
1. Introduction
Automatic document (text) summarization has been studied since the 1950s of the 20th century. In the view of the researchers of document summarization, summarization is a reduction of one or more original documents by selection and generalization of the most important concepts. According to [1], document summarization is the process of extracting the most important information from the original text to create a simplified version to use for different purposes or tasks. Typically a summarization is no more than half the length of the original text. There are many approaches to document summarization, through which there are also many ways to classify document summarization systems. The most common approach is by results. According to this classification, there are the Extractive, Abstractive and Hybrid method [2]. With Extractive methods, the summarization including the important units such as the sentence, the paragraph is extracted, selected from the original text. While the Abstractive methods, the summarization consisting of concepts, content is summarized from the original text. Combining Extractive and Abstractive methods by strengthening their pros and weakening their cons leads to Hybrid methods.
Currently in the world there are many works on automatic text summary for many different languages, mostly focusing on English, Japanese and Chinese. Regarding the summary method, most still focus on extraction methods with diverse and rich proposed models such as the method of using frequency features from TF × IDF, cluster-based method, Latent Semantic Analysis (LSA), Machine Learning, Neural Networks, Query Based, Computational Regression or graphical Model.
2. Related Work
An extractive summarization method involves selecting important sentences from the source document to form output document (summary document). The selection sentence is based on how much it is important to the summary. In general, an Automatic Text Summarization (Extractive) system is composed of 5 components in series: Preprocessing on documents, Computation of feature’s score, Calculation of sentence’s score, Extraction of important sentences, Formation of summary [3]. There are many types of approaches used in previous research work in extractive summarization such as: Fuzzy logic approach, Latent semantic analysis (LSA) approach, Graphical based approach, Discourse based approaches, Statistical based approaches, Machine learning approach (MLA) [4]. In Graphical based approach, the weight graphs which are generated from the document has connected from the set of vertices and edges. Each vertice is a sentence, the edge is represented the similarity between two sentences. In the graph approach, there are also used LexRank and TextRank, which are both based on fully unsupervised algorithms and depended on entire text-based but not training sets. LexRank was proposed by Erkan and Radev [5], firstly is used inmultiple document text summarization. Recently, LexRank method has been widelyused for text summarization in various languages or domains around the world like Indonesian News Articles in [6], Greek Case Law in [7], Customer Reviews in [8], Privacy Policies in [9], Health Domain in [10] or Restaurant Reviews in [11].
Regarding Vietnamese text summarization, currently studies mainly focus on extraction methods with models using common features of English documents. Some typical works such as Nguyen Le Minh et al [12], Ha Thanh Le et al [13], Le Thanh Huong et al [14], Nguyen Thi Thu Ha [15], Nguyen Nhat An [16]. Nguyen Le Minh et al [12] extracted using SVM method with features including sentence position, sentence length, topic relevance, word frequency, main phrase and word distance. Ha Thanh Le et al [13] combined some features extraction methods in extracting Vietnamese text such as frequency characteristics of TF × IDF words, position, title word, and related word. Features are combined linearly to weight each sentence in the original text. Le Thanh Huong et al [14] used an improved PageRank algorithm with a multiplier for words appearing in the title of the text to extract sentences. Nguyen Thi Thu Ha [17] uses features of word frequency, sentence position and title feature to extract important sentences. Nguyen Nhat An [18] extracts sentences based on the features of sentence position, word frequency, sentence length, word probability, named entities, numerical data, similar to title and center sentence to sentence weight calculation. Recently, In [19], Lam, K.N et al investigates several text summarization models based on neural networks, including extractive summarization, abstractive summarization, and abstractive summarization based on the re-writer approach and bottom-up approach. The above studies are mainly used on data sets from Vietnamese online newspaper documents but have not yet used the specific features of this document as mentioned [20].
3. Proposed System
3.1. Backbone Model
With graph-based approach [21], the documents are represented as a graph where the sentences are the nodes and the edges between them indicate their relationships. The graph is then analyzed using various algorithms to identify the most important sentences or nodes, which are then used to create a summary. One popular algorithm used for this purpose is the PageRank algorithm, which is also used by Google to rank web pages. In this algorithm, each node is assigned a score based on the number and quality of incoming edges. The nodes with the highest scores are considered the most important and are selected for the summary. Another one is LexRank. The main idea of LexRank is that the preprocessed text will be represented as a weighted undirected graph and the importance of sentences on the graph will be estimated [5]. Each graph vertex corresponds to a sentence in the text, each edge connecting two vertices denotes the relationship between the two sentences. The edge weight is the similarity value between two sentences. For the LexRank, the sentence similarity calculation method is the basic factor affecting the output. The most important ones are the ones with the highest similarity to the rest. In this study, we propose an automatic summarization method based on LexRank method in taking into account the characteristics of Vietnamese language and add some specific features of Vietnamese online newspapers.
