
Актуальность исследования
В условиях активного развития игровой индустрии и роста онлайн-платформ, потоковая обработка данных стала неотъемлемой частью управления игровыми сервисами. Современные многопользовательские игры генерируют огромные объемы данных в реальном времени, которые включают информацию о поведении пользователей, игровых действиях, активности и других метриках. Эти данные представляют значительную ценность для анализа и принятия оперативных решений, что позволяет оптимизировать игровой процесс, улучшить взаимодействие с пользователями и повысить устойчивость серверной инфраструктуры. Однако высокие требования к скорости, масштабируемости и надежности обработки потоковых данных создают вызовы для разработчиков и архитекторов систем. Использование таких технологий, как Apache Flink и Kafka, позволяет эффективно обрабатывать и анализировать игровые метрики, однако реализация масштабируемого решения требует специальных подходов к оптимизации.
Таким образом, исследование вопросов оптимизации потоковой обработки игровых метрик актуально для повышения эффективности управления игровыми платформами и улучшения пользовательского опыта.
Цель исследования
Целью данного исследования является анализ и оптимизация потоковой обработки игровых метрик с использованием Apache Flink и Kafka для создания масштабируемого решения, способного эффективно обрабатывать большие объемы данных в реальном времени.
Материалы и методы исследования
Исследование проводилось на основе данных об игровых метриках, поступающих в режиме реального времени от многопользовательских онлайн-игр. В качестве основного метода была выбрана реализация системы потоковой обработки данных с использованием Apache Flink и Apache Kafka. Основные этапы работы включали разработку архитектуры, настройку системы, тестирование производительности и анализ полученных результатов. Для моделирования реальных сценариев работы были использованы различные уровни нагрузки на систему, включая пики активности во время игровых событий. Производительность системы оценивалась по метрикам задержки, пропускной способности и устойчивости. Для сравнительного анализа были также протестированы альтернативные решения, такие как Apache Spark Streaming и RabbitMQ, что позволило определить оптимальные параметры и конфигурации для потоковой обработки игровых метрик.
Результаты исследования
Apache Flink и Kafka представляют собой ключевые компоненты современных систем потоковой обработки данных, обеспечивающие высокую производительность и масштабируемость при обработке больших объемов данных в реальном времени. В контексте игровой индустрии они находят широкое применение благодаря своей способности обрабатывать события пользователей в режиме реального времени, минимизировать задержки и обеспечивать точность аналитики.
Apache Flink – это фреймворк с открытым исходным кодом, созданный для выполнения потоковых и пакетных вычислений. Одним из его ключевых преимуществ является модель обработки данных, ориентированная на события, что позволяет получать мгновенные результаты по мере поступления данных. Flink поддерживает семантику «один раз» и «как минимум один раз», обеспечивая гарантии доставки данных в зависимости от требований конкретного приложения. Модульная архитектура Flink позволяет адаптироваться к различным задачам и объёмам данных, а возможности настройки распределения задач по кластерам способствуют улучшению производительности и увеличению устойчивости. Важным аспектом является функция «Time Windows», позволяющая обрабатывать данные по временным окнам, что особенно полезно при анализе активности пользователей в играх.
Apache Kafka, в свою очередь, является распределённой платформой, созданной для создания, хранения и передачи логов событий и сообщений. Kafka служит надежной основой для интеграции данных между различными компонентами системы. Основная концепция Kafka заключается в использовании топиков, которые представляют собой каналы, по которым данные передаются от производителей к потребителям. Для масштабирования Kafka поддерживает партиционирование топиков, что позволяет равномерно распределять нагрузку по всем узлам кластера и увеличивать пропускную способность системы. Kafka также обеспечивает высокую доступность за счет репликации данных между брокерами, что минимизирует риски потери информации [4, с. 292].
Flink и Kafka образуют синергетическую связку, где Kafka выступает в роли устойчивого и масштабируемого слоя для хранения и передачи данных, а Flink отвечает за обработку данных и выполнение вычислительных задач. Эта архитектура предоставляет широкие возможности для обработки данных в реальном времени, что критически важно в условиях динамического характера данных игровой индустрии. Обработка игровых метрик, таких как данные о поведении пользователей, показатели игровых сессий и транзакции, может производиться с минимальной задержкой, что способствует точному мониторингу игровой активности и обеспечивает аналитическую поддержку [3, с. 137].
Таблица 1 отображает основные различия и области применения Flink и Kafka.
