
Формулировка проблемы заключается в том, что большинство моделей генерации искусственной речи из текста работают на английском языке. Русскоязычные же версии, хоть и существуют, однако остаются далеки от иноязычных аналогов. Нейросетевой подход в последнее время показывает успехи в задаче синтеза речи. С их помощью можно производить качественную генерацию с выделением просодии голоса и его речевых особенностей. Однако русскоязычные модели синтеза речи пока не могут полноценно конкурировать с англоязычными аналогами. Это ограничивает доступ пользователей к технологиям синтеза речи на родном языке. Для решения этой проблемы необходимо продолжать исследования и разработку русскоязычных моделей синтеза речи. Улучшение качества таких моделей позволит обеспечить более широкий доступ к технологиям синтеза речи на русском языке и повысить удобство и качество коммуникации для пользователей.
Таким образом можно выделить две основные проблемы, связанные с разработкой полноценной системы синтеза речи (TTS) на русском языке с использованием нейронных сетей:
- Естественность звучания: Одной из ключевых задач при разработке TTS системы является достижение естественного и понятного звучания. Нейросетевые методы должны уметь генерировать речь, которая звучит, как настоящий человеческий голос. Это включает в себя правильное ударение, интонацию, паузы и другие аспекты, которые делают речь естественной.
- Производительность и скорость: Нейросетевые модели для TTS могут быть достаточно сложными и требовательными к вычислительным ресурсам. Одной из проблем является баланс между качеством синтеза и временем, необходимым для генерации речи. Разработчики должны стремиться к оптимальной производительности, чтобы обеспечить быстрый и отзывчивый синтез речи.
Важно учитывать, что эти проблемы могут иметь разные решения в зависимости от выбранной архитектуры нейронной сети, объема обучающих данных и других факторов.
Smart Open Virtual Assistant (SOVA) – одни из первых предоставили полностью открытую систему синтеза речи (TTS) на русском языке. Эта реализация основана на оригинальной архитектуре Tacotron, описанной в статье Джона Шена. Однако в SOVA реализованы различные подходы для улучшения качества синтезируемой речи. Модуль включает в себя предобработку текстовых данных, расстановку ударений в словах и перевод символов в числовой вектор. На данный момент SOVA поддерживает только русский и английский языки, но есть возможность добавления своих языков и обработчиков текста. Несмотря на отсутствие многоголосого синтеза речи, данная реализация может служить отправной точкой для создания еще более качественных многоголосых систем синтеза речи на русском языке. Также важно собрать систему, которая могла бы генерировать речь различными голосами.
Актуальность исследований в данной области обусловлено несколькими факторами:
- Рост интереса к голосовым интерфейсам: Голосовые помощники, аудиокниги, роботы и другие системы, использующие синтез речи, становятся все более популярными. Это создает потребность в более качественных и естественных голосовых системах.
- Прорывы в нейронных сетях: Современные нейросетевые архитектуры, такие как Tacotron, WaveNet и FastSpeech [2, с. 3617-3621], позволяют достичь высокого качества синтеза речи. Это стимулирует дальнейшие исследования и улучшение методов.
- Мультиязыковой синтез: С развитием международных коммуникаций возрастает потребность в TTS системах, способных работать на разных языках. Исследования направлены на создание многоголосых систем с поддержкой разных языков.
- Приложения в медицине и образовании: TTS может помочь людям с нарушениями речи, а также расширить возможности образования и доступности информации.
- Генерация контента: TTS используется для создания аудиоконтента, например, в подкастах, аудиокнигах и рекламных роликах. Это делает исследования в этой области актуальными.
Все эти факторы подтверждают, что исследования в области синтеза речи с помощью нейронных сетей остаются важными и перспективными. На современном этапе исследований в области синтеза речи с использованием нейронных сетей (TTS) происходит активное развитие и применение новых методов.
