
1. Introduction
Automatic text summarization has extensively employed applications based on information retrieval, information extraction, question answering, text mining, and analytics. Ingeneral, there are two different approaches for automatic text summarization: extraction and abstraction. There have been different algorithms and methods for summarizing text automatically. In extractive text summarization, two approaches of machine learning are applied: supervised and unsupervised machine learning. The abstractive summarization approaches are of two types, one is a structure-based method, and the other one is a semantic-based method.
Besides these popular models, recently, some pre-trained language models such as BERT, BART, GPT-2, TransformerXL, XLnet.... have significantly improved in automatic text summarization. These language models are pre-trained on vast amounts of text data and fine-tuned with various task-specific objectives.
2. Related Work
This section reviews related work of text summarization in two main approaches: unsupervised learning methods and supervised learning methods.
2.1. Unsupervised learning methods
TF-IDF approach
The Term Frequency-Inverse Document Frequency (TF-IDF) is a numerical statistic which reflects how important a word is to a document in the collection or corpus. In this approach, the algorithm calculates the frequency of each word in the document (term frequency) and multiplies it by the inverse document frequency which is the logarithm of the total number of documents over the number of documents that contain the word. The result is a score that indicates how important a word is in a particular document. This score is then used to identify the most important sentences in the document based on the frequency and relevance of the words they contain. The sentences with the highest scores are selected to form the summary [1].
Cluster based approach.
In a clustering method, to ensure good coverage and avoid redundancy, the sentences in each document are grouped into related clusters. Each cluster is known as a sub-domain of the content, created based on different criteria such as semantic similarity, topic similarity, or other features. After grouping the sentences in some clusters, then a summary is generated by selecting the most relevant sentences from each cluster [2].
Graphical based approach
In this approach, the documents are represented as a graph where the sentences are the nodes and the edges between them indicate their relationships. The graph is then analyzed using various algorithms to identify the most important sentences or nodes, which are then used to create a summary. One popular algorithm used for this purpose is the PageRank algorithm, which is also used by Google to rank web pages. In this algorithm, each node is assigned a score based on the number and quality of incoming edges. The nodes with the highest scores are considered the most important and are selected for the summary [3].
Latent semantic analysis approach
Latent semantic analysis (LSA), a statistical method which analyzes relationships between a set of documents and the terms they contain by creating a matrix that represents the relationships between the documents and these terms. This matrix is then decomposed using singular value decomposition (SVD), which allows the important concepts and relationships between documents and terms to be identified. Once the important concepts have been identified, the LSA approach can be used to generate a summary by selecting the most relevant sentences based on their similarity to the important concepts. This is typically done by calculating a score for each sentence based on its similarity to the important concepts, and then selecting the top-scoring sentences for inclusion in the summary [4].
Discourse based approach.
In discourse-based approach, the important sentences are selected based on their content and consider the relationships between sentences in the text. One common approach is to use rhetorical structure theory (RST), in which the relationships between sentences in a text are identified based on their rhetorical function (e.g. elaboration, contrast, cause-effect) and a tree structure is created to represent the discourse [5]. The summary is then produced by selecting a subset of sentences from the original text that preserves the important rhetorical relationships. Another approach is to use entity-based discourse models, which represent the entities mentioned in the text and their relationships. The summary is then produced by selecting sentences that contain important entities and maintain the relationships between entities.
2.2. Supervised learning methods
The idea behind machine learning is to use a training set of data to train the summarization system, which is modeled as a classification problem. Sentences are classified into two groups: summary sentences and non-summary sentences. The probability of choosing a sentence for a summary is estimated according to the training document and extractive summaries. Some of the common machine learning methods used for text summarization are the naïve Bayes classification, artificial neural network... [6].
Naïve Bayes method
Naïve Bayes is a supervised learning method, considers the selection of a sentence as a classification problem, in which, each sentence is put in a binary class to determine whether it will be included in the summary or not [7]. To summarize a text using Naïve Bayes, the algorithm first trains a large dataset of previously summarized texts and their associated topics. Then, for a new input text, the algorithm uses the probability of each word being associated with a particular topic to identify the most relevant sentences. Naïve Bayes summarization has some advantages over other methods, such as its simplicity and speed. However, it also has some limitations, such as its reliance on the quality of the training data and its inability to capture complex relationships between words.
