
In recent years, the gaming industry has taken a huge leap forward and has begun to attract more and more people around the world. It is quite easy to understand such a rise in the popularity of video games: all thanks to the widespread use of computer technology. Thanks to this, unlike other forms of entertainment, computer games have become much more accessible to the end user.
The Russian gaming market is no exception, and its importance and potential continue to grow every year. The rapid growth in the number of players and the variety of gaming platforms create huge opportunities for the development of the industry in the Russian Federation.
In 2021, the Internet Development Institute (IDI) of the Russian Federation announced that they plan to provide long-term support for game projects of Russian developers. In 2022, due to the refusal of major stores to accept payments from Russia, the government plans to support the Russian gaming market by allocating at least 1 billion rubles for the development of computer games in Russia. In 2022 the IRI intends to support about 177 game projects created by Russian developers.
As the industry itself grows, so do the requirements for the games themselves, and one of the most important aspects is artificial intelligence. Under game artificial intelligence is understood a set of software methods that are used in video games to create the illusion of intelligence in non-player characters.
In-game artificial intelligence can be applied to various aspects of gaming, such as managing the behavior of enemies, allies, or neutral characters, creating adaptive gameplay, managing game balance, creating realistic and challenging artificial behavior, and more.
The development of in-game artificial intelligence is of great importance to the gaming industry as it can significantly improve the gaming experience of players, making it more immersive, diverse, and challenging. Also, gaming artificial intelligence can help developers create more complex and engaging games, which helps to attract new players and retain existing audiences.
This paper proposes to review Q-learning methods with approximation: DQN and its modification DDQN.
Methods
One of the Gym library environments was chosen as the environment for reinforcement learning.
Gym is a library for developing and testing reinforcement learning algorithms developed by OpenAI. It provides a set of environments for creating and evaluating agents that can learn in the environment and make decisions based on their experience. Various environments for agent learning are provided, such as Atari games, robot simulators, classical control problems and many others. And also Gym provides a user-friendly interface to create your own learning environments.
Reinforcement learning is a machine learning method in which an agent learns based on the experience gained from interacting with the environment. It is used to train systems to make decisions and act in uncertain and volatile environments, which is well suited for gaming projects.
Q-learning. Q-learning is one of the reinforcement learning algorithms, the main idea of which is that an agent can independently learn to choose optimal actions in each situation without having a predetermined strategy. In the process of learning, a utility function Q is formed on the basis of the reward received from the environment, which allows the agent to take into account its past experience of interaction with the environment.
The Bellman equation for Q-learning is: 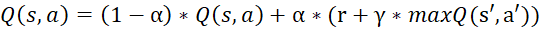 , where α is the learning rate, r is the reward received, γ is the discount factor (reflecting the importance of future rewards), s' is the next state, a' is the next action.
, where α is the learning rate, r is the reward received, γ is the discount factor (reflecting the importance of future rewards), s' is the next state, a' is the next action.
Q-learning, however, has disadvantages. Since conventional Q-learning requires computing values over all state-action pairs, the execution can take a large amount of time in an environment with a large number of actions.
The main problem with conventional Q-learning is that the state space may not be discrete, in which case compiling a Q-table is an extremely hard task. In order to avoid this, Q values should be approximated. One option for approximation is the use of neural networks.
Deep Q Network (DQN). DQN is a deep learning algorithm that uses a neural network to train an agent to make decisions in the environment.
DQN uses the neural network to determine the Q-function score. The Q-function values provide an estimate of how well the agent will perform in a particular state given all subsequent actions.
The Bellman equation for computing the Q-function is:  , where Q(s, a) is the value of the Q-function for state s and action a, r is the reward for performing action a in state s, γ is the discount factor, s' is the next state after performing action a in state s, a' is the action chosen using a greedy strategy.
, where Q(s, a) is the value of the Q-function for state s and action a, r is the reward for performing action a in state s, γ is the discount factor, s' is the next state after performing action a in state s, a' is the action chosen using a greedy strategy.
The input of the neural network is a screen describing the current game situation, after which it passes through a DQN network representing several convolutional layers, and then through several fully connected layers. The output of the network is the choice of action.
The architecture of the DQN network:
- Conv1(4, 32, 8, 4) is the first convolutional layer,
- Conv2(32 64, 3, 2) is the second convolutional layer,
- Conv3(64, 64, 2, 1) is the third convolutional layer,
- Fn1 (7*7*64, 512) is the first full-link layer,
- Fn2 (512, action) is the second full-link layer.
There are two other important components in DQN: Replay Memory and a separate target function.
1. Replay Memory is a buffer that stores sequences of states, actions, rewards, and next states that the agent has interacted with the environment.
Instead of training a neural network on sequential observations, mini-packets of data are randomly selected from Replay Memory for training. This allows the agent to learn from a wider variety of data and avoid overtraining on specific sequences.
2. The individual target function has the same architecture, but the target network parameters are updated much less frequently. Instead of using predicted Q-values to update immediately after each learning step, the DQN algorithm uses the target network to compute target Q-values, which are then compared to the predicted Q-values to compute the learning error.
The target network parameters are updated much less frequently. Instead of using the predicted Q-values to update immediately after each training step, the DQN algorithm uses the target network to compute target Q-values, which are then compared to the predicted Q-values to compute the learning error.
Double Deep Q Network (DDQN). DDQN is a modification of the DQN algorithm designed to improve its performance and stability when training a neural network.
The Bellman equation for DDQN is:  , where Q function value for state s and action a, r is the reward for performing action a in state s, γ is the discount factor, s' is the next state after performing action a in state s, a' is the action selected using a greedy strategy, Q_target is the target Q network
, where Q function value for state s and action a, r is the reward for performing action a in state s, γ is the discount factor, s' is the next state after performing action a in state s, a' is the action selected using a greedy strategy, Q_target is the target Q network
The basic idea behind DDQN is that instead of using a single neural network for Q-value estimation and action selection, as is done in classical DQN, two separate neural networks are used: one for action selection and one for Q-value estimation. This allows the separation of the action selection process from the action value estimation, which can lead to more stable learning.
Conclusion
Nowadays, due to the huge growth in popularity of the video game industry, the demand for the quality of the games themselves, as well as one of the most important aspects of modern video games - artificial intelligence - is also growing. This paper discusses one type of reinforcement learning, Q-learning and its variant, Q-learning with approximation, as a way of realizing artificial intelligence in video games. The main advantage of Q-learning is the relative simplicity of its realization and the ability to learn in uncertain environments. However, in complex systems, with a large number of states, the algorithm can run slowly and as one way to solve this problem we consider the use of approximation with the help of neural networks.