Далее предлагается рассмотреть методы решения задачи разработки полноценной системы синтеза речи на русском языке с использованием нейронных сетей. Существует несколько методов:
- Tacotron и Tacotron 2: Эти архитектуры основаны на рекуррентных нейронных сетях (RNN) и сверточных нейронных сетях (CNN). Они позволяют преобразовывать текст в спектрограммы и затем генерировать речь. Tacotron 2 улучшает качество синтеза, добавляя внимание (attention) и более сложные архитектуры [6, с. 3-16].
- WaveNet и WaveGlow: Эти генеративные модели, разработанные компанией DeepMind, используют сверхточные нейронные сети для прямой генерации аудиосигнала. Они достигают высокого качества, но требуют больших вычислительных ресурсов [7].
- FastSpeech и FastSpeech 2: Эти архитектуры используют трансформеры для генерации спектрограммы из текста. Они обеспечивают более быстрый синтез речи и хорошее качество [8, с. 3-16].
- Применение GAN: Генеративные состязательные сети (GAN) также применяются для синтеза речи. Они позволяют создавать более разнообразные и выразительные голоса [9].
- Производство обучающих данных: Сбор и подготовка больших объемов аудиоданных для обучения нейронных сетей – важный этап. Это включает в себя аннотацию, выравнивание и создание датасетов.
Для обучения подобному в систему добавляется энкодер – нейросетевая модель, которая преобразует сказанную речь в числовой вектор фиксированной длины. Благодаря созданной модели возможно различие голосов разных дикторов.
Общая схема генерации речи. Синтез речи состоит из 4 разных этапов: преобразование текста, выделение просодии голоса, создание мел-спектрограммы и преобразование мел-спектрограммы в синтезированную речь. Этапы представлены на рисунке 1.
На первом этапе просодия голоса кодируется с помощью энкодера. Просодия включает в себя такие характеристики, как тембр, высота, громкость и другие особенности. На втором этапе синтезируется мел-спектрограмма с использованием синтезатора. В качестве входных данных используются текст и вектор просодии голоса. В результате получается мел-спектрограмма, которая отображает изменение мощности сигнала во времени. На третьем этапе происходит преобразование мел-спектрограммы в синтезированную речь с помощью вокодера. Входными данными является мел-спектрограмма, а выходными – синтезированная аудиозапись.
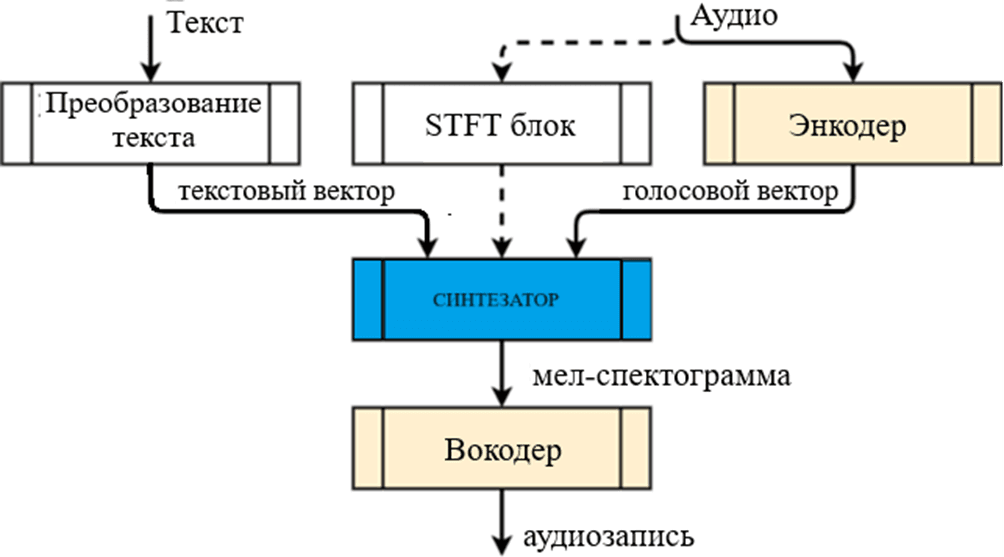
Рис. 1. Общая схема системы синтеза речи
Обучение энкодера. Для обучения использовались такие наборы данных, как Common Voice и LibriSpeech, а также данные, собранные с помощью аудиокниг. Common Voice – это многоязычный набор данных с открытым исходным кодом, включающий около 124 часов аудиозаписей на русском языке от 1638 носителей. LibriSpeech содержит примерно 98 часов аудиоданных на русском языке. Собранные данные проходят предварительную обработку: удаляются некачественные записи с неразборчивой речью, фрагменты с шумами и отрезки без речи. Постановка задачи для энкодера выглядит следующим образом. Пусть 𝑋 – матрица размером 𝑁 × 𝑀, где 𝑁 – количество дикторов, 𝑀 – количество высказываний и 𝑥𝑖𝑗 – 𝑗-e высказывание 𝑖-го диктора, 𝑌 – матрица, в которой каждому элементу 𝑦𝑖𝑗 ∈ 𝑌 соответствует вектор вещественных чисел, состоящий из 256 компонент 𝑦𝑖𝑗 = (𝑦1, 𝑦2, … , 𝑦256).