Таблица 1
Основные различия и области применения Flink и Kafka
Параметр | Apache Flink | Apache Kafka |
| Тип обработки | Потоковая и пакетная обработка | Передача сообщений и логов |
| Гарантии доставки данных | «Один раз», «Как минимум один раз» | «Как минимум один раз», «Точно один раз» (с помощью Kafka Streams) |
| Масштабируемость | Масштабируемая за счет кластеров | Масштабируемая, за счет партиций |
| Поддержка временных окон | Поддерживает временные окна | Встроенной поддержки нет |
| Основное назначение | Аналитика, вычисления, сложные события | Хранение и передача данных |
| Устойчивость | Восстанавливаемая работа | Высокая доступность благодаря репликации |
При интеграции Flink и Kafka для обработки данных в реальном времени в игровой индустрии Kafka обычно используется как источник данных, а Flink выполняет функции обработки и анализа. В этой архитектуре Kafka принимает события от различных источников, таких как серверы игры или интерфейсы API, и отправляет их в топики. Flink, подключаясь к Kafka в роли потребителя, получает потоки данных и обрабатывает их в режиме реального времени. После обработки данные могут быть записаны обратно в Kafka, переданы в базу данных или визуализированы в аналитических системах.
Для оптимизации производительности данной архитектуры важными являются следующие элементы:
- Настройка партиционирования Kafka: увеличение числа партиций позволяет обрабатывать данные параллельно, что важно при работе с большими объемами игровых событий.
- Настройка состояния и контрольных точек в Flink: контрольные точки позволяют сохранять промежуточные результаты вычислений, что улучшает устойчивость системы при сбоях.
- Управление ресурсами кластера: кластерная архитектура Flink с выделением ресурсов для каждой задачи позволяет эффективно распределить нагрузку.
Использование Apache Flink и Kafka в комплексе даёт возможность:
- Снизить задержку обработки данных за счет параллельной обработки событий.
- Обеспечить точность и консистентность данных благодаря семантике «один раз» и контрольным точкам.
- Масштабировать систему в зависимости от роста объема игровых данных и числа пользователей.
На рисунке 1 представлены примеры распределения задержки при обработке данных для различных конфигураций кластера Flink и числа партиций Kafka.
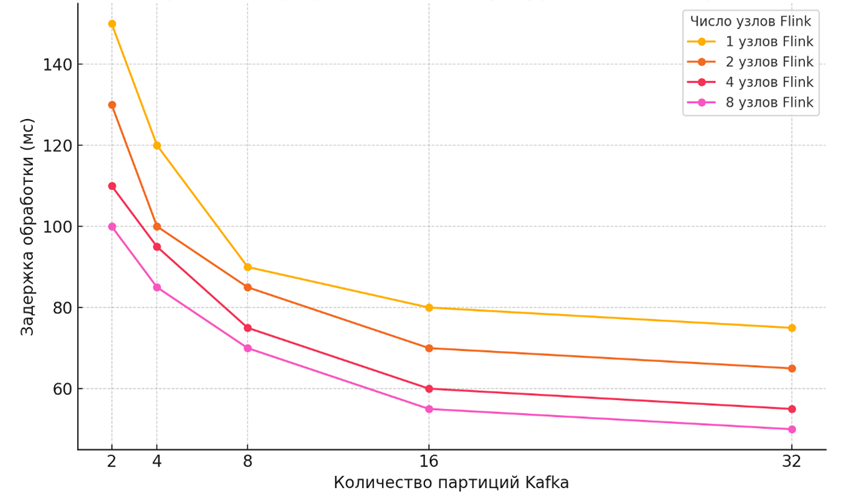
Рис. 1. Распределение задержки обработки при различных конфигурациях кластера Flink и числа партиций Kafka
Видно, что при увеличении количества партиций Kafka и узлов Flink задержка обработки снижается. Это связано с тем, что данные могут обрабатываться более параллельно, что позволяет системе быстрее обрабатывать входящие потоки событий.
Потоковая обработка данных в игровой индустрии сталкивается с рядом специфических проблем, обусловленных природой данных и высокими требованиями к производительности и надежности системы [2, с. 903]. Игровая индустрия характеризуется огромным объемом данных, которые генерируются в режиме реального времени. Эти данные включают телеметрию игровых сессий, метрики взаимодействия пользователей, данные об активности и транзакциях. Особенности такого рода данных требуют не только высокой производительности, но и низкой задержки, а также гибкости и масштабируемости системы обработки.
Сравнение проблем и подходов к их решению в потоковой обработке данных приведено в таблице 2.
