
Обработка текстовой информации методами NLP (англ. natural language processing обработка естественного языка) вне зависимости от подходов и методов требует пересмотра взглядов на построение архитектуры аппаратного обеспечения. Это связано с тем, что классическая «фон Неймановская» и «Гарвардская» вычислительная архитектура не справляется с вычислительными нагрузками [1]. Даже создавая мультипроцессорные (многоядерные) универсальные процессоры, инженерам не удаётся достичь требуемого уровня производительности. Прежде всего, это связанно с ограничениями по доступу к памяти и методам её буферизации, а также по скорости обмена информацией между процессорами. Попытки создания сверхбольших кристаллов с гигантским количеством универсальных процессоров (ядер) сталкиваются с технологическими проблемами их производства, отвода тепла, сравнительно высоким энергопотреблением и относительно низкой скоростью обмена информацией между вычислительными ядрами. Специалисты по созданию больших интегральных микросхем отмечают, что самые большие проблемы при проектировании вызывает расположение и прокладка шин передачи данных. Универсальные вычислители обладают избыточной сложностью. Оптимизация вычислительного процесса проводится путём:
- увеличения скорости выполнения последовательности операций с использованием «конвейеров» и «предсказателей ветвлений», что повышало производительность однопоточных вычислений, но значительно усложняло архитектуру процессора общего назначения [1];
- увеличения разрядной сетки (адресуемого слова) процессора общего назначения, что позволяло увеличить адресное пространство оперативной памяти и скорость доступа к ней. Однако это влекло за собой усложнение информационных шин и увеличение их разрядности.
Основным достоинством больших (512 и даже 1024 бит (в интернете появлялись сообщения о процессорах с ещё большей разрядностью, но только в виде экспериментальных образцов)) регистров было повышение точности вычислений и меньшее накопление ошибок при массовых вычислениях, что было важно при моделировании погоды или физики ядерных процессов. Однако опыт показывает, что при обучении нейронных сетей, работающих в рамках NLP, вполне достаточно 16-битных FLOP (англ. FLoating-point OPerations per Second внесистемная единица, используемая для измерения производительности компьютеров, показывающая, сколько операций с плавающей запятой в секунду выполняет данная вычислительная система.) (операций с плавающей точкой) и даже 8-битных (integer целочисленных операций).
Для обработки различных графов знаний (семантических сетей) требуются быстрый поиск информации по полному или частичному совпадению, а также различные виды сортировки и упорядочивания информации. Несмотря на то, что к 2000 г. IT – индустрией были разработаны подходы для организации параллельных вычислений и создания для их работы спецвычислителей (в Советском Союзе значительные исследования и построение на их основе экспериментальных ЭВМ различных архитектур были проведены замечательными учеными Виктор Михайлович Глушков, Георгий Евсеевич Цейтлин, Екатерина Логвиновна Ющенко (1951-1964 гг.)), успех пришёл с несколько неожиданной стороны. Распространение и развитие среди специалистов по искусственному интеллекту (ИИ) получили различные графические процессоры (GPU), благодаря их относительно невысокой стоимости и доступности, также способности распараллеливать простые вычислительные операции.
Правда, программирование операций, не связанных с обработкой графической информации, было довольно затруднительно и требовало низкоуровневого программирования. В 2006 году компания Nvidia выпустила программно-аппаратный инструмент для программирования графических процессоров под названием CUDA, который позволил разработчикам легко программировать и использовать для этого высокоуровневые языки программирования. Графический процессор включает в себя тысячи относительно простых вычислительных ядер, работающих одновременно для визуализации каждого пикселя. Технология CUDA, на разработку которой компания Nvidia потратила несколько лет, упростила программирование графических процессоров на языках высокого уровня. Используя технологию CUDA, программисты могут разрабатывать модели глубокого обучения гораздо быстрее, дешевле и эффективнее. Основа архитектуры CUDA –масштабируемый массив потоковых мультипроцессоров (Streaming Multiprocessors). Данные мультипроцессоры способны обрабатывать параллельно сотни нитей. Для управления работой подобного массива потоков была разработана архитектура SIMT (Single-Instruction, Multiple-Thread), в которой реализуется подход к параллельным вычислениям, при котором несколько потоков выполняют одни и те же операции на разных данных. Бум развития ИИ и методов глубокого обучения нейросетей дал возможность компании Nvidia на основе разработанных ранее методов создать целое семейство различных ускорителей ИИ вычислений. Подробнее о достижениях в 2023-2024г.г. флагмана индустрии ИИ-ускорителей компании Nvidia мы рассмотрим ниже.
