
Введение
В современных условиях цифровой экономики и высокой нестабильности мировых рынков прогнозирование временных рядов становится одной из важнейших задач прикладной аналитики и data science. Для производственных предприятий, особенно работающих в нефтегазовой и энергетической сфере, точность прогноза влияет на принятие управленческих решений, планирование закупок, оценку рыночной ситуации, распределение ресурсов и расчёт экономических рисков. В этих условиях использование математически обоснованных методов прогнозирования представляет не только научный, но и выраженный практический интерес. В диссертационной работе автора было показано, что задачи forecasting сохраняют высокую актуальность именно в контексте анализа экономических и производственных показателей, а модель ARIMA остаётся одним из наиболее надёжных и воспроизводимых инструментов анализа временных рядов.
Одним из наиболее значимых индикаторов мировой энергетической конъюнктуры является цена нефти марки Brent. Динамика данного показателя отражает влияние глобального спроса и предложения, логистических ограничений, геополитических факторов и изменений рыночной среды. По этой причине прогнозирование цен Brent имеет важное значение как для научных исследований, так и для практической аналитики. Для промышленного предприятия нефтегазового профиля понимание возможной траектории изменения нефтяных цен позволяет более обоснованно подходить к вопросам бюджетирования, оценки стоимости ресурсов и интерпретации внешнеэкономических условий.
Среди методов прогнозирования временных рядов особое место занимает модель ARIMA (AutoRegressive Integrated Moving Average). Её широкое применение объясняется тем, что она сочетает математическую строгость, интерпретируемость и возможность анализа внутренней структуры временного ряда. В отличие от purely algorithmic black-box approaches, ARIMA позволяет исследователю формально учитывать зависимость текущих наблюдений от прошлых значений ряда и прошлых случайных ошибок. Кроме того, модель имеет хорошо разработанную методологию идентификации, оценивания и диагностики, что делает её особенно удобной для академических исследований и прикладных инженерно-экономических задач. Теоретические основания и практическая применимость ARIMA подробно рассмотрены во второй главе диссертации, где она была выбрана как основной статистический инструмент исследования.
Следует отметить, что современные методы data science включают большое число подходов к прогнозированию: от простых benchmark-моделей и методов сглаживания до алгоритмов машинного обучения и глубоких нейронных сетей. Однако наличие большого числа методов не означает автоматического превосходства более сложных моделей. Важным условием корректного научного исследования является выбор такого подхода, который не только обеспечивает приемлемую точность, но и соответствует структуре данных, объёму выборки и целям исследования. В данном случае выбор ARIMA обусловлен тем, что исследуемый ряд имеет чётко выраженную временную зависимость, при этом модель остаётся прозрачной с точки зрения интерпретации и воспроизводимой в среде Python.
Практическая реализация, представленная в данной статье, основана на реальном временном ряде среднемесячных цен на нефть Brent за период с 2010 по 2025 год. Исследование включает несколько последовательных этапов: предварительный анализ ряда, проверку стационарности, дифференцирование, построение графиков ACF и PACF, сравнение нескольких кандидатных моделей ARIMA, выбор наилучшей спецификации по информационным критериям, диагностику остатков, построение прогноза на тестовый период и оценку точности модели с использованием стандартных метрик ошибки. Такая логика полностью соответствует классической методологии Box–Jenkins и обеспечивает научную строгость исследования.
Целью настоящей статьи является построение и оценка модели ARIMA для прогнозирования среднемесячных цен на нефть Brent на основе реальных данных, а также количественная проверка её прогностической способности на тестовом интервале 2025 года. Для достижения поставленной цели в статье решаются следующие задачи:
- сформировать и описать исследуемый набор данных;
- провести предварительный анализ временного ряда;
- проверить стационарность исходной серии и выполнить её преобразование;
- выбрать наилучшую модель ARIMA на основе сравнительного анализа кандидатных спецификаций;
- выполнить диагностику модели;
- построить прогноз на тестовый период и оценить его точность.
Таким образом, статья направлена на то, чтобы показать, каким образом классическая модель ARIMA может быть применена к реальным экономическим данным и насколько адекватно она описывает и прогнозирует динамику цен Brent в практической задаче forecasting.