The Figure illustrates 6 steps of our system. Firstly, the inputs (a single document) are pre-processed and follows feature extraction. The next section follows summarization approaches and methods which based on LexRank algorithm. In this section, instead of using tf-idf-modified cosine similarity between any two sentences in the document, we propose a new model by adding a new similarity matrix with the injection of the knowledge of the article itself. Finally, the sentences are ordered and selected to form a summary of the document.
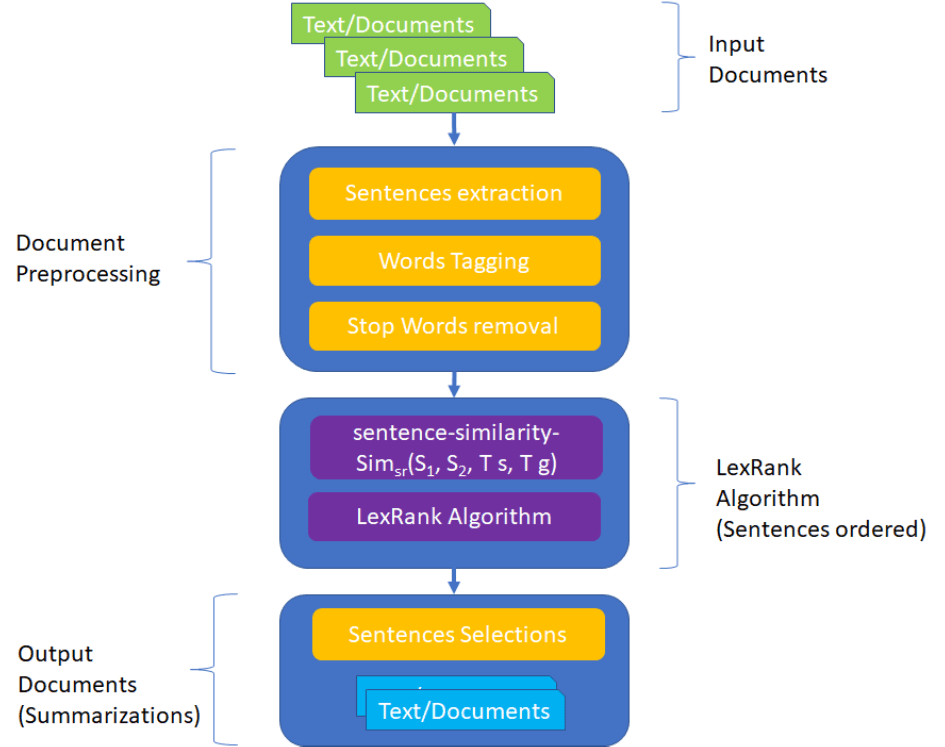
Fig. Proposed model
3.2. Vietnamese Text Tokenization
3.2.1. Phonetic characteristics
In Vietnamese [22], there is a special unit called “tiếng”, each “tiếng” is a syllable. A Vietnamese word is a set of “tiếng” or a single word. For example, the word “teacher” in Vietnamese is “giáo viên”, it contains two syllables (tiếng) or a single word and in written form, these single words are separated by a space. So that, the meaning token is the set of these two single words.
3.2.2. Vocabulary characteristics
The Vietnamese vocabulary is based on the single words (one syllable) and the complex words which are the combination of single words. For example, the complex word “đất nước” is based on two words “đất” (land) an “nước” (water) and the meaning of “đất nước” is “country”. It is flexible so that it is difficult to tokens.
3.2.3. Grammatical characteristic
Vietnamese is not a morphing language, for example, the verb conjugation and case endings don’t exist. The sentence is the combination of words, hence, it is very important to know the word order and keywords to recognize its tenses. The order of words in a sentence shows the syntax relations between them and give the meaning of the sentence. For example, two sentences “Con chó cắn con mèo” and “Con mèo cắn con chó” have the same set of word but the meaning is different (the first mean “the dog beat the cat”, and the second one is “the cat beat the dog”).
3.2.4. Tokenization
In Vietnamese documents, we do not use "space" as a word separator, it only has the meaning of separating syllables from each other. Therefore, to process Vietnamese documents, the process of word tokenization and tagging is one of the most basic and important problems. For example, the word "đất nước" is made up of two syllables "đất" and "nước", both of which are single words with their own meanings when standing alone, but when put together give a word that has a unique meaning. Word Tokenization and Tagging is a prerequisite problem for Vietnamese text processing applications, having a decisive factor in the accuracy of the following problems. Currently, there have been a number of published studies on the problem of word Tokenization and Tagging with high efficiency and widely used, such as Nguyen Cam Tu’s JvnTextPro tool [23] or VnCoreNLP tool developed and built by Thanh Vu et al. [24].
