
Актуальность исследования
В эпоху активного роста объёмов и разнообразия данных задачи классификации становятся ключевыми в аналитике, особенно в областях медицины, финансов, маркетинга и многих других. Среди множества алгоритмов наибольшей популярностью пользуются логистическая регрессия, Random Forest и XGBoost. Логистическая регрессия ценится за простую интерпретацию и математическую строгость. Random Forest признан как устойчивый к шуму и склонный к менее выраженному переобучению благодаря механизму bootstrap‑ансамблирования. XGBoost предлагает передовые возможности: встроенная регуляризация, высокая точность на структурированных данных и эффективность при работе с несбалансированными выборками.
Однако, несмотря на широкое применение, отсутствует глубокое теоретическое сравнение этих моделей, позволяющее чётко понять их преимущества и ограничения в зависимости от характеристик задачи (линейность зависимости, объём данных, требования к интерпретируемости и др.). Именно это препятствует обоснованному выбору модели в условиях академических и прикладных исследований.
Цель исследования
Целью данного исследования является всесторонний теоретический анализ и сравнение трёх алгоритмов классификации (логистической регрессии, Random Forest и XGBoost).
Материалы и методы исследования
В исследовании использованы открытые источники, включая научные публикации, документацию библиотек машинного обучения, а также результаты прикладных и академических проектов. Проведён теоретический анализ алгоритмов логистической регрессии, Random Forest и XGBoost по ключевым критериям: тип модели, интерпретируемость, устойчивость к переобучению, вычислительная сложность, работа с пропущенными значениями, обработка категориальных данных и поддержка несбалансированных классов.
Результаты исследования
Логистическая регрессия – фундаментальная линейная модель для классификации, преобразующая входящую линейную комбинацию признаков через сигмоидную функцию, формируя оценку вероятности принадлежности класса.
На рисунке 1 видно S‑образную кривую, ограничивающую значения между 0 и 1. Основная мотивация – использовать функцию логитов, приводящую лог-отношение шансов к линейной модели, что позволяет применять методы максимального правдоподобия для оценки коэффициентов:
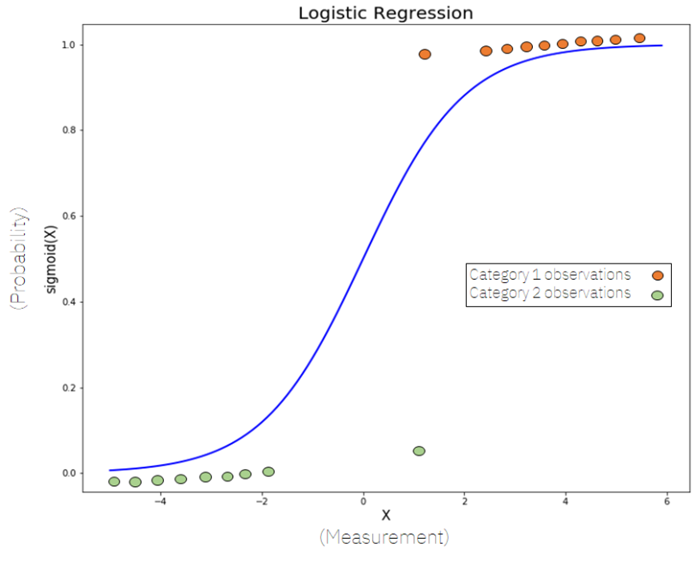
Рис. 1. Графическое представление логистической функции (сигмоиды)
Оценка коэффициентов осуществляется через максимально правдоподобную оценку, без замыкания на аналитическом решении, с использованием численных методов. Коэффициенты напрямую интерпретируются как изменение log-odds при единичном увеличении признака, что позволяет аналитически понимать вклад каждой переменной. Однако логистическая регрессия хорошо работает только при линейной разделимости и независимости признаков, и неустойчива при мультиколлинеарности.
Random Forest представляет собой ансамблевый метод, основанный на бутстреп-процедуре и случайном отборе подмножеств признаков и объектов для построения множества решающих деревьев. Каждый дерево обучается на случайной выборке с заменой, а финальное предсказание – усреднение или голосование большинства (рисунок 2).
