
Введение
В условиях быстро меняющегося ландшафта цифровых индустрий необходимость использования возможностей данных для принятия решений усилилась. В широком спектре аналитических методологий предиктивная аналитика, характеризующаяся использованием сложных алгоритмов для прогнозирования будущих событий и поведения, заняла важное место. Несмотря на его широкое применение в различных секторах, таких как маркетинг, телекоммуникации, здравоохранение и розничная торговля, сохраняется заметная пропасть между его концептуальным потенциалом и практической реализацией.
Рынок сталкивается с фундаментальным затруднением фрагментарным пониманием предиктивной аналитики. Предприятия часто признают его внутреннюю ценность, но при этом сталкиваются с проблемой определения и внедрения соответствующих методов, адаптированных к их специфическим требованиям. Некоторые отрасли, в частности розничная торговля и телекоммуникации, сталкиваются с проблемой эффективного внедрения предиктивной аналитики в свои операционные системы, надеясь, что эти прогностические идеи приведут к ощутимому улучшению бизнес-результатов.
Клиенты, хотя и с энтузиазмом относятся к использованию преимуществ предиктивной аналитики, часто сталкиваются с препятствиями. Они сталкиваются с целым рядом проблем, связанных с агрегированием и уточнением данных, разумным выбором методологий моделирования и, что особенно важно, прагматичным использованием идей, полученных на основе этих моделей.
Более того, обширная сфера знаний, окружающая предиктивную аналитику, остается в состоянии постоянного изменения. Несмотря на то, что существует понимание ее различных проявлений – описательных, диагностических, прогностических и предписывающих, – во многих профессиональных областях наблюдается дефицит глубоких знаний, особенно в том, что касается плавного перехода между этими формами.
Общая трудность очевидна – теоретический потенциал предиктивной аналитики находится в резком противоречии с ее практическим применением.
Данная методология направлена на преодоление этой пропасти. Она сосредоточена на технологиях и инструментах, имеющих ключевое значение для выполнения предиктивной аналитики, с особым акцентом на повышение эффективности бизнеса за счет интеграции систем и продуктов предиктивной аналитики. Кроме того, включение машинного обучения, которое меняет правила игры в современном мире, основанном на данных, является важным компонентом в этом уравнении.
Основная цель состоит в том, чтобы оценить текущее состояние систем и продуктов предиктивной аналитики и оценить их потенциал для повышения эффективности бизнеса. Для достижения этой цели была принята многогранная методология, охватывающая общие логические методы, такие как описание, анализ, синтез, моделирование, обобщение и сравнительный анализ. Наряду с этим, передовые методы анализа данных, включая контролируемое машинное обучение, регрессионный анализ (с особым акцентом на модель ARIMA, реализованную на Python), многомерный статистический анализ (такой как кластерный анализ с помощью Python, анализ "что, если" и комбинированный "ABC-XYZ-анализ", реализованный в Qlik Sense), были наняты.
Цель состоит в том, чтобы гарантировать, что обещания, содержащиеся в предиктивной анализе данных, преобразуются в поддающиеся количественной оценке результаты.
Заметной инновационностью, представленной в этой методологии, стала разработка регрессионных моделей, в частности модели ARIMA, использующей контролируемое машинное обучение (реализованное на Python) для прогнозирования продаж. Кроме того, был применен кластерный анализ с использованием контролируемого машинного обучения, также выполненного на Python, с целью прогнозирования моделей поведения клиентов.
В последующих разделах будет проведено углубленное изучение нюансов предиктивной аналитики. Это будет включать в себя презентацию методического подхода к решению перечисленных проблем и определение четкой траектории для предприятий, стремящихся использовать преобразующий потенциал, заложенный в прогнозном анализе данных.
I. Теоретические основы предиктивной аналитики
1.1. Краткое введение в бизнес-аналитику и ее инструменты
В эпоху, характеризующуюся быстрым распространением цифровых технологий и неустанным технологическим прогрессом, первенство анализа данных как основы для принятия взвешенных решений вышло на первый план. Однако внутренняя ценность, заключенная в хранилищах данных, остается скрытой до тех пор, пока она не подвергнется тщательной обработке и проницательной интерпретации, тем самым создавая способность прогнозировать будущие тенденции и подкреплять процессы принятия взвешенных решений [8].
Цифровые технологии произвели революцию в традиционных бизнес-структурах, процессах и методологиях управления. Этот динамичный ландшафт требует более продвинутых инструментов прогнозирования, чем могут предложить классические функциональные возможности OLTP и OLAP-систем. В результате многие предприятия переходят к предиктивной аналитике, которая позволяет осуществлять более гибкое и вероятностное прогнозирование [7].
Современные коммерческие предприятия, находящиеся в этом водовороте перемен, предъявляют настоятельный спрос на интегрированную аналитическую экосистему. Такая экосистема не только усваивает потоки данных в режиме реального времени, но и развивает когнитивные способности, чтобы предвосхитить непосредственное временное пространство. В то время как человеческий фактор продолжает оказывать преобладающее влияние в аналитической области, распространение автоматизации и машинного обучения набрало существенный импульс, предлагая оперативную и оптимизированную для эффективности информацию.
Бизнес-аналитику можно разделить на три основных типа: описательную, которая интерпретирует исторические данные; предиктивную, которая предсказывает будущие тенденции на основе прошлых данных; и предписывающую, которая предоставляет рекомендации по действиям для достижения бизнес-целей. На современном конкурентном рынке способность быстро анализировать и интерпретировать огромные объемы данных имеет важное значение, что делает незаменимым специализированное программное обеспечение и передовые аналитические методы, такие как предиктивная аналитика [4].
1.2. Понятие и преимущества предиктивной аналитики
Предиктивная аналитика – это комплексный метод анализа данных, который использует исторические данные для прогнозирования будущих тенденций, видов деятельности, поведения и событий. Позволяя понять потенциальные сценарии будущего, этот подход помогает оптимизировать текущие стратегии. В условиях неопределенности, которая охватывает процесс принятия решений, связанных с инвестиционными проектами, особенно в секторах, где исторических данных недостаточно для надежных прогнозов (рис. 1), таких как оценка потенциала стартапа или оценка других активов, предиктивная аналитика оказывается бесценной [3].
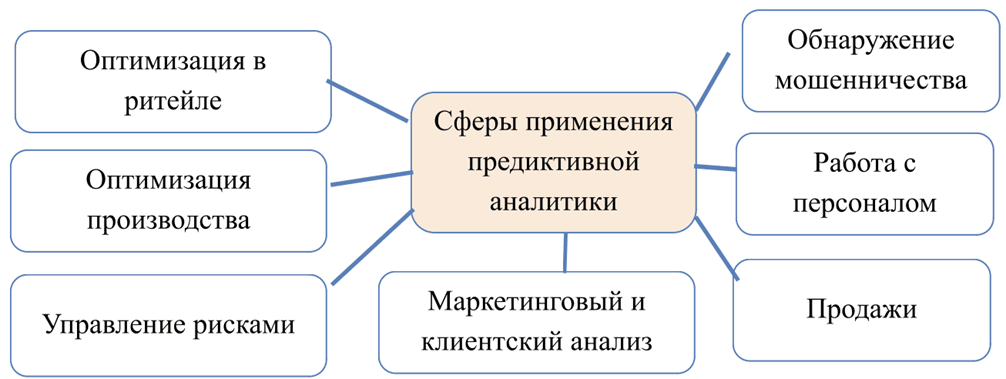
Рис. 1. Основные сферы применения предиктивной аналитики
Процесс предиктивной аналитики включает в себя ряд этапов (рис. 2): сбор исходных данных, очистка данных, идентификация кластеров и прогнозирование. Первичный этап включает в себя сбор и уточнение данных, на котором выявляются и устраняются выбросы. Эффективные прогнозы зависят от качества данных, что подчеркивает необходимость тщательной предварительной очистки данных. После уточнения эти данные группируются для выявления закономерностей и прогнозирования будущих явлений, тем самым уменьшая неопределенность при принятии решений [5].
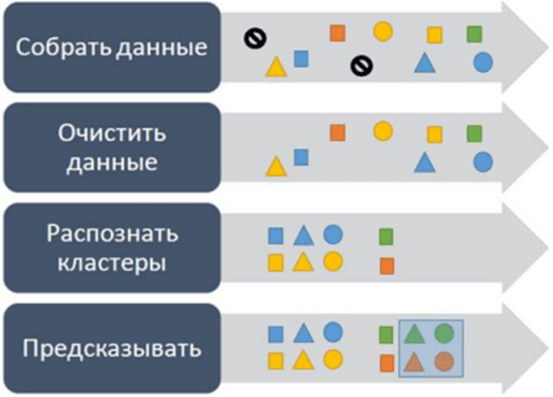
Рис. 2. Этапы процесса создания предиктивной аналитики
Эффективность предиктивной аналитики заключается в ее способности обрабатывать большие наборы данных. Чем обширнее данные, тем точнее результаты. Он особенно эффективен в сочетании с большими данными, хотя его эффективность может быть снижена, если он перегружен нерелевантными данными или выбросами, что приводит к неточностям прогнозирования. Ключевые этапы предиктивной аналитики включают сбор и очистку данных, исследовательский анализ данных и прогностическое моделирование. Каждый бизнес-сектор предъявляет уникальные требования к данным, и хотя большее количество данных, как правило, обещает лучшие результаты, существуют неотъемлемые ограничения. Например, количественные показатели, такие как количество обслуженных клиентов, или экономические показатели, такие как маржа прибылей и убытков, внешние факторы, такие как уровень конкуренции или политический климат, внутренние факторы, такие как компетентность персонала, и показатели поведения клиентов, имеют решающее значение на этапе сбора данных [10].
