
Социальные сети, такие как Twitter, Facebook, ВКонтакте и другие, представляют собой одни из самых популярных площадок в сети Интернет. Здесь люди могут делиться разнообразной информацией: обмениваться сообщениями, публиковать свои мнения и отзывы о различных событиях. Например, они могут обсуждать политические новости, делиться впечатлениями о новых кинофильмах, а также обсуждать другие актуальные события. Исследование, проведенное Kaplan и Haenlein в 2010 году, подтверждает, что социальные сети играют важную роль в обмене информацией и взаимодействии между пользователями.
В сфере информационного обмена через социальные сети активно участвуют миллионы пользователей. Передаваемая информация может иметь как личный, так и публичный характер. Количество публичных текстов постоянно растет, что привлекает внимание различных социальных, рекламных и маркетинговых служб [4, с. 21]. Это явление подтверждается исследованиями, проведенными в данной области. Согласно данным Brand Analytics за 2017 год, в среднем летом наиболее популярные социальные сети в России публиковали более 200 миллионов публичных сообщений в месяц. Эти тексты часто размещаются пользователями в открытом доступе, чтобы выразить свою позицию по отношению к различным событиям. Громадный объем такой информации и её оценочный характер позволяют собирать статистику о событиях в виде мнений. Анализ таких данных позволяет выявить общественную оценку тех или иных событий.
Из-за обширного объема информации, используемой при анализе, стало необходимым применять компьютерные технологии для автоматизации этого процесса. Для извлечения мнений из текста с использованием компьютеров требуется применение формализованных методов оценки мнения. Один из главных методов выявления отношения человека к событию в тексте заключается в определении эмоциональной окраски (тональности). Эта окраска формируется на основе слов, выражающих положительное или отрицательное отношение автора. Анализ эмоциональной окраски текста заключается в классификации текстов на группы, которые положительно или отрицательно оценивают события, а также на тексты, которые невозможно однозначно классифицировать [10, с. 53]. Для анализа текстов необходимо учитывать специфические особенности каждого из них. Отношение человека к событию может быть выражено кратко, в нескольких словах, а также в длинных повествованиях. Это может быть как литературный, так и разговорный стиль. Например, отзыв о фильме на специализированном интернет-ресурсе, таком как «КиноПоиск», зачастую представляет собой объемную рецензию, соблюдающую правила русского языка и использующую эмотивную лексику (то есть лексику с ярко выраженной эмоциональной окраской) [7, с. 44]. В то время как публикации в социальных сетях обычно отличаются малым объемом текста, наличием сокращений и иногда содержат орфографические ошибки и сленговые выражения. При этом такие тексты могут не содержать прямой оценки события.
В настоящее время эта проблема привлекает внимание экспертов, что способствовало формированию различных подходов к решению задачи автоматического анализа мнений.
Автоматический анализ текста требует формализованного подхода к представлению текста. В задачах классификации документ представляется в виде вектора N-грамм, то есть совокупности N последовательных слов текста. Чаще всего используются N-граммы малых порядков – униграммы и биграммы, так как они обеспечивают лучшие результаты. Последовательности из трех и более связанных по смыслу слов встречаются значительно реже, поэтому N-граммы высших порядков могут быть избыточными и давать менее точные результаты [6, с. 65]. Иногда также используется комбинация униграмм и биграмм. Этот подход позволяет получить более точные результаты, так как он учитывает не только частоту использования отдельных слов, но и их последовательные пары [2, с. 32]. Примерно так. Если мы рассмотрим предложение «Эта новость меня приятно удивила», то его представление в виде векторов будет следующим:
- Униграммы:
- «эта»
- «новость»
- «меня»
- «приятно»
- «удивила»
- Биграммы:
- «эта новость»
- «новость меня»
- «меня приятно»
- «приятно удивила»
- Комбинация униграмм и биграмм:
- «эта»
- «новость»
- «меня»
- «приятно»
- «удивила»
- «эта новость»
- «новость меня»
- «меня приятно»
- «приятно удивила»
Такое представление позволяет учесть как отдельные слова, так и их последовательные пары в тексте.