Исследование и разработка спецвычислителей диктуется требованиями рынка и ведётся в следующих пяти направлениях:
1. Создание ИИ-ускорителей для работы в огромных вычислительных кластерах, на которых проходит обучение больших языковых и мультимодальных моделей, имеющих сложную архитектуру с более чем 200 миллиардов параметров. Основное внимание при построении таких архитектур уделяется большому объему высокоскоростной памяти, расположенной непосредственно на платах ускорителей. На ускорителях средней мощности применяется память класса GDDR6X, а вот на более современных HBM2E и даже HBM3E общим объёмом до 192 Гбайт на ускоритель с пропускной способностью 8 Тбайт/с (информация на начало 2024 г. К 2025 г. планируется удвоить эти показатели). Одной из основных проблем при обучении нейросетей, особенно со сложной архитектурой, является скорость обмена информацией процессоров с оперативной памятью и между ускорителями ИИ даже в пределах одного сервера, а тем более между серверами. Эта проблема потребовала разработки новых интерфейсов и методов передачи информации. Так, фирма Eliyan представила технологию интерконнекта NuLink [2], предназначенного для соединения чиплетов (Чиплет (от английского chiplet) – микросхема, специально разработанная для совместной работы с другими себе подобными. Несколько чиплетов формируют одну более большую и сложную микросхему. Например, такую, как центральный или графический процессор). Данная технология рассматривается в качестве альтернативы упаковочным решениям TSMC CoWoS и Intel EMIB. При этом NuLink совместима с единым стандартом UCIe. Производительность NuLink, в четыре раза превышает показатели конкурирующих решений. В NuLink реализована функция одновременной двунаправленной передачи сигналов, что позволяет каждому соединению отправлять и получать данные одновременно. Это удваивает пропускную способность на линию по сравнению с традиционными решениями, которые обычно могут в каждый момент времени либо передавать, либо принимать информацию. Так, NuLink, реализованная на базе 3-нм техпроцесса TSMC, обеспечила лучшую в отрасли производительность – до 64 Гбит/с на канал. Внедрение NuLink может помочь в развитии аппаратных ИИ-платформ нового поколения. Помимо объединения чиплетов, эта система также позволяет связывать процессоры с модулями памяти.
Для организации обмена информацией между платами ускорителей как внутри одного сервера, так и между серверами может служить интерфейс NVLink (NVIDIA) пятого поколения [3], который обеспечивает пропускную способность до 1,8 Тбайт/с в обоих направлениях. С помощью данного интерфейса (коммутатор NVSwitch 7.2T) в одну связку можно объединить до 576 GPU. Если эти параметры кажутся чересчур огромными, то следует знать, что фирмы Microsoft и OpenAI планируют для задач ИИ проект дата-центра Stargate, стоимостью $100 млрд. Ожидается, что Microsoft возьмет на себя ответственность за финансирование Stargate [4].
2. ИИ-ускорители для создания (обучения) сравнительно небольших моделей, отработки каких-либо новых подходов в NLP. Либо когда метод переноса знаний (трансфертного обучения) применяется для тонкой настройки имеющихся больших языковых моделей при решении узкого круга задач. Как правило, это несколько ускорителей ИИ, расположенных в корпусе одного сервера или стойки. Такие системы используются также для предобученных моделей в закрытых организациях, не желающих эксплуатировать облачные вычисления с целью предотвращения утечек информации.
3. ИИ-ускорители, специализирующиеся на работе с заранее обученными моделями. Они оптимизированы именно для этих целей и обладают более простой архитектурой, что позволяет им справляться с довольно высокими нагрузками. Данные ускорители могут встраиваться уже в готовые микропроцессорные системы. Либо могут быть построены на основе ПЛИС (программируемых матриц (FPGA), ASIC, сигнальных процессорах DSP и т. д.).
