.png&w=384&q=75)
Современные технологии человеко-машинного взаимодействия всё чаще требуют создания систем, способных воспроизводить не только речь, но и невербальные элементы коммуникации, такие как жестикуляция. Жесты играют ключевую роль в передаче эмоций, акцентов и смысловых нюансов, что особенно важно для виртуальных ассистентов, анимационных персонажей или социальных роботов. Однако автоматическая генерация естественных и контекстно-зависимых движений тела на основе текста остается сложной задачей.
Процесс сбора данных включал несколько этапов, объединенных в последовательный пайплайн.
На первом этапе исходные видеозаписи длительностью 7 часов были нарезаны в CapCut на фрагменты, фокусируясь на сценах с выраженной жестикуляцией, синхронизированной с речью; это позволило исключить паузы, фоновые движения и шумы, сохранив только релевантные для обучения данные.
Далее для каждого видеофрагмента с помощью Whisper выполнялась транскрипция аудио в текст с точными временными метками начала и конца каждой реплики, включая обработку пауз, интонаций и частичное распознавание эмоциональной окраски речи.
Параллельно через MediaPipe (модули Pose и Holistic) извлекались ключевые точки тела в формате 3D-координат: 8 точки скелета (только туловище и предплечье), 21 точка рук (суставы пальцев), что дало детальное представление о динамике движений.
Для синхронизации текстовых транскрипций и кинематических данных использовались временные метки из текстовых данных и данных MediaPipe.
Автоматизация обеспечивалась скриптом на Python, где цикл последовательно обрабатывал каждый видеофайл.
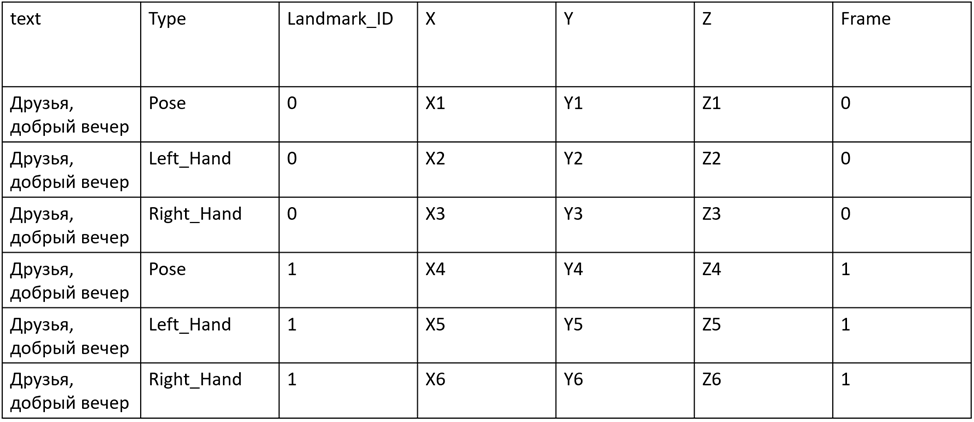
Рис. 1. Структура полученного датасета
На рисунке 1 изображена структура полученного датасета, в котором объединены текстовые и жестовые данные. Где text – текст, извлеченный из видео. Type – один из типов позы Media Pipe. Landmark_Id – id сустава, соответствующего своему типу позы. X, Y, Z – координаты точек суставов, Frame – номер кадра в анимации.
Архитектура нейронной сети для генерации жестикуляции имеет вид, представленный на рисунке 2.
Текст подается на вход в предобученную модель BERT, где он преобразуется в эмбеддинги и его размерность корректируется до 512D, для возможности его дальнейшей обработки с помощью механизма внимания.
С другой стороны, данные о жестах подаются в Frame Encoder, где они кодируются в скрытое пространство и их размерность так же приводится к 512D для тех же целей.
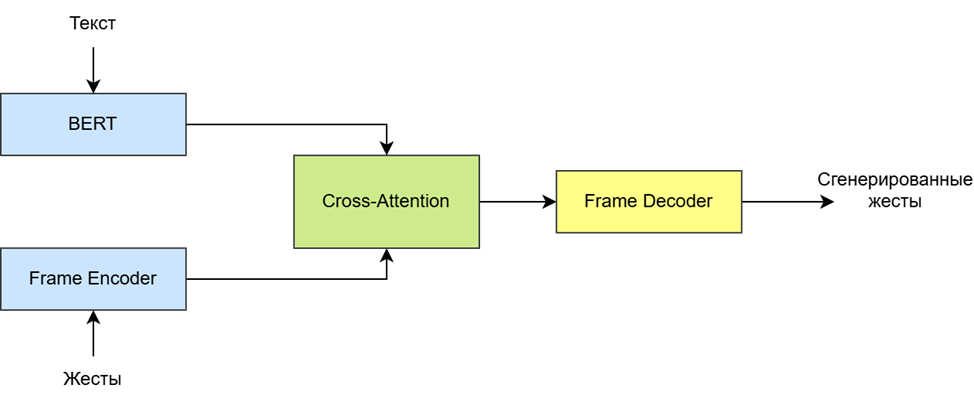
Рис. 2. Архитектура нейронной сети для генерации жестикуляции
Данные подаются в блок Cross-Attention, где между ними устанавливаются связи с помощью механизма внимания для того, чтобы модель могла лучше уловить и обучиться зависимости между текстовыми и жестовыми признаками.