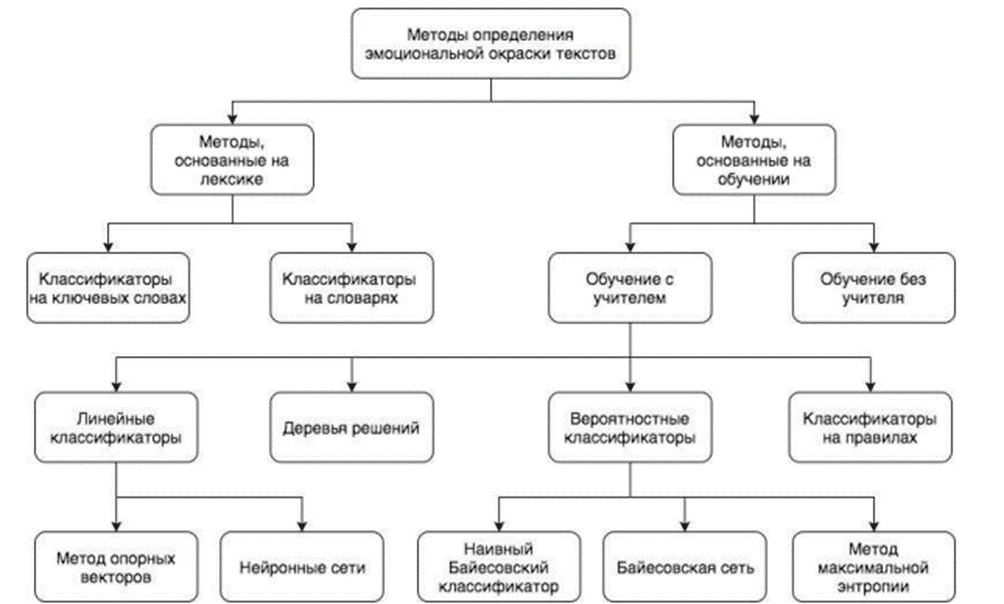
Рис. 1. Классификация методов определения эмоциональной окраски текстов
Существуют две основные группы методов анализа эмоциональной окраски текста:
1. Методы, основанные на лексике:
Эти методы используют словари или лексические ресурсы, чтобы оценить эмоциональную окраску слов в тексте. Например, слова «радостный» или «грустный» могут иметь положительную или отрицательную тональность соответственно.
2. Методы, основанные на машинном обучении:
Эта группа методов использует алгоритмы машинного обучения для автоматического определения тональности текста.
Обучение с учителем: здесь используются размеченные данные (с текстами, помеченными как положительные, негативные или нейтральные), чтобы обучить модель классификации.
Обучение без учителя: эти методы не требуют разметки данных и позволяют выявлять общие закономерности в текстах (рис. 1).
Первая категория методов основана на эмотивной лексике в тексте. Она вычисляет тональность текста на основе тональности отдельных слов и их комбинаций, используя заранее составленные словари тональностей и правила вида «если – то». При этом применяется лингвистический анализ. Одним из ключевых моментов при использовании таких методов является сложность процесса составления необходимых словарей и правил. Готовых словарей тональностей для русского языка в открытом доступе на данный момент не существует, а процесс сопоставления каждому слову эмоциональной окраски является нетривиальным. Кроме того, данный подход неустойчив к орфографическим ошибкам или сокращениям, которые часто встречаются в публикациях в социальных сетях.