Вектор говорящего определяется по следующей формуле:
![]() (1)
(1)
где 𝑥𝑖𝑗 – 𝑗-е высказывание 𝑖-го диктора; 𝑤 – веса.
После подсчёта векторов дикторов необходимо вычислить их центроиды. Центроид – усреднённый вектор высказываний диктора [4], вычисляемый по формулам (2) и (3):
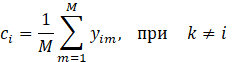 (2)
(2)
![]() (3)
(3)
где 𝑖 – номер диктора; 𝑗 – номер высказывания; 𝑘 – номер диктора, 𝑘 ∈ [0; 𝑁].
Затем необходимо найти матрицу подобия между всеми векторами-высказываниями и центроидами по формуле (4):
![]() (4)
(4)
Чтобы корректно определять просодии и идентифицировать говорящего, важно, чтобы вектор встраивания был близок к центроиду говорящего и отличался от векторов других говорящих (5). Итоговая функция потерь рассчитывается по следующей формуле (5):
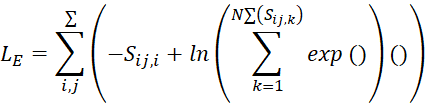 (5)
(5)
Обучение происходило методом обратного распространения ошибки, для оптимизации функции потерь был выбран оптимизатор Adam. Для определения качества нейросетевой модели была выбрана метрика, называемая метрикой равной частотой ошибок (EER), которая рассчитывается по следующей формуле:
![]() (6)
(6)
где 𝐹𝐴𝑅 доля неправильно верифицированных дикторов самозванцев, классифицируемых как подлинные; 𝐹𝑅𝑅 доля истинных дикторов, классифицируемых как самозванцы; данные значения показывают, когда нейросетевая модель правильно верифицировала диктора (𝑇𝐴) или отклонила диктора (𝑇𝑅), а также неправильно верифицировала диктора (𝐹𝐴) или неправильно отклонила диктора (𝐹𝑅).
Графики изменения значения функции потерь и метрики качества представлены на рисунке 2. В результате обучения нейронной сети на полученном графике видно, что при увеличении количества итераций уменьшалась функция потерь. В результате тестирования нейронной сети метрика, называемая равной частотой ошибок, уменьшилось, что свидетельствует о качестве обученной модели. В результате работы нейронной сети были получены графики, представленные на рисунке 3. Различные дикторы представлены различными цветами. Здесь представлено 50 дикторов, у каждого по 16 высказываний. В процессе обучения 16 высказываний одного диктора становятся настолько близки друг к другу, что отображаются практически в одну точку.