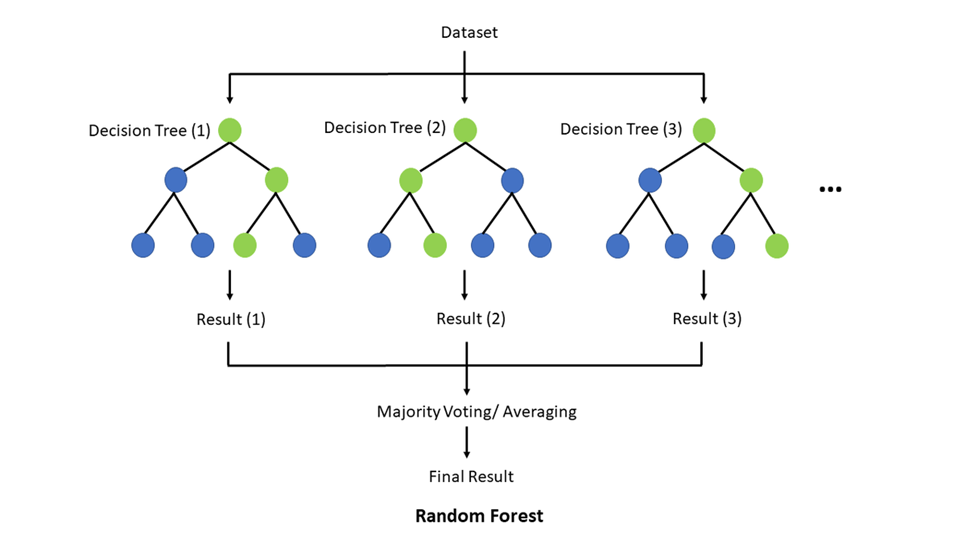
Рис. 2. Схематическое представление работы алгоритма Random Forest
Передовая техническая схема обеспечивает снижение дисперсии модели и устойчивость к шуму. Алгоритм не требует нормализации признаков и автоматически обрабатывает категориальные переменные. Основная проблема – высокая вычислительная сложность и объем потребляемой памяти, особенно при большом количестве деревьев. Random Forest устойчив к переобучению за счёт бутстрепа и усреднения. Теоретически доказана эффективность метода Bagging; выбор случайных признаков приводит к декорреляции ошибок деревьев, что улучшает обобщающую способность.
XGBoost – реализация градиентного бустинга, основанного на последовательном обучении слабых моделей (обычно деревьев), где каждая следующая модель исправляет ошибки предыдущей. Алгоритм включает сложную регуляризацию (L1/L2), усечение значимости признаков, поддержку пропущенных значений и оптимизацию жадным образом, что обеспечивает быструю работу и точность [2].
На рисунке 3 показана схема градиентного бустинга: каждый следующий модель корректирует остатки предыдущих. XGBoost зарекомендовал себя как наиболее точная модель на структурированных данных, превосходя Random Forest даже при балансированных наборах.
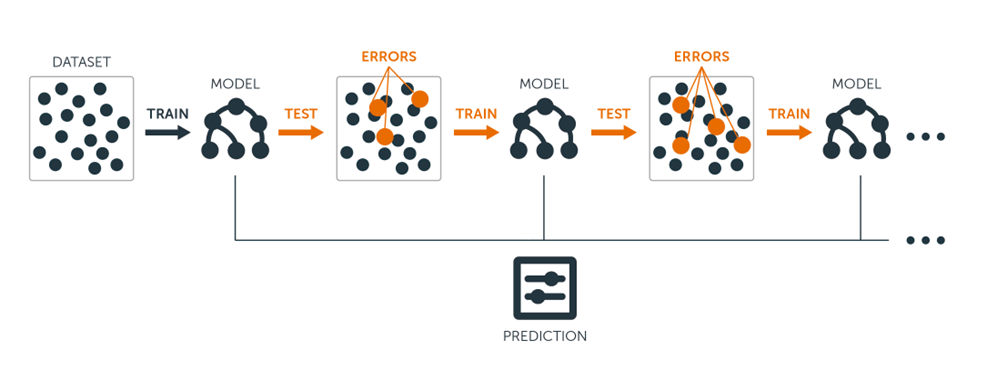
Рис. 3. Принцип работы алгоритма градиентного бустинга
Критерии теоретического сравнения моделей классификации позволяют формализовано оценивать эффективность, применимость и целесообразность использования каждого алгоритма в зависимости от условий конкретной задачи. Таблица 1 иллюстрирует ключевые различия.