Второй этап включает в себя анализ данных, направленный на выявление ранее неизвестной информации и получение практических выводов. Используя целый ряд методологий, от классификации и регрессии до кластеризации и анализа отклонений, он направлен на классификацию элементов, понимание зависимостей, группировку объектов на основе параметров и выявление закономерностей и аномалий.
Заключительный этап использует предиктивную аналитику для глубокого изучения множества данных, гарантируя принятие решений в условиях, когда логические закономерности объекта остаются неуловимыми. Предлагая предвидение продаж, нормы прибыли или жизнеспособности нового продукта, лица, принимающие решения, могут повысить эффективность своего выбора. Упрощенно говоря, модель предиктивной аналитики предсказывает будущие события с определенной вероятностью. Более сложная модель обещает более высокую точность при условии, что она работает в благоприятных внутренних условиях.
Однако предиктивная аналитика не лишена своих проблем. Недостаточность данных или некачественные источники могут поставить под угрозу результаты. Кроме того, изменчивый характер данных, особенно во время кризисов или внешних потрясений, может привести к искаженным прогнозам. Даже обладая самыми современными инструментами прогнозирования, люди-аналитики остаются незаменимыми. Они могут различать случаи, когда корреляции данных могут не обязательно подразумевать причинно-следственную связь. Кроме того, проблемы с измерением качественных данных, непредсказуемое влияние внешних переменных и неотъемлемый риск, связанный с принятием решений исключительно на основе прогнозов, создают проблемы.
Теория "черного лебедя", которая указывает на непредсказуемость редких, но имеющих последствия событий, подчеркивает еще одну проблему. Такие труднопрогнозируемые события были признаны в таких секторах, как прогнозирование погоды, демонстрируя необходимость в больших объемах данных, непрерывном обновлении и итеративном прогнозировании [3].
Резкий рост доступности Интернета привел к резкому увеличению объема генерируемых данных, подчеркивая необходимость более глубокого понимания потребителями и частого анализа. Поскольку предприятия сталкиваются с экспоненциальным ростом объема данных, как внутренних, так и внешних, специализированные отделы становятся незаменимыми для получения точных прогнозов, постоянно совершенствуя и диверсифицируя модели для повышения точности.
Таким образом, предиктивная аналитика, обещающая дальновидность, также требует тщательного баланса, постоянного совершенствования и бдительного понимания ее ограничений и возможностей.
1.3. Обзор алгоритмов машинного обучения для предиктивного моделирования
Машинное обучение эволюционировало, предлагая различные алгоритмы, адаптированные для прогностического моделирования. Эти алгоритмы используют различные стратегии и методы для анализа структуры данных и составления прогнозов на будущее [11].
Машинное обучение – это метод, в котором программисты используют наборы данных для обучения алгоритмов. Алгоритмы обучаются на данных, но в них нет заранее запрограммированных инструкций. Машине дается большой набор данных и правильные ответы. Затем машина создает свои собственные алгоритмы на основе этих ответов (рис. 3). С каждой новой порцией данных машина учится все большему. Точность прогнозов при этом еще более повышается.
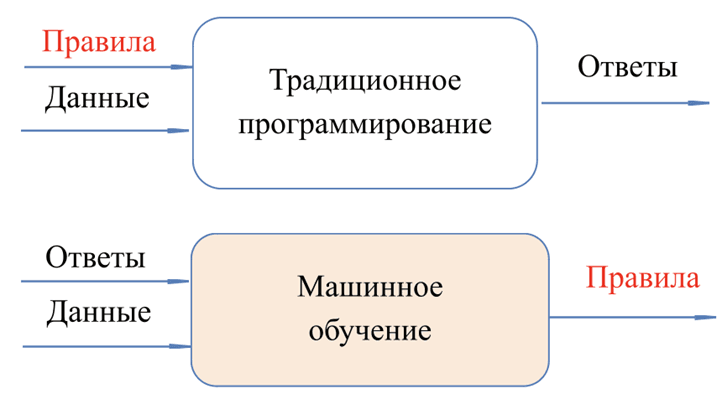
Рис. 3. Различия в подходах традиционного программирования и машинного обучения
Выбор конкретного алгоритма часто зависит от типа данных, поставленной задачи и желаемого результата. Ниже приводится краткое описание некоторых известных алгоритмов машинного обучения, их характеристик и их применения в прогностическом моделировании.
Метод опорных векторов (англ. SVM, support vector machine), представленный на рисунке 4, превосходно работает как в задачах классификации, так и в задачах регрессии. Он работает путем нахождения гиперплоскости, которая четко классифицирует данные по классам, гарантируя, что разница между точками данных различных классов максимальна. Благодаря своей надежности и универсальности SVM нашел применение в различных областях, включая категоризацию текста и изображений [2].
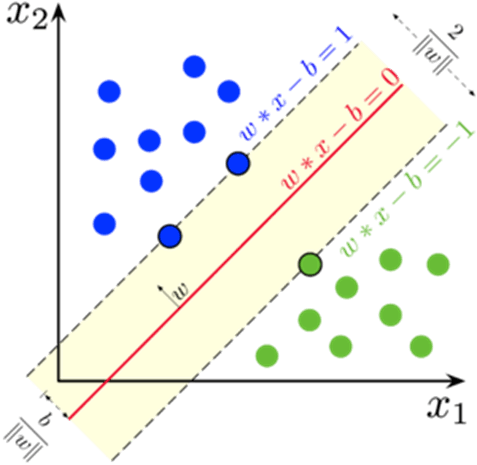
Рис. 4. Метод опорных векторов
Деревья решений (рис. 5) – это интуитивно понятные алгоритмы, которые рекурсивно разделяют данные, принимая решения на основе определенных условий или пороговых значений. В то время как их визуальное представление помогает понять процесс принятия решений, их подверженность переобучению требует осторожности при применении. Такие методы, как случайные леса, которые объединяют несколько деревьев принятия решений, часто смягчают эту проблему [9].
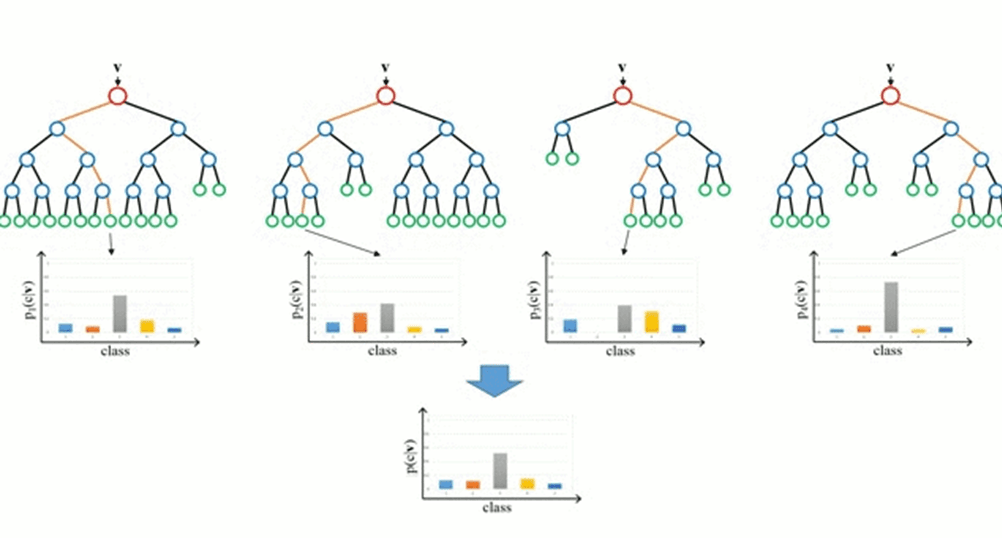
Рис. 5. Деревья принятия решений
Наивный байесовский классификатор (рис. 6) основан на теореме Байеса и предполагает независимость признаков. Несмотря на свой "наивный" подход, он доказывает свою эффективность в решении нескольких сложных задач, в частности, в классификации спама и распознавании рукописных цифр. Его мастерство заключается в вычислении условных вероятностей наступления событий [1].
Рис. 6. Иллюстрация к алгоритму «наивный байесовский классификатор» (примечание – источник: [12])
Условные случайные поля (CRF) предоставляют статистический метод классификации, который учитывает "контекст" классифицируемого объекта. Это делает CRFs особенно подходящей для задач моделирования последовательностей, таких как обработка естественного языка и распознавание речи [3, 6].
В области неконтролируемого обучения особое место занимает анализ основных компонентов (PCA) (рис. 7). Он направлен на уменьшение размерности данных, сохраняя большую часть дисперсии исходных данных. PCA определяет направления с наибольшими отклонениями в данных, обеспечивая снижение уровня шума и предотвращая переобучение.
Рис. 7. Метод главных компонент
Независимый компонентный анализ (ICA) позволяет выявить скрытые факторы, влияющие на случайные величины или сигналы. В отличие от PCA, который стремится к максимальной дисперсии, ICA ищет компоненты, которые являются статистически независимыми, что делает его эффективным в сценариях, где традиционные подходы дают сбои.