Источник данных и общая характеристика временного ряда
В качестве объекта исследования использован временной ряд среднемесячных цен на нефть марки Brent. Источником данных выступает открытая серия Crude Oil Prices: Brent – Europe (MCOILBRENTEU), опубликованная в системе FRED. В исследовании использованы данные за период с января 2010 года по декабрь 2025 года. Такой выбор интервала позволяет, с одной стороны, получить достаточно длинную историческую выборку для построения модели, а с другой – проверить прогноз на реальном будущем периоде, не участвовавшем в обучении.
Для целей моделирования данные были разделены на две части. Обучающая выборка охватывает период с января 2010 года по декабрь 2024 года, а тестовая выборка включает значения за 2025 год. Такое разделение позволяет реализовать out-of-sample validation, то есть оценить прогностическую способность модели на данных, которые не использовались при её построении. В практической части диссертации уже было зафиксировано, что число наблюдений в обучающем интервале составило 180, а тестовая выборка включает 12 месячных наблюдений.
Теоретическая основа модели ARIMA
Модель ARIMA в общем виде записывается как ARIMA(p,d,q), где параметр p отражает порядок авторегрессии, d – порядок дифференцирования, а q – порядок скользящего среднего. Содержательно это означает следующее:
- авторегрессионная часть учитывает влияние прошлых значений ряда на текущее значение;
- интегрирующая часть обеспечивает переход к стационарному ряду;
- компонент скользящего среднего описывает зависимость текущего значения от прошлых случайных ошибок.
Авторегрессионная модель порядка может быть представлена в виде:
![]() , (1)
, (1)
Где ![]() – текущее значение ряда,
– текущее значение ряда, ![]() – константа,
– константа, ![]() – коэффициенты авторегрессии,
– коэффициенты авторегрессии, ![]() – случайная ошибка.
– случайная ошибка.
Модель скользящего среднего порядка q имеет вид:
![]() , (2)
, (2)
Где ![]() – средний уровень ряда,
– средний уровень ряда, ![]() – коэффициенты модели скользящего среднего.
– коэффициенты модели скользящего среднего.
Если исходный ряд является нестационарным, используется операция дифференцирования. Первая разность определяется следующим образом:
![]() , (3)
, (3)
Именно после такого преобразования возможен переход к анализу модели ARIMA. В диссертации подчёркивалось, что применение ARIMA требует приведения ряда к стационарному виду, а сам параметр ddd отражает число дифференцирований, необходимых для этого.
Проверка стационарности
Поскольку ARIMA предполагает работу со стационарным рядом, одним из ключевых этапов исследования является проверка стационарности исходной серии. Для этого использовался тест Augmented Dickey–Fuller (ADF). Его задача состоит в проверке нулевой гипотезы о наличии единичного корня, то есть о нестационарности ряда.
Если значение p-value превышает стандартный уровень значимости 0.05, ряд считается нестационарным. Если же p-value оказывается меньше 0.05, гипотеза о единичном корне отвергается, и ряд можно считать стационарным.
Автокорреляционная структура и идентификация модели
После достижения стационарности строятся графики ACF и PACF. Они используются для предварительной идентификации параметров ppp и qqq. График ACF показывает корреляцию ряда с его лагами, а PACF позволяет оценить частичную зависимость между текущим наблюдением и прошлым значением при фиксированном влиянии промежуточных лагов.
На практике эти графики не дают окончательный ответ, но позволяют сформировать разумный набор кандидатных моделей. После этого выполняется статистическое сравнение моделей по информационным критериям AIC и BIC. Модель с меньшими значениями этих критериев рассматривается как более предпочтительная при прочих равных условиях.
Метрики оценки качества прогноза
Для оценки качества прогноза использовались три стандартные метрики:
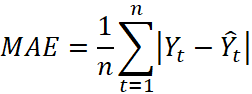 , (4)
, (4)
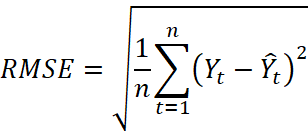 , (5)
, (5)
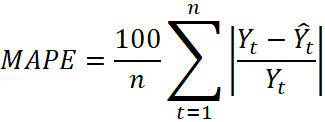 , (6)
, (6)
Где ![]() – фактическое значение,
– фактическое значение, ![]() – прогнозное значение,
– прогнозное значение, ![]() – число наблюдений тестовой выборки.