Таблица 1
Сравнительный анализ логистической регрессии, Random Forest и XGBoost по теоретическим характеристикам
| Критерий | Логистическая регрессия | Random Forest | XGBoost |
|---|---|---|---|
| Тип модели | Линеарный, GLM | Ансамбль деревьев (Bagging) | Ансамбль деревьев (Boosting) |
| Интерпретируемость | Высокая | Средняя (feature importance) | Низкая, возможны SHAP/TreeExplainer |
| Устойчивость к шуму | Низкая | Высокая | Средняя – высокая с регуляризацией |
| Обработка признаков | Только числовые после масштабирования | Простая, масштабирование не требуется | Аналогично RF |
| Вычислительная сложность | Низкая | Высокая для множества деревьев | Очень высокая |
| Предотвращение переобучения | Регуляризация, лог-лосс | Бутстреп и усреднение | Регуляризация + бустинг |
| Полезность при несбалансированных данных | Средняя (нужна пере-/до‑sampling) | Хорошая | Отличная – weight, subsample |
Логистическая регрессия зарекомендовала себя как надёжный инструмент в медицине, социальной и экономической статистике благодаря прозрачности модели и статистически обоснованному интерпретируемому выводу. Используется для предсказания вероятности развития заболеваний (диабет, болезни сердца), оценки риска летального исхода (TRISS, шкалы травматических повреждений) и анализа клинических данных. Методы её применения детально описаны в руководящих публикациях и стандартах (PMC review). В образовании модель применяется для оценки вероятности успеха студентов, эффективности образовательных программ. В инженерии – для предсказания отказов систем или дефектов конструкций [1].
Random Forest является мощным инструментом в задачах с высокими размерностями и шумом. Он стабильно используется в задачах обработки медицинских данных (прогнозирование сепсиса), в экологических и геномных исследованиях, оборудованных большим количеством признаков и переменных. Благодаря способности обрабатывать несбалансированные классы и давать значимости признаков, используется в отборе переменных и биомедицинском анализе, как показано на рисунке облака важных признаков.
XGBoost, благодаря регуляризации и итеративному обучению, применяется в задачах с требованием максимальной точности, лидерству на соревнованиях и анализе структурированных данных. Он превосходит Random Forest в задачах с несбалансированными классами, значительно улучшая F1‑score, ROC‑AUC и MCC при помощи подходов типа SMOTE/ADASYN. В дистанционном зондировании и классификации спутниковых снимков XGBoost показал лучшие результаты по сравнению с RF. Также в работе оценивается схема XGBoost из архитектур графиков [4].
Сравнительный обзор областей применения моделей логистической регрессии, Random Forest и XGBoost представлен в таблице 2.
Таблица 2
Сравнительный обзор областей применения моделей логистической регрессии, Random Forest и XGBoost
| Сфера применения | Логистическая регрессия | Random Forest | XGBoost |
|---|---|---|---|
| Медицина | Оценка риска сердечно-сосудистых заболеваний, выживаемости, шкалы тяжести | Диагностика сепсиса, онкологических патологий, отбор значимых биомаркеров | Оценка вероятности осложнений, точная медицинская триажа |
| Социальные науки | Анализ выбора потребителей, социологические опросы, демографическое моделирование | Прогноз откликов на программы господдержки, анализ поведения респондентов | Моделирование голосований, предсказание эффективности социальных программ |
| Образование | Предсказание успеваемости, вероятность отчисления, эффективность курсов | Анализ образовательных траекторий с множеством переменных | Индивидуализация обучения на основе сложных структурных факторов |
| Финансовая аналитика | Скоринговые модели, вероятность дефолта | Выявление мошенничества, обнаружение аномалий | Модели кредитного риска с учётом коррелированных факторов |
| Экология и геоданные | – | Обработка спутниковых данных, анализ биоразнообразия, прогностическое моделирование | Классификация землепользования, детекция объектов на спутниковых снимках |
| Соревнования по ML (Kaggle) | – | Используется как baseline-модель | Наиболее частый победитель благодаря высокой точности и работе с несбалансированными данными |
| Инженерия и надёжность | Прогнозирование отказов оборудования, техобслуживание по состоянию | Детекция скрытых неисправностей, построение надёжных предикторов | Интеграция в системы мониторинга и технического зрения |
Выводы о сильных и слабых сторонах каждой модели:
1) Логистическая регрессия.
Сильные стороны:
- Высокая интерпретируемость модели: каждый коэффициент напрямую отражает вклад признака в логарифм шанса (log-odds).
- Низкая вычислительная нагрузка и быстрое обучение даже на больших наборах данных.
- Устойчивость к переобучению при наличии регуляризации (L1, L2).
- Применима к малым и средним выборкам.
- Теоретически строго обоснована, активно используется в медицинской, социологической и экономической статистике.
Слабые стороны:
- Неэффективна при наличии нелинейных зависимостей между признаками и целевой переменной.
- Чувствительна к мультиколлинеарности и требует предварительного анализа корреляции.
- Требует масштабирования признаков и обработки категориальных данных (one-hot encoding).
- Не поддерживает пропущенные значения и неустойчива к шуму в данных.
2) Random Forest.
Сильные стороны:
- Высокая точность классификации и устойчивость к переобучению за счёт бутстрепа и случайного отбора признаков.
- Хорошо работает на высокоразмерных и шумных наборах данных.