Среди алгоритмов, основанных на близости, алгоритм k-ближайших соседей (KNN) (рис. 8) является простым, но мощным. Он классифицирует объект на основе класса большинства его "k" ближайших соседей в пространстве объектов. Несмотря на свою простоту, вычислительные требования KNN могут возрасти при работе с данными большой размерности [3].
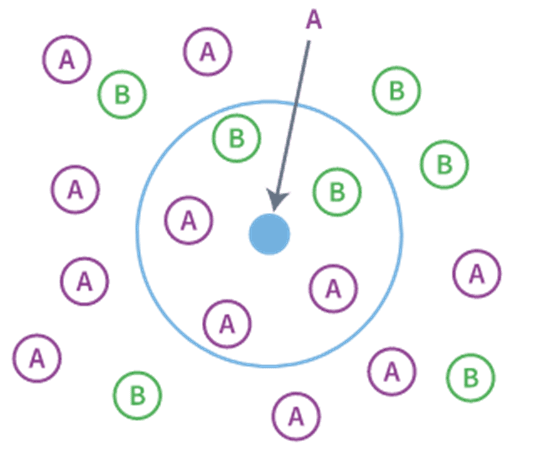
Рис. 8. Метод k-ближайших соседей
Рекуррентные нейронные сети (RNNS) превосходно подходят для последовательного моделирования данных, особенно при обработке естественного языка. Они фиксируют зависимости в последовательностях, что делает их подходящими для таких задач, как генерация предложений и перевод. В то время как традиционные RNN имеют ограничения в захвате долгосрочных зависимостей, усовершенствованные версии, такие как сети с длительной кратковременной памятью (LSTM), устраняют эти недостатки.
Что касается языков программирования, то Python доминирует в области машинного обучения, чему способствуют такие библиотеки, как Scikit-Learn, в которой реализовано множество алгоритмов машинного обучения. Шесть других языков программирования, наиболее часто используемых в машинном обучении (по данным использования на платформе GitHub), включают C++, JavaScript, Java, C#, Julia и R [13].
В заключение отметим, что область прогностического моделирования предлагает множество алгоритмов, каждый из которых имеет свои сильные стороны и ограничения. На специалистах по обработке данных лежит ответственность за определение наиболее подходящего алгоритма для их конкретной задачи, принимая во внимание такие факторы, как размер данных, качество и тонкости предметной области. Для осознанного выбора часто требуется сочетание знаний в предметной области, экспериментов и четкого понимания потребностей бизнеса.
II. Методический анализ системы: Регрессионная модель обучаемая с помощью машинного обучения для прогнозирования продаж
Модель ARIMA (авторегрессионная интегрированная скользящая средняя) становится преобладающей регрессионной моделью в рамках предиктивной аналитики. ARIMA, основанная преимущественно на техническом анализе, а не на фундаментальном, оценивает инерционность исследуемого процесса. В нем также исследуется влияние текущих и запаздывающих значений стандартной ошибки на зависимую переменную. В этом контексте "стандартная ошибка" охватывает потенциальные предикторы, влияющие на зависимую переменную, даже если они остаются неопознанными. В то время как ARIMA оценивает величину влияния этих предикторов, она не ставит своей целью выделить их конкретно. Такие задачи углубленной идентификации лучше подходят для эконометрических моделей, присущих фундаментальному анализу, которые используют конкретные переменные помимо "стандартной ошибки".
В BI-платформах с большим объемом данных, таких как Qlik Sense, Power BI и Tableau, всегда можно подготовить образцы для конкретных продуктов в течение определенного периода времени. На таких платформах, как Qlik Sense, можно упростить аналитические подключения к таким языкам, как Python или R. Эти языки обладают библиотеками, которые включают алгоритм модели ARIMA. Прогнозы, сгенерированные с помощью ARIMA, впоследствии могут быть интегрированы в Qlik Sense для визуализации.
Демонстрация реализации модели ARIMA на Python (рис. 9), особенно в среде Jupyter Notebook, дает бесценную информацию. В этом анализе используются данные из открытых источников: ежемесячные розничные продажи строительных материалов, садового инвентаря и аксессуаров в США за период с января 1992 по декабрь 2020 года, на которые приходится 347 наблюдений, полученных из Федеральной резервной системы США [14].


Рис. 9. Скрипт алгоритма машинного обучения регрессионной модели (примечание – источник: собственная разработка)
Начиная с самого необходимого, потребуются конкретные библиотеки, модули и их составляющие. К ним относятся matplotlib.pylab, requests, numpy, pandas, io, time, json и statsmodels. Набор данных, представляющий ежемесячные показатели продаж строительных материалов и садового инвентаря в США в миллионах долларов, представлен на рисунке 10. Согласно графику, в апреле 2020 года наблюдался всплеск, что свидетельствует о росте продаж.
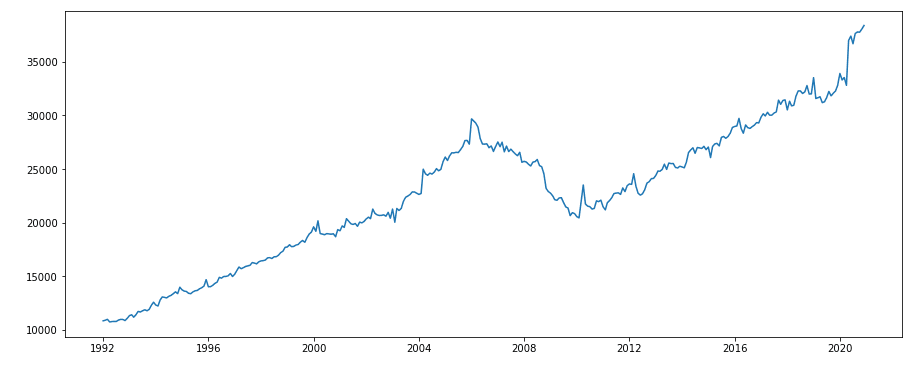
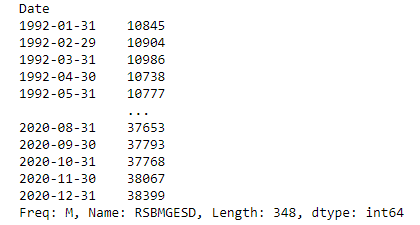
Рис. 10. Динамика продажи стройматериалов в США, млн. USD в месяц (примечание – источник: собственная разработка в среде Jupyter Notebook)
Результаты теста Дикки-Фуллера показывают, что исходные данные имеют единичный корень с вероятностью 98% и, следовательно, являются нестационарными. Декомпозиция данных подтвердила, что исходные данные имеют сезонную составляющую и трендовую составляющую (рис. 11).
Рис. 11. Декомпозиция прологарифмированного ряда (примечание – источник: собственная разработка в среде Jupyter Notebook)
Для достижения условной стационарности данные представлены в первых разностях. На этот раз результаты теста Дики-Фуллера показывают, что данные являются стационарными на уровне значимости 1% (p-value = 0,00) - рис. 12.
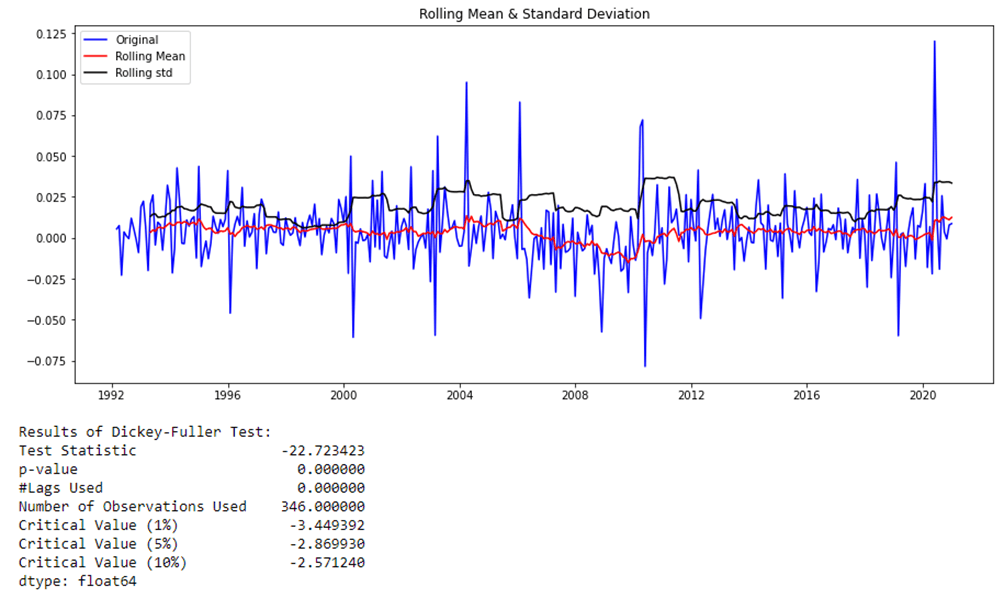
Рис. 12. Результат теста Дики-Фуллера для исходного ряда (примечание – источник: собственная разработка в среде Jupyter Notebook)
Наиболее оптимальной представилась модель ARIMA со спецификацией (1,1,1). Все коэффициенты регрессии и константа значимы.