Neural Network (NN) based method.
The artificial neural network (ANN) for text summarization typically consists of multiple layers of interconnected nodes that process text data and select sentences in an extractive summarization based on the patterns and relationships in the data. There are three phases of this approach: neural network training, feature fusion, and sentence selection. The neural network training to identify the type of sentences that should be inserted in the summary. The feature fusion phase, feature combining which also called as feature fusion, feature selecting which is also called as feature pruning by applying both to the neural network which give away the hidden layer unit activations into discrete values with frequencies. This phase finalises features that must included in the summary sentences by combining the features and finding fashion in the summary sentences. The training phase identifies the types of sentences that should be presented in the document summary. An ANN for text summarization can be a powerful tool for automatically generating summaries of large amounts of text data. As with any machine learning model, the quality of the summary output depends on the quality of the input data and the accuracy of the model's training [8].
Conditional Random Fields (CRFs) Method
In Conditional Random Fields (CRFs) based text summarization, the algorithm learns to identify important sentences or phrases in the input text by analyzing the relationships between the words and phrases in the text, which requires a large amount of annotated data for training. The training data consists of pairs of input texts and their corresponding summaries. The CRFs algorithm then learns to identify the important features of the text, such as the frequency of certain words, the position of certain phrases, and the relationships between words and phrases. Once the CRFs model is trained, it can be used to generate summaries for new input texts. The algorithm analyzes the input text and assigns a probability score to each sentence or phrase based on its importance in the text. The sentences or phrases with the highest probability scores are then selected to generate a summary for a new document. CRFs have been shown to be effective for text summarization, achieving state-of-the-art performance on some benchmark datasets. They are particularly useful for generating abstractive summaries, where the summary sentences may not appear in the original document [9].
Pre-trained models
The emergence of Transformer [10] boosts the performance of summarization models, in which pre-trained-based summarizers obtain the best results on various benchmark datasets.
BERT stands for Bidirectional Encoder Representation from Transformer [14], which is a pretrained word embedding model developed in 2018 by researchers at Google AI Language for natural language processing. BERT uses masked language models to enable pretrained deep bidirectional representations and can be applied on almost of language tasks: Sentiment Analysis, Text prediction, Text generation, Summarization... with revolutionary improvements in previous models.
The special thing about BERT is that it can balance the scene in both left and right directions. Transformer's attention mechanism will transmit all the words in the sentence simultaneously into the model at once without paying attention to the direction of the sentence. The Transformer is therefore considered as bidirectional training although in fact we can more accurately say that it is non-directional training. This feature allows the model to learn the context of a word based on all surrounding words, including words on the left and right.
HIBERT, one of the major advantages of the HIBERT model is that it can handle long documents by breaking them down into individual sentences and then summarizing them into a coherent whole. This allows it to generate summaries that are more accurate and informative than other models. The HIBERT model has achieved state-of-the-art performance on several benchmark datasets for text summarization, including the CNN/Daily Mail and New York Times datasets [11].
PNBERT, In PNBERT model the sentence encoder is instantiated with a CNN layer. The LSTM-based structure and the Transformer structure were investigated at the level of document encoder. For the Decoder, both auto-regressive (Pointer Network) and non-auto-regressive (Sequence Labeling) architectures were investigated. PNBERT has achieved state-of-the-art results on CNN/Daily Mail by a large margin based.
An Additional difference, BERTSUM uses interval segmentation embeddings to distinguish multiple sentences [12].
DiscoBERT is a pre-trained transformer model based on BERT To perform compression with extraction simultaneously and reduce redundancy acrosss sentences, DISCOBERT takes elementary discourse unit (EDU), ca sub-sentential phrase unit originating from RST as the minimal selection unit (instead of sentence) as candidates for extractives election. To capture the long-range dependencies among discourse units, structural discourse graphs are constructed based on RST trees and coreference mentions, encoded with Graph Convolutional Networks. This model achieves new state-of-the-art on two popular news wire text summarization datasets (CNN/DailyMail and NYT), outperforming other BERT-based models [13].