3.2.5. Tags and key words in Vietnamese online newspaper
Vietnamese online newspapers have developed through three phases. Currently, the information structure in an online newspaper usually includes the main title, the sapô, the main text, the subtitle, pictures, graphics, videos and animations, sound, information boxes and texts, Links, Keywords and Tags [25]. Sapô is the prologue of the newspaper, tends to be as concise as possible, the purpose is to make the reader more attractive. Through research on the features of online newspapers, we found that the Keywords, Tag words (Tags) and Named entities, the phrases in the main title, in the Sapô are the components with much information in online newspapers. Therefore, in order to extract the sentence in the text, we find that it is necessary to study and evaluate the semantic role of the above features. Research results in [20] have also indicated this problem. Here, named entities are considered important when appearing 2 or more times in the main text of the document, either the ones named in the main text or in the Sapô. The following when referring to named entities we understand that named entities satisfy one of the above requirements.
3.3. Preprocessing documents
The input text is in a file *.txt. The text will be passed through the word preprocessor to split to sentences, words, and remove stop words. To split sentences and words, we use VnCoreNLP tool developed and built by Thanh Vu, Dat Quoc Nguyen, Dai Quoc Nguyen, Mark Dras and Mark Johnson [24]. We use this tool because in addition to the ability to split sentences and words, it also provides a good method to label single words, compound words, and identify proper nouns (named entities). Stopwords are defined as words that appear commonly in the text but do not have much semantics in linguistic analysis, or appear very little in the corpus, so they do not contribute to the meaning of the text. Therefore, removing the stop word will reduce the semantic noise of these words in the text. To remove stop words, we built a module that compares words in a sentence with the stop word list at https://github.com/stopwords/vietnamesestopwords/blob/master/vietnamese-stopwords.txt. If any word appears in the stop word list, remove it from the sentence in the text. As a result, each article will include 4 *.txt files corresponding to content, abstract, Tags and Named entities.
3.4. Sentence similarity
Similarity is a quantity used to compare two or more objects, reflecting the strength of the relationship between them. The problem of parallelism of two documents is stated as follows: Considering two documents di and dj, finding the similarity between di and dj is the problem of finding a value S(di, dj) ∈ (0,1) such that the higher of the value of S, the more semantic similarity of the two documents.
3.4.1. LexRank IDF modified cosine similarity
To define similarity, LexRank [5] use the bag-of-words model to represent each sentence as an N-dimensional vector, where N is the number of all possible words in the target language. For each word that occurs in a sentence, the value of the corresponding dimension in the vector representation of the sentence is the number of occurrences of the word in the sentence times the idf of the word. The similarity between two sentences is then defined by the cosine between two corresponding vectors:
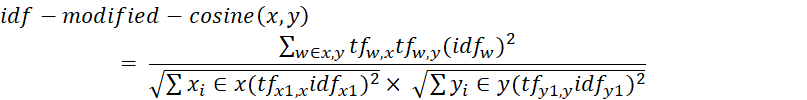
where tfw,s is the number of occurrences of the word w in the sentence s.
3.4.2. Semantic similarity
Because the WordNet for Vietnamese language has not been fully built, it is impossible to apply the algorithms using the WordNet to calculate the sentence similarity. Therefore, we use a proposed solution in [26] to calculate the semantic similarity of sentences in Vietnamese online newspapers based on the weights of tags words and named entities that are important semantic components in the sentence. Let:
- Tg is the set of Tags words of the article: Tg = Tg1, Tg2. . . ., Tgm
- Tt is the set of named entities words of the article: Tt = Tt1, Tt2, . . . , Ttk
We normalize Tg, Tt so that Tg ∩ Tt = ∅, it means that if one word belongs to two sets it will be removed from the other one (in this case it will be removed from named entities). The formulation to calculate the similarity is defined as following:
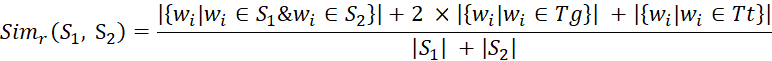
Algorithm 1 Semantic similarity of two sentences
Input: Two sentences S1 and S2, set of Tags Tg, set of NameEntities Tt
Output: Ss the semantic similarity of tow sentences
1: function sentence-similarity-Sims(S1, S2, Tg, Ts)
2: Ss ← 0
3: S1[0...n - 1] be a array of words of sentence S1.