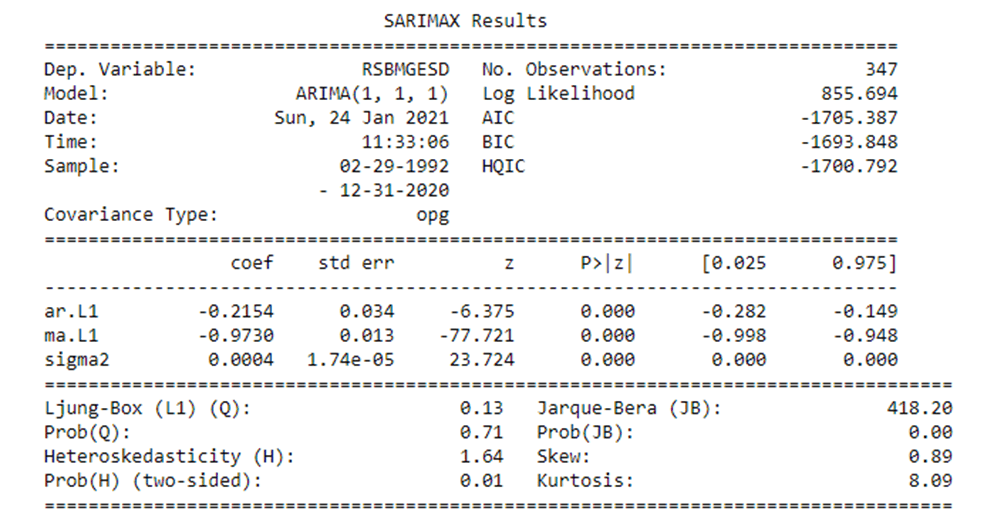
Рис. 13. Результат построения модели ARIMA (1, 1, 1) (примечание – источник: собственная разработка в среде Jupyter Notebook)
Согласно результатам теста Luyng-Box, автокорреляция в остатках модели отсутствует. В остатках присутствует гетероскедастичность и отсутствует нормальное распределение (рис. 13).
Малое значение RSS указывает на то, что модель хорошо подходит к данным. Значение коэффициента суммы квадратов равно 0,1433, что говорит о том, что модель работает хорошо. Визуально остатки модели имеют нормальное распределение (рис. 14). Однако на практике, судя по результатам теста Жарка-Бера, они вряд ли нормально распределены. Очевидно, что нормальное распределение портится небольшим количеством пиков. Другими словами, модель приемлема.
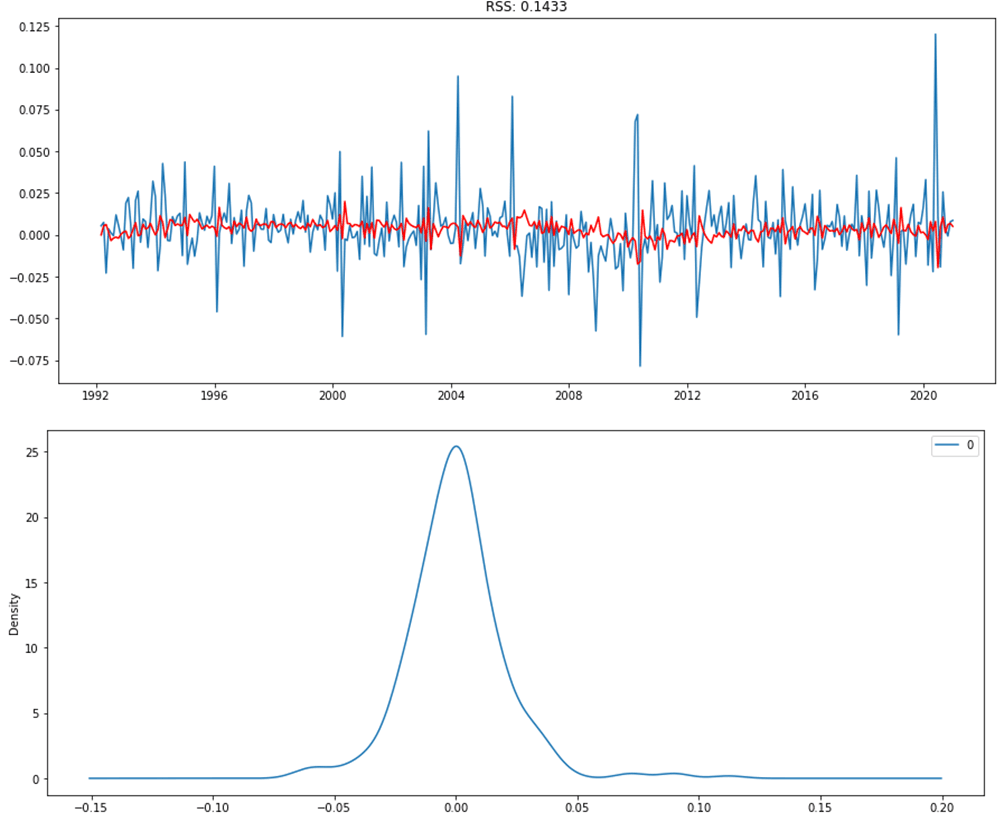
Рис. 14. График распределения остатков модели ARIMA (1,1,1) (примечание – источник: собственная разработка в среде Jupyter Notebook)
Теперь снова разделим весь набор данных на отдельные наборы данных для обучения и тестирования. Далее снова применим машинное обучение с целью улучшить точность прогноза модели (рис. 15).
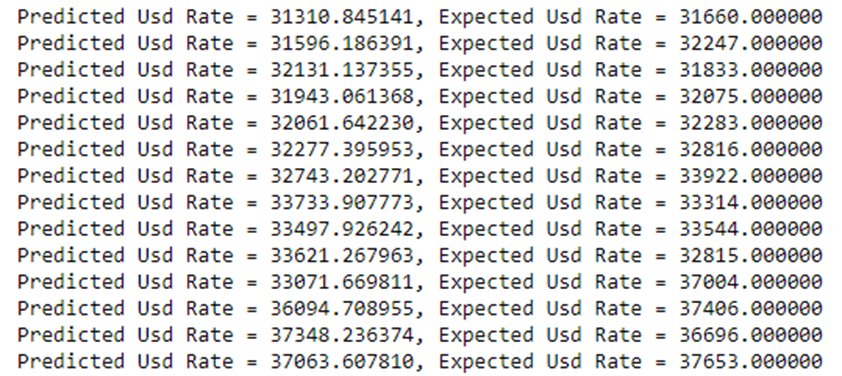

Рис. 15. Проверка соответствия прогнозных значений ожидаемым (примечание – источник: собственная разработка в среде Jupyter Notebook)
В результате обученная модель выдает ошибку прогноза (по показателю MSE) 0.08% или на 0.1%-м уровне значимости. Для экономических моделей прогнозирования это сравнительно высокая точность прогноза (рис. 16).
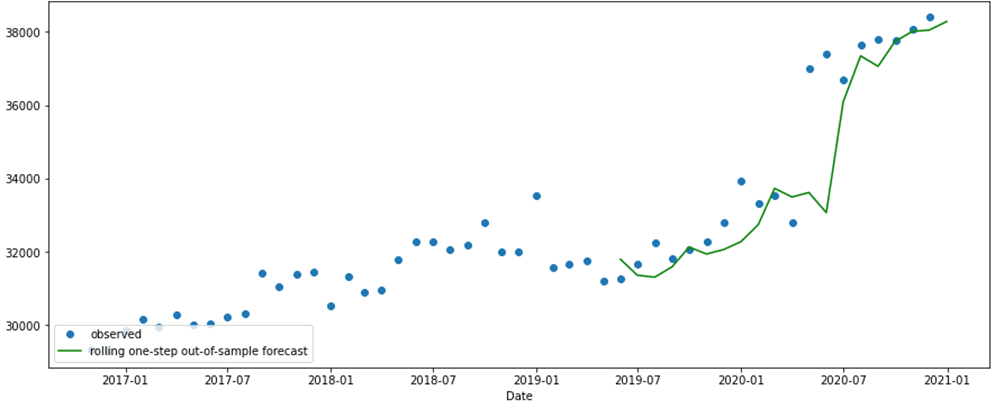
Рис. 16. График прогнозных значений (примечание – источник: собственная разработка в среде Jupyter Notebook)
Таким образом в данном разделе был представлен методический анализ системы построения ARIMA-модели (модели авторегрессионного интегрального скользящего среднего) с использованием машинного обучения. Модель была реализована на языке программирования Python в интегрированной среде разработки Jupiter Notebook. Алгоритм машинного обучения, используемый в модели, был протестирован на наборе данных; ошибка прогнозирования после применения машинного обучения составила 0.08% или на 0.1%-м уровне значимости. Прежде чем использовать машинное обучение, необходимо пройти итерационный процесс: импортировать необходимые библиотеки и наборы данных, подготовить временные ряды путем повторной выборки и приведения их к статическому виду, подобрать параметры и построить модель, доказать ее валидность и построить прогноз. Кроме того, полученные прогнозные данные могут быть интегрированы в платформы бизнес-аналитики, такие как Quick Sense, и включены в состав визуализационных конструкций в виде Dashboads.
III. Этапы внедрения предиктивной аналитики в компании
2.1. Анализ текущего состояния бизнес-процессов и определение потребностей в предиктивной аналитике
В современной динамичной бизнес-среде внедрение предиктивной аналитики в систему принятия корпоративных решений больше не дополнение, а необходимость. По мере роста бизнеса сложность и объем обрабатываемых ими данных соразмерно возрастают, что делает традиционные методы обработки и интерпретации данных неоптимальными. Продукты предиктивной аналитики, обычно включающие в себя прогностические модели, редко являются самостоятельными предложениями. Вместо этого они интегрированы в целостные бизнес-приложения, известные как информационные панели.