BERTSum is a variant model of BERT, which uses fine tuning layers to add document-based context from the BERT outputs for extractive summarization [15]. The main difference between BERT and BERTSUM is the change of the input format, in which, a [CLS] token is added at the start of each sentence to separate multiple sentences and to collect features of the preceding sentence.
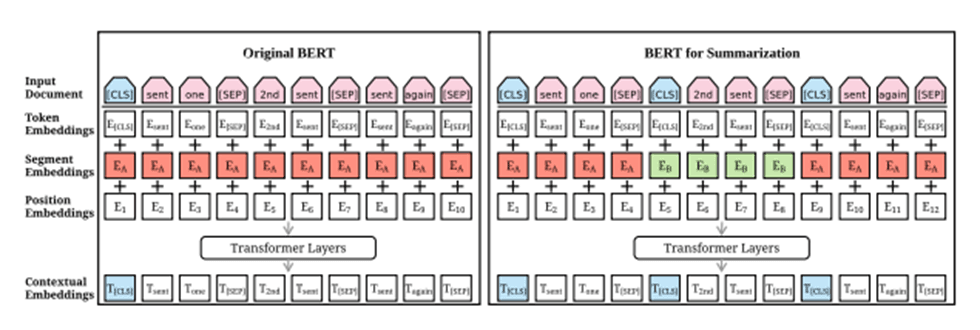 Fig. 1. BERT and BERTSUM model
Fig. 1. BERT and BERTSUM model
An Additional difference, BERTSUM uses interval segmentation embeddings (illustrated in red and green color) to distinguish multiple sentences [16].
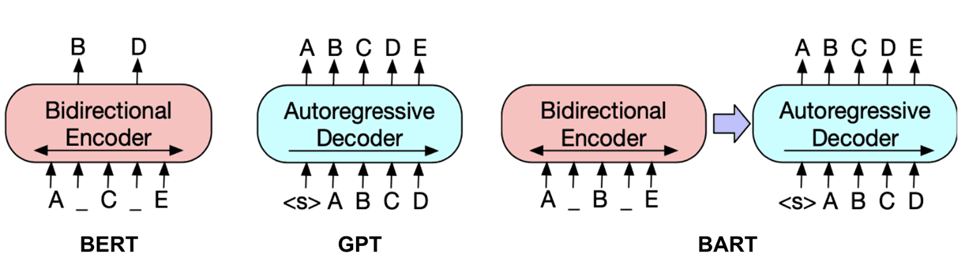 Fig. 2. BERT and BART model
Fig. 2. BERT and BART model
In comparison with BERT, BART have two differences: (1) each layer of the decoder additionally performs cross-attention over the final hidden layer of the encoder (as in the transformer sequence-to-sequence model); and (2) BERT uses an additional feed-forward network before word prediction, which BART does not.
3. The Proposed Method
BART, Bidirectional Auto Regressive Transformer with an architecture and pre-training strategy is a denoising auto-encoder built with a sequence-to-sequence model that is applicable to a very wide range of end tasks. BART is particularly effective when fine tuned for text generation but also works well for comprehension tasks [17]. While BERT corresponds to the encoder part only, we have to train a decoder for our specific task, BART contains an encoder encoder like in BERT and an auto regressive decoder like GPT. BART can be used for multiple tasks: token masking, tokens detection, text infilling, sentence permutation, and document rotation.
3.1. Prior knowledge
For document d={s1, s2, …, sn} with n sentences, the prior knowledge of the document is understood as the importance level of each sentence in document d. Existing knowledge (Prior Knowledge) is defined as a matrix A = [n х n] initialized from text d through some operations calculating sentence similarity. In which, each value A represents the semantic correlation between sentence si and sentence sj.
3.2. Problem statement
For a document d={s1, s2, …, sn} with n sentences, the task of the text summarization problem by extraction using a pre-trained model supplemented with prior knowledge is to classify the sentences in the text to evaluate whether they are important or not important.