4: S2[0...m - 1] be a array of words of sentence S2.
5: Tg[0...p - 1] be a array of Tags.
6: Tt[0...q - 1] be a array of NameEntities.
7: a ← 0
8: for i=0 don-1
9: ai ← 0
10: wi ← S1[i]
11: if (wi ∈ [S2]) then
12: ai ← a + 1
13: if (wi ∈ [Tg]) then
14: ai ← ai + 2
15: end if
16: if (wi ∈ [Ts]) then
17: ai ← ai + 1
18: end if
19: end if
20: a ← a + ai
21: end for
22: Sims ← a ÷ (n + m)
23: return Sims
24: end function
3.4.3. Word order similarity
If only based on semantic similarity, two sentences containing the same set of words will be exactly the same even if there is a difference in word order in these sentences. Li et al in [27] has proposed a method to calculate the similarity of two sentences based on the order of words. For simplicity, in this study, we omit the step of finding similar words. The algorithm to calculate the similarity is described as follows:
Let:
- T(S1∪S2) = (w1,w2. . . .wm) is a set of distinctive vocabulary of these two sentences.
- R1 = (r11, r12. . . , r1m) is a vector of word order of the sentence S1.
- R2 = (r21, r22. . . , r2m) is a vector of word order of the sentence S2.
With each wi in T if wi in S1 then r1i set to be the order of wi in S1 else r1i = 0.
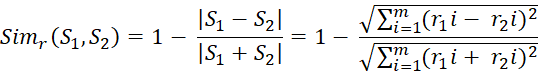
Algorithm 2 Word order similarity of two sentences
Input: Two sentences S1 and S2
Output: Sr the word order similarity of tow sentences
1: function sentence-similarity-Simr(S1, S2)
2: T ← S1 ∪ S2
3: m ← card(T)
4: n ← card(S1)
5: p ← card(S2)
6: R1[0..m - 1] be a new array.
7: R2[0..m - 1] be a new array.
8: for i=0 dom-1
9: R1[i] ← 0
10: R2[i] ← 0
11: for j=0 don-1
12: if (wi ≡ S1[j]) then
13: R1[i] ← j
14: end if
15: end for
16: for j=0 dop-1
17: if (wi ≡ S2[j]) then
18: R2[i] ← j
19: end if
20: end for
21: end for
22: a ← 0
23: b ← 0
24: for i=0 dom-1
25: a ← a + (R1[i] − R2[i])2
26: b ← b + (R1[i] + R2[i])2
27: end for
28: Simr ← 1 − a ÷ b
29: return Simr
30: end function
3.4.4. Calculation of sentence similarity
To calculate the similarity of two sentences, as in [28] we combine the two measures above. The combined expression between two measures is as following:
Simsr(S1, S2) = a ∗ Sims(S1, S2) + b ∗ Simr(S1, S2) with a + b = 1
There is no general formula to determine the weights a, b. It is usually determined through the experimental method or the balance of the criteria. In this case we chose a = 0.5 and b = 0.5.
Algorithm 3 Calculation of sentence similarity
Input: Two sentences S1 and S2, set of Tags Tg, set of NameEntities Tt
Output: Ssr the similarity of tow sentences
1: function sentence-similarity-Simsr(S1, S2, Tg, Ts)
2: Sims ← Sims(S1, S2, Tg, Ts)
3: Simr ← Simr(S1, S2)
4: Simsr ← 0.5 × Sims + 0.5 × Simr
5: return Simsr
6: end function
3.5. Text summarization by LexRank
Algorithm 4 LexRank Algorithm
Input: Array S of n sentences, threshold t
Output: array L of LexRank scores
1: procedure LexRank(S,t, Ts, Tg)
2: SimilaryMatrix [0..n - 1][0..n - 1] be a new Matrix.
3: Degree[0..n - 1] be a new array.
4: L[0..n - 1] be a new array.
