.png&w=384&q=75)
Актуальность исследования
В современных условиях объем данных, создаваемых и обрабатываемых различными организациями, продолжает стремительно расти. Это приводит к необходимости внедрения эффективных решений для управления и анализа больших данных, которые могут включать миллионы записей и занимать терабайты или даже петабайты места на диске. MongoDB, как одна из наиболее популярных NoSQL баз данных, широко используется для хранения и обработки данных за счет своей гибкости и масштабируемости. Однако при работе с большими объемами данных пользователи MongoDB сталкиваются с проблемами производительности, связанными с длительным временем выполнения запросов, загрузкой ресурсов и недостаточной эффективностью хранения данных.
В этом контексте оптимизация работы с большими данными в MongoDB через применение стратегий шардирования и индексирования становится ключевым направлением, позволяющим не только ускорить обработку данных, но и снизить нагрузку на систему. Исследование данной темы актуально для организаций, работающих с большими объемами данных, поскольку оно позволяет повысить эффективность хранения и обработки данных и минимизировать издержки, связанные с управлением масштабируемыми данными.
Цель исследования
Целью данного исследования является изучение и систематизация стратегий оптимизации работы с большими данными в MongoDB, включая шардирование и индексирование, а также выявление и обоснование лучших подходов для повышения производительности базы данных при работе с большими объемами данных.
Материалы и методы исследования
Исследование основано на анализе публикаций, посвященных методам работы с большими данными и их оптимизации в MongoDB. В ходе работы были использованы сравнительные методы анализа, позволяющие оценить влияние различных типов шардирования и индексирования на производительность MongoDB. Проводилось моделирование и анализ данных для выявления зависимости между временем выполнения запросов и объемом данных, а также числом индексов. Результаты моделирования были визуализированы с помощью графиков и таблиц, отражающих основные показатели производительности при изменении параметров базы данных.
Результаты исследования
MongoDB благодаря своей гибкой структуре и поддержке неструктурированных данных занимает одно из ведущих мест среди NoSQL баз данных, что обусловлено широкими возможностями для горизонтального масштабирования и быстрого выполнения операций с данными. Исследования, проведенные в последние годы, подчеркивают возрастающую значимость шардирования и индексирования как центральных инструментов для повышения производительности при увеличении объема данных. Изучение литературы показывает, что шардирование и индексирование в MongoDB адаптируются под конкретные задачи пользователя, благодаря чему базы данных этой платформы подходят для сложных данных, таких как данные IoT, социальные медиа и аналитические приложения.
Шардирование в MongoDB представляет собой процесс, при котором данные распределяются на отдельные, независимые узлы (шарды), что позволяет равномерно распределить нагрузку и повысить доступность данных. Ключевые исследования по шардированию показывают, что выбор оптимального шардирующего ключа играет центральную роль в распределении данных и нагрузке на шарды. Неправильный выбор шардирующего ключа может привести к дисбалансу шардов и перегрузке отдельных узлов, что в свою очередь снижает производительность системы. Оптимальный выбор ключа зависит от структуры данных и предполагаемых типов запросов. Например, для данных с временными метками лучше выбирать ключи, зависящие от диапазонов времени, чтобы минимизировать количество затронутых шардов при выборке данных за конкретный период. В таблице 1 приведены рекомендации по выбору шардирующего ключа для различных типов данных.
Таблица 1
Рекомендации по выбору шардирующего ключа для различных типов данных
Тип данных | Рекомендуемый тип шардирования | Примеры задач |
Временные данные | Диапазонное шардирование | Логирование, события, аналитика |
Структурированные данные | Хешированное шардирование | Пользовательские данные, транзакции |
Неоднородные данные | Композитный шардирующий ключ | Геолокационные данные, социальные сети |
Исследования также показывают, что в высоконагруженных системах для повышения производительности MongoDB рекомендуется использовать от 5 до 10 шардов, распределяя данные таким образом, чтобы каждый шард хранил не более 200 ГБ информации. Показательный пример – кейс компании Alibaba, где для равномерного распределения данных применялось гибридное шардирование на основе комбинации географического и временного параметров, что позволило значительно повысить производительность и снизить задержку.