Методы второй категории различаются по наличию или отсутствию обучающей выборки (корпуса) данных. Обучение без учителя – это раздел машинного обучения, в котором закономерности и взаимосвязи между объектами определяются из неразмеченной выборки (то есть выборки, где эмоциональная окраска текстов заранее не определена экспертом (учителем)) [3, с. 22]. В рамках методов обучения без учителя данные из выборки разбиваются на классы, которые близки по различным свойствам (например, позитивно или негативно окрашенные тексты). Одной из разновидностей таких методов является кластеризация. При этом любой алгоритм кластеризации требует наличия функции определения расстояния между двумя объектами выборки. Например, такие величины могут представлять собой расстояния между векторами признаков двух документов. В анализе данных часто используется расстояние Евклида (1):
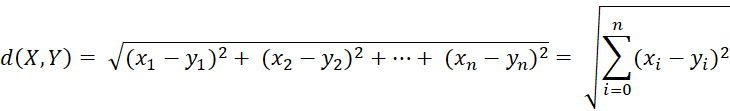 (1)
(1)
где x и y – это n-мерные векторы, представляющие объекты из исходной выборки. В задачах классификации текстов можно рассматривать векторы, полученные из униграмм, биграмм и других текстовых признаков. Эти векторы представляют собой числовые представления текстовых данных, которые могут быть использованы для обучения моделей машинного обучения и классификации текстов.
В задачах анализа эмоциональной окраски текстов с помощью обучения без учителя используется следующая идея: больший вес при классификации конкретного текста присваивается словам, которые часто встречаются в нём, но реже – в остальных объектах выборки. Эмоциональная окраска всего текста определяется на основе весовых коэффициентов таких слов [9, с. 65]. В задачах анализа эмоциональной окраски текстов весовой коэффициент обычно принимает значение на отрезке от -1 до 1. Этот коэффициент показывает степень принадлежности слова к тому или иному классу. Например, для слова «отличный» весовой коэффициент стремится к единице, в то время как для слова «ненавижу» он будет близок к -1. Для слова «привет», не несущего никакой эмоциональной окраски, этот коэффициент будет находиться в некоторой окрестности нуля. Тем не менее, для данного подхода также необходим словарь тональностей слов, который, как было упомянуто ранее, отсутствует в открытом доступе. В результате этот метод не способен учитывать особенности текстов, характерные для социальных сетей.
Методы обучения с учителем используют заранее размеченную (обучающую) выборку, где для каждого объекта известна его эмоциональная окраска, определенная экспертом (учителем). На этой выборке система проходит первоначальное обучение, и поэтому для таких методов не требуется наличие тональных словарей. Формально обучающая выборка представляет собой массив пар (x, y), где x – вектор характеристик конкретного объекта, а y – класс, к которому учитель отнес этот объект. Создание обучающей выборки позволяет избежать необходимости использования тональных словарей и, в то же время, учитывать особенности предметной области. Обученная модель затем применяется для классификации неразмеченных текстов, также известных как тестовая выборка. Размер тестовой выборки может быть значительно больше размера обучающей выборки. Последняя представляется в виде пар (x, ?), где результирующий класс неизвестен [3, с. 22]. Важно отметить, что точность классификатора напрямую зависит от размера обучающей выборки. Чем больше текстов разметил эксперт, тем выше будет точность. Ручная настройка обучающей выборки также позволяет учесть специфические особенности конкретной предметной области. Например, можно включить в размеченный корпус тексты с применением узкоспециальных терминов, что способствует повышению точности автоматического анализа.
Важно отметить, что точность классификатора напрямую зависит от размера обучающей выборки. Чем больше текстов разметил эксперт, тем выше будет точность. Ручная настройка обучающей выборки также позволяет учесть специфические особенности конкретной предметной области. Например, можно включить в размеченный корпус тексты с применением узкоспециальных терминов, что способствует повышению точности автоматического анализа.
Главным преимуществом данного подхода является высокая точность даже для коротких текстов. Однако сложность его применения связана с трудоемким процессом составления обучающей выборки.
В рамках методов определения эмоциональной окраски с применением обучения с учителем можно выделить следующие подходы, которые отличаются своей эффективностью [10, с. 14]:
- Метод опорных векторов.
- Наивный Байесовский классификатор.
- Метод максимальной энтропии.
Эти методы позволяют эффективно решать задачи классификации текстов по их эмоциональной окраске.