4. Сравнительно маломощные универсальные ускорители для ПК планшетов и смартфонов. Так, например, компания INTEL в своих процессорах 15 поколения Core Ultra стали встраивать NPU – движок для ускорения задач, связанных с ИИ. По заявлению компании Intel, он является одним из трех «движков ИИ» в процессоре, другими являются GPU с высокой скоростью обработки данных и CPU. Процессор Core Ultra 7 165H (для ноутбуков) обеспечит при решении задач ИИ производительность до уровня 34 TOPS (триллионов операций в секунду) для CPU, GPU и NPU вместе взятых. Компания Intel утверждает, что производительность генеративного ИИ на новом чипе в 1,7 раза выше, чем у моделей прошлого поколения, энергоэффективность в вычислениях INT8 в UL Procyon Ai в 2,5 раза выше – также благодаря разгрузке NPU. Кроме того, компания Intel заявляет, что новые процессоры способны автономно запустить большую языковую модель LLama2 с семью миллиардами параметров. Массовый выпуск этих процессоров планируется на IV квартал 2024года.
Исследователи из Южной Кореи создали процессор, который обладает высоким быстродействием при минимальном энергопотреблении. Изделие предназначено для обработки больших языковых моделей (LLM). В работе приняли участие специалисты Корейского института передовых технологий (KAIST). Утверждается, что при обработке модели GPT-3 новинка по сравнению с ускорителем NVIDIA A100 затрачивает в 625 раз меньше энергии и занимает в 41 раз меньше физического пространства. Таким образом, южнокорейский ИИ-чип теоретически может применяться даже в смартфонах. Чип производится по 28-нм процессу Samsung Electronics. Технология, получившая название C-DNN (Complementary Deep Neural Network), позволяет использовать сверхточные нейронные сети (CNN) и импульсные нейронные сети (SNN).
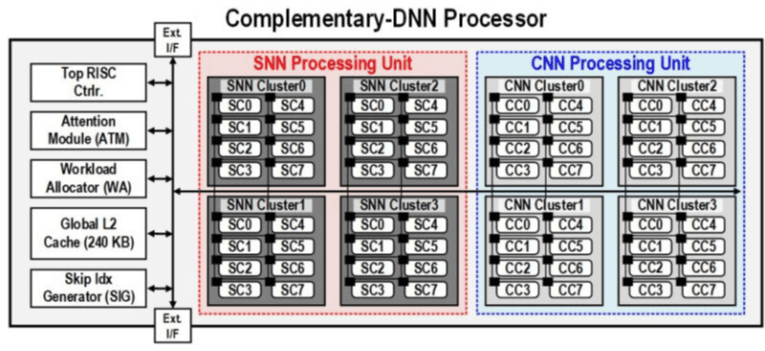
Рис. 1. Структура процессора C-DNN
5. Отдельно следует упомянуть большой класс ускорителей, построенных на нетрадиционных подходах: антропоморфные, нейроморфные и импульсные ускорители, построенные на принципах, отличающихся от традиционных нейросетей.
Нейроморфный процессор строится по принципу взаимодействия биологических нейронов, а не традиционной арифметики. Кодирование информации происходит за счет частоты импульсов. По состоянию на 2024 год среди исследователей ИИ нет согласия, является ли этот подход правильным путём для продвижения, но некоторые результаты являются многообещающими с продемонстрированной большой экономией энергии при решении задач машинного обучения.
Нейроморфный процессор «Алтай» является результатом совместной работы «Лаборатории Касперского» и компании «Мотив нейроморфные технологии» [5]. В целом ряде задач «Алтай» показал прекрасные результаты. Процессор имеет площадь в 64 мм², на которой смогли разместиться 256 нейронных ядер, в которых 131 072 нейрона. Все это дает 67 миллионов синапсов. «Алтай» изготавливается по 28-нанометровому технологическому процессу и потребляет всего 0,5 Вт электроэнергии. К сравнению флагманский процессор Intel Core i9-при стандартных нагрузках потребляет 125 Вт, то есть в 250 раз больше. Отечественная разработка способна обрабатывать 67 млрд действий в секунду.