Панель мониторинга предлагает визуальное представление основных данных, синтезированных и упорядоченных в едином интерфейсе для удобства понимания. Давайте разберем это определение подробнее:
- Визуальное представление: Информация представлена графически, что оптимизирует когнитивные способности.
- Информация: В основном количественные, эти данные представлены в виде диаграмм и таблиц.
- Самое важное: Акцент делается на ключевых показателях, необходимых для принятия обоснованных решений.
- Сгруппированные по значению: точки данных взаимосвязаны, вращаясь вокруг тематической оси, будь то отдел, продукт или процесс, чтобы предоставить пользователю целостное представление.
Логическое обоснование внедрения бизнес-аналитики (BI) на средних и крупных предприятиях, как правило, непротиворечиво по всем направлениям. По мере расширения компании увеличивается количество контрольных точек, объемы данных и численность персонала, включая удаленных сотрудников, – все это требует точных и своевременных данных. Такой рост усложняет надзор за процессами и снижает прозрачность бизнес-процессов. Растущее число транзакций усугубляет ошибки при принятии решений, что приводит к росту требований к разработке отчетов и их усовершенствованиям, увеличению ресурсов для обработки данных, аналитики и растущей команде аналитиков.
Этот всплеск часто приводит к тому, что бизнес-пользователи теряют автономию в доступе к интуитивно понятным данным. Руководству приходится сталкиваться с большими объемами данных, что затрудняет их способность оценивать магазины, продукты или персонал с многогранных точек зрения. Часто наблюдается заметное отставание между запросами на анализ данных и выдачей результатов. Последующая задержка в принятии управленческих решений может иметь пагубные последствия.
Следовательно, средние и крупные предприятия сталкиваются с рядом проблем:
- Вместо централизованной системы анализа данных или хранилища данных появляется множество источников данных (базы данных, такие как 1С, в сочетании с OLAP и EXCEL).
- Ограничения производительности таких платформ, как 1С, становятся очевидными.
- На разработку и усовершенствование отчетов расходуются непомерные ресурсы.
- При определении показателей производительности и измерений возникают двусмысленности.
По сути, несмотря на то, что потенциальные преимущества предиктивной аналитики огромны, ее фактическая интеграция должна основываться на всестороннем понимании текущего состояния бизнес-процессов и четком осознании возникающих аналитических потребностей.
2.2. Выбор подходящего алгоритма машинного обучения
В современном мире бизнес-аналитики программные платформы играют ключевую роль как в агрегировании, так и в интерпретации данных. Ярким примером этого является пакет, принятый компанией "A2 Консалтинг", который в основном основан на Qlik Sense, Power BI и Exasol.
Qlik Sense, ведущая система бизнес-аналитики, легко интегрирует возможности предиктивной аналитики и машинного обучения. Что делает его достойным внимания выбором, так это его совместимость с широко используемыми языками программирования Python и R. Qlik Sense обеспечивает прямую интеграцию с внешними решениями для прогнозной аналитики через свой продвинутый интерфейс прикладного программирования (API). Эта платформа облегчает прямой обмен данными между движком QIX и внешними математическими инструментами во время сеансов анализа данных. Преимуществом Qlik Sense является использование ассоциативной модели Qlik для передачи релевантных данных на основе пользовательского выбора в сочетании с полной интеграцией с собственными выражениями и библиотеками. Кроме того, это обеспечивает гибкость при создании соединителей для любых внешних механизмов, причем соединители с открытым исходным кодом легко доступны как для Python, так и для R.
С 2017 года платформа Qlik Sense обладает возможностями предиктивной аналитики, уделяя особое внимание интеграции с Python и R. Как правило, схема взаимодействия проста: приложение в Qlik Sense хранит данные, для которых создаются модели или алгоритмы с использованием сценариев Python или R. После их создания эти алгоритмы или скрипты вызываются во время сеансов загрузки данных. Python использует команду EXECUTE, в то время как R использует обработчик statconnDCOM, инициируемый в фоновом режиме макросом. Этот процесс приводит к результатам прогностического моделирования, которые затем интерпретируются и подвергаются дальнейшему изучению.
Дизайн платформы также подчеркивает полезность аналитических подключений, позволяя использовать внешние аналитические инструменты. Аналитическое подключение расширяет диапазон выражений, доступных для развертывания в сценариях загрузки данных Qlik Sense и системных диаграммах, запуская внешний вычислительный модуль. В этой архитектуре вычислительный модуль функционирует как серверное расширение (SSE). Например, в Qlik Sense Desktop настройки выполняются с помощью файла Settings.ini. Эта функция позволяет пользователям устанавливать аналитическое подключение к Python или R, используя статистические выражения во время загрузки данных, тем самым подчеркивая адаптивность платформы и мастерство в выполнении сложных аналитических задач.
2.3 Процесс предиктивной аналитики и машинного обучения на основе интеграции Qlik Sense и Python
На примере разберем конкретный сценарий работы. Набор данных, находящийся в фокусе, включает 2800 клиентов с примерно 500 функциями. Эти функции включают такие параметры, как средняя стоимость чека, способ оплаты, приобретенные продукты, пол, возраст, демографические данные и даже социальные показатели, такие как владение транспортными средствами или наличие детей и домашних животных.
Первоначальная обработка данных включала очистку и заполнение недостающих значений. В частности, пустые ячейки в числовых столбцах были заменены средним значением соответствующих столбцов. Впоследствии, используя библиотеки Python, был выполнен кластерный анализ (рис. 17).
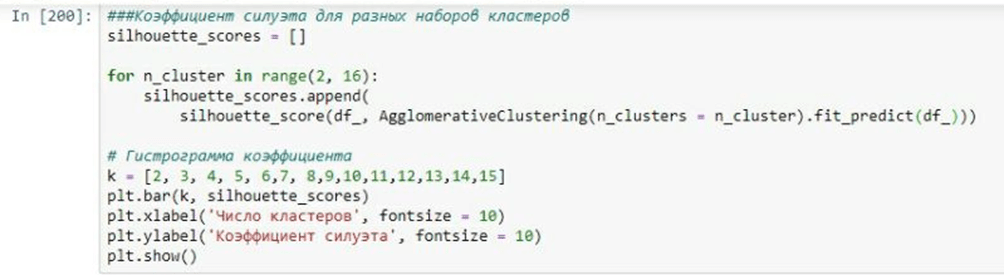
Рис. 17. Фрагмент скрипта на языке Python
Предварительный анализ выявил шесть различных кластеров, каждый из которых обладает своим уникальным набором характеристик (рис. 18).
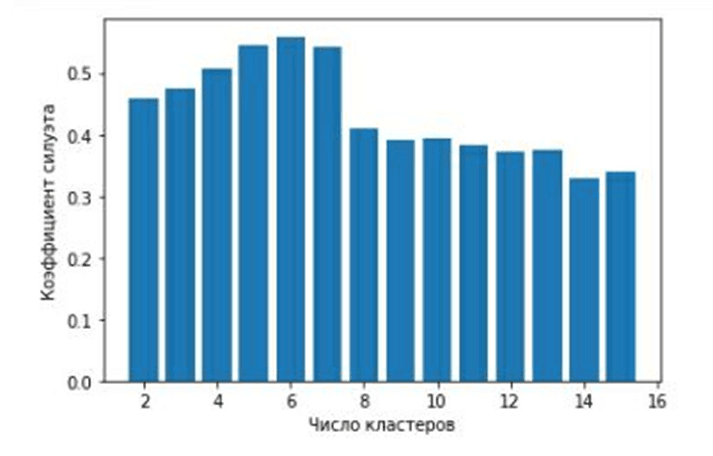
Рис. 18. Гистограмма значений коэффициента силуэта для разных наборов кластеров
При уточнении данных была обучена модель, использующая иерархическую кластеризацию, что привело к разделению этих кластеров.
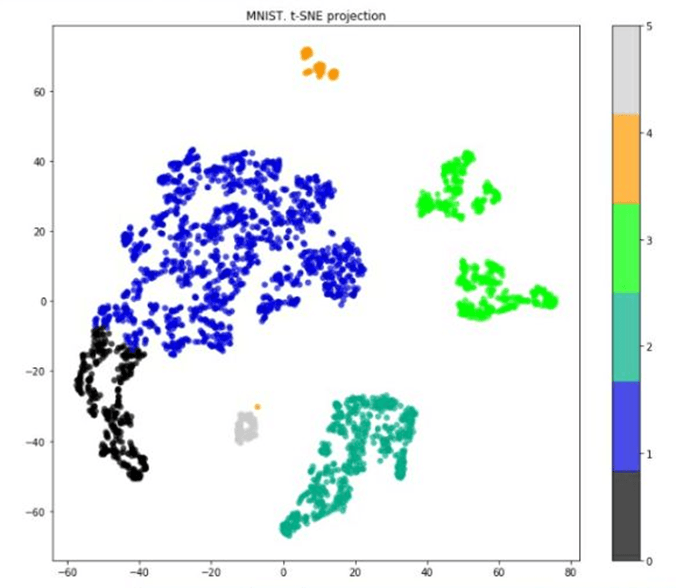
Рис. 19. Кластеры, выделенные с помощью алгоритма иерархической кластеризации (реализация на Python)
После стандартизации и масштабирования (то есть дисперсия для каждого признака будет равна 1) был рекомендован диапазон из 2-3 кластеров. Чтобы придать смысл каждому кластеру, был проведен углубленный анализ. Например, первая группа, получившая название "пенсионеры", состояла в основном из пожилых покупателей, часто покупающих товары первой необходимости, но со скромным средним чеком. "Семейный" кластер определялся более высоким средним чеком, и клиенты покупали более разнообразные товары. Другая группа, получившая название "одиночки", показала нечастые покупки с более высокими индивидуальными затратами и предпочтение косметики и полуфабрикатов.