Метод опорных векторов (SVM) основан на идее построения разделяющей гиперплоскости. Для этого требуется увеличить размерность пространства признаков текстов. Разделяющая гиперплоскость находится между двумя параллельными гиперплоскостями, которые, в свою очередь, представляют группы текстов со схожими свойствами (например, позитивные и негативные). Расстояние между этими гиперплоскостями зависит от того, насколько точно можно разделить выборку на эти группы. Если все тексты можно однозначно отнести либо к положительным, либо к отрицательным, то расстояние между гиперплоскостями будет максимальным. Таким образом, это расстояние характеризует точность классификатора: чем оно больше, тем меньше будет величина ошибки.
![]() (2)
(2)
Наивный байесовский классификатор (NB) – это статистический метод, основанный на теореме Байеса, которая описывает соотношение между условными вероятностями. В данном контексте (2) А и В представляют собой классы, к которым может принадлежать текст. Вероятность принадлежности документа d к классу ci определяется на основе частоты встречаемости признаков документа d в документах класса ci в обучающей выборке. Кроме того, в методе делается предположение об условной независимости признаков.
Метод максимальной энтропии (ME), в отличие от наивного байесовского классификатора, не базируется на предположении об условной независимости признаков. Для определения степени принадлежности документа к некоторому классу ci, вводится функция (3).
![]() (3)
(3)
В данном контексте wi представляет собой очередной признак вектора признаков корпуса документов. Далее оценка принадлежности документа d к классу ci вычисляется следующим образом [1, с. 56]:
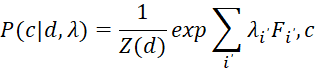 (4)
(4)
где:
- λi – вес i-го признака,
- Z(d) – функция нормировки, определяемая формулой (5):
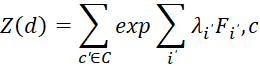 (5)
(5)
Для сравнения рассмотренных методов используем метрики точности (precision) и полноты (recall):
1. Точность (precision) (6):
- TP – истинно-положительное решение (количество документов, имеющих положительную окраску и отнесенных классификатором в эту группу).
- FP – ложноположительное решение (количество документов, имеющих не положительную окраску, но отнесенных классификатором в эту группу).
2. Полнота (recall) (7):
- FN – ложноотрицательное решение (количество документов, имеющих не отрицательную окраску, но отнесенных классификатором в эту группу).
![]() (6)
(6)
![]() (7)
(7)
Для наглядности также используем F1-меру, которая предоставляет гармоничную оценку, учитывая точность и полноту (8).
В таблице 1 представлены оценки метода максимальной энтропии и метода опорных векторов при представлении текста в виде вектора униграмм на основе данных из исследования [1, с. 14]. Метод максимальной энтропии продемонстрировал незначительно более высокую точность по сравнению с методом опорных векторов.
Таблица 1
Результаты сравнения методов ME и SVM
| Метод | Precision | Recall | F1 |
| ME | 0.81 | 0.735 | 0.77 |
| SVM | 0.77 | 0.75 | 0.76 |
Согласно исследованию [11, с. 10], для униграмм и комбинированного подхода наиболее точным методом среди рассмотренных (наивный байесовский классификатор, метод опорных векторов и метод максимальной энтропии) является метод опорных векторов с точностью в диапазоне 82–83%. Наивный байесовский классификатор и метод максимальной энтропии показывают приблизительно одинаковые результаты с точностью 80–81%. Для биграмма точность всех трех методов оказалась примерно одинаковой и составила 77% (табл. 2).
Таблица 2
Результаты сравнения точности методов NB, ME и SVM
| Метод | Unigram | Bigram | Unigram + Bigram |
| NB | 0.81 | 0.773 | 0.806 |
| ME | 0.804 | 0.774 | 0.808 |
| SVM | 0.829 | 0.771 | 0.827 |
На рисунке 2 представлены результаты сравнения наивного байесовского классификатора и метода опорных векторов на основе данных из исследования. Оказалось, что точность метода опорных векторов превосходит точность наивного байесовского классификатора как для униграмм, так и для биграмм, а также для комбинированного подхода. Аналогичные результаты были получены в другом исследовании [8, с. 43] (табл. 3). Кроме того, показатели полноты и F1-меры также оказались выше у метода опорных векторов.