5: for i=0 don-1
6: for j=0 don-1
7: SimilarMatrix[i][j] =sentence-similarity-Simsr(S[i], S[j], Ts, Tg)
8: if SimilarMatrix[i][j] ≥ t then
9: SimilarMatrix[i][j] ← 1
10: Degree[i] ← Degree[i] + 1
11: else
12: SimilarMatrix[i][j] ← 0
13: end if
14: end for
15: end for
16: for i=0 don-1
17: for j=0 don-1
18: SimilarMatrix[i][j] ← SimilarMatrix[i][j]/Degree[i]
19: end for
20: end for
21: for i=0 don-1
22: for j=0 don-1
23: SimilarMatrix[i][j] ← (d/n) + (1 − d) ∗ SimilarMatrix[i][j]
24: end for
25: end for
26: L = PowerMethod(SimilarMatrix, n, ɛ)
27: end procedure
In this step, the LexRank algorithm takes the cleaned data as an input and performs the steps mentioned in the pseudocode to obtain the sentence ranking. Firstly, the similarity matrix is generated by the function sentence−similarity−Simsr(S1, S2, Tg, Ts) as mentioned above instead of using the cosine similarity value of base LexRank [5]. If a value is greater than the value of a threshold t, it will be replaced by value 1. If it is lower than the appropriate threshold, the value is replaced by 0. According to Le Thanh Huong [14], for the text summary model, we use the coefficient d (DAMPING-FACTOR) of the PageRank algorithm is 0.85. After all, the Power method is used to measure the value of a matrix ’s largest eigenvector. The convergence condition of the algorithm is determined through the experimental process with ɛ = 0.001.
3.6. Choose sentence, generate summary
The sentences will be sorted by descending importance, then rearrange in text order to generate output text. Here we will take high to low weight sentences in turn, where the number of sentences is determined through the compression ratio of the summary text, by default it is 30%. Sentences that are included in the summary will be rearranged in text order for final results.
4. Experiments
4.1. Building a corpus of linguistics
As mentioned above, for the problem of summarizing Vietnamese text, there are a number of corpuses shared on the Internet like [29], but they do not have the tags words (tags) of the text. So that they cannot be used in this work. Therefore, we use our own documents built in [20]. These experimental documents include 100 documents in the categories of “the world”, “news”, “law”, and “business”, randomly selected from online newspapers in Vietnam from http://dangcongsan.vn, https://znews.vn/, https://vnexpress.net. Each article has about 500 words or more. Each article contains title, chapeau, content and Tags words. Each content is saved to a *.txt file. The summary of each extracted text has 30% of the sentences. We work with an experienced journalist to select the sentence in the summary.
4.2. Experimental Metric
Experimental Metric To evaluate the accuracy of an automated extract, we use the co-selection method [30]. This assessment method is suitable for extract summaries by comparing the system-extracted summary with the human-extracted summary based on three features, the accuracy measure: precision, recall, and f- score. Precision: Calculated based on the ratio of the total number of matches of the manual summary text and the system summary text to the system’s total number of summary sentences. Recall: Calculated based on the ratio of the total number of matches of the manual summary text and the system summary text to the total number of sentences of the manual summary text. The F-score is a measure of precision and recall. F1-score is called a harmonic function of the accuracy and summon measure.
F1-score values accept the value in the segment [0, 1], where the best value is 1.
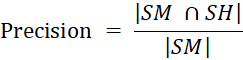
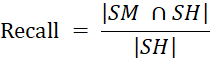
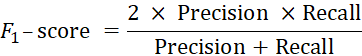
In which: SM is the set of sentences extracted from the system, SH is the manual extract set, |SM| is the number of elements in the set SM.
4.3. Experimental Results
Table
The accuracy of 100 documents
|
|
Precision |
Recall |
F1−score |
|
idf-modified-cosine |
0.650 |
0.610 |
0.315 |
|
sentence-similarity-Simsr |
0.664 |
0.625 |
0.322 |
From Table. 1, we have some of the following remarks regarding the test dataset results:
- The Precision is now 0.664, compared to the baseline (0.650) it has increased by 2.15% higher than the basic. The F1−score value has also reached 0.322, compared to 0.315 of the base algorithm it has increased by 2,22%. So that, with the semantic of the Tags words and the named entities in the similarity formula we have a better result, though not much.
- When reviewing each extract made by experts and by the system, we found that sentences in the LexRank extract summurys are also unevenly distributed in the text.
5. Conclusions and Recommendations
The article has proposed an extracted summary approach to online newspapers based on the LexRank method with the addition of some specific features of online newspapers, which are Tags words and named entities. The results obtained from the experiment show the important semantics of the Tags words and the named entities in the problem of summarizing Vietnamese online newspapers. In the future, we will continue to experiment on different data sets to optimize the method of calculating sentence similarity with Tags words and named entities to improve the efficiency of this method. At the same time, we will also add the solution of eliminating similarity sentences to limit the number of sentences with high similarity but high weight is selected to the summary.
6. Acknowledgments
We would like to express our sincere thanks to journalist Tran Le Thuy, reporter of Vietnamese Women’s newspaper for assisting us in the process of researching and building a corpus of linguistics for this article. I also want to thank the group of authors of the library VnCoreNLP.