Suppose 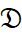 is the training text set, for sentence the probability of sentence si ∈ d being included in the summary is a conditional probability ŷi calculated according to the function
is the training text set, for sentence the probability of sentence si ∈ d being included in the summary is a conditional probability ŷi calculated according to the function 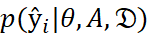 . The final summary will include sentences that are expected to be important. The hyperparameter θ can be learned from the training corpus
. The final summary will include sentences that are expected to be important. The hyperparameter θ can be learned from the training corpus 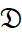 with or without the addition of prior knowledge A.
with or without the addition of prior knowledge A.
3.3. The Proposed Model
Based on correlation, there are several unsupervised methods for extracting summarization. We argue that the correlation between sentences can be a useful indicator that can guide the learning process to focus more on important sentences. To encode correlations with training, we introduce a new text extraction model. The model uses BERT as the basis, and the correlation indicator is fed into BERT through attention calculation.
Figure 3. Description of the proposed model to summarize extraction using prior knowledge. Given a document d with n sentences, the model first generates knowledge about d in the form of matrix A. The model then adds Tokens [CLS] and [SEP] to concatenate the n sentences to form a new input string. The new sequence is introduced into the transformer architecture to obtain the context vectors of each token. The knowledge from matrix A is fed into BERT's attention layers in the process of conditionally refining the sentence representation. Finally, the model uses the Token word vector [CLS] for classification to estimate the importance of each sentence. Sentences with high reliability of importance are selected to form the final sentence of the summary.
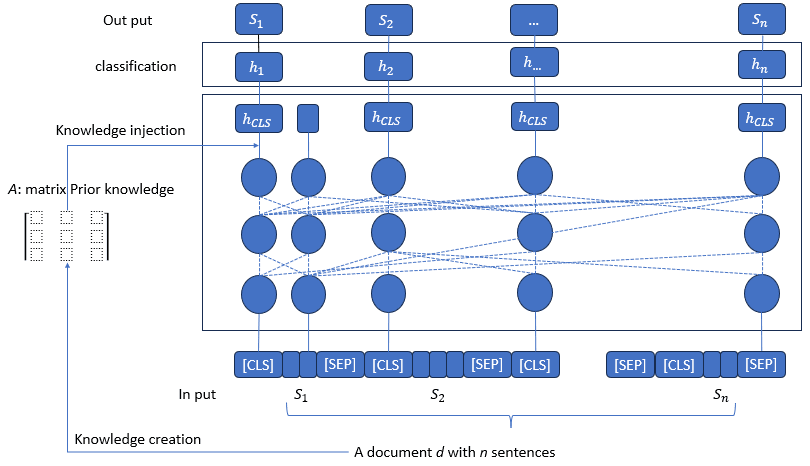
Fig. 3. The summary model uses Prior knowledge
The idea-sharing model fine-tune BERT for summarization [15]. However, instead of just using BERT, we introduce existing knowledge that encodes the correlation between sentences and feeds the knowledge into BERT. Binding causes BERT to focus more attention on some of the important sentences which helps improve the quality of the summary.
3.3.1. Prior knowledge creation from Cosine similarity
As mentioned, correlation exists between sentences in a document. Correlations are beneficial for estimating sentence importance. This section presents the knowledge generation available in Cosine similarity algorithms.
Cosine similarity
To calculate the similarity of two sentences, according to the Cosine measure, the sentences will be mapped into an n-dimensional vector space. After mapping, the correlation between the two sentences is calculated using the similarity Cosine of two corresponding vectors.
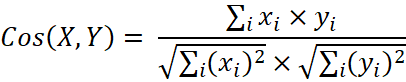
3.3.2. Input Representation
Once knowledge has been created, the model maps input sequences to context vectors to enrich the knowledge.
With an input document d={s1, s2, …, sn} containts n sentences, we concatenate two special tokens: [CLS] and [SEP]. More precisely, the token [CLS] is inserted at the beginning of each sentence to represent the meaning of the sentence. The [SEP] token is inserted at the end of each sentence to separate the two sentences.