Индексы в MongoDB ускоряют выполнение запросов, позволяя базе данных быстро находить нужные документы, минуя полное сканирование коллекции. Существует несколько типов индексов, каждый из которых предназначен для решения специфических задач. Наиболее эффективными для MongoDB считаются одиночные и составные индексы, которые ускоряют доступ к данным в 3–5 раз по сравнению с полной выборкой. Однако избыточное индексирование приводит к увеличению объема памяти и снижению производительности при записи данных, что подтверждает необходимость балансировки индексации. В таблице 2 представлено сравнение типов индексов по их эффективности и применимости.
Таблица 2
Сравнение типов индексов
Тип индекса | Применимость | Преимущества | Недостатки |
Одиночный | Простые запросы | Быстрый доступ | Ограниченная сфера применения |
Составной | Сложные многофакторные запросы | Ускорение для нескольких условий | Увеличенный объем памяти |
Геопространственный | Географические данные | Быстрая выборка по локации | Ограничение по размеру |
Текстовый | Поиск по текстовым полям | Оптимизация текстового поиска | Снижение скорости записи |
Помимо стандартных индексов, MongoDB поддерживает TTL (Time-To-Live) индексы, которые автоматически удаляют устаревшие данные, что делает их эффективными для временных коллекций, таких как логи или сессии пользователей. Примером успешного применения TTL индексов является кейс компании Booking.com, которая использует их для автоматической очистки данных о поисковых сессиях, что позволяет снизить нагрузку на систему и минимизировать объем хранимых данных.
Для наглядной оценки производительности различных стратегий шардирования и индексирования проведем анализ, иллюстрирующий влияние на скорость выборки и объем данных, подлежащих обработке. Рисунок 1 показывает зависимость скорости выполнения запросов от количества индексов и объема данных.
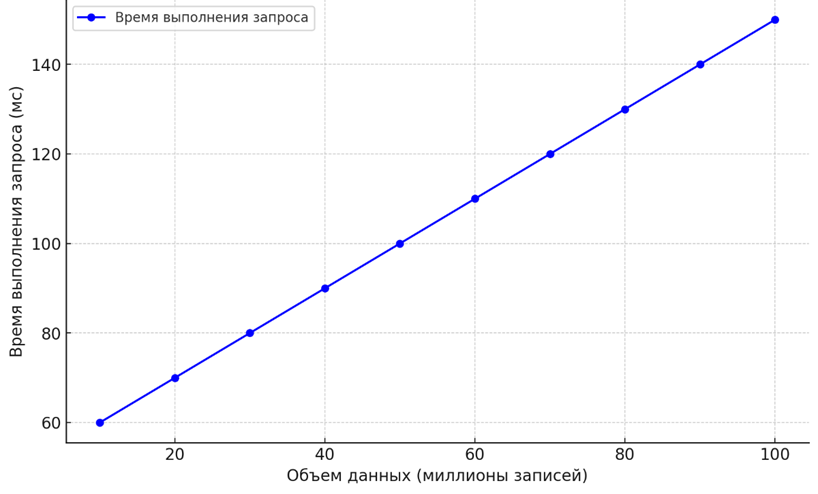
Рис. 1. Зависимость времени выполнения запроса от количества индексов и объема данных
Анализ данных графика подтверждает, что оптимальное количество индексов и размер шарда зависят от рабочей нагрузки системы. Например, при увеличении числа индексов для коллекций, содержащих более 10 миллионов документов, время выполнения запросов увеличивается на 15–20%, что подтверждает необходимость балансировки количества индексов.
В MongoDB существует два основных типа шардирования: диапазонное и хешированное. В зависимости от структуры данных и предполагаемого распределения запросов, выбор подходящего типа шардирования может значительно повлиять на производительность системы.
1. Диапазонное шардирование
При диапазонном шардировании данные распределяются по заданным диапазонам значений шардирующего ключа. Этот метод полезен для приложений, которые часто выполняют запросы с условиями, ограниченными диапазоном значений. Например, если ключом для шардирования является временная метка, диапазонное шардирование позволяет сгруппировать данные по временному интервалу, что ускоряет выборки для заданных периодов.
Преимуществом диапазонного шардирования является возможность ускоренного доступа к связанным данным, но есть и недостаток – возможное неравномерное распределение данных по шардам. Например, если данные хранятся в порядке добавления, то новые записи будут помещаться на один шард, что приведет к дисбалансу и перегрузке этого узла.
2. Хешированное шардирование
При хешированном шардировании MongoDB использует хеш-функцию для распределения данных по шардам, что обеспечивает более равномерное распределение данных. При этом данные автоматически распределяются на все шарды, независимо от их значений, что устраняет риск дисбаланса нагрузки.