После обработки данные попадают в Frame Decoder, где из них в обратном порядке получаются данные о жестах.
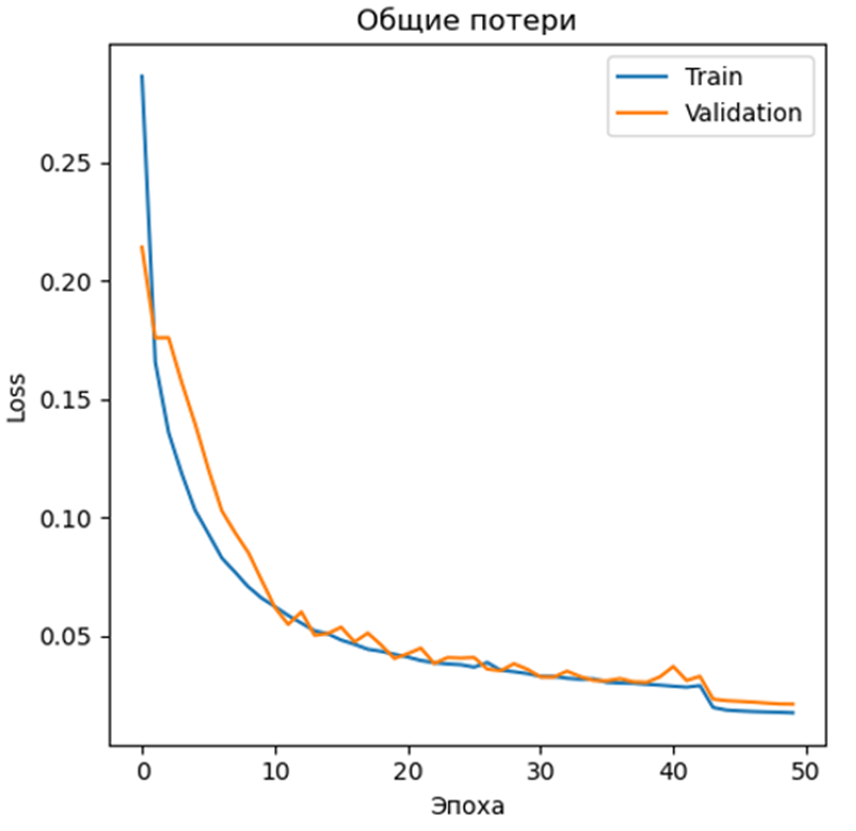
Рис. 3. Результаты обучения модели
На рисунке 3 представлены результаты обучения модели. Видно, что общие потери модели стабильно уменьшаются, что указывает на то, что модель обучается улавливать зависимости.
На рисунке 4 изображен график накопления ошибки MAE. Видно, что к 150 значение ошибки практически стабильно. На 150 и 200 кадрах наблюдаются скачки, что говорит о том, что модель хуже справляется с длинными жестами. После 250 кадра наблюдается резкий рост ошибки, что значит, что модель не справляется с генерацией жестов такой длины.
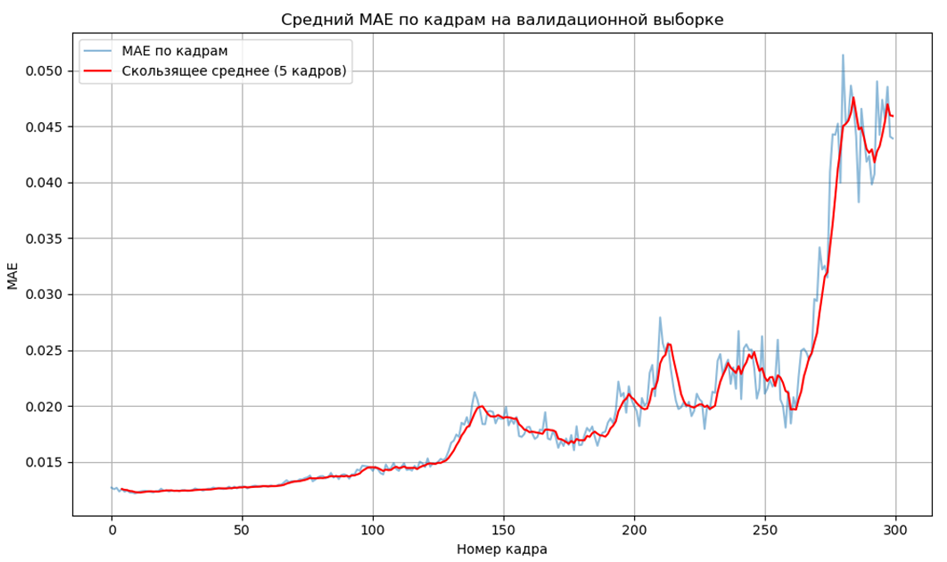
Рис. 4. Накопление ошибки MAE