Рис. 2. Модуль нейроморфного ускорителя с 8 прототипами НП «Алтай»
Таблица 1
Сравнение технических показателей нейроморфных ускорителей разных производителей по состоянию на 2023 г
Наименование технических показателей | «Алтай» | IBM TrueNorth | Intel Loichi | NVIDIA Jetson | Intel |
Технологический процесс | 28 нм | 28 нм | 14 нм | - | - |
Площадь кристалла | 64 мм² | 64 мм² | 60 мм² | - | - |
Количество нейронов на чип | 131 072 | 1 000 000 | 128 000 | - | - |
Количество синапсов на чип | 67 млн | 256 млн | 128 млн | - | - |
Энергопотребление | 0,5 Вт | 0,2 Вт | 0,37 Вт | 15 Вт | 0,65 Вт |
Производительность на задачах ТЗ, кадр/с | 1000 (до 2200) | 1738 | 296 | 779 | 11 |
Энергоэффективность мДж/кадр | 0,5 | 0,12 | 0,37 | 19,25 | 59,09 |
Нейроморфная архитектура | Да | Да | Да | Нет | Нет |
Масштабируемость | Неограниченная | Ограниченная | Нет | Нет | Нет |
Значительный интерес в развитии ускорителей ИИ представляют гибридные системы, где совместно используется дискретные и аналоговые вычисления.
Модуль такой гибридной системы представляет собой в общем случае прямоугольную матрицу ячеек-хранилищ электрического заряда, позволяющую напрямую смоделировать узлы, соединения и, самое главное, веса для взвешенного суммирования. Операции, производимые над этой матрицей (электрическими зарядами), представляют собой прямой аналог работы биологической нейронной сети. Используется не виртуальное моделирование биологического нейрона на программном уровне, а прямая физическая аналогия, что чрезвычайно важно. На рисунке 3 представлена PCIe-плата расширения Mythic MP10304 Quad-AMP с четырьмя аналоговыми матричными процессорами: потенциальная производительность на задачах ИИ – до 100 трлн. операций в секунду, энергопотребление – до 25 Вт.

Рис. 3. PCIe-плата расширения Mythic MP10304 Quad-AMP
Такая архитектура может реализовываться на различной элементной базе, включая магниторезистивную (MRAM) и резистивную (RRAM) память, а также память на основе эффекта фазового перехода (PCM) (Технология разрабатывается и продвигается компанией IBM) или флэш-память (NAND). Перечисленные технологии отработаны в промышленности, и их реализация не представляет сложности.
Основные вычислительные затраты при обучении нейросетей связаны с выполнением операции умножения на многомерных матрицах (тензорах) и сложении. Как это осуществляется в гибридных системах? Вектор входных данных задаётся набором уровней напряжения по каждому из входных каналов. Матрица же весов представляет собой электротехническую микроструктуру с соответствующим распределением сопротивлений по узлам-ячейкам. Вычисление происходит естественным образом, как и свойственно аналоговому компьютеру. В данном случае применяется закона Ома (сила тока равна напряжению, умноженному на сопротивление) для каждого из параметров, проходящих через матричную структуру резисторов. Суммирование взвешенных сигналов происходит в соответствии с правилами Кирхгофа для сложения токов в сложных цепях. Точности вычислений вполне достаточно для работы с NLP (как это упоминалось ранее).
Исследовательское подразделение компании Microsoft представило в 2023 г аналоговый оптический компьютер для решения практических задач. Базовый вычислительный модуль компьютера оперирует непрерывными (аналоговыми) данными в виде пучков света (рис. 4).
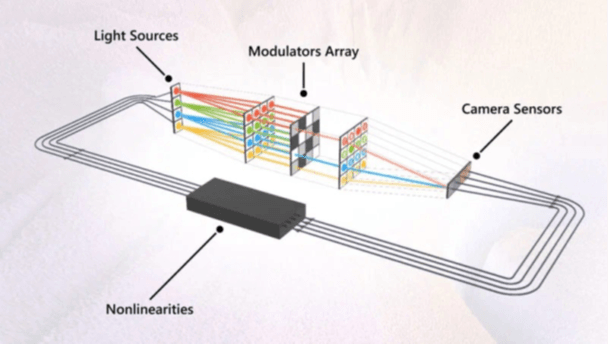
Рис. 4. Схема работы оптического модуля. Источник изображений: Microsoft
Представленный компанией аналоговый оптический компьютер не может считаться универсальной вычислительной платформой. Тем не менее его архитектура и алгоритмы могут быть задействованы в других сферах, если там присутствует обработка больших потоков данных с необходимостью выполнять множество векторно-матричных умножений или сложений. Оптический блок или аналоговое ядро установки выполняет только такие операции, но делает это молниеносно и без промежуточного перевода данных в цифровой (дискретный) вид.
Полностью оптический фреймворк глубокого обучения Diffractive Deep Neural Network (DNN) физически сформирован из множества отражающих или прозрачных поверхностей. Эти поверхности работают сообща, выполняя произвольную функцию, усвоенную в результате обучения. В то время как получение результата и прогнозирование в физической сети организованы полностью оптически, обучающая часть с проектированием структуры отражающих поверхностей рассчитывается на компьютере [6].