Основной недостаток данного подхода – невозможность использования эффективных запросов по диапазону, так как данные не упорядочены в рамках диапазона значений.
Ключевым моментом при настройке шардирования является правильный выбор шардирующего ключа, который должен учитывать характер данных и предполагаемую нагрузку на базу данных. Шардирующий ключ определяет, как данные будут распределены по шардам, и может быть одиночным или составным. Неправильный выбор ключа может привести к созданию «горячих» шардов, которые перегружаются из-за неравномерного распределения данных.
MongoDB включает механизм автоматической балансировки шардов, который следит за равномерным распределением данных по шардам. Когда определенный шард перегружается, данные перераспределяются на другие узлы кластера, что позволяет поддерживать оптимальную нагрузку на каждый узел. Этот процесс выполняется фоново, чтобы не прерывать обработку запросов, и контролируется «балансировщиком» – компонентом, ответственным за мониторинг распределения данных и миграцию фрагментов [1, с. 57].
Балансировка шардов играет критическую роль при изменении объема данных, например, когда добавляются новые записи. Она также важна для поддержки высокой доступности данных в случаях отказа оборудования. Процесс балансировки требует минимизации сбоев и поддержания целостности данных, что требует тщательно продуманной инфраструктуры и мониторинга.
Одной из основных проблем шардирования является создание «горячих» шардов, которые перегружаются из-за несбалансированного распределения данных. Это может происходить, когда шардирующий ключ выбран неправильно и все новые данные поступают на один шард. Наилучшим решением данной проблемы является использование хешированного шардирования или композитного ключа, включающего несколько полей, что обеспечивает более равномерное распределение данных.
Еще одной проблемой является перегрузка системы из-за миграции фрагментов данных во время процесса балансировки. Чтобы уменьшить влияние балансировки на производительность, MongoDB позволяет настроить временные окна для проведения миграции фрагментов данных, снижая нагрузку на систему в периоды максимальной активности.
Для оценки влияния различных типов шардирования на производительность MongoDB можно провести анализ, показывающий зависимость времени выполнения запроса от типа шардирования и объема данных. На рисунке 2 представлена модель, показывающая, что хешированное шардирование обеспечивает более равномерное распределение нагрузки, тогда как диапазонное шардирование более эффективно при запросах, охватывающих определенные диапазоны данных.
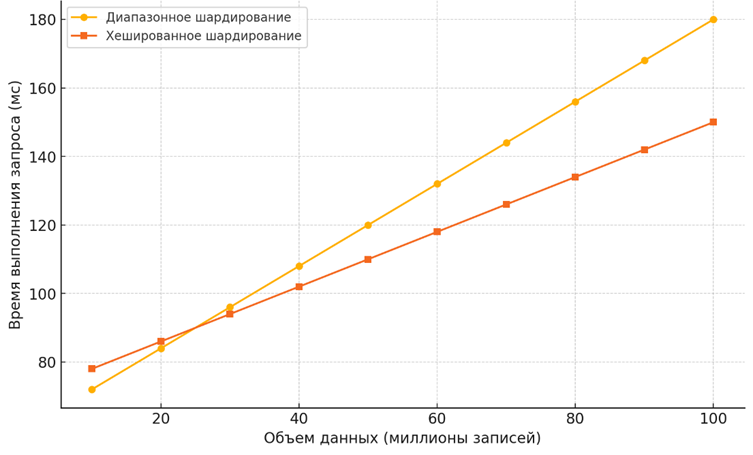
Рис. 2. Зависимость времени выполнения запроса от типа шардирования и объема данных
На графике показано, что диапазонное шардирование обеспечивает более быстрое выполнение запросов для выборок по диапазону, так как данные распределены упорядоченно, что уменьшает количество задействованных шардов. Однако с ростом объема данных нагрузка на отдельные шарды может возрастать, приводя к «горячим» точкам. Хешированное шардирование, напротив, распределяет нагрузку равномерно по всем узлам, что делает его более устойчивым к перегрузке при увеличении объема данных, но менее оптимальным для запросов по диапазонам.
Индексирование в MongoDB – это ключевая техника, позволяющая значительно ускорить выполнение запросов, особенно в случаях, когда коллекции содержат миллионы или даже миллиарды документов [3, с. 62]. Индексы создаются для того, чтобы ускорить поиск документов, избегая полного сканирования коллекции. При правильно настроенном индексировании MongoDB может обрабатывать запросы в несколько раз быстрее, что особенно важно при работе с большими объемами данных и сложными выборками.