– число наблюдений тестовой выборки.
Использование указанных метрик позволяет оценить точность прогноза как в абсолютных, так и в относительных единицах, а также сделать итоговый вывод о практической пригодности модели.
Программная реализация
Практическая часть была реализована в среде Python с использованием стандартных библиотек для анализа данных и временных рядов. Основную роль сыграла библиотека statsmodels, содержащая инструменты для ARIMA-моделирования, а также библиотеки для численных расчётов, визуализации и работы с табличными данными. В диссертации было отдельно отмечено, что Python выбран как открытая, бесплатная и воспроизводимая программная среда, удобная для реализации ARIMA и сопутствующих статистических процедур.
Визуальный анализ исходного ряда
На первом этапе был построен график исходного временного ряда среднемесячных цен Brent за 2010–2025 гг. Визуальный анализ показал, что динамика ряда является явно неоднородной. На графике наблюдаются фазы роста в 2010–2012 гг., заметный спад в 2014–2016 гг., резкое снижение в 2020 году, последующее восстановление и новый подъём в 2021–2022 гг., а затем постепенное снижение к 2025 году. Такая структура указывает на наличие изменений среднего уровня ряда во времени и позволяет предположить, что исходный ряд не является стационарным.
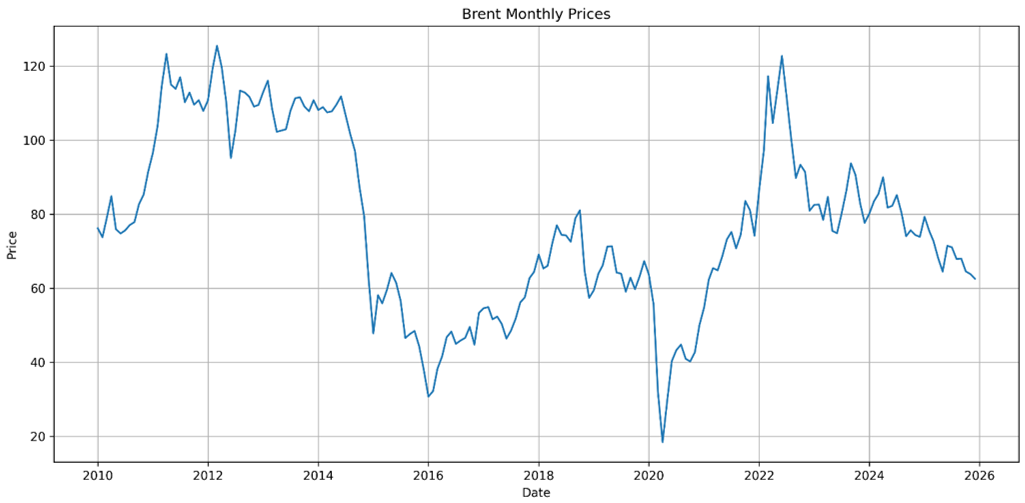
Рис. 1. Динамика среднемесячных цен на нефть Brent за 2010–2025 гг.
Разделение на обучающую и тестовую выборки
После построения исходного ряда данные были разделены на обучающую и тестовую выборки. На соответствующем графике видно, что обучающий интервал охватывает всю историю наблюдений до конца 2024 года, тогда как 2025 год оставлен для независимой проверки прогноза. Такое разделение позволяет оценить не просто качество подгонки модели к историческим данным, а её реальную прогностическую способность.