Графы знаний (семантических сетей) с нашей точки зрения являются наиболее перспективным направлением развития методов NLP. Для обработки различных графов знаний целесообразны архитектуры, совершенно отличные от представленных выше. На первое место выступают задачи быстрого поиска фильтрации и упорядочивания информации. В Московском государственном техническом университете (МГТУ) им. Н.Э.Баумана созданы первые в мире микропроцессор и суперкомпьютер, в которых на аппаратном уровне реализован набор команд дискретной математики DISC (Discrete Mathematics Instruction Set). Вычислительный комплекс получил название «Тераграф» [7]: он предназначен для хранения и обработки графов сверхбольшой размерности. В основу комплекса положен уникальный микропроцессор «Леонард Эйлер» (Leonhard), который содержит 24 специализированных гетерогенных ядра DISC Lnh64. Чип берёт на себя ту часть вычислительной нагрузки, с которой плохо справляются традиционные процессоры или ускорители. Для создания модулей «Леонард Эйлер» использовали ПЛИСы (Программируемые логические интегральные схемы), от AMD, на которые были записаны архитектура и инструкции. Отмечается, что «Леонард Эйлер» занимает в 200 раз меньше ресурсов кристалла, чем один микропроцессор семейства Intel Xeon. Энергопотребление при этом меньше на порядок. Тактовая частота решения составляет около 200 МГц. Благодаря параллелизму при обработке сложных моделей данных процессор способен обрабатывать до 120 млн вершин графов в секунду. Что касается системы «Тераграф», то она может работать с графами сверхбольшой размерности – до одного триллиона вершин.
Тем не менее флагманом промышленного производства ИИ-ускорителей остаётся компания NVIDIA. В рамках конференции GTC 2024 представила ИИ-ускорители следующего поколения на графических процессорах с архитектурой Blackwell [7]. По словам производителя, грядущие ИИ-ускорители позволят создавать ещё более крупные нейросети, в том числе работать с большими языковыми моделями (LLM) с триллионами параметров, и при этом будут до 25 раз энергоэффективнее и экономичнее в сравнении с Hopper. Графический процессор Nvidia B200 производитель без лишней скромности называет самым мощным чипом в мире. В вычислениях FP4 и FP8 новый GPU обеспечивает производительность до 20 и 10 Пфлопс соответственно. Новый GPU состоит из двух кристаллов, которые произведены по специальной версии 4-нм техпроцесса TSMC 4NP и объединены 2,5D-упаковкой CoWoS-L. Это первый GPU компании Nvidia с чиплетной компоновкой. Чипы соединены шиной NV-HBI с пропускной способностью 10 Тбайт/с и работают как единый GPU. Всего новинка насчитывает 208 млрд транзисторов. Флагманским ускорителем на новой архитектуре станет Nvidia Grace Blackwell Superchip, в котором сочетается пара графических процессоров B200 и центральный Arm-процессор Nvidia Grace с 72 ядрами Neoverse V2. Данный ускоритель шириной в половину серверной стойки обладает TDP до 2,7 кВт. Производительность в операциях FP4 достигает 40 Пфлопс, тогда как в операциях FP8/FP6/INT8 новый GB200 способен обеспечить 10 Пфлопс. Как отмечает компания Nvidia, новинка обеспечивает 30-кратный прирост производительности по сравнению с Nvidia H100 для рабочих нагрузок, связанных с большими языковыми моделями.
В 2022 году основной производитель видеокарт GPU, ускорителей ИИ и библиотек по их использованию (компания NVIDIA) приостановил продажи видеокарт в Россию. В 2023-2024 гг. отечественные компании не могут легально купить продукцию NVIDIA. Даже если получится приобрести видеокарту по «параллельному» импорту, в случае поломки владелец не получит техподдержки.
Исследования по развитию архитектуры и методов создания ускорителей ИИ ведутся в разных направлениях и чрезвычайно интенсивно. К сожалению, невозможно осветить все существующие направления исследований в этой области, поскольку только в 2022-2023 гг. данной тематике было посвящено более 5000 статей в научной литературе. Вместе с тем данный обзор может послужить хорошим ориентиром для отечественных компаний, использующих перспективные технологии обработки текстовой информации методами NLP.
