом того, что подобного рода комплексы синхронизации представляют собой широко универсальные системы с большим количеством кода, в них, как и в любой сложной системе, наблюдается сравнительно высокое количество уязвимостей, чем в сугубо специализированных системах, спроектированных под конкретную задачу.
- Масштабируемость. Применительно к определенным проектам, которые впоследствии могут получить широкое распространение и будут вынуждены масштабироваться, система также обязана включать в себя элементы, позволяющие значительно увеличить ее производительность без глобальных переделок архитектуры.
- Возможность хранения истории изменений и аудита синхронизации. В некоторых случаях такая опция будет крайне полезной для идентификации параметров (например пользователя) не только последнего изменения, но и всей цепочки изменений. Особенно это становится важным при редактировании одной и той же записи одновременно несколькими пользователями при разборе и устранении коллизий.
- Многопоточность системы. Система должна обеспечивать параллельную работу процессов синхронизации для различных потоков (или каналов). Данные между узлами взаимодействия могут объединяться в каналы по принципу участия в одних и тех же частях бизнес-процесса. При этом процессы синхронизации каналов не блокируют друг друга, работают параллельно и асинхронно. Однако же, в одном и том же канале данные синхронизируются в строго определенном порядке и синхронно.
- Наличие специальных функций системы. Для управления узлами синхронизации у системы должен быть интерфейс управления. Через интерфейс управления система должна иметь возможность активировать специальные управляющие функции: приостановку процессов синхронизации по определенной таблице, каналу или по узлу в целом, возобновление процессов синхронизации, перезагрузку всех данных одной таблицы из одного узла в другой, перезагрузку всех данных всех таблиц канала, отправка запросов на соседний узел на перезагрузку данных таблицы или таблиц канала. При этом операции полной перезагрузки данных не должны приводить к потере изменений, которые образовались в процессе перезагрузки в исходной таблице или таблицах канала.
- Маршрутизация данных для синхронизации на определенные целевые узлы. Изменения в определенной таблице или в канале должны оправляться на целевые узлы, которые определяются настроенными правилами маршрутизации. Более того, система должна определять источник, вызвавший конкретные изменения для того, чтобы построить правильный маршрут передачи данных на целевые узлы.
- Минимальное использование ресурсов подчиненной базы данных и наличие сценариев обработки ситуаций обрыва связи с узлом. В процессе синхронизации данных одного и того же канала на множество других узлов синхронизации система должна выполнить минимальное количество запросов изменившихся данных, которые должны быть собраны в структуру и копии собранной структуры должны передаваться на целевые узлы. При этом, в случае отсутствия связи с каким-либо целевым узлом, система должна кэшировать неотправленные структуры в памяти или на диске. При длительном отсутствии связи допускается сброс кэшированных данных, соответственно, при возобновлении связи могут применяться сценарии либо полной перезагрузки таблицы/канала, либо запрос и передача актуальных на текущий момент времени данных по изменениям, которые накопились за время отсутствия связи с узлом. Эти сценарии, а также глубина и тип хранилища кэшированных данных должны настраиваться для каждого канала.
- Модификация передаваемых данных в процессе синхронизации от одного узла к другому. Необходимо, чтобы в системе настраивались правила модификации передаваемых данных одной таблицы в зависимости от значений определенных полей. Также для определенных каналов необходимо иметь возможность настроить вызов хранимой процедуры в блоке транзакций в начале этого блока или в конце (например, принимающий узел может создать временную таблицу, загрузить в нее измененные данные, модифицировать их согласно своей бизнес-логике, перегрузить данные из временной таблицы в постоянную и удалить временную таблицу).
- Гибкость системы. Любой проект базируется в первую очередь на техническом задании. Однако в процессе развития часто появляется необходимость в реализации функций, изначально отсутствующих в проектной документации, поэтому важен баланс между узкой специализацией системы и обеспечением максимальной гибкости функционала, либо возможности внедрения нового функционала также без глобальной переделки архитектуры системы.
- Легкость в разработке, интеграции и обслуживании. При проектировании коммерческих проектов важным параметром является скорость разработки компонентов проекта. Грамотный выбор платформы разработки может существенно упростить задачу. Однако необходимо предусмотреть дальнейшую работу с системой в рамках обслуживания и возможной интеграции системы в другие проекты.
Пример проектирования системы. Рассмотрим общий случай задачи двусторонней синхронизации в многоуровневой централизованной иерархической распределенной системе хранения данных [2] (рис. 1).