Согласно исследованию [5, с. 10], результаты точности, полноты и F1-меры для всех рассмотренных методов оказались примерно одинаковыми (табл. 4). В данном случае тексты были представлены в виде векторов униграмм.
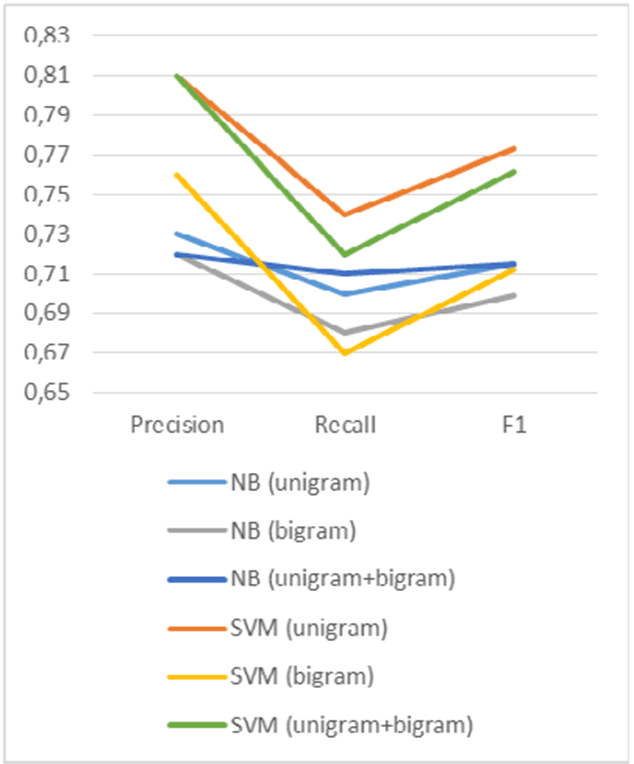
Рис. 2. График результатов сравнения показателей методов NB и SVM
Таблица 3
Результаты сравнения точности методов
| Метод | Unigram | Bigram |
| NB | 0.746 | 0.764 |
| SVM | 0.767 | 0.777 |
Таблица 4
Результаты сравнения методов
| Метод | Precision | Recall | F1 |
| NB | 0.79 | 0.78 | 0.78 |
| ME | 0.8 | 0.8 | 0.79 |
| SVM | 0.8 | 0.79 | 0.79 |
Исходя из проведенного сравнительного анализа, можно сделать вывод, что метод опорных векторов демонстрирует наилучшие результаты. Точность и полнота наивного байесовского классификатора и метода максимальной энтропии практически одинаковы, что говорит о том, что главное преимущество метода максимальной энтропии – отсутствие предположения об условной независимости признаков – не оказывает существенного влияния на результаты. Учитывая, что предположение об условной независимости признаков упрощает затраты на проведение анализа, использование наивного байесовского классификатора более обосновано в рамках задачи определения эмоциональной окраски текстов.
Сравнивая различные методы, можно сделать вывод, что представление текста в виде вектора униграмм дает наилучшие результаты по сравнению с другими способами. Это может быть связано как с особенностями предметной области, так и с размерами тестовых выборок. Интересно, что связи между двумя соседними словами не оказывают существенного влияния на задачу определения эмоциональной окраски текста. Важно учитывать конкретные слова для точного заключения о его тональности.
В исследовании рассмотрена задача определения эмоциональной окраски текстов в социальных сетях. Произведен сравнительный анализ методов, основанных на обучении с учителем:
- Метод опорных векторов.
- Наивный байесовский классификатор.
- Метод максимальной энтропии.
Анализ показателей точности, полноты и F1-меры привел к заключению, что лучшие результаты (независимо от способов представления векторов признаков) достигаются с помощью метода опорных векторов. Результаты метода максимальной энтропии и наивного байесовского классификатора отличаются незначительно, при этом реализация последнего значительно проще, в связи с чем его применение более приоритетно. Для достижения наибольшей точности в общем случае следует представлять исходные тексты в виде векторов униграмм.