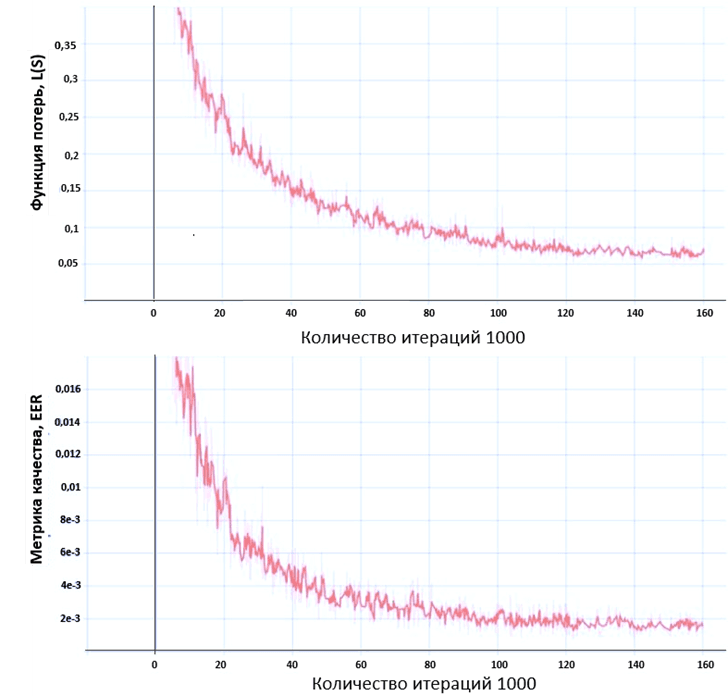
Рис. 2. Изменение значения функции потерь (сверху) и метрики качества (снизу)
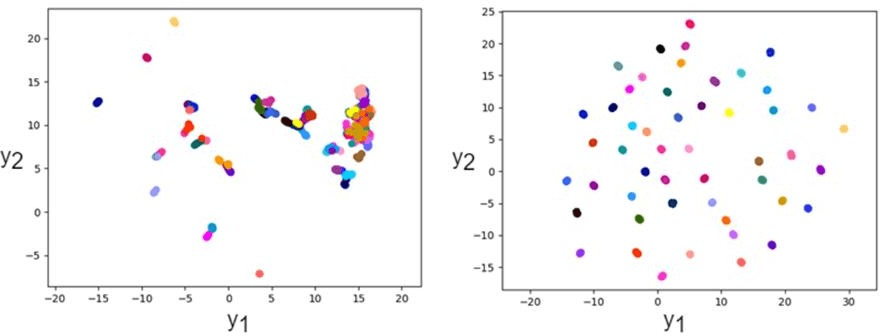
Рис. 3. Отображение векторов после 1000 (слева) и 140000 (справа) итераций
Обучение синтезатора. Для обучения в качестве источника данных использовался набор Common Voice Corpus 6.1 и часть данных была собрана при помощи аудиокниг. Набор данных Common Voice Corpus 6.1 включает более 80000 аудио на русском языке. На вход нейросетевой модели подаётся текст и мел-спектрограмма, полученная из исходной аудиозаписи. Мел-спектрограмма – это спектрограмма, где частота выражена в мелах (рисунок 4).
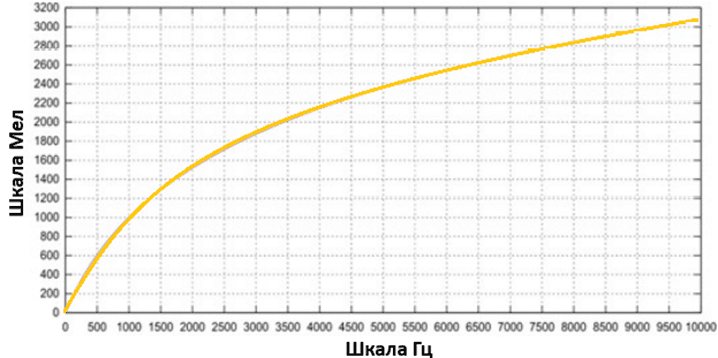
Рис. 4. График зависимости частоты от мел
В качестве основной функции потерь используется линейная комбинация трех функций потерь, представленных в формуле (7).