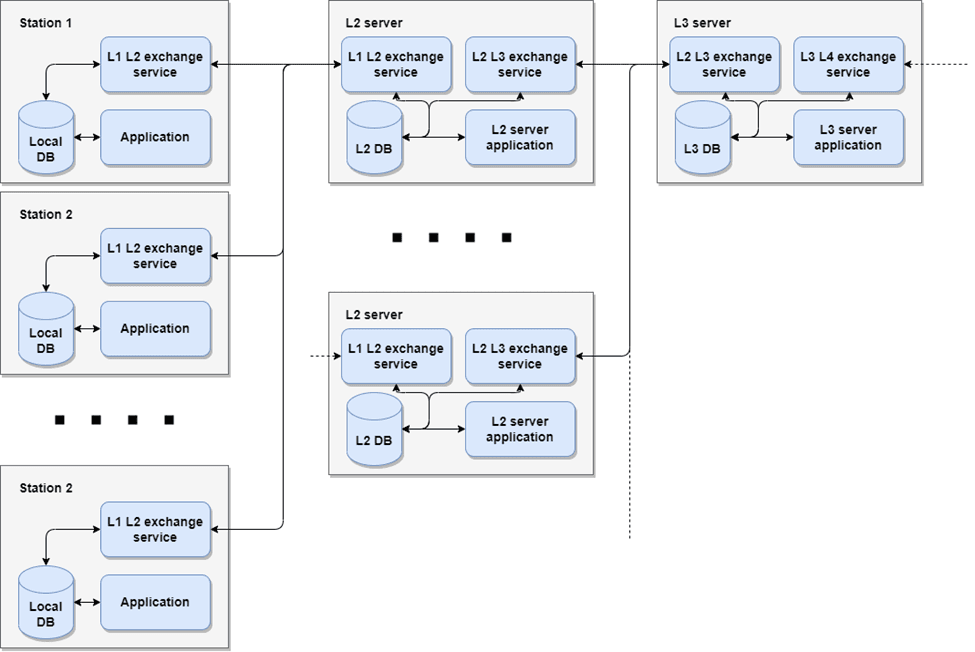
Рис. 1. Общая структурная схема распределенной иерархической системы
Конечные станции пользователя Station 1…Station n имеют локальную базу данных и приложение Application, использующее данные из этой базы. Такие решения применяются везде, где бесперебойность и скорость доступа к данным играют ключевую роль. Базы данных необходимо поддерживать в актуальном состоянии согласно последним изменениям на удаленном сервере L2 server, а данные этого сервера должны быть синхронизированы с базой L3 server и так далее. Такой прием построения распределенной сети [7] обеспечивает следующие выгоды по сравнению с прямой синхронизацией L3 server – Station n:
- минимизирована зависимость конечных станций системы от изначального хранилища. Так как хранилище единственное, то любой отказ системы приведет к полной остановке синхронизации. Промежуточные узлы в этой цепочке могут выступать в роли накопительного демпфера и резервной системы синхронизации Station n – L2 server. Также появляется возможность различным образом аутентифицировать данные передаваемые с Station n на L2 server и с Server на L2 Server L3, что позволяет существенно сократить накладные расходы на кодирование данных, особенно при нахождении станций и L2 server в одной защищенной локальной сети.
- При большом количестве станций Station n решение позволяет существенно снизить нагрузку на серверы L3 server, так как рассылка данных большому количеству конечных станций требует как больших вычислительных ресурсов (преимущественно память), так и высокой пропускной способности сетей.
- Наконец, третья выгода обусловлена территориальным распределением узлов [5] (серверов L3 server, L2 server).
При этом обмен данными происходит как от станций к серверу, так и в обратном направлении. Также учтем, что не все таблицы локальных баз данных подлежат синхронизации. В свою очередь сервер L2 обменивается данными с агрегационным сервером более высокого уровня. Для аудита содержимого БД на серверах также предусмотрено специальное ПО – L2 server application, напрямую подключенное к своей БД.
Таким образом, задача обмена данными сводится к программированию модулей работы с базами данных и обмена L1 L2 exchange service, L2 L3 exchange service и так далее.
Для максимизации производительности целесообразно разделить всю систему синхронизации на конкретной машине на две независимые подсистемы. Первая работает непосредственно в БД и осуществляет регистрацию изменений в записях контролируемых таблиц (рис. 2).