Concatenating n sentences creates a new input sequence for embedding using the Transformer architecture. Input generation is shown in the input construction section as shown in Figure 3.
3.3.3. Knowledge injection
To generate knowledge, we use SentenceBERT [21] to calculate sentence embeddings and then form Cosine matrix A. Input embeddings are the sum of three parts: token embedding, location embedding, and segment embedding.
BERT's attention functions can be described as a mapping from a query vector Q and a set of key-value vector pairs (K, V) to an output vector - attention intensity.
The dot product of the query with all keys is calculated as follows.
scores = QKT
Prior knowledge is incorporated into the model by calculating the product of each element's score with Cosine similarity matrix A to make the model. The image pays more attention to pairs of sentences with higher similarity in the document.
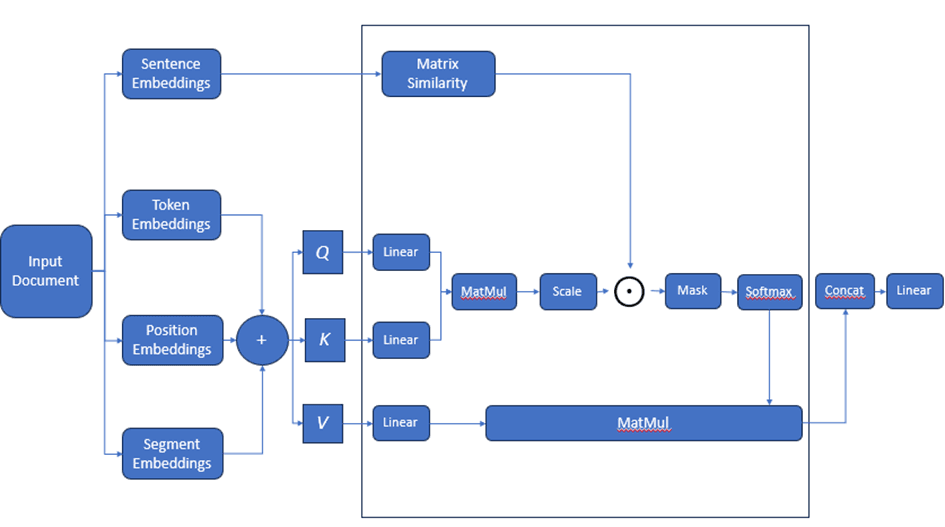 Fig. 4. Knowledge injection into BERT’s multi-head attention
Fig. 4. Knowledge injection into BERT’s multi-head attention
The calculation is then scaled back 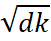 and the softmax function is applied to obtain weights on the values.
and the softmax function is applied to obtain weights on the values.
scores = QKT ⊙ A + MASK
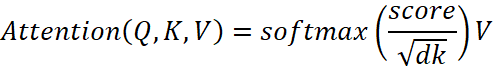
where A represents prior knowledge in the form of a correlation matrix.
In this study, prior knowledge was included only in the first attention layer and the first two layers of BERT.
After adding the knowledge of Figure 3, the implicit representation of the input sequence S is shown as follows.
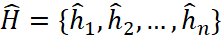
The representation of H is the input for classification to estimate the importance of the sentences corresponding to each latent vector hi. The final output layer is the sigmoid classifier:
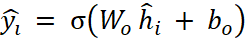
where yi is the predicted probability of sentence si indicating the importance of the sentence.
3.3.4. Sentence selection
After training, the model is applied to the test sets to extract document summaries. After ranking the predicted sentences based on their importance (score), the model uses the Maximum Marginal Relevance (MMR) algorithm [22] to form the final summary. MMR iteratively builds a summary by including the sentence with the highest score with the following formula:
Snext= maxs∈ S-Ssum(0.7*f(s) - 0.3*sim(s,Ssum))
where S is the set of all sentences in the document, Ssum contains the sentences currently in the summary, f(s) is the sentence score from the model, sim() is the Cosine similarity of the sentence with Ssum.
3.3.5. Training and inference
To train, the model receives input documents and applies knowledge from that document to the training process. The representation of context vectors of tokens [CLS] is used to predict the decision whether a sentence is important or not using the sigmoid function.
