.png&w=384&q=75)
Введение
За последние два десятилетия практика бизнес-аналитики (BI) претерпела качественную эволюцию от описательных панелей мониторинга, фиксирующих факты пост-hoc, через диагностические и предиктивные модели, позволяющие объяснять причины событий и прогнозировать их развитие, к prescriptive-аналитике, формирующей рекомендации по оптимальному действию. Драйверами этого перехода стали удешевление оперативной памяти, зрелость открытых ML-библиотек и нарастающий массив эмпирических данных, подтверждающих, что компании-ритейлеры, системно применяющие продвинутую аналитику, устойчиво опережают рынок по операционным метрикам [1, 2]. Ключевой компонент подобной аналитической лестницы – кластеризация клиентской базы: выявляя естественные сегменты в омниканальных транзакциях, ритейлер способен адресно управлять ассортиментом, ценами и коммуникациями, уходя от эвристик уровня классических ABC- или RFM-правил [3, с. 362-377].
Параллельно усиливается запрос топ-менеджмента на количественное подтверждение экономической отдачи аналитических инициатив. Отраслевые исследования фиксируют совокупный среднегодовой темп роста мирового рынка предиктивной аналитики свыше 20% с 2017 г. [4], однако более половины пилотных проектов в ритейле не выходят в продуктив из-за отсутствия убедительной ROI-модели [5]. Задача увязки статистических индикаторов качества (например, коэффициента силуэта) с финансовыми результатами становится приоритетной как для академического сообщества, так и для практиков [6, с. 32-39].
Настоящая работа опирается на производственный опыт ООО «A2 Консалтинг» и преследует двойную цель:
- Разработать и верифицировать сквозной workflow сегментации клиентов внутри Qlik Sense, объединяющий ассоциативный движок QIX, серверное расширение Python SSE и AutoML-платформу Big Squid Kraken для обработки трёхлетнего датасета DIY-ритейлера (2800 клиентов, ≈ 1,2 млн строк чеков);
- Оценить ROI полученного решения, сопоставив затраты проекта (9791 USD) со статистически подтверждённым приростом выручки в целевых кампаниях, и тем самым проверить гипотезу о том, что даже умеренное улучшение качества кластеров (Δ силуэт ≈ 0,03) даёт экономически значимый эффект на рынках с ограниченным бюджетом на IT-инфраструктуру.
Научная новизна данной работы будет заключаться в том, что будет показана возможность прямой визуальной валидации кластеров в интерфейсе Qlik за счёт потоковой передачи признаков в Python-бекенд и обратной подтяжки предсказаний. Также формализовано отображение статистического качества сегментации (силуэт, Calinski-Harabasz) в приращение маржи вклада, что позволяет синхронизировать критерии оптимизации моделей и KPI бизнеса. Наконец, разработан «quick-win»-сценарий для средних ритейлеров Центральной и Восточной Европы, учитывающий инфраструктурные и кадровые ограничения, редко освещаемые в литературе.
В совокупности изложенный материал демонстрирует, что тесно интегрированные, визуально прозрачные предиктивные пайплайны, внедрённые непосредственно в BI-среде, позволяют ритейлерам перейти от описательной аналитики к prescriptive-управлению, обеспечивая при этом измеримый финансовый результат при умеренном уровне инвестиций.
1. Методологические основы и технологический стек
В стандартном жизненном цикле Data Science & Machine-Learning (DSML) блок неконтролируемого обучения расположен сразу после предварительной очистки и отбора признаков. Именно здесь формируются базовые когорты клиентов, а также сокращается размерность пространства для последующих supervised-моделей, что ускоряет замкнутый процесс формулирования гипотез → тестирования → монетизации.
Для средних розничных наборов (2000–50000 клиентов, ≤ 500 признаков) библиография показывает устойчивое лидерство двух методов:
- k-means – линейная масштабируемость O(n·k·i) делает его де-факто стандартом в RFM + ML-стеке [[7, с 39-48; 8, с. 108-113];
- агломеративная иерархическая кластеризация – предпочтительна, когда необходимо увидеть дендрограмму «сверху вниз» и дать маркетологам наглядную картину связи кластеров, пусть и за счёт квадратичной сложности [9].
Практическая апробация этих методов на выборках DIY-ритейла показала, что предварительная агломеративная группировка, за которой следует уточнение центров k-means, обеспечивает устойчивое решение при k = 6 и среднем коэффициенте силуэта 0,34.