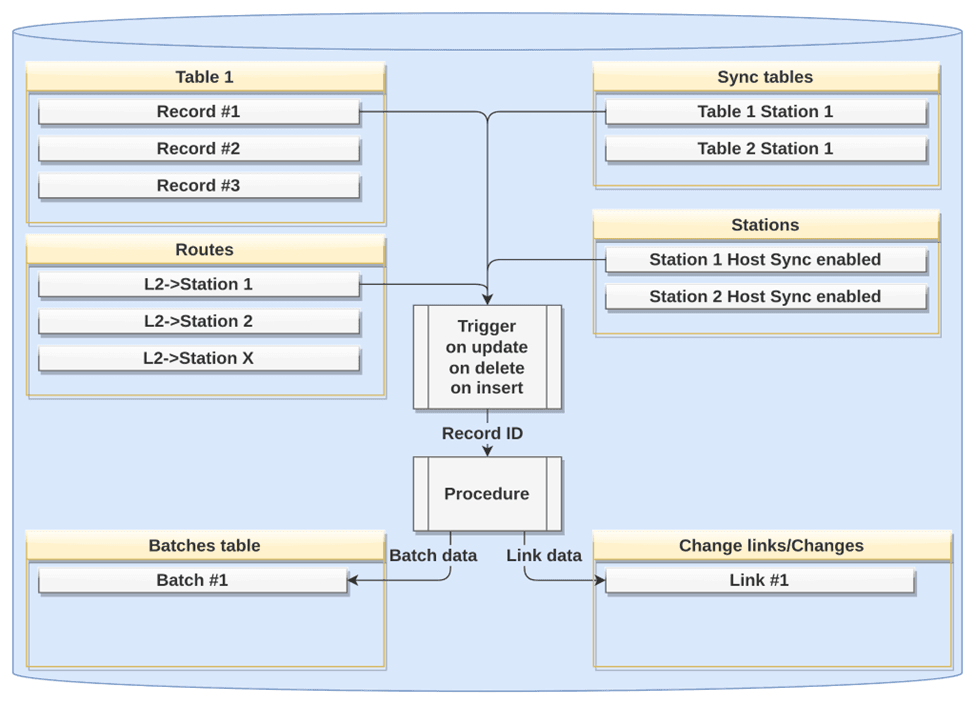 Рис. 2. Вспомогательные структуры БД
Рис. 2. Вспомогательные структуры БД
Для осуществления функционирования этой подсистемы в БД предусматриваются вспомогательные и настроечные таблицы:
1. Table 1. Контролируемая таблица, в которой фиксируются изменения (вставки, обновления, удаления строк).
2. Sync tables. Таблица содержит список контролируемых таблиц, а также обслуживаемые конкретно этой таблицей станции. При необходимости контроля только определенных полей таблицы целесообразно адаптировать информацию в Sync tables соответствующим образом. В этой же таблице содержится и флаг, с помощью которого можно оперативно отключить контроль.
3. Таблица с записями настроек маршрутизации, которые позволяют передавать изменения информации в определенной контролируемой таблице на заданные целевые узлы.
4. Stations. В таблице содержатся сведения о внешних узлах, которые необходимо поддерживать в актуальном состоянии (как нисходящие – станции пользователя, так и восходящие – в нашем примере серверы L3, если мы рассматриваем непосредственно сервер L2). В этой таблице также имеется флаг отключения синхронизации для выбранного узла.
5. Change links/Changes. Хранение информации об изменениях может осуществляться двумя принципиально разными путями:
- В таблице Change links содержатся ссылки на изменившиеся строки в исходной таблице Table 1. Этими ссылками могут быть значения первичного ключа таблицы (или любого другого уникального ключа). По каждой ссылке в этой таблице однозначно определяется одна изменившаяся запись в исходной таблице. Также в записях данной таблицы указывается тип изменения строки в исходной таблице (например: I – вставка, U – обновление, D – удаление), а также ссылка на запись в таблице “Batches table”. Этот подход менее ресурсоемкий, однако, если в таблице быстро произошли изменения одной и той же записи по схеме: A -> B, B -> C, то система на целевой хост передаст изменение вида: A -> C, т.е. Изменение B будет утеряно. Если бизнес-логика приложения на целевом хосте допускает такую потерю, то рекомендуется использовать именно этот подход.
- В таблице Changes записи содержат ссылки на изменившиеся строки в исходной таблице Tables 1 в виде первичного ключа таблицы (или любого другого уникального ключа), а также сами строки в преобразованном виде, записанные сразу после изменения (например, могут содержаться в текстовом виде с использованием разделителя, либо в бинарном виде). Этот подход лишен недостатка, указанного в пункте выше, однако, он более ресурсоемкий и требует ресурса хранения как минимум такого же, какой использует исходная таблица. Более того, при достаточно высокой интенсивности изменений, запросы от службы синхронизации в таблицу Changes будут требовать больше времени и ресурсов системы. Для нивелирования данного недостатка допускается использовать кэширование данных не в таблицу БД, а в отдельные файлы, указывая в таблице Changes пути до файла с измененными данными. Этот подход рекомендуется использовать там, где бизнес-логика приложения целевого узла базируется на полном воспроизведении изменений данных в таблице исходного узла.