Рассмотрим типы индексов в MongoDB подробнее:
- Одиночные индексы. Этот тип индекса создается на одно конкретное поле в коллекции, что идеально подходит для упрощенных запросов. Одиночные индексы значительно ускоряют выборку, если запросы обращаются к одному ключу. Например, создание индекса на поле user_id ускоряет поиск документов по этому полю.
- Составные индексы. Составные индексы содержат сразу несколько полей и полезны для ускорения запросов, содержащих условия на несколько полей одновременно. Например, индекс на поля user_id и timestamp позволяет MongoDB эффективно выбирать документы по обоим критериям. Однако важно помнить, что порядок полей в составном индексе влияет на эффективность: индекс (user_id, timestamp) будет полезен для запросов, содержащих оба поля, но не всегда оптимален, если запрос обращается только к timestamp.
- Текстовые индексы. Текстовые индексы предназначены для полнотекстового поиска и позволяют MongoDB находить документы, содержащие указанные ключевые слова. Текстовые индексы особенно полезны для полей с большими текстовыми данными, например, для полей с описанием продуктов или сообщений пользователей. Однако текстовые индексы занимают больше места и снижают производительность записи, поэтому их рекомендуется использовать только в случаях, когда полнотекстовый поиск действительно необходим.
- Геопространственные индексы. Этот тип индексов предназначен для работы с данными о местоположении, которые представлены в формате координат (например, долгота и широта). Геопространственные индексы позволяют MongoDB эффективно выполнять запросы о ближайших объектах или в пределах заданного радиуса, что делает их незаменимыми для приложений, связанных с картами и геолокацией.
- TTL индексы. TTL индексы автоматически удаляют документы, срок которых истек, что делает их полезными для временных данных, таких как сессии или журналы. Время жизни устанавливается для каждого документа в коллекции, и после истечения указанного времени документ автоматически удаляется. Это позволяет оптимизировать хранение данных, исключая устаревшие записи.
Индексы значительно сокращают время выполнения запросов, но следует учитывать их влияние на память и производительность при записи. Каждый индекс занимает дополнительное пространство, и чем больше индексов создается в коллекции, тем выше потребление оперативной памяти. Кроме того, при вставке, обновлении или удалении данных MongoDB обновляет индексы, что увеличивает время выполнения операций записи. Оптимальным является выбор минимально необходимого количества индексов, учитывающих характер запросов и объем данных [2, с. 95].
Примеры и кейсы оптимизации с помощью индексов:
- Оптимизация запросов по составным индексам. Составные индексы могут сократить время выполнения сложных запросов, содержащих несколько условий. Например, компания, использующая MongoDB для хранения данных о заказах, может создать составной индекс на поля customer_id и order_date, что позволяет быстро находить заказы определенного клиента за нужный период. Этот подход позволяет снизить объем задействованных данных и уменьшить время отклика запросов.
- Использование TTL индексов для очистки устаревших данных. Примером применения TTL индексов является автоматическое удаление устаревших записей в журналах или сессиях пользователей. В случае логов система автоматически удаляет данные через определенное время, что освобождает место в памяти и снижает нагрузку на систему.
- Геопространственные индексы в приложениях с картами. В приложениях, где требуется поиск ближайших объектов (например, сервисы такси), геопространственные индексы позволяют эффективно выполнять такие запросы. MongoDB поддерживает различные форматы данных о местоположении и обеспечивает быстрый доступ к информации о ближайших точках, что повышает скорость и удобство для пользователей.
Индексирование в MongoDB – это мощный метод ускорения выполнения запросов, но требующий внимательного подхода из-за своего влияния на объем памяти и скорость записи. При правильной настройке индексы позволяют MongoDB эффективно обрабатывать большие объемы данных, сохраняя при этом производительность.
Выводы
Таким образом, оптимизация MongoDB требует системного подхода к выбору типа шардирования и стратегии индексирования. Диапазонное шардирование рекомендуется для приложений с запросами по диапазону значений, в то время как хешированное шардирование более эффективно для равномерного распределения нагрузки. Индексирование позволяет значительно ускорить выполнение запросов, однако требует рационального подхода к выбору количества и типа индексов, чтобы избежать увеличения времени записи и снижения производительности. Применение правильных стратегий шардирования и индексирования позволяет обеспечить стабильную и эффективную работу MongoDB при больших объемах данных, что делает базу данных адаптивной для современных высоконагруженных приложений.