The loss function is the binary cross-entropy loss, which measures the difference between the predicted probability 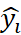 and the target label yi over N training samples.
and the target label yi over N training samples.
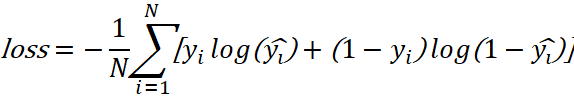
To infer, given an input document, the model is trained to estimate the importance of each sentence using the input knowledge. After prediction, m important sentences (with the highest probability) are selected to form the final summary using the MMR algorithm.
4. Experimental Settings
4.1. Dataset
The evaluation uses two datasets summarizing text in Vietnamese.
VNDS
VNDS is a benchmark dataset for Vietnamese summarization [18]. The dataset consists of 150,704 documents collected from news providers in Vietnam and was divided into three sets in the following ratio: 70% for training, 15% for development, and 15% for testing. Each document contains a title, a gold summary, and sentences.
VNNews.100.2018
VNNews.100.2018 is a dataset randomly select articles from Vietnamese electronic newspaper sites including http://dangcongsan.vn, https://news.zing.vn, https://vnexpress.net [19]. Each article has about 500 words or more. Each article includes title, cover letter (chapeau), content, keywords and tag words and an extracted version to retain about 30% of the sentences in the text by an experienced journalist.
4.2. Implementation
We used PyTorch and the “bert-base-uncased” version of BERT to implement the model. We also used SentenceBert [23] to tokenize each sentence for creating prior knowledge from the Cosine similarity.
The models were trained in 50,000 steps with the learning rate of 2e−3 on an A100 GPU. In this study, we use the Adam optimizer with β1 = 0.9 and β2 = 0.999. The learning rate follows the warming-up method value is 10000.
lr=2e-3.min(step-0.5,step.warmup-1.5)
4.3. Evaluation method
Rouge (Recall-Oriented Understudy for Gisting Evaluation) is a set of metrics to evaluate Automatic Summarization of texts or Machine Translation. Rouge compares an automatically generated summary or translation with a reference summary (usually human-generated).
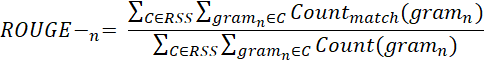
ROUGE-N: Measures the overlap of n-grams between automatically generated summaries and reference summaries. In n-gram the value of N can vary from 1 to n, but as the value of n increases, the computational cost also increases rapidly. The mainly used n-gram metrics are uni and bi-gram. With ROUGE-1, we consider each single word (gram); ROUGE-2 weighs 2 grams.
5. Results and Discussion
The performance comparison was done with two scenarios. First, the model is trained on the VNDS dataset with and without injection Cosine prior knowledge, after that it is tested on the VNNews.100.2018. The summary extracts the five most important sentences of the article and compares it with the sapeau of article.
Table
ROUGE score of dataset VNNews.100.2018
|
Data |
Method |
ROUGE-1 |
ROUGE-2 |
ROUGE-L | |
|
Train |
Test | ||||
|
VNDS |
VNNews.100.2018 |
No injection |
32.67 |
17.01 |
26.86 |
|
Injection Cosine |
33.49 |
17.55 |
27.11 | ||
The ROUGE score in Table shows that the addition of knowledge benefits the proposed model for extraction summarization. The ROUGE score of the proposed model is always better than the baseline score without using the knowledge addition method. The reason is that prior knowledge can encode the correlation between sentences in the document. By representing knowledge as a matrix, the model can take knowledge into account during training. Therefore, it helps improve the assessment of sentence importance.
6. Conlusion
This paper introduces a method for extractive summarization in Vietnamese language on the domain of online newspapers. The method considers context representation from BERT and prior knowledge obtained from sentence similarity of document. Prior knowledge is injected into attention layers of BERT, force the model to focus more on important sentences. Experimental results confirm two important points. Firstly, prior knowledge makes the performance of the summarization model improve. Second, we can study this method to inject various types of prior knowledge to improve the performance of sumarization.