6. Batches table. Таблица заданий на синхронизацию с каждым из целевых узлов. Содержит непосредственные сформированные задания, генерируемые при каждом завершении транзакции в контролируемой таблице. Одна запись задания объединяет в себе ссылку на узел, которому предназначается передача изменений по этому заданию, а также ссылка на записи изменений в таблице Change links. Кроме того, запись задания содержит поле, обозначающее статус выполнения задания (например, NW – новое задание, QY – идет построение структуры, содержащей измененные данные из исходной таблицы, LD – передача данных на целевой узел, OK – синхронизация по заданию завершена, ER – ошибка синхронизации). Эти задания затем группируются и преобразуются второй подсистемой в посылки данных на определенные узлы.
Все эти таблицы обслуживает система триггеров Trigger, настроенных на изменение, добавление или удаление записей. Триггер вызывает процедуру Procedure, которая агрегирует и подготавливает данные, затем записывает их в таблицы Change links/Changes и Batches в соответствии с настроечными данными. На этом работа подсистемы в БД окончена, в работу включается внешний сервис синхронизации – вторая подсистема (рис. 3).
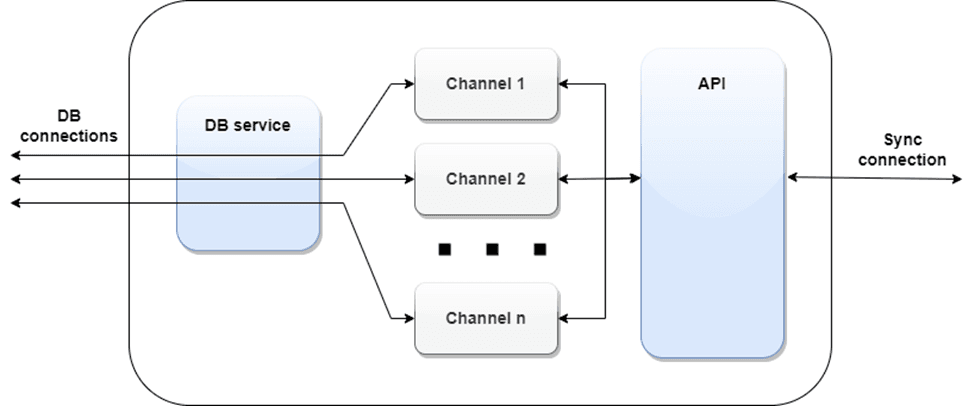 Рис. 3. Структура второй части системы синхронизации
Рис. 3. Структура второй части системы синхронизации
Эта подсистема с одной стороны имеет подключение к локальной БД узла, а с другой стороны интерфейс API обмена данными со следующими в иерархии узлами. Это может быть, например, REST API, WEBSOCKET или другой, удовлетворяющий политике разработки.
Задания на синхронизацию целесообразно разделить на изолированные каналы [7, 11], в которых процессы синхронизации будут проходить параллельно и независимо друг от друга. Количество различных каналов и соответствия каждой таблице определенному каналу должно настраиваться в момент разворачивания системы. Распределение таблиц по каналам должно быть сообразным бизнес-логике приложений, развернутых на узлах синхронизации.
Приведем здесь поясняющий пример (рис. 4): в приложении магазина (на рабочих станциях) имеется список товара с его характеристиками (таблица Stock_descriptions), наличием на складе (таблица Stock_counts) и ценой (таблица Stock_prices). При приходе новой большой партии товара на склад (L3 server), производится большое число изменений записей таблицы, показывающей наличие товара. Эти данные должны быть синхронизированы с локальной базой магазина, а также с каждой рабочей станцией магазина (L3 server -> L2 server -> Station n). Однако кроме этого процесса есть процесс покупки пользователем товара (таблицы Transactions, Receipts). Для учета совершения операции покупки необходимо синхронизировать информацию с аккаунтом пользователя, например списать бонусные баллы (таблица Clients). Операция передачи списания бонусных баллов более приоритетная и важная, чем операция передачи информации о проданном товаре в магазине, поскольку эта операция прямо влияет на финансовую составляющую бизнес-логики системы. Также, операция синхронизации изменения баланса бонусов клиента с базы данных склада (L3 server) по остальным магазинам также более приоритетная, чем операция синхронизации изменения количества товара на складе.