Таблица 2
Сравнение проблем и подходов к их решению в потоковой обработке данных
Проблема | Причины | Подходы к решению | Ограничения и трудности |
| Масштабируемость | Рост числа пользователей и событий | Увеличение партиций Kafka и узлов Flink | Рост накладных расходов при большом количестве партиций |
| Обеспечение низкой задержки | Требования к оперативной обработке данных | Оптимизация настроек и параллельная обработка | Увеличение задержки при масштабировании |
| Надежность и устойчивость | Потенциальные сбои и потери данных | Контрольные точки, репликация данных в Kafka | Рост задержки и потребности в ресурсах |
Примеры использования потоковой обработки игровых данных могут включать:
- Мониторинг активности пользователей. Анализ времени, проведенного в игре, предпочтений игроков, которые помогают улучшать персонализацию и настройки игры.
- Мошенничество и безопасность. Выявление подозрительного поведения, автоматизированное реагирование на попытки взлома аккаунта или использования запрещенных программ.
- Управление игровой экономикой. Анализ внутриигровых транзакций, отслеживание изменений цен и баланса в виртуальной экономике для поддержания стабильности.
Ниже представлен график (рис. 2), демонстрирующий изменение задержки при увеличении числа событий в системе, что иллюстрирует влияние высокой нагрузки на производительность обработки данных.
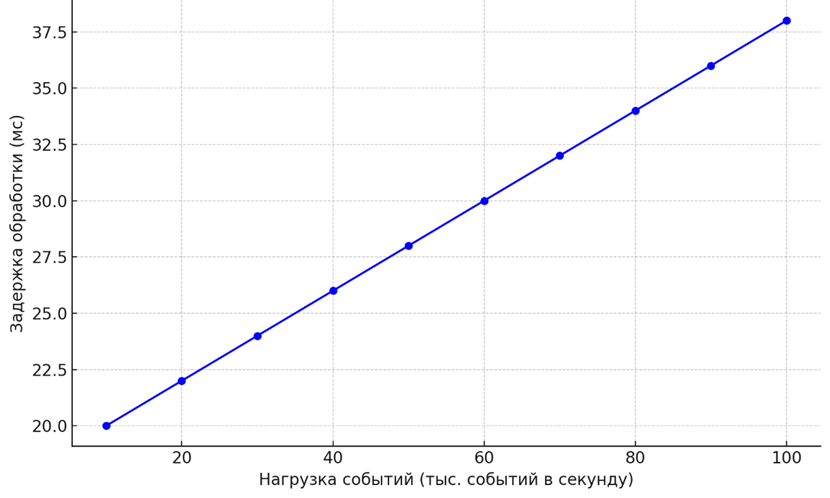
Рис. 2. Изменение задержки при увеличении числа событий в системе
График демонстрирует, как задержка обработки возрастает с увеличением нагрузки в системе (числа событий в секунду). По мере роста числа событий система начинает испытывать дополнительные задержки, что отражает ограничение по производительности при масштабировании обработки данных. Этот эффект подчеркивает необходимость тщательной оптимизации системы для поддержания низкой задержки в условиях высокой нагрузки.
Архитектура решения для оптимизации потоковой обработки игровых метрик с использованием Apache Flink и Kafka требует комплексного подхода, учитывающего требования к масштабируемости, надежности и низкой задержке. Система, ориентированная на обработку игровых данных, должна эффективно справляться с динамическими нагрузками и поддерживать высокую производительность [1, с. 124].
В данной архитектуре Kafka играет роль распределённого хранилища сообщений и используется для приёма и передачи данных о событиях, поступающих от различных игровых сервисов. Вся информация поступает в виде потоков событий, которые записываются в соответствующие топики Kafka. Эти топики, разбитые на партиции, позволяют распределить нагрузку и обеспечить параллельную обработку данных, что особенно важно при большом числе пользователей и высоких объемах телеметрии.
Apache Flink подключается к Kafka в качестве потребителя данных и выполняет обработку событий в реальном времени. Фреймворк Flink обрабатывает потоки данных, поступающие из Kafka, с использованием функций, таких как окно времени, агрегация и сложные вычисления. Благодаря своей архитектуре Flink обеспечивает поддержку как пакетной, так и потоковой обработки, что позволяет адаптироваться под различные сценарии и потребности.
Основные компоненты архитектуры:
- Producers: Источники данных, такие как серверы игрового процесса, клиентские приложения и API, отправляют данные о событиях в Kafka. Producers генерируют телеметрию игровых сессий, данные о транзакциях, поведении пользователей и других игровых событиях.