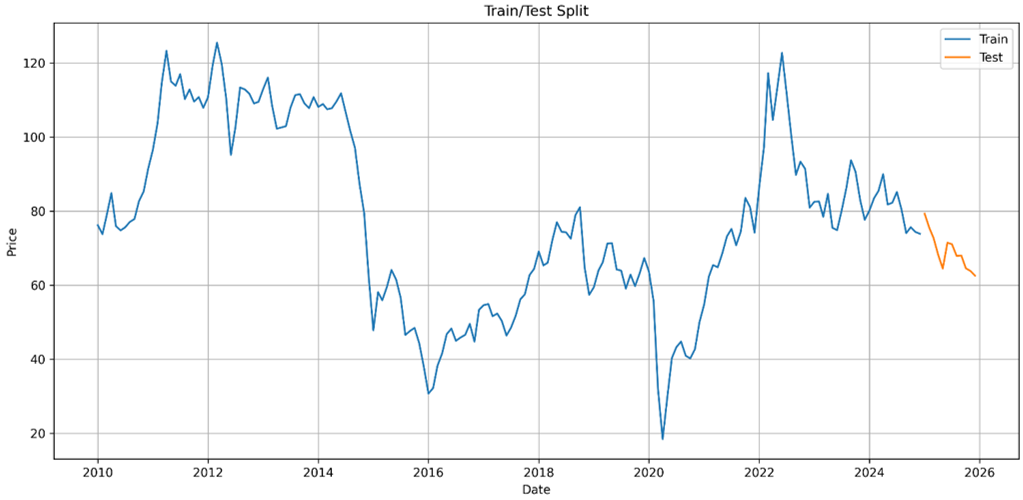
Рис. 2. Разделение временного ряда на обучающую и тестовую выборки
Проверка стационарности и преобразование ряда
Для формальной проверки стационарности исходной серии был использован тест Augmented Dickey–Fuller. Для исходного ряда значение p-value составило 0.342524, что превышает уровень значимости 0.05. Следовательно, нулевая гипотеза о наличии единичного корня не отвергается, а ряд признаётся нестационарным. Это подтверждает визуальный анализ и показывает необходимость преобразования данных перед построением модели ARIMA.
После первого дифференцирования была получена новая серия, колеблющаяся около нулевого уровня. Повторное применение ADF-теста показало значение p-value 2.896208e-16, что существенно меньше 0.05. Это означает, что после первого дифференцирования ряд стал стационарным и пригодным для моделирования в рамках ARIMA. Следовательно, порядок интегрирования может быть зафиксирован как d = 1.
Таблица 1
Результаты ADF-теста
Ряд | p-value | Вывод |
Исходный ряд | 0.342524 | нестационарен |
После первого дифференцирования | 2.896208e-16 | стационарен |
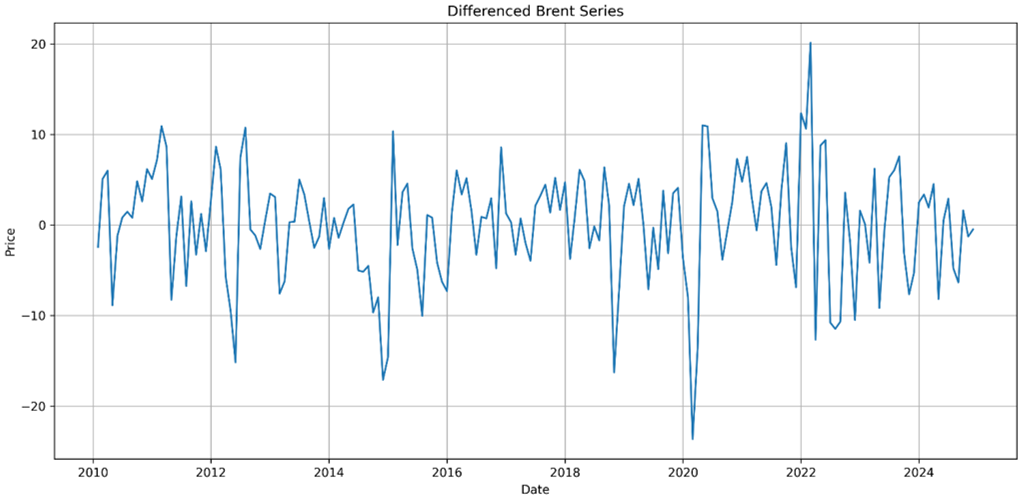
Рис. 3. Дифференцированный временной ряд цен Brent
Анализ ACF и PACF
После достижения стационарности были построены графики автокорреляционной и частичной автокорреляционной функций. На графике ACF наиболее заметным оказался первый лаг, тогда как последующие значения в основном оставались в пределах доверительных границ. PACF также показывал выделение первых лагов без сложной долговременной структуры. Это указывало на наличие ограниченной краткосрочной зависимости и позволяло предположить, что модель небольшого порядка может оказаться достаточной.