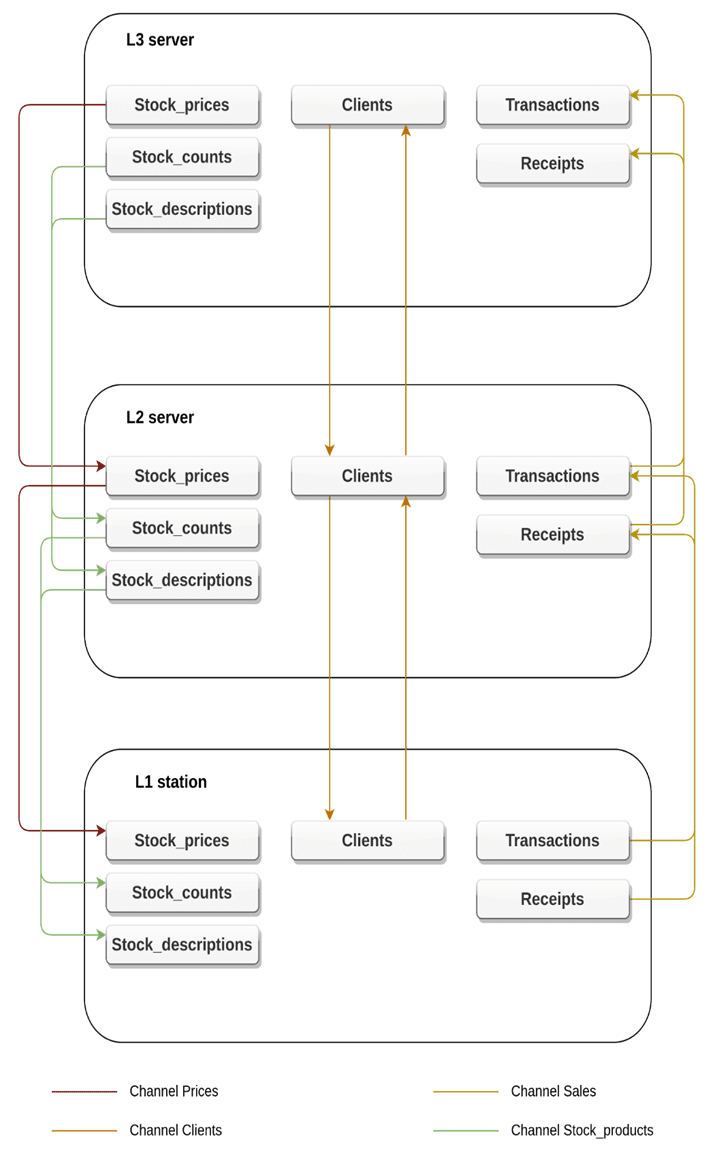
Рис. 4. Пример организации таблиц и каналов синхронизации данных
В то же время операция синхронизации данных по ценам товаров с базы данных склада (L3 server) более приоритетная, чем операция передачи количества и характеристик товара и операция передачи изменений баланса бонусных карт клиентов.
Соответственно, при проектировании каналов системы синхронизации таких данных должно основываться на:
- критичности данных для бизнес-логики;
- объема передаваемых данных;
- частоте передачи обновлений.
В конкретном примере есть смысл распределить таблицы по каналам следующим образом:
- Канал Prices: таблица Stock_prices, приоритет 1 (наивысший);
- Канал Clients: таблица Clients, приоритет 2;
- Канал Sales: таблицы Transactions и Receipts, приоритет 3;
- Канал Stock_products: таблицы Stock_counts, Stock_descriptions, приоритет 4 (низший).
Как видно из примера, один канал необязательно обслуживает одну таблицу. Обычно данные, требующие одинакового приоритета при синхронизации, можно разместить в одном канале. Таким образом, наличие отдельных каналов позволяет нивелировать влияние одного потока данных на другой, а в случае нештатных ситуаций избежать полной остановки передачи данных.
Заключение. Авторы показали важность грамотного подхода к проектированию отказоустойчивой распределенной иерархической системы синхронизации данных между узлами реляционных баз данных и привели наглядный пример архитектуры такой системы. Как было показано, структура возможных решений может быть реализована по-разному в зависимости от конкретной задачи и логики функционирования распределенного комплекса. Также уделено особое внимание аспекту оптимального использования ресурсов и приведены решения, позволяющие использовать имеющиеся ресурсы наиболее эффективным способом. Архитектура решения, в которой учитываются приведенные в статье рекомендации авторов, позволяет построить отказоустойчивую распределенную систему с практически любым количеством узлов и иерархических уровней, большой скоростью передачи информации, а также с практически неограниченными возможностями масштабирования.