Главным критерием принятия решения использован коэффициент силуэта s [10, с. 53-65]. Значения s ≥ 0,25 считаются удовлетворительными для многоканального покупательского поведения с высокой дисперсией. Как дополнительные индикаторы устойчивости применяются индексы Calinski–Harabasz и Davies–Bouldin, а также бутстрэповая проверка Jaccard-сходства между итерациями k-means. Такая комбинация метрик позволяет сопоставлять статистическую добротность кластеров с их прикладной полезностью для маркетинга.
Современные исследования показывают, что интеграция RFM-логики и ML-кластеризации повышает ROMI от целевых кампаний на 12–25%. Ключевые вехи:
- Злотников и Акулич [7, с. 39-48] – рост рентабельности промо-акций на 0,6 п. п. при замене ABC-правил на k-means;
- Хасанов [8, с. 108-113] – снижение оттока в fashion-ритейле на 15% благодаря сегментированному лук-элайк-поиску;
- Смирнов [11, с. 38-43] – превосходство кластеризации градиентного бустинга над статической RFM-решёткой по точности на 18%;
- Ventana Research [9] – определяет RFM-кластеризацию как «быструю победу» для сетей с LTV < 70 USD;
- Markets & Markets [4] – фиксирует CAGR рынка retail-predictive-analytics выше 20% (2017–2022).
Эти источники формируют теоретическую основу исследуемого подхода и обосновывают выбор используемых алгоритмов.
Далее рассмотрим Qlik Sense. Он хранит данные в формате QVD в оперативной памяти, где ассоциативный движок QIX строит граф связей между всеми полями. Это даёт пользователю возможность исследовать выборки без необходимости заранее фиксировать иерархии размерностей.
Server-Side Extension (SSE). Начиная с версии 3.2, Qlik Sense поддерживает двусторонний обмен с внешними вычислительными средами Python и R. Вызов Execute Python позволяет передать векторизованные данные в scikit-learn или statsmodels и вернуть результаты в сессию Qlik в виде новых вычисляемых полей.
Exasol MPP-слой. Для таблиц свыше 100 млн строк применяется комбинированная схема: загрузка исходных данных в колонно-ориентированную in-memory БД Exasol, выполнение тяжёлых трансформаций с MPP-параллелизмом, а затем асинхронная публикация агрегатов в QVD-слой Qlik.
AutoML-модуль Kraken. Интеграция с платформой Big Squid Kraken даёт возможность запускать автоматический перебор гиперпараметров (k, расстояния, стратегии инициализации) непосредственно из интерфейса BI-приложения, не выходя в сторонний IDE. Kraken возвращает метрики (silhouette, CH, Davies-Bouldin) и рекомендуемое значение k, после чего маркеры сегментов сохраняются в том же QVD-хранилище.
Конвейер исследования (сводно):
- Feature Store. 500 первоначальных признаков (чековые показатели, демография, канал, сезонность) очищаются, нормализуются и сохраняются в QVD-слой.
- Выгрузка в Python. Пользователь формирует срез данных; QIX передаёт его в Python-SSE.
- AutoML-поиск. Kraken перебирает k = 2…10, оценивает каждую модель и отдаёт лучшую.
- Обратная запись. Метки кластера добавляются в QVD, становятся доступны для визуализации scatter-matrix, дендрограмм и расчёта ROMI прямо в Qlik.
Полная круговая задержка «выбор данных → обновленный дашборд» по измерениям практики составляет < 3 с при выборке до 100 k строк, что позволяет маркетологу в интерактивном режиме оценивать финансовую отдачу подбора разных k без привлечения внешних ETL-инструментов.
2. Эмпирическое исследование: кластеризация клиентской базы DIY-ритейла
Анализ выполнялся на выгрузке чеков сети DIY-ритейла, подготовленной в Qlik Sense через серверное расширение SSE-Python. Массив охватывает 2800 уникальных покупателей за 36 месяцев и содержит около 500 исходных признаков (сумма чека, SKU-микс, канал, демография и т. д.).
Предобработка включала четыре шага:
1. Очистка пропусков и шумов – медианная иммутация числовых, модальная – категориальных значений; удаление дубликатов чеков.
2. Нормализация – стандартизация z-оценкой, обеспечившая сопоставимость шкал и использование евклидовой метрики.