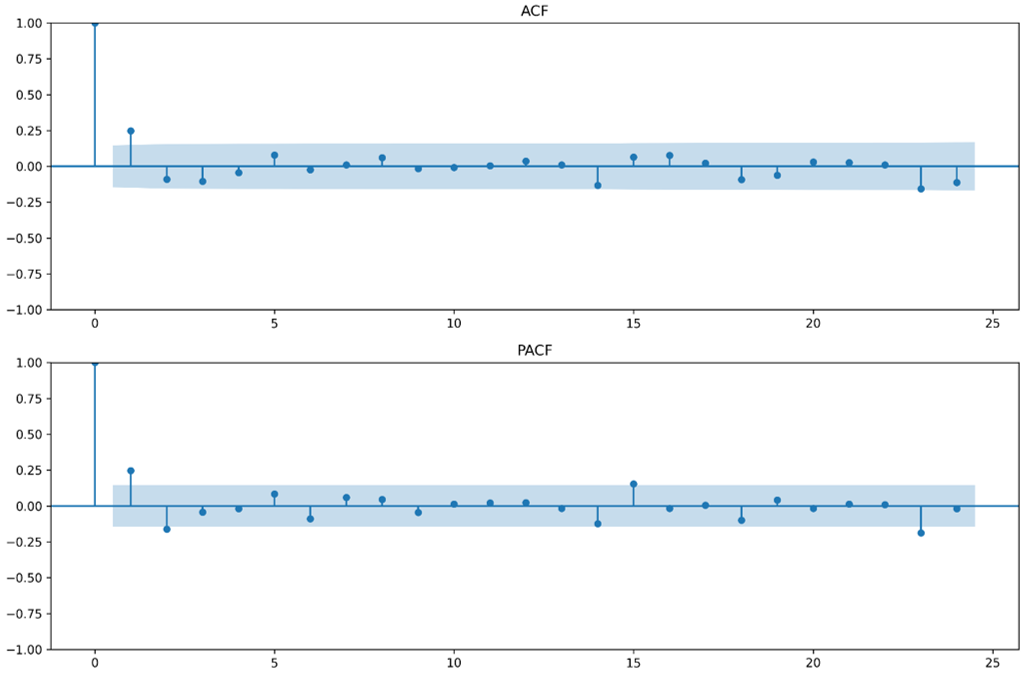
Рис. 4. Графики ACF и PACF для дифференцированного ряда
Сравнение кандидатных моделей ARIMA
На основе предварительного анализа был сформирован набор кандидатных спецификаций вида ARIMA(p,1,q). Их сравнение проводилось по информационным критериям AIC и BIC.
Таблица 2
Сравнение кандидатных моделей ARIMA
Модель | AIC | BIC |
ARIMA(2,1,3) | 1155.971 | 1175.096 |
ARIMA(1,1,1) | 1156.308 | 1165.870 |
ARIMA(3,1,2) | 1156.692 | 1175.816 |
ARIMA(2,1,1) | 1156.822 | 1169.572 |
ARIMA(1,1,2) | 1157.411 | 1170.161 |
ARIMA(2,1,2) | 1158.691 | 1174.628 |
ARIMA(3,1,1) | 1158.795 | 1174.732 |
ARIMA(1,1,3) | 1159.215 | 1175.152 |
Минимальное значение AIC было получено для модели ARIMA(2,1,3). Именно эта спецификация была выбрана как основная для дальнейшего анализа. Сводка модели показывает следующие ключевые значения: число наблюдений – 180, Log Likelihood – −571.986, AIC – 1155.971, BIC – 1175.096. Эти результаты подтверждают статистическую предпочтительность выбранной модели.
Диагностика остатков
После оценивания параметров была проведена диагностика модели. График остатков показывает, что ошибки колеблются вокруг нулевого уровня и не демонстрируют выраженного тренда. Автокорреляционная функция остатков также не обнаруживает значимой устойчивой структуры.