![]() (7)
(7)
где 𝐿𝑚𝑒𝑙 – среднеквадратическая ошибка между синтезированной мел-спектрограммой и оригиналом; 𝐿𝑔𝑎𝑡𝑒 – бинарная кросс-энтропия с сигмоидальной функцией; 𝐿𝑠𝑠𝑖𝑚 – функция ошибки, основанная на индексе структурного сходства. Бинарная кросс-энтропия с сигмоидальной функцией, которая представлена в формуле (8), служит для контроля своевременной остановки синтеза мел-спектрограмм.
![]() (8)
(8)
![]() (9)
(9)
где 𝑛 – число точек на временном отрезке; 𝑥, 𝑦 – соответствуют символам окончания синтеза для исходной мел-спектрограммы и синтезированной.
Среднеквадратичная ошибка (англ. «Mean Squared Error»), которая представлена в формуле (10), используется для оценки среднеквадратического различия между предсказанной мел-спектрограммой и исходной.
![]() (10)
(10)
где 𝑥 и 𝑦 соответствуют оригинальной и синтезированной мел-спектрограмме; 𝑛 – число точек данных по всем переменным.
Индекс структурного сходства (Structural Similarity Index Measure), который выражается формулой (11), определяет различия между двумя изображениями. Область значений находится на промежутке от 0 до 1, где 1 означает полное сходство двух изображений, а 0 полное несоответствие.
![]() (11)
(11)
где 𝜇𝑥 и 𝜇𝑦 – средние значения картинок 𝑥 и 𝑦; 𝜎𝑥 и 𝜎𝑦 – среднеквадратичные отклонения для картинок 𝑥 и 𝑦; 𝜎𝑥𝑦 ковариация 𝑥 и 𝑦; 𝑐1 = (𝑘1𝐿)2, 𝑐2 = (𝑘2𝐿)2 – поправочные коэффициенты для стабилизации деления с малым знаменателем; 𝐿 = (2(𝑁 бит на пиксель) − 1) – динамический диапазон пикселей; 𝑘1 = 0.01 и 𝑘2 = 0.003 – константы. За основу модели синтезатора была взята архитектура нейронной сети Sova-TTS. В ходе обучения системы синтеза речи (TTS) методом обратного распространения ошибки был применен алгоритм Ranger для оптимизации функции потерь. В результате обучения нейронной сети были получены графики изменения значения функции потерь на тренировочной и валидационной выборках, представленные на рисунке 8. Из графиков видно, что при увеличении количества итераций уменьшается функция потерь. Валидационная выборка, не участвующая в процессе обучения, позволяет более репрезентативно и точно оценить качество системы. Эмпирически было установлено, что качество звука также повышается с увеличением числа итераций обучения.
На каждом этапе валидации сохранялась пара из оригинальной и синтезированной мел-спектрограмм, на основе которых генерировалось аудио с помощью вокодера.
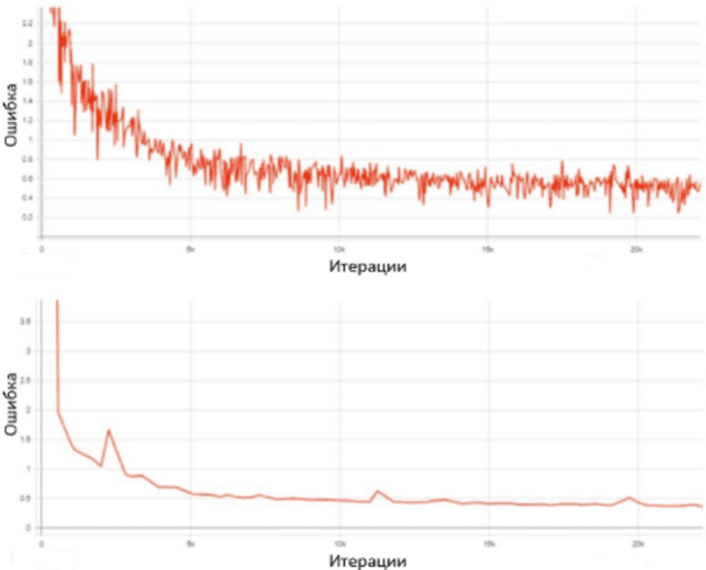
Рис. 5. График обучения нейронной сети на тренировочной (сверху) и на валидационной выборках (снизу)
Обучение вокодера. Для обучения в качестве источника данных были использованы несколько наборов: LJ Speech Data – набор данных состоит из 13 100 аудиофрагментов, записанных одним диктором. Он предоставляет разнообразные речевые сегменты для обучения TTS системы. Common Voice Corpus 6.1 – содержащий большой объем аудиоданных, собранных от добровольцев. Он включает в себя разнообразные голоса и акценты, что помогает улучшить обобщающую способность TTS модели. А также аудиокниги, что позволяет включить в обучающий набор разнообразные тексты и стили речи. В качестве функции потерь для обучения вокодера использовалась функция, представленная в формуле (12).