- Поддерживает пропуски и категориальные признаки без необходимости масштабирования.
- Предоставляет оценки важности признаков, что полезно для feature selection.
- Универсальность в задачах с разной природой данных (медицина, экология, финансы).
Слабые стороны:
- Средняя интерпретируемость: модель представляет собой «чёрный ящик» при большом числе деревьев.
- Более высокая вычислительная сложность по сравнению с логистической регрессией.
- Менее эффективен по сравнению с XGBoost на точно сбалансированных задачах с высокими требованиями к точности.
3) XGBoost.
Сильные стороны:
- Исключительно высокая точность за счёт последовательной коррекции ошибок (градиентный бустинг).
- Встроенные механизмы регуляризации (L1/L2), subsampling, контроль переобучения.
- Эффективная работа с несбалансированными классами и пропущенными значениями.
- Поддержка параллельных вычислений и оптимизация sparsity-aware.
- Фаворит на соревнованиях по машинному обучению (Kaggle, DrivenData и др.).
Слабые стороны:
- Низкая интерпретируемость (даже ниже, чем у Random Forest); требуется использование SHAP/LIME для объяснения.
- Высокая чувствительность к настройке гиперпараметров – требует кросс-валидации и тюнинга.
- Вычислительно затратен: сложность обучения выше, особенно на больших данных.
- Не оптимален при малом объёме данных (может переобучиться).
Практические рекомендации по выбору модели в зависимости от условий задачи представлены в таблице 3.
Таблица 3
Практические рекомендации по выбору модели в зависимости от условий задачи
| Условия задачи | Рекомендуемая модель | Обоснование выбора |
|---|---|---|
| Необходима прозрачность и интерпретируемость решений | Логистическая регрессия | Простая линейная модель, чётко показывает влияние признаков. Используется в медицине, праве, социологии |
| Малый объём выборки, линейные зависимости, высокая скорость | Логистическая регрессия | Эффективна при небольших данных, быстро обучается, требует минимальных вычислений |
| Признаки взаимосвязаны, есть шум, данные не отмасштабированы | Random Forest | Не требует нормализации, устойчив к шуму и мультиколлинеарности, умеет обрабатывать категориальные признаки |
| Пропуски в данных, переменные разной природы | Random Forest или XGBoost | Оба алгоритма могут корректно обрабатывать пропущенные значения и смешанные типы данных |
| Задача максимальной точности, соревнования, большие датасеты | XGBoost | Наиболее точный алгоритм при грамотной настройке параметров, лидирует в задачах с несбалансированными классами |
| Требуется борьба с переобучением на сложных данных | XGBoost | Встроенная регуляризация и бустинг по ошибкам повышают устойчивость к переобучению на сложных и многомерных выборках |
| Ограничены вычислительные ресурсы, важна простота реализации | Логистическая регрессия | Простая и быстрая в реализации модель, не требует сложной настройки |
| Требуется оценка важности признаков и отбор переменных | Random Forest | Позволяет формировать список feature importance без дополнительных метрик |
| В задаче наблюдаются сложные нелинейные зависимости и скрытые закономерности | XGBoost или Random Forest | Обе модели хорошо справляются с выявлением сложных взаимосвязей; XGBoost предпочтительнее при требовании высокой точности |
| Наличие категориальных признаков без предварительной обработки | Random Forest | Поддерживает работу с категориальными признаками напрямую, в отличие от логистической регрессии и XGBoost |
Выбор модели всегда должен быть обусловлен целями анализа, структурой данных, требованиями к интерпретации и доступными вычислительными ресурсами. Ни одна модель не является универсальной: каждая из них обладает своими уникальными преимуществами и ограничениями, и именно грамотный анализ условий задачи позволяет сделать эффективный выбор [3].
Выводы
Проведённое теоретическое сравнение показало, что логистическая регрессия, Random Forest и XGBoost обладают уникальными преимуществами и ограничениями, делающими их более или менее подходящими в зависимости от контекста задачи. Логистическая регрессия предпочтительна при необходимости высокой интерпретируемости, малом объёме данных и наличии линейной зависимости между признаками. Random Forest эффективно применяется при наличии шумных и высокоразмерных данных, а также при необходимости отбора признаков. XGBoost демонстрирует наивысшую точность в задачах с большой выборкой, несбалансированными классами и сложной структурой взаимосвязей, но требует тщательной настройки и значительных вычислительных ресурсов.
Выбор алгоритма классификации должен быть обусловлен спецификой данных, задачей анализа, требованиями к объяснимости и доступными техническими ресурсами. Универсального решения не существует: каждая модель представляет собой инструмент, оптимальный в строго определённых условиях.