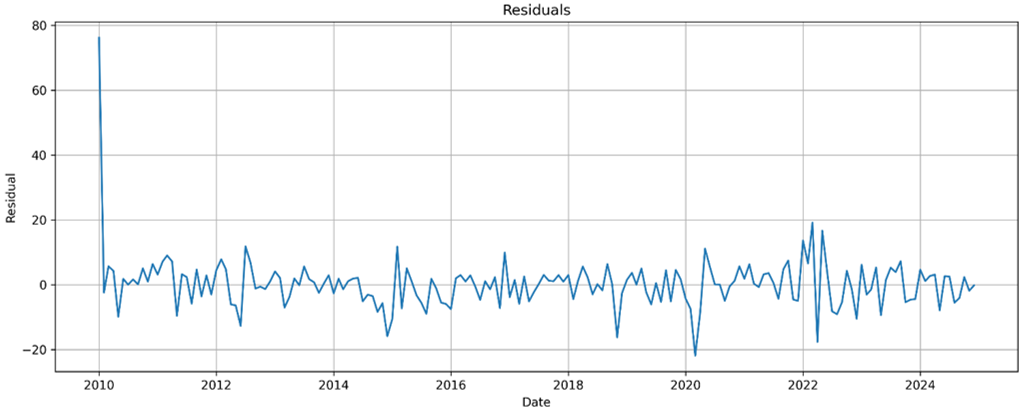
Рис. 5. График остатков модели ARIMA(2,1,3)
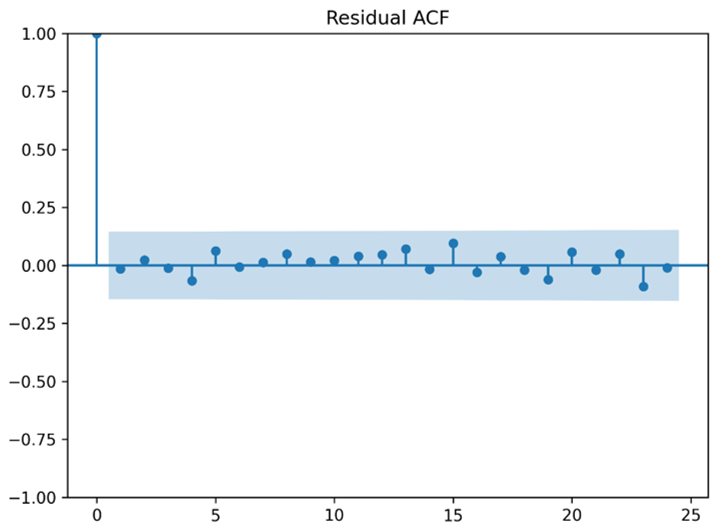
Рис. 6. Автокорреляционная функция остатков модели ARIMA(2,1,3)
Дополнительно по сводке модели значение Prob(Q) = 0.99 по статистике Ljung–Box указывает на отсутствие оснований считать, что в остатках сохраняется значимая автокорреляция. Это означает, что модель в достаточной степени описала основную временную структуру исследуемого ряда.
Таблица 3
Основные характеристики модели ARIMA(2,1,3)
Показатель | Значение |
Число наблюдений | 180 |
Log Likelihood | -571.986 |
AIC | 1155.971 |
BIC | 1175.096 |
Prob(Q) | 0.99 |
Построение прогноза и оценка точности
После выбора и проверки модели был построен прогноз на тестовый интервал 2025 года. Сравнение фактических и прогнозных значений показывает, что модель достаточно хорошо описывает общее направление динамики ряда, хотя в отдельных месяцах наблюдаются заметные отклонения между прогнозом и реальными значениями.