После первоначальной кластеризации были применены модели машинного обучения, такие как Random Forest, для классификации каждого нового клиента по этим сегментам. Эта прогностическая модель достигла 98%-ной точности, продемонстрировав возможности использования расширенной аналитики в розничной торговле.
Учитывая успех этого подхода, можно в дальнейшем использовать предиктивную аналитику для прогнозирования продаж, моделирования оттока клиентов или даже персонализации клиентских предложений. Например, используя интеллектуальную аналитику данных, можно обнаружить неочевидные закономерности. Одним из наглядных примеров является связь неожиданного оттока покупателей с кратковременным отсутствием такого основного продукта, как помидоры. В то время как традиционная отчетность может не указывать на эту проблему, машинное обучение может выявлять такие корреляции, подчеркивая его важность в современной розничной аналитике.
Понимание и прогнозирование поведения клиентов имеет решающее значение для современного бизнеса, особенно в секторе розничной торговли. Передовые методы моделирования, основанные на машинном обучении, дают бесценную информацию о различных явлениях, таких как отток клиентов, прогнозирование продаж и персонализированные предложения.
Прогнозирование оттока: Процесс моделирования начинается с формирования набора данных о клиентах, у которых произошел отток. Для секторов с высокой частотой покупок, таких как бакалейные лавки или автозаправочные станции, учитывается период в последние три месяца, в то время как для секторов с низкой частотой покупок, таких как розничная торговля непродовольственными товарами, этот период увеличивается до 1-2 лет. Эти данные подвергаются кластерному анализу для выявления общих атрибутов оттока клиентов. После этого разрабатываются модели для распознавания признаков изменения поведения клиентов, которые совпадают с теми, кто ранее сбивал клиентов. Кроме того, различные факторы, способствующие оттоку, коррелируются и ранжируются по их влиянию.
Прогнозирование продаж по артикулу: Эта задача начинается с категоризации продуктов для определения различных подходов к прогнозированию. Проблемы, связанные с управлением, такие как нехватка товара на складе, возврат товара или рекламные мероприятия, рассматриваются и исправляются. С помощью предиктивной аналитики можно с точностью до 95% предсказать намерения конкретного клиента совершить покупку. Однако неучет таких факторов, как сезонность, праздничные смены или погодные эффекты, может резко снизить точность модели. Выявляя и принимая во внимание эти влиятельные факторы, можно усовершенствовать прогностические модели. Эти модели проходят тщательное тестирование с использованием исторических данных, после чего, в случае успеха, используются для прогнозирования продаж в режиме реального времени.
Моделирование персонализированного предложения: Для создания персонализированного предложения требуется набор данных, охватывающий как минимум год, чтобы охватить весь спектр покупательского поведения клиента. Первоначально определяется подход к сегментации, за которым следует фактическая сегментация клиентов. Затем разрабатываются или внедряются алгоритмы для отслеживания переходов между этими сегментами, сигнализирующие о потенциальных изменениях в структуре покупок, которые могут указывать на намерение клиента перейти в другие магазины. Могут быть использованы алгоритмы, подобные моделям Look-a-like. После этого составляются списки товаров, которые часто покупают постоянные клиенты. Затем системы оповещения предупреждают предприятия, если: а) постоянный клиент перестает покупать эти продукты или б) клиенты из другого сегмента не покупают эти идентифицированные продукты. Опять же, перед окончательным внедрением эти модели проходят тщательное тестирование с использованием исторических данных, а затем данных в режиме реального времени.
Используя алгоритмы машинного обучения, предприятия розничной торговли могут глубоко вникать в основные закономерности поведения своих клиентов, оптимизируя свои операции и маркетинговые стратегии в режиме реального времени. Это свидетельство преобразующей силы принятия решений на основе данных в современном ритейле.
2.4 Использование связки технологий и инструментов
В современной предиктивной аналитике для розничной торговли объединение технологий и инструментов имеет первостепенное значение. Как правило, используются такие языки программирования, как C# и Python, наряду с BI-платформами, такими как Qlik Sense и Azure Machine Learning Studio.
C# служит жизнеспособным языком разработки для базовых моделей. На начальных этапах проектов прогнозной аналитики большинство вычислений выполняются по сценарию, адаптированному для интеграции с такими платформами, как Qlik Sense. Независимо от того, выполняется ли разработка на ресурсах разработчика или на клиентских серверах, конечным продуктом является передаваемый исходный код. Богатые библиотеки Python отлично подходят для кластерного анализа, необходимого для моделирования оттока клиентов и разработки персонализированных предложений.
Для совершенствования устоявшихся моделей выделяется Azure Machine Learning Studio. Несмотря на то, что в нем представлены возможности машинного обучения, важно отметить, что ручное моделирование остается преобладающим, на его долю приходится примерно 90% всего процесса моделирования.
В секторе розничной торговли аналитика "Что, если" имеет большое значение. Изменяя конкретные параметры, можно спрогнозировать такие сценарии, как потенциальный результат продвижения продукта. Например, изменение структуры затрат и конечных цен позволяет получить представление о возможных изменениях объема продаж. В этой области BI-системы, такие как Qlik Sense, предлагают преимущества перед традиционными инструментами, такими как Excel. Они предоставляют динамические фильтры с расширенными метриками и обеспечивают мгновенный пересчет и корректировку визуализации по мере изменения значений.
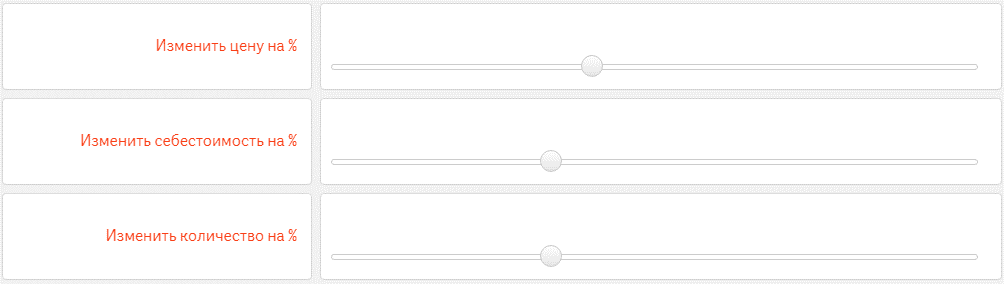
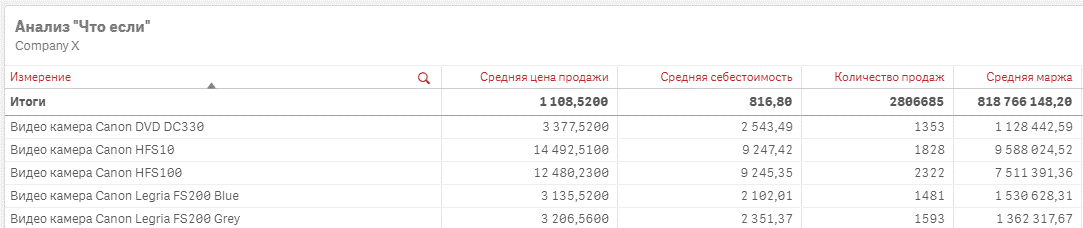
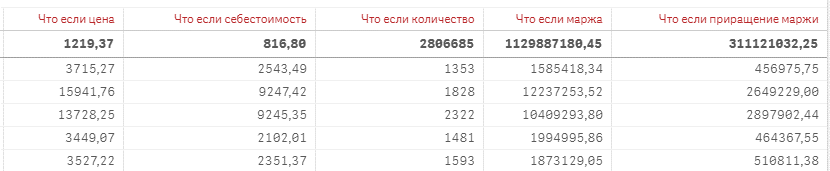
Рис. 20. Пример реализации аналитики «Что-Если» в Qlik Sense
Сегментация в розничной торговле часто основывается на таких методологиях, как ABC и XYZ-анализ, а также на их комбинированной форме - ABC-XYZ-анализе. Анализ ABC сортирует элементы (будь то продукты, клиенты и т.д.) на основе их вклада в общий результат, например, выручку. Типичным проявлением ABC-анализа является правило 80/20, предполагающее, что на 20% продуктов приходится 80% выручки. XYZ-анализ классифицирует товары на основе моделей потребления и точности прогноза за определенный период. Комбинированный анализ ABC-XYZ делит товары на девять отдельных сегментов.