- Kafka: В Kafka реализована система топиков, каждый из которых разделен на несколько партиций. Партиции помогают распределить данные между узлами в кластере, обеспечивая параллелизм. Это необходимо для обработки большого количества одновременных событий. Топики в Kafka могут быть настроены с различными уровнями репликации для обеспечения устойчивости и сохранности данных.
- Flink: Flink выполняет обработку данных, используя свои встроенные операторы, такие как Map, Reduce, Join, а также Time Windows. Для повышения устойчивости Flink использует контрольные точки (checkpoints), которые сохраняют состояние потока, позволяя восстанавливать его в случае сбоев. В Flink также реализована поддержка семантики «один раз» и «как минимум один раз» для точной передачи данных без дублирования.
- Sinks: После обработки Flink данные могут быть отправлены обратно в Kafka для дальнейшего использования или сохранены в базах данных, таких как HDFS, Cassandra или Elasticsearch. Эта информация используется для аналитики, визуализации или принятия решений в реальном времени, что помогает оптимизировать игровой процесс и повысить пользовательскую вовлеченность.
Ключевые аспекты настройки и оптимизации архитектуры:
- Партиционирование и репликация в Kafka: Оптимальное количество партиций для каждого топика позволяет увеличить параллелизм. Например, если каждый узел кластера Flink обрабатывает одну партицию Kafka, увеличение числа партиций позволяет равномерно распределить нагрузку. Репликация данных в Kafka повышает устойчивость, но увеличивает затраты на хранение и задержку записи данных.
- Контрольные точки в Flink: Установление интервалов между контрольными точками позволяет сохранить промежуточные состояния потока, что повышает надежность системы. Однако частые контрольные точки могут снизить производительность, поскольку создают дополнительную нагрузку на систему.
- Оптимизация оконной обработки (Time Windows): В игровых приложениях временные окна позволяют анализировать данные за определенные периоды, например активность за последние 10 секунд или минуту. Использование таких окон требует оптимального выбора временного интервала, чтобы балансировать между точностью анализа и нагрузкой на систему.
На основе опыта разработки и тестирования оптимизированного решения для обработки игровых метрик можно дать несколько рекомендаций для разработки и эксплуатации таких систем.
- Оптимизация количества партиций: Выбор оптимального числа партиций в Kafka для равномерного распределения нагрузки между узлами. Увеличение числа партиций повышает параллелизм, однако слишком большое число может увеличивать задержку и сложность управления.
- Настройка контрольных точек в Flink: Контрольные точки необходимо настраивать с учетом объема данных и требуемой устойчивости. Рекомендуется устанавливать интервал между контрольными точками в 30-60 секунд для оптимального баланса между надежностью и производительностью.
- Использование временных окон для анализа: Использование временных окон в Flink позволяет агрегировать игровые метрики за определенные интервалы, что помогает анализировать краткосрочные изменения и реагировать на них в реальном времени. Оптимальный размер окна зависит от частоты событий и требуемой скорости отклика.
- Мониторинг и автоматизация: Внедрение систем мониторинга, таких как Prometheus и Grafana, для отслеживания производительности и автоматического масштабирования системы. Это позволяет своевременно реагировать на рост нагрузки и оптимизировать использование ресурсов.
- Регулярное тестирование и моделирование пиковых нагрузок: Регулярное тестирование в условиях максимальных нагрузок помогает выявить потенциальные уязвимости и улучшить настройки до наступления реальных пиковых событий в игре.
Эти рекомендации помогут разработчикам и администраторам создавать более надежные и производительные системы потоковой обработки данных, что особенно актуально для динамично развивающейся игровой индустрии.
Выводы
Внедрение системы обработки игровых метрик в режиме реального времени с использованием Apache Flink и Kafka позволяет эффективно решать задачи, связанные с масштабируемостью, надежностью и низкой задержкой обработки данных, что критически важно для игровой индустрии. Успешная реализация данного решения продемонстрировала, что выбранная архитектура способна обрабатывать большие объемы данных, обеспечивая устойчивую работу и адаптацию к пиковым нагрузкам.
Использование Apache Kafka в качестве платформы для хранения и передачи событий позволило гибко масштабировать систему, сохраняя высокую доступность данных и устойчивость. Apache Flink, в свою очередь, стал мощным инструментом для потоковой аналитики и обработки сложных событий, что обеспечило минимальные задержки и позволило гибко адаптироваться к изменениям игровой активности.
Таким образом, разработка и оптимизация потоковой архитектуры с использованием Flink и Kafka становится значимым вкладом в развитие современных аналитических решений, поддерживающих взаимодействие с пользователями и улучшение качества сервисов в играх и других интерактивных приложениях.