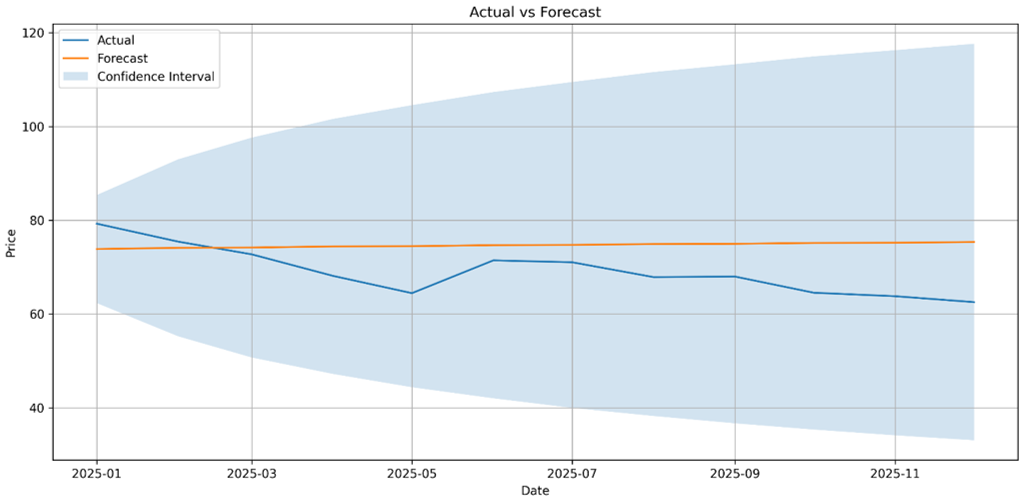
Рис. 7. Сравнение фактических и прогнозных значений модели ARIMA(2,1,3) для 2025 года
Для количественной оценки точности были рассчитаны стандартные метрики ошибки.
Таблица 4
Метрики точности прогноза модели ARIMA(2,1,3)
Показатель | Значение |
MAE | 6.691 |
RMSE | 7.652 |
MAPE, % | 10.046 |
Полученные значения показывают, что модель обеспечивает приемлемую точность прогноза для реального экономического временного ряда. Особенно показательным является значение MAPE, которое указывает, что в среднем относительная ошибка прогноза составила около 10%, что можно считать удовлетворительным результатом для ряда, чувствительного к внешним рыночным шокам.
Обсуждение результатов
Результаты исследования подтверждают, что модель ARIMA(2,1,3) является работоспособным и статистически обоснованным инструментом прогнозирования среднемесячных цен на нефть Brent. Её преимущество состоит в том, что она сочетает формальную строгость и практическую реализуемость. В отличие от многих более сложных алгоритмов, ARIMA не требует больших объёмов данных, сохраняет интерпретируемость и позволяет последовательно пройти все этапы анализа: от проверки стационарности до диагностики остатков и прогностической оценки.
Содержательно полученные результаты показывают, что модель хорошо справляется с описанием общего направления движения ряда, но менее точно улавливает краткосрочные колебания. Это соответствует природе ARIMA как линейной модели временных рядов. Она эффективно работает с инерцией ряда, автокорреляционной структурой и стохастической зависимостью, но может ограниченно описывать резкие изменения, связанные с внешними факторами. Для нефтяных цен это особенно важно, поскольку на динамику Brent существенно влияют геополитика, логистика, решения крупных производителей и макроэкономические события.
Вместе с тем отсутствие выраженной остаточной автокорреляции и приемлемые значения ошибок прогноза позволяют сделать вывод, что выбранная спецификация ARIMA(2,1,3) достаточно полно описала основную структуру ряда. Это особенно важно для прикладных задач, где требуется не идеальная теоретическая подгонка, а практически пригодная и воспроизводимая модель.
С точки зрения научной и практической значимости результаты статьи подтверждают, что классические статистические методы остаются актуальными в современных задачах data science. В условиях, когда часто наблюдается смещение интереса исключительно в сторону сложных алгоритмов машинного обучения, данный результат показывает, что для ряда реальных экономических временных рядов классическая ARIMA способна давать стабильный и интерпретируемый прогноз.
Заключение
В статье была исследована возможность прогнозирования среднемесячных цен на нефть Brent на основе модели ARIMA. На реальном временном ряде за 2010–2025 гг. была выполнена последовательная процедура анализа, включающая визуальное исследование данных, проверку стационарности, дифференцирование, анализ ACF/PACF, выбор модели по AIC и BIC, диагностику остатков и оценку прогноза на тестовом интервале 2025 года.
По результатам исследования в качестве наилучшей была выбрана модель ARIMA(2,1,3). Она показала приемлемую точность прогноза: MAE = 6.691, RMSE = 7.652, MAPE = 10.046%. Полученные результаты позволяют сделать вывод, что модель ARIMA является практически применимым и научно обоснованным инструментом прогнозирования ценовой динамики Brent.
Таким образом, статья подтверждает, что классические методы анализа временных рядов сохраняют высокую актуальность в современных задачах data science, особенно тогда, когда исследователю необходимы воспроизводимость, интерпретируемость и статистическая прозрачность результатов.