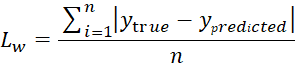 (12)
(12)
где 𝑦𝑡𝑟𝑢𝑒 – это мел-спектрограмма аудио, которое подается на вход, представленная в формате массива весов, которые относятся к признакам аудио; 𝑦𝑝𝑟𝑒𝑑𝑖𝑐𝑡𝑒𝑑 – это мел-спектрограмма синтезированного аудио, так же представленная в формате массива весов; 𝑛 – количество всех аудио.
Для оценки качества сгенерированной речи использовалась оценка Mean Opinion Score (MOS) – это усредненная оценка разборчивости речи. MOS оценивается по шкале от 1 до 5, где 5 означает, что сгенерированная речь имеет хорошее качество и почти или совсем неотличима от человеческой, а 1 ставится, когда речь имеет очень низкое качество и совсем не похожа на человеческую. Обучение происходило методом обратного распространения ошибки, а для оптимизации функции потерь был выбран оптимизатор Adam. График изменения значения функции потерь представлен на рисунке 6.
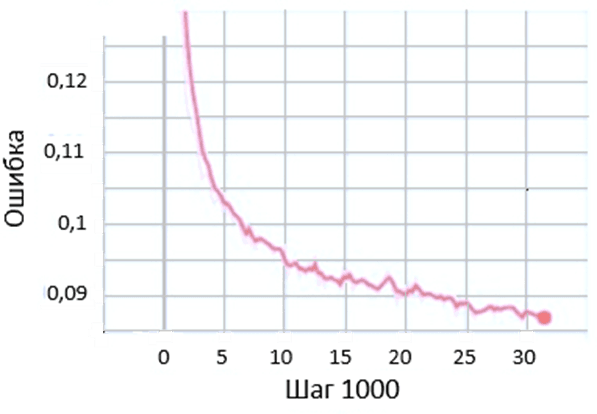
Рис. 6. График обучения нейронной сети
Результаты обучения нейронной сети WaveGrad были сравнены с результатами других нейросетевых вокодеров с помощью оценки Mean Opinion Score (MOS). Данные об оценках представлены в таблице. По результатам сравнения было выявлено, что использованный вокодер WaveGrad генерирует аудио, более приближенное к настоящему человеческому голосу.
Таблица
Вокодеры | MOS |
Оригинальное аудио | 4.45±0.04 |
WaveGrad | 4.43±0.07 |
WaveGlow | 4.13±0.247 |
WaveNet | 3.97±0.05 |
WaveRNN | 4.02±0.02 |
По данным из таблицы можно сделать вывод, что в ходе исследования были достигнуты результаты, превосходящие большинство аналогов в области синтеза речи на русском языке. Представлена система синтеза речи, объединяющую три нейронные сети: модифицированную модель Sova-TTS, энкодер для выделения просодии голоса и вокодер для синтеза аудио. Основной целью работы было обеспечение поддержки нескольких дикторов для синтеза речи. Приведенная архитектура позволяет генерировать аудио с уникальным голосом конкретного человека, с частичной передачей эмоциональности и просодии. Одним из главных преимуществ нашей системы является заменяемость отдельных модулей на более современные, при этом не требуется изменения общей архитектуры.