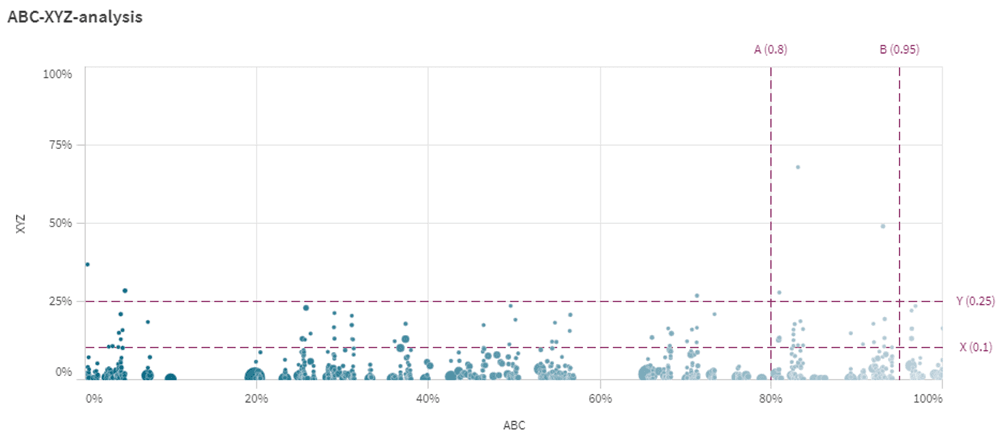
Рис. 21. Результаты совмещенного «ABC-XYZ-анализа» в Qlik Sense
Реализация такого анализа в Qlik Sense одновременно удобна и практична, благодаря таким функциям, как настраиваемые границы для конкретных визуализаций, улучшающим пользовательский опыт и глубину анализа.
IV. Уникальность методологии
Отличительной особенностью методологии является гармоничная интеграция Qlik, передовой системы бизнес-аналитики, с передовыми возможностями прогнозного моделирования платформы Kraken от Big Squid Inc. В отличие от обычных BI-систем, Qlik устраняет необходимость в отдельном хранении данных, выполняя ETL внутри самой BI-системы, тем самым обеспечивая быстрое и эффективное реагирование. Это прямое подключение к источникам данных в сочетании с возможностью хранения данных на сервере Qlik в специализированном формате обеспечивает интуитивно понятный пользовательский интерфейс, отмеченный ассоциативными связями (рис. 22).
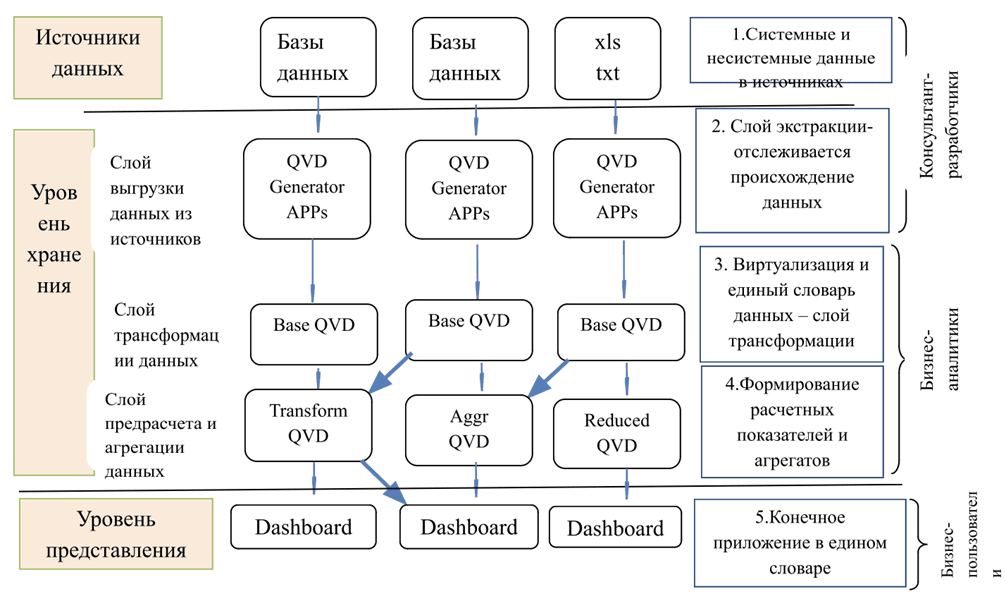
Рис. 22. Архитектура Qlik (без хранилища данных)
Более того, гибкость построения архитектуры хранения данных, которая может либо работать без хранилища данных, либо включать виртуализацию данных, либо поддерживать единый словарь на всех уровнях BI, не имеет аналогов. Эта динамическая архитектура изолирует пользователей и аналитиков от необработанных источников данных, вместо этого представляя собой "хранилище данных", оснащенное сформулированным семантическим слоем, специально разработанным для разработчиков приложений и бизнес-аналитиков.
В стратегическом сотрудничестве с Big Squid Inc. компания Qlik расширила свой портфель, внедрив прогностическое моделирование в свои аналитические процессы. Kraken, эмблема автоматизированного машинного обучения, расширяет возможности пользователей, автоматизируя сложные процессы предварительной обработки данных, построения объектов, извлечения и селекции с последующим выбором алгоритма и оптимизацией гиперпараметров. Эта автоматизация, основанная на искусственном интеллекте, не только упрощает решения, но и ускоряет их создание, часто превосходя модели, созданные вручную.
Кроме того, внедрение Exasol в экосистему аналитики компанией “A2 Консалтинг” добавляет еще одно измерение уникальности. Являясь одной из самых быстрых аналитических баз данных в мире, Exasol превосходит как столбчатые, так и распределенные архитектуры баз данных, гарантируя эффективные OLAP-запросы и объемное хранение данных. Он поддерживает ANSI SQL, тем самым обеспечивая удобство работы с пользователем без сложных этапов обучения, связанных с другими системами. Встроенный драйвер PyExasol, основанный на передовой технологии веб-сокетов, и возможность плавного перехода от бесплатной версии Exasol к платной подчеркивают приверженность методологии адаптивности и масштабируемости.
Таким образом, эта методология представляет собой симбиоз высокоскоростной аналитики, прогностического моделирования и бизнес-аналитики, обещающий непревзойденную производительность, гибкость и ориентированный на пользователя дизайн, что позиционирует ее как значительный вклад в развитие отрасли.
V. Экономический результат
Оценка эффективности внедрения продуктов предиктивной аналитики остается предметом серьезных научных дискуссий. Многие сходятся во мнении, что определить прямую корреляцию между внедрением продуктов предиктивной аналитики и организационными показателями непросто, в первую очередь из-за многогранного влияния на финансовые показатели. Тем не менее, при правильном использовании предиктивная аналитика может улучшить бизнес-операции, повысив инициативу персонала в обслуживании клиентов, привлекая прибыльных клиентов, увеличивая продажи существующей клиентуре, удерживая ценных клиентов и создавая систему упреждающего управления рисками против мошеннических действий.
Внедрение предиктивной аналитики – это инвестиционная инициатива, по своей сути нацеленная на улучшение финансовых показателей организации, включающая снижение затрат, увеличение доходов и рост прибыли. Стандартная процедура определения эффективности таких инвестиций включает сравнение финансовых результатов в ходе реализации проекта с первоначальными капитальными затратами. В то время как компоненты затрат на разработку и внедрение предиктивной аналитики просты, внешние факторы, такие как лицензионные сборы, расходы на оборудование, затраты на адаптацию и накладные расходы на поддержку, увеличивают общую стоимость.
Кроме того, интеграция продуктов предиктивной аналитики часто требует наличия организационной инфраструктуры для обслуживания, как правило, выделенной команды аналитиков данных. Их ежедневная работа обеспечивает обновление моделей и сохранение актуальности прогнозов. Хотя создание минимально функциональной системы предиктивной аналитики может потребовать значительных первоначальных инвестиций, например, примерно 10 000 долларов США (табл. 1), последующие финансовые выгоды могут компенсировать эти затраты. Однако определение точных факторов, влияющих на увеличение доходов, остается сложной задачей.
Таблица 1
Статьи расходов на внедрение приложения Qlik Sense в ритейле
| № | Статьи расходов | Величина расходов (USD) |
|---|---|---|
| 1 | Разработать приложение Qlik Sense | 3011 |
| 2 | Подписка на пакет Qlik Sense Cloud Business | 480 |
| 3 | Расходы на закупку компьютерной техники и оборудования (отдел прогнозирования, 3 компьютера) | 3600 |
| 4 | Расходы на работы по адаптации и интеграции продукта предиктивной аналитики в информационно-аналитическую систему организации | 200 |
| 5 | Расходы на оплату труда сотрудников, задействованных во внедрении | 1000 |
| 6 | Дополнительные расходы на услуги сторонних организаций по внедрению | 1500 |
| Всего | 9791 |
Например, рассмотрим гипотетическую компанию "ООО ОМА". Операционная маржа рассчитывается как отношение операционной прибыли к объему продаж (выручке). Рентабельность продаж является показателем способности компании контролировать затраты. Отношение операционной прибыли к объему продаж сильно варьируется от компании к компании из-за различий в конкурентных стратегиях и продуктовых линейках. Этот показатель часто используется для оценки операционной эффективности компании. Однако следует отметить, что если две разные компании имеют одинаковые объемы продаж, операционные расходы и прибыль до налогообложения, то показатель отношения операционной прибыли к объему продаж может существенно отличаться из-за влияния процентных расходов на чистую прибыль" [46].