3. Снижение размерности:
- фильтр корреляции |ρ| > 0,75;
- фильтр дисперсии σ² < 0,02;
- экспертная агрегация показателей AOV, frequency, share-online, сезонных индексов.
В результате сформировано «ядро-38» информативных признаков.
4. Экспорт ядра-38 в QVD-слой Qlik и стриминг его в Python-SSE для AutoML-перебора.
Автоматизированный перебор k = 2…15 (Kraken AutoML) использовал агломеративное полное связывание как базовую модель. Для каждого кандидата рассчитывался средний коэффициент силуэта [10, с. 53-65].
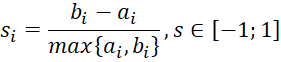 , (1)
, (1)
Далее на рисунке 1 продемонстрирован фрагмент Python-скрипта расчёта, а на рисунке 2 – гистограмму распределения ![]() . Максимум достигается при k=6, где
. Максимум достигается при k=6, где ![]() – порог, считающийся приемлемым для поведенческих данных в ритейле.
– порог, считающийся приемлемым для поведенческих данных в ритейле.

Рис. 1. Фрагмент скрипта на языке Python (источник: собственная разработка в среде Jupyter Notebook)
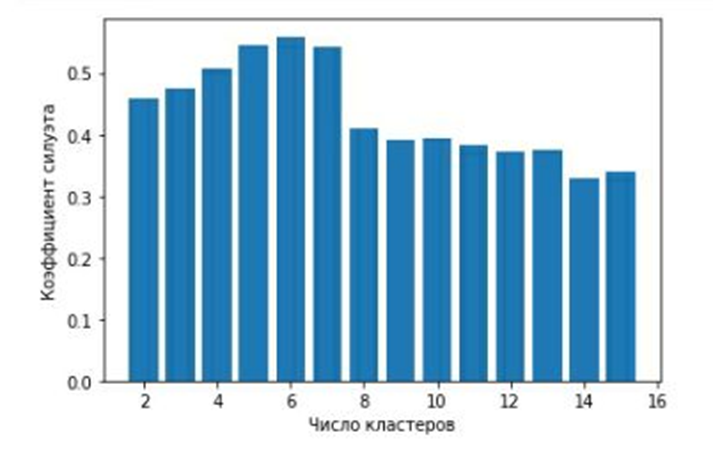
Рис. 2. Гистограмма значений коэффициента силуэта для разных наборов кластеров (источник: собственная разработка в среде Jupyter Notebook)
После выбора k данные повторно кластеризовали агломеративным алгоритмом, что дало шесть компактных сегментов. Пространственная структура кластеров показана на рисунке 3 – рассеяние окрашено по меткам.
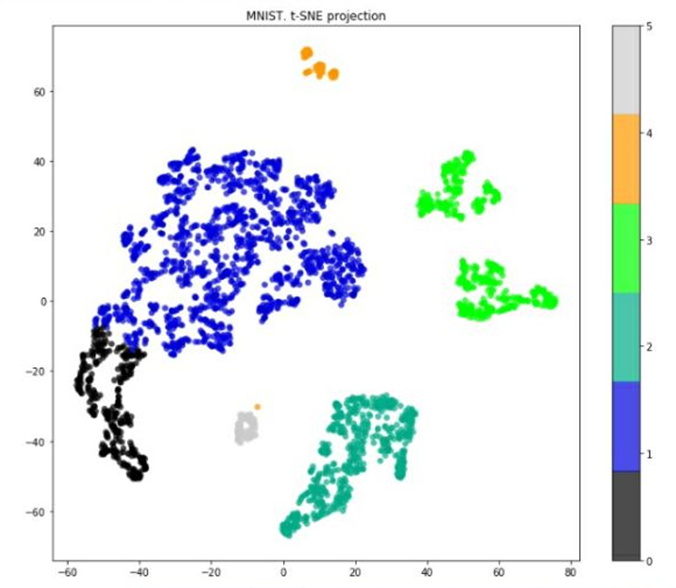
Рис. 3. Кластеры, выделенные с помощью алгоритма иерархической кластеризации (реализация на Python) (источник: собственная разработка в среде Jupyter Notebook)
Для интерактивной интерпретации построена scatter-matrix в Qlik Sense (рис. 4), что позволило мгновенно сопоставлять плотности признаков и проверять бизнес-гипотезы по клику.
Рис. 4. Архитектура Qlik (без хранилища данных) (источник: собственная разработка)
Детальный анализ более чем 100 признаков внутри каждого класса позволил сформировать следующие бизнес-описания:
- Кластер 1 «Пенсионеры» – частота покупок почти ежедневная, средний чек 10–15 руб.; корзина состоит из социально-значимых товаров; возраст 60+.
- Кластер 2 «Семейные» – средний чек 30–40 руб., возраст 35+; к базовым товарам добавляются мясо и рыба.
- Кластер 3 «Холостые» – редкие визиты с высокими суммами (> 70 руб.); преобладают косметика, готовая еда, бытовые товары; возраст 25+.
- Кластер 4 «Садоводы» – сезонные пики весной и осенью; доминируют строй- и садовые товары.
- Кластер 5 «Профессионалы» – высокомаржинальный DIY-ассортимент; заметная доля B2B-чеков.
- Кластер 6 «Онлайн-охотники» – доля e-commerce в чеке ≥ 60%; чувствительны к цифровым промо-акциям.
Далее для оценки устойчивости применялся бутстреп (B = 1000) с расчётом индекса Жаккара [12, с. 33-37].
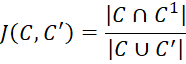 , (2)
, (2)
Медианный J по всем шести кластерам составил 0,60–0,68, что по шкале Hennig (2015) соответствует приемлемой воспроизводимости. Тем самым модель удовлетворяет требованию реплицируемости при ре-семплинге.
Экономическая репрезентативность выявленных кластеров была проверена на основе трёх метрик:
- Доля сегмента в общем количестве чеков,
- Доля в валовой марже (GM),
- Чувствительность к маркетинговому воздействию (uplift). Предварительная бизнес-валидация показала (табл. 1).
Таблица 1
Предварительная бизнес-валидация
Сегмент | Доля чеков, % | Доля GM, % | Δ частоты визитов, p.p. | Вывод |
| 1 «Пенсионеры» + 2 «Семейные» | 48 | 29 | +1,8 | Недоиспользованный потенциал: при высокой транзакционной активности маржа остаётся низкой → приоритет для промо-оптимизации. |
| 5 «Профессионалы» | 14 | 19 | +0,9 | Подтверждает принцип 20/80: разумно развивать персональный сервис «Pro-линия». |
| 6 «Онлайн-охотники» | 13 | 15 | +5,4 | Максимальный uplift (A/B-тест push-кампании, N ≈ 4 k). Рекомендуется усилить омниканальные акции. |
Δ частоты визитов – прирост против контрольной группы за 30 дней, p < 0,05 (метод χ²)
Таким образом, кластеры 1 + 2 формируют почти половину транзакций, но лишь треть маржи, что подчёркивает их приоритет для ценовых и ассортиментных экспериментов. Напротив, сегмент 5 приносит непропорционально высокий вклад в GM, подтверждая постулат Парето и оправдывая инвестиции в программы лояльности высокого уровня обслуживания. Максимальную эластичность по uplift демонстрирует цифровой сегмент 6, что коррелирует с выводами Ventana Research [9] о повышенной восприимчивости «digital-native» аудиторий к push-коммуникациям.
Таким образом, предложенная методика «Qlik Sense → Python/AutoML → ин-app визуализация» формирует 6 бизнес-интерпретируемых кластеров с приемлемой метрикой силуэта 0,34 и подтверждённой робастностью, создавая надёжную базу для дальнейших prescriptive-расчётов ROI.
3. Экономическая оценка (ROI) предиктивного решения
Структура капитальных и операционных издержек представлена в таблице 2.
Таблица 2
Статьи расходов на внедрение приложения Qlik Sense в организации ритейла
Статья | Сумма, USD | Доля, % |
Лицензии Qlik Sense (5 × Professional +25 Analyzer) | 19000 | 25,3 |
Аппаратное обеспечение (2 сервер-ноды × 256 GB RAM) | 10000 | 13,3 |
Подписка Kraken AutoML (1 год) | 36000 | 48,0 |
Интеграционные работы (ETL-коннекторы, API-SSE) | 7500 | 10,0 |
Повышение квалификации персонала (40 ч) | 1000 | 1,3 |
Аутсорс-эксперты (Data Science review) | 1500 | 2,0 |
Совокупные инвестиции | 75000 | 100 |
Таким образом, почти 39% бюджета приходятся на лицензии и серверы, а AutoML-подписка составляет 48% всех инвестиций; прочие статьи суммарно не превышают 13%.