Начнем с условных данных по основным показателям хозяйственной деятельности ООО "ОМА" (табл. 2)
Таблица 2
Расчет окупаемости вложенных инвестиций внедрения приложения бизнес-анализа
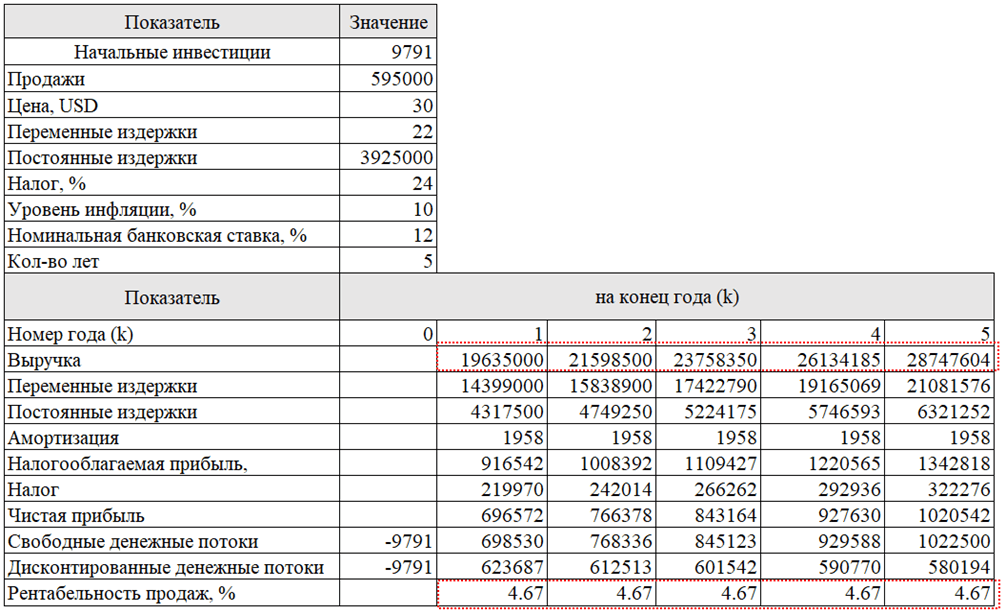 Примечание: везде, где не указано иное, значения приведены в долларовом эквиваленте.
Примечание: везде, где не указано иное, значения приведены в долларовом эквиваленте.
Предположим, что система предиктивной аналитики, которая включена в Dashboard, разработанной на платформе Qlik Sense, полностью окупается в течение первого года. Она увеличивает объем продаж сети ОМА на 10 000 долл. (в долларах США). Это выражается в увеличении рентабельности продаж на 0,05% в первый год в результате установки продукта предиктивной аналитики (табл. 3).
Таблица 3
Расчет окупаемости вложенных инвестиций внедрения приложения бизнес-анализа (на примере за один год)
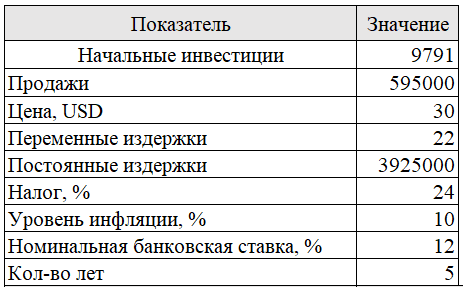
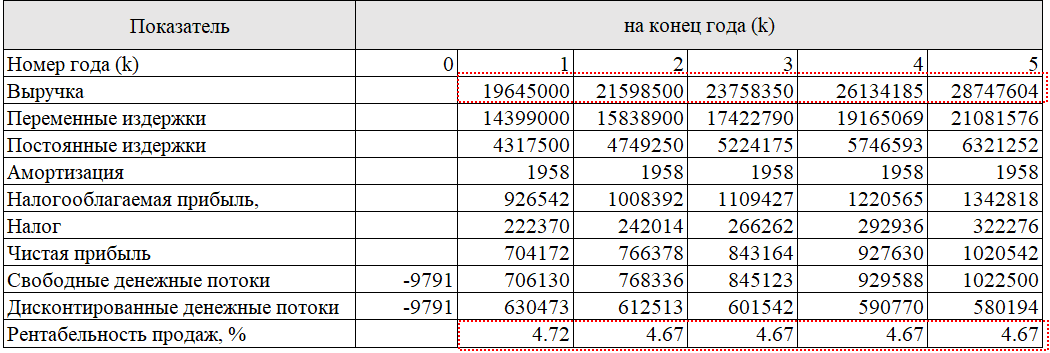
Однако гипотетический корпоративный клиент не настаивает на конкретном краткосрочном периоде окупаемости. Для него главное, чтобы система предиктивной аналитики была прибыльной, но он соглашается на пятилетний срок. Для того чтобы окупить $10 000, вложенные во внедрение продукта предиктивной аналитики, компании необходимо увеличивать выручку на $2 000 в год в течение пяти лет. По расчетам, рентабельность продаж должна увеличиваться на 0,01% в год в течение пяти лет (табл. 4).
Таблица 4
Расчет окупаемости вложенных инвестиций внедрения приложения бизнес-анализа (на примере за один год)
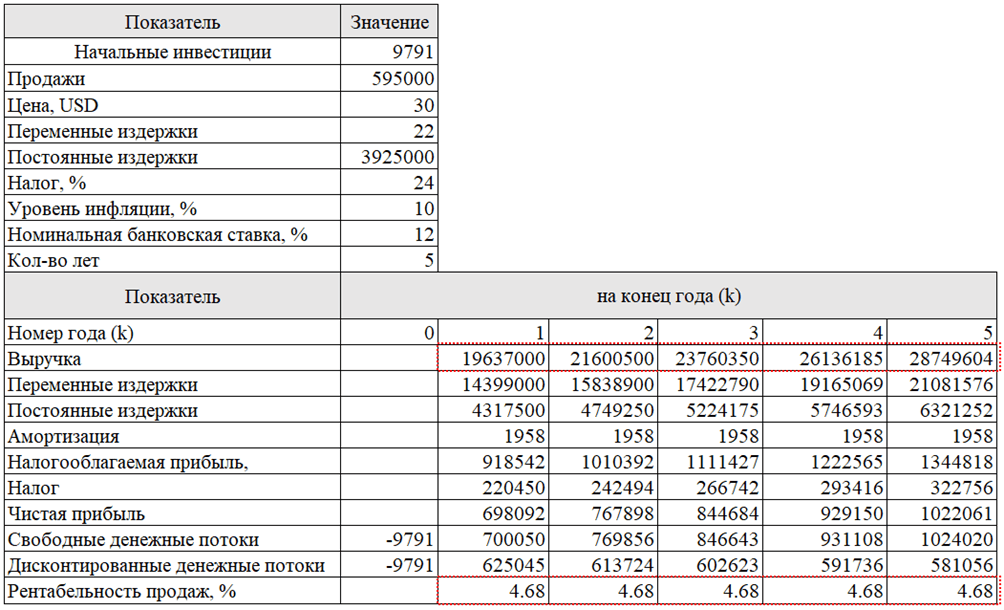
Подводя итог, можно сказать, что успешное внедрение предиктивной аналитики в организации – это не только интеллектуальное упражнение; оно имеет ощутимые финансовые последствия. С течением времени и по мере накопления данных экономические выгоды от такой интеграции становятся все более очевидными, хотя точное определение причин может оставаться труднодостижимым. Методология подчеркивает, что экономическая отдача от предиктивной аналитики, хотя и трудно поддается точной количественной оценке, бесспорно значительна.
Заключение
Представленная методология предлагает всеобъемлющую основу для понимания и внедрения предиктивной аналитики в отрасли. Основные выводы включают в себя:
Сфера применения предиктивной аналитики: Эта методология определяет предиктивную аналитику как синергетическое сочетание методов, от интеллектуального анализа данных до машинного обучения, способных использовать исторические данные для прогнозирования будущих явлений.
Выявление тенденций: Через эту методологическую призму очевиден растущий интерес к предиктивной аналитике, особенно к передовым методам машинного обучения в развитых странах. Это подчеркивает его растущую актуальность и незаменимость в современной корпоративной стратегии.
Региональное применение: Описывая текущее состояние машинного обучения и создания прогностических моделей в Беларуси, методология демонстрирует различия и области роста в различных регионах мира.
Определение приоритетов платформ: Методология подчеркивает стратегическое предпочтение таких платформ, как Qlik Sense, подчеркивая их преимущества, такие как отсутствие необходимости в хранилищах данных и совместимость с современными языками программирования.
Экономические соображения: Подчеркивая меняющуюся динамику затрат на поддержание прогностических моделей, методология подчеркивает перспективность новых технологий, таких как автоматизированное машинное обучение, для повышения эффективности процесса с точки зрения затрат.
Повышенная доступность: Методологический подход признает демократизацию бизнес-аналитики при снижении затрат на разработку и повышении доступности для неспециалистов.
Аналитические задачи: Методология откровенно рассматривает присущие ей сложности в количественной оценке точных преимуществ и рентабельности инвестиций предиктивной аналитики, особенно в сочетании с другими формами аналитики.
Интегративный анализ: Методология выступает за целостный подход, предполагающий объединение результатов предиктивной аналитики с другими аналитическими методами для получения обогащенной, действенной информации.
Подводя итог, можно сказать, что данная методология предлагает надежную основу, которая не только разъясняет нюансы предиктивной аналитики, но и служит значительным вкладом в развитие отрасли, прокладывая путь к обоснованным, ориентированным на будущее бизнес-стратегиям.