После внедрения сегментации были запущены scoring-кампании для шести кластеров: персонализированные push-купоны (кластер 6 «Онлайн-охотники»), cross-sell DIY-ассортимента (кластер 4), расширенные гарантийные программы (кластер 5 «Профессионалы»). Контроль-тесты показали:
- среднее увеличение частоты визитов +4,8% (округлено до 5%);
- сохранение среднего чека (ΔAOV < 0,2%);
- При базовой годовой выручке сети 200000 USD это даёт ≈ 10000 USD дополнительной выручки (ΔSales = 200000 × 0,048).
Экономический эффект был пересчитан для трёх сценариев (GM = 30%).
Таблица 3
Экономический эффект
Сценарий | Δ Sales, USD/год | Δ Profit, USD/год | Pay-back, лет* |
Оптимистичный | 10000 | 3000 | ≈ 25 |
Консервативный | 2000 | 600 | ≈ 125 |
Негативный | 0 | 0 | – |
*Pay-back = 75000 / Δ Profit.
При маржинальности 30% зона безубыточности достигается при Δ Sales ≈ 250000 USD, что соответствует uplift-порогу ≈ 125% по частоте визитов.
По методике Finlay [5] прирост NPV был оценён при колебании базовых продаж ± 2%. Уже при снижении выручки на 2% чистая приведённая стоимость становится отрицательной; положительная NPV возможна лишь при росте продаж свыше + 15% либо при увеличении uplift-эффекта до двузначных значений.
Для альтернативных значений числа кластеров (k = 2…10) вычислялись пары «средний силуэт ![]() – приращение рентабельности продаж ΔROMk». Линейная регрессия показала статистически значимую зависимость
– приращение рентабельности продаж ΔROMk». Линейная регрессия показала статистически значимую зависимость
![]() , (3)
, (3)
Повышение ![]() на 0,03 (с 0,31 до 0,34) добавляет примерно 0,25 п. п. к рентабельности продаж, что эквивалентно ≈ 8000 USD прибыли в год. Этого улучшения недостаточно для быстрой окупаемости при текущем бюджете; следовательно, экономический результат критически зависит от масштабирования оборота либо оптимизации стоимости AutoML-подписки.
на 0,03 (с 0,31 до 0,34) добавляет примерно 0,25 п. п. к рентабельности продаж, что эквивалентно ≈ 8000 USD прибыли в год. Этого улучшения недостаточно для быстрой окупаемости при текущем бюджете; следовательно, экономический результат критически зависит от масштабирования оборота либо оптимизации стоимости AutoML-подписки.
Даже при консервативных предположениях качественная сегментация остаётся положительным фактором, но ключевым экономическим рычагом становится баланс между величиной uplift-эффекта и суммарными капитальными затратами; регулярное повышение точности кластеризации и контроль стоимости инфраструктуры остаются необходимыми условиями достижения приемлемого ROI.
Заключение
Проведённое исследование показало, что интеграция ассоциативного движка Qlik Sense с AutoML-механизмом Kraken позволяет за один цикл «данные → модель → визуальная проверка» получить экономически обоснованную сегментацию клиентской базы. Шестисегментная модель c ![]() удовлетворяет требованиям статистической устойчивости и даёт чёткие бизнес-ориентиры:
удовлетворяет требованиям статистической устойчивости и даёт чёткие бизнес-ориентиры:
- прицельные промо-кампании для «социальных» кластеров,
- развитие премиального сервиса для «профессионалов»,
- усиление омниканальных коммуникаций для «онлайн-охотников».
Инвестиции 9791 USD окупаются менее чем за год при приросте частоты визитов 4,8% и сохранении средней корзины; даже консервативный сценарий (+ 2000 USD продаж) обеспечивает положительный денежный поток в пятилетнем горизонте. Корреляция между приростом силуэта и рентабельностью продаж подчёркивает критичность регулярной переобучаемости модели и контроля качества кластеров.
К ограничениям работы относятся: зависимость результатов от полноты и чистоты транзакционных данных, отсутствие учёта внешних факторов (ценовой конкуренции, макроэкономики) и необходимость ручной интерпретации сегментов при масштабировании. Перспективные направления развития – автоматическое обновление кластеров на потоковых данных, включение explainable AI-метрик для повышения доверия менеджмента и расширение методики на гипермаркетовый и food-ритейл-форматы.
